














![● CRUD + column iteration, Partial support of JPA standart
● Consistency Level can be set per Column Family and per
operation type (Read, Write)
● Based on Thrift RPC protocol (1 response per 1 request)
● Mapping a Collection (POJO property) to columns
● Inheritance through ‘single table’
● Custom converters to/from byte[]
Hector](https://image.slidesharecdn.com/jpoint15169hibernatenosql-150419013224-conversion-gate02/75/JPoint-15-Mom-I-so-wish-Hibernate-for-my-NoSQL-database-20-2048.jpg)











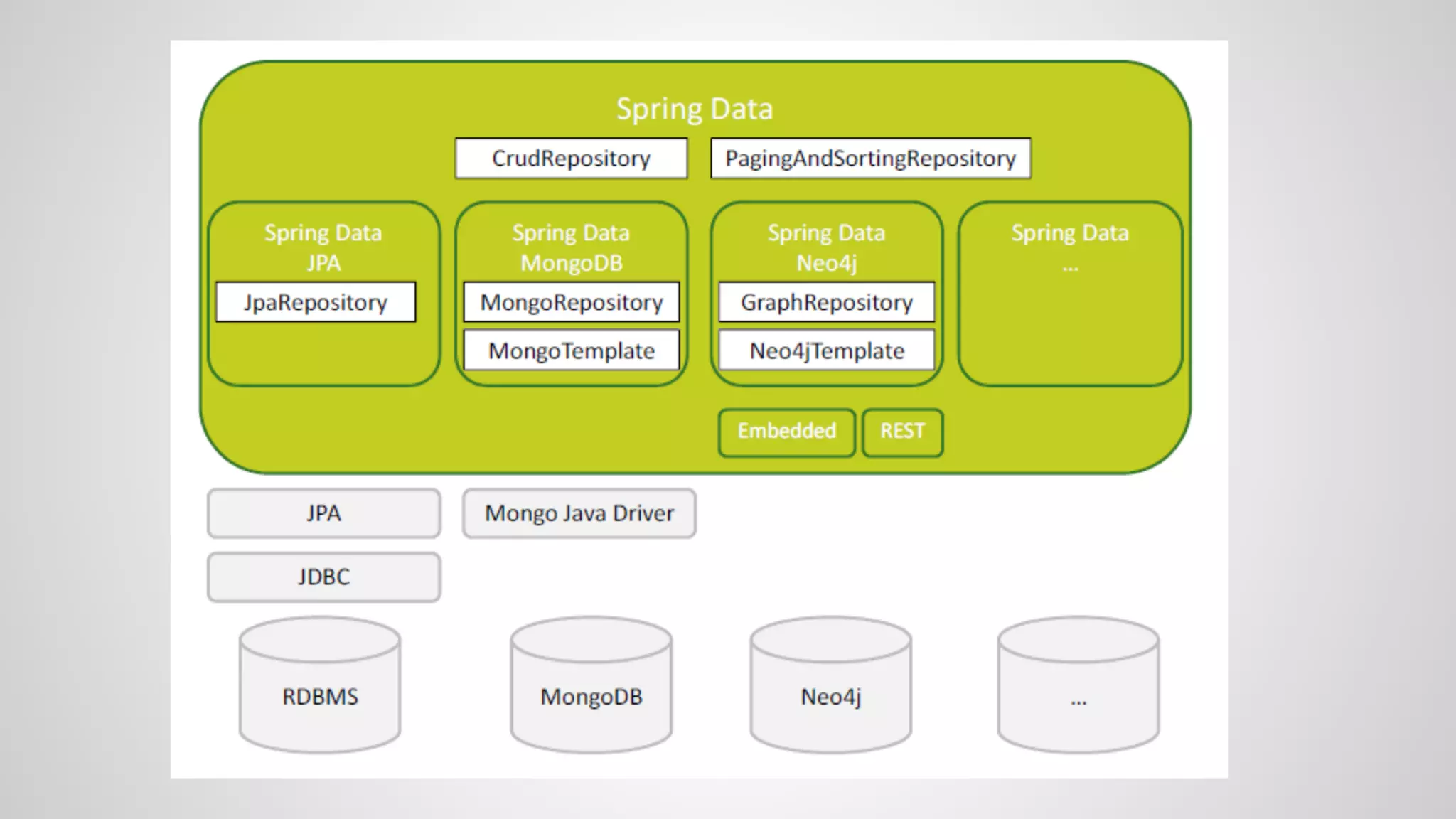





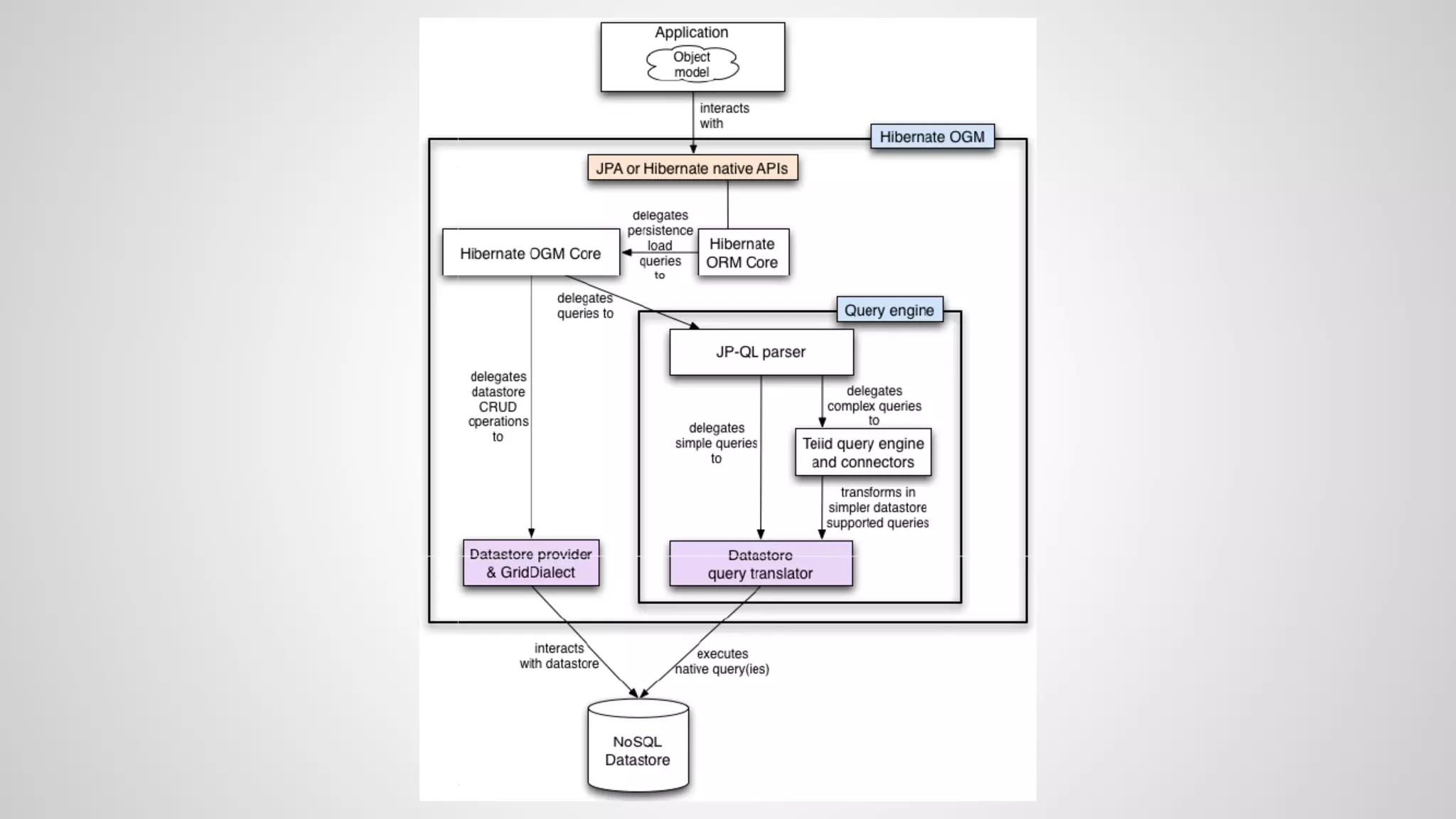
