






















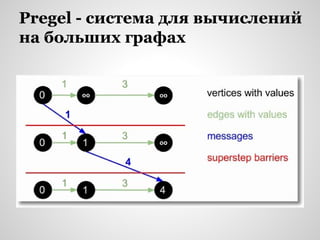
















![Алгоритмы для вычисления
кратчайшего расстояния
ALT: [Goldberg & Harrelson 05], [Delling & Wagner 07]
RE: [Gutman 05], [Goldberg et al. 07]
HH: [Sanders & Schultes 06]
CH: [Geisberger et al. 08]
TN: [Geisberger et al. 08]
HL: [Abraham et al. 11]
Dijkstra ALT RE HH CH TN HL
2 008 300 24 656 2444 462.0 94.0 1.8 0.3](https://image.slidesharecdn.com/bigdataalgorithmsanddatastructuresforlarge-scalegraphs-140317043038-phpapp02/85/Big-data-algorithms-and-data-structures-for-large-scale-graphs-46-320.jpg)

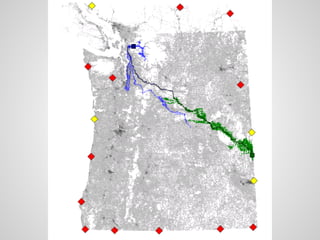









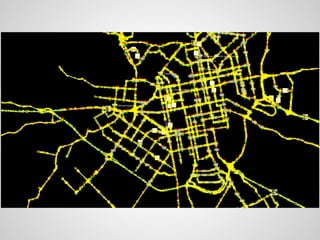






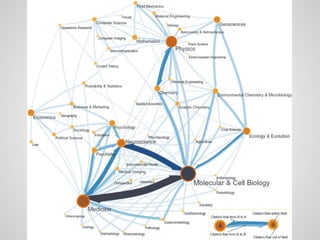
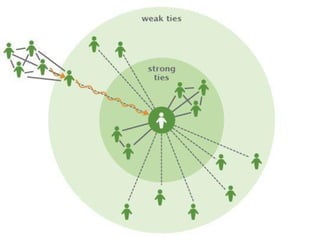
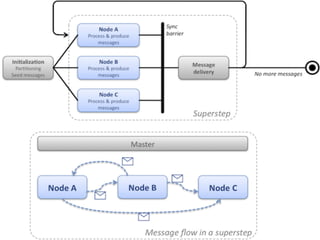
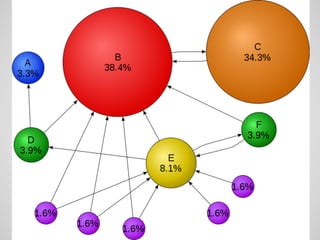
Доклад обсуждает использование алгоритмов и структур данных для обработки больших графов, охватывая теорию графов и практические применения в различных областях, таких как социология и транспортные сети. Основное внимание уделяется поиску кратчайших путей, включая оптимизации и алгоритмы, такие как A* и Dijkstra, а также вопросам хранения данных и устойчивости к ошибкам. Также акцентируется внимание на современных системах вычислений, таких как Pregel и Giraph, для работы с большими графами.















































