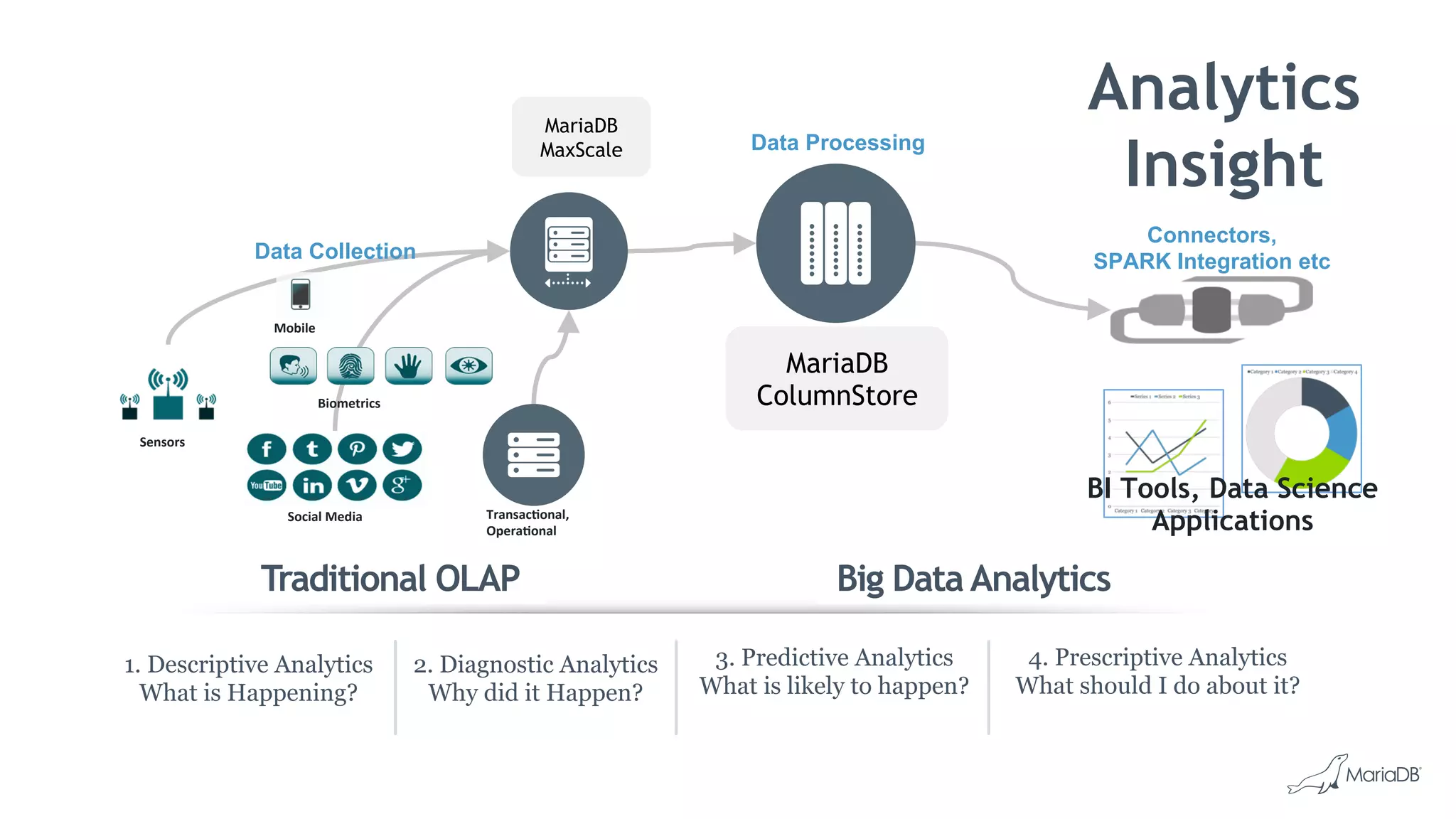
