Downloaded 10 times








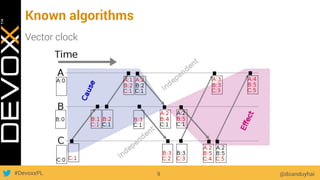












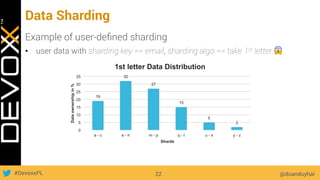
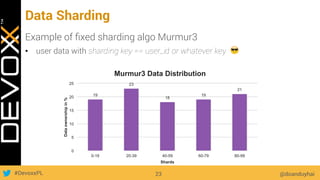


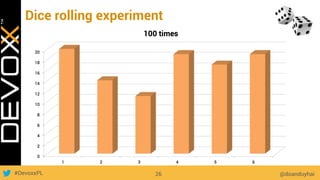
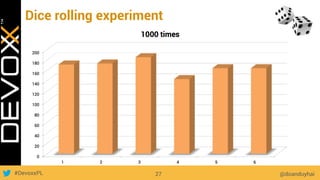
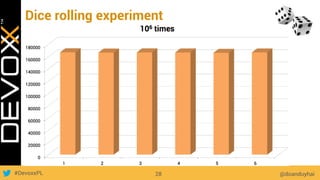


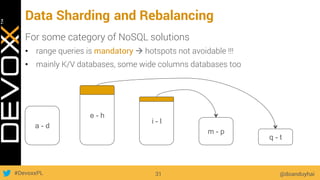


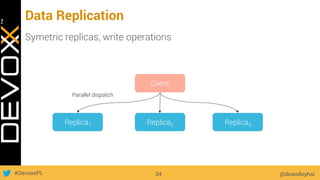
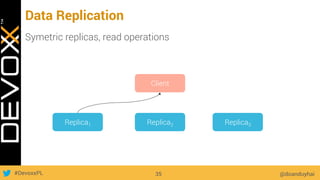
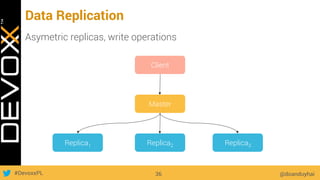
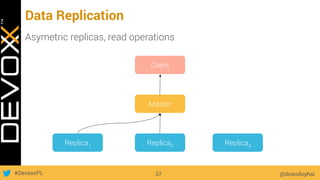
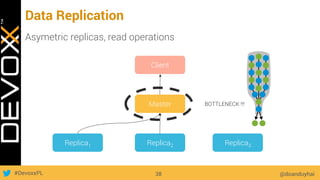
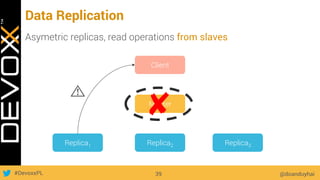
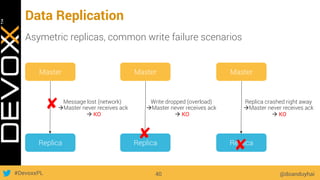
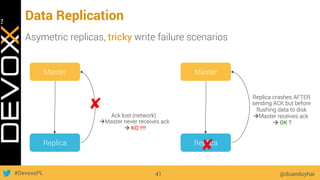




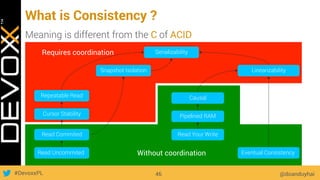
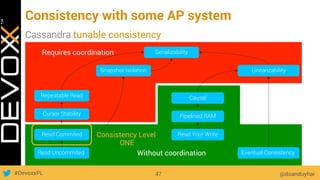
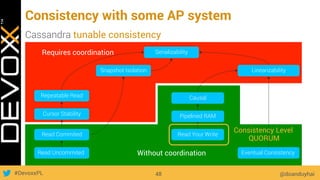
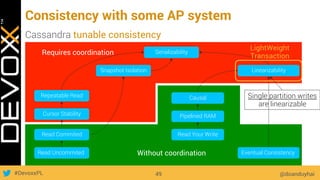


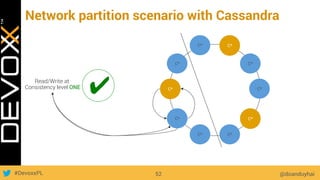
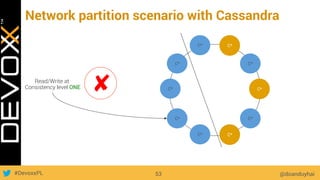
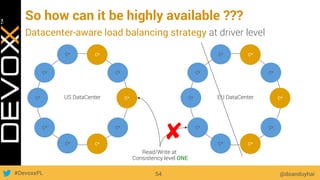


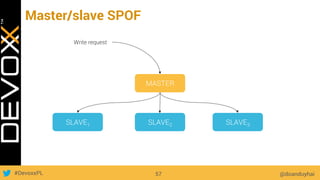
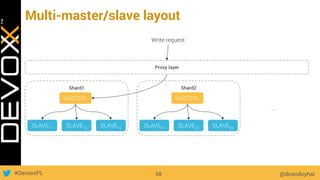





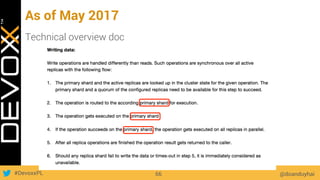
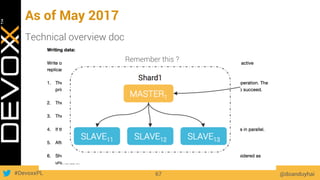


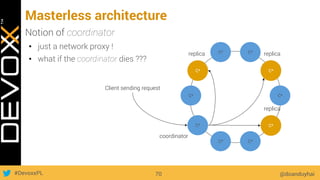
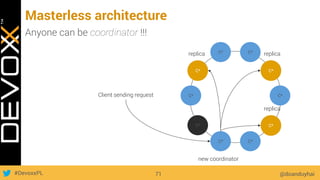


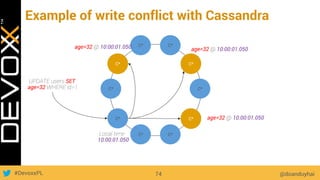
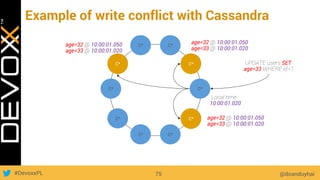
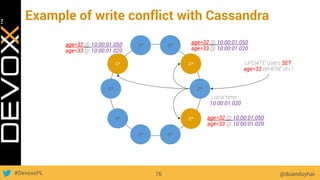





This document provides an overview of big data concepts for a new project in 2017. It discusses distributed systems theories like time ordering, latency, failure and consensus. It also covers data sharding, replication, and the CAP theorem. Key points include how latency is impacted by network delays, different failure modes, and that the CAP theorem states that a distributed system can only guarantee two of consistency, availability, and partition tolerance at once.


















































































