Download as PDF, PPTX

















![@doanduyhai
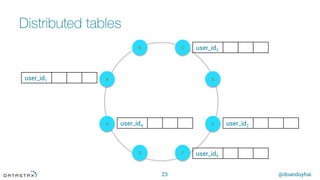
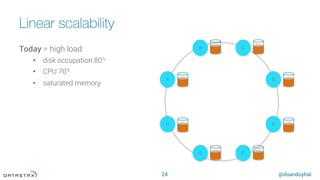
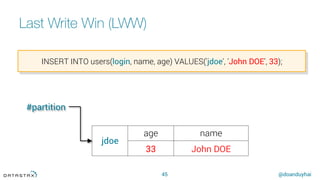
The tokens
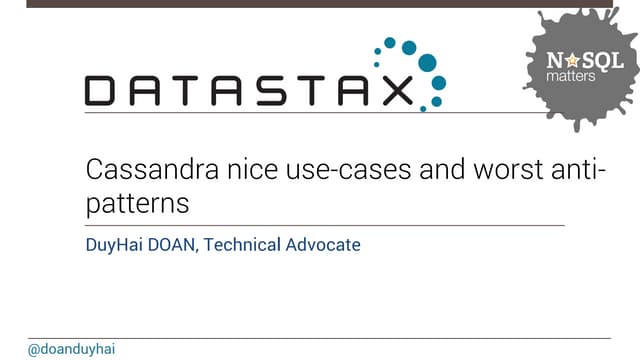
20
Random hash of #partition à token = hash(#p)
Hash: ] –x, x ]
hash range: 264 values
x = 264/2
C*
C*
C*
C*
C* C*
C* C*](https://image.slidesharecdn.com/cassandraintroduction-160324222223/85/Cassandra-introduction-2016-20-320.jpg)





































![@doanduyhai
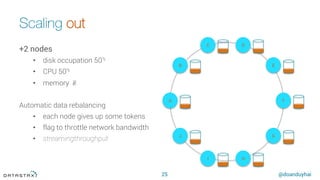
WHERE clause restrictions
66
What if I want to perform "arbitrary" WHERE clause ?
• search form scenario, dynamic search fields
Or Datastax Enterprise Search (battle field proven)
• ☞ Apache Solr (Lucene) integration (Datastax Enterprise Search)
• ☞ Same JVM, 1-cluster-2-products (Solr & Cassandra)
SELECT * FROM users WHERE solr_query = 'age:[33 TO *] AND gender:male';
SELECT * FROM users WHERE solr_query = 'lastname:*schwei?er';](https://image.slidesharecdn.com/cassandraintroduction-160324222223/85/Cassandra-introduction-2016-66-320.jpg)







![@doanduyhai
JSON syntax for SELECT
74
> SELECT JSON * FROM users WHERE id = 'me';
[json]
----------------------------------------
{"id": "me", "age": 25, "state": "CA”}
> SELECT JSON age,state FROM users WHERE id = 'me';
[json]
----------------------------------------
{"age": 25, "state": "CA"}
> SELECT age, toJson(state) FROM users WHERE id = 'me';
age | system.tojson(state)
-----+----------------------
25 | "CA"](https://image.slidesharecdn.com/cassandraintroduction-160324222223/85/Cassandra-introduction-2016-74-320.jpg)


![@doanduyhai
User Defined Functions (UDF)
77
CREATE [OR REPLACE] FUNCTION [IF NOT EXISTS]
maxOf (col1 int, col2 int)
CALL ON NULL INPUT | RETURNS NULL ON NULL INPUT
RETURN int
LANGUAGE java
AS $$
return Math.max(col1, col2);
$$;
SELECT maxOf(col1, col2) FROM table WHERE id = xxx;](https://image.slidesharecdn.com/cassandraintroduction-160324222223/85/Cassandra-introduction-2016-77-320.jpg)
![@doanduyhai
User Defined Aggregates (UDA)
78
CREATE [OR REPLACE] AGGREGATE [IF NOT EXISTS]
sum(bigint)
SFUNC accumulatorFunction
STYPE bigint
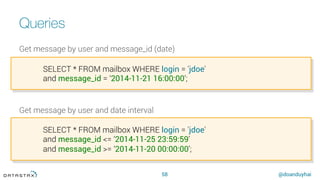
[FINALFUNC finalFunction]
INITCOND 0;
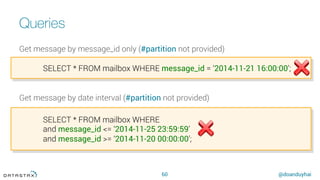
CREATE FUNCTION accumulatorFunction(accu bigint, column bigint)
RETURNS NULL ON NULL INPUT RETURN bigint LANGUAGE java
AS $$ return accu + colum; $$;](https://image.slidesharecdn.com/cassandraintroduction-160324222223/85/Cassandra-introduction-2016-78-320.jpg)



There are a few options for performing more complex queries in Cassandra beyond the restrictions of the WHERE clause: 1. Denormalize/duplicate data across tables to allow querying on different columns. For example, have one table keyed on user ID and another keyed on message date to allow filtering by date. 2. Offload complex queries to an external search index like Solr or Elasticsearch that can handle full-text and complex queries, and keep Cassandra as the system of record. 3. Use Spark/Hive on Cassandra to run queries across the cluster and leverage their more powerful query engines. 4. Consider a different database if your queries require joins, complex where clauses, or don't map well to