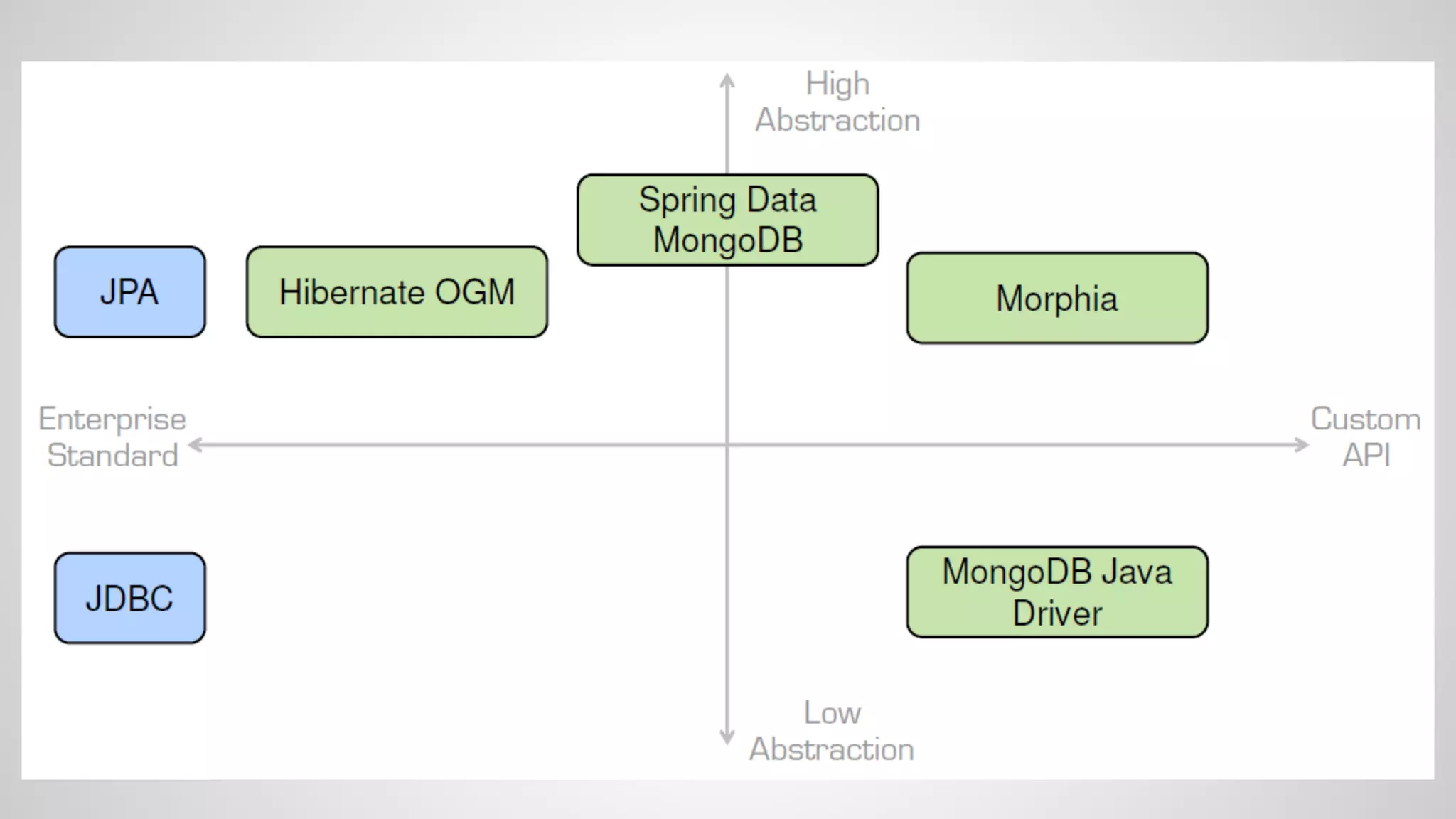








The document discusses various NoSQL databases and their functions, including Cassandra, MongoDB, and Neo4j, highlighting their data models, query APIs, and integration with Java frameworks. It emphasizes the importance of selecting the right database and framework based on specific project needs and provides insights into polyglot persistence and different database architectures. The speaker also touches on challenges and considerations for working with NoSQL within the context of Java persistence and ORM solutions.



























![[db tech showcase Tokyo 2016] E32: My Life as a Disruptor by Jim Starkey](https://cdn.slidesharecdn.com/ss_thumbnails/7pst93zhrlgqst8otgwx-signature-ff0930cf8fa20a70dc651834f3f575781e7b627c103482f6776b02ac84b96485-poli-160719054907-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db tech showcase Tokyo 2016] E34: Oracle SE - RAC, HA and Standby are Still ...](https://cdn.slidesharecdn.com/ss_thumbnails/lqy2zqfxqmif8xeztxtr-signature-44327555e43d6a00760901a1f10c738a3c30da5dd494b81e3f7ae75f088cd2d2-poli-160815043717-thumbnail.jpg?width=640&height=640&fit=bounds)































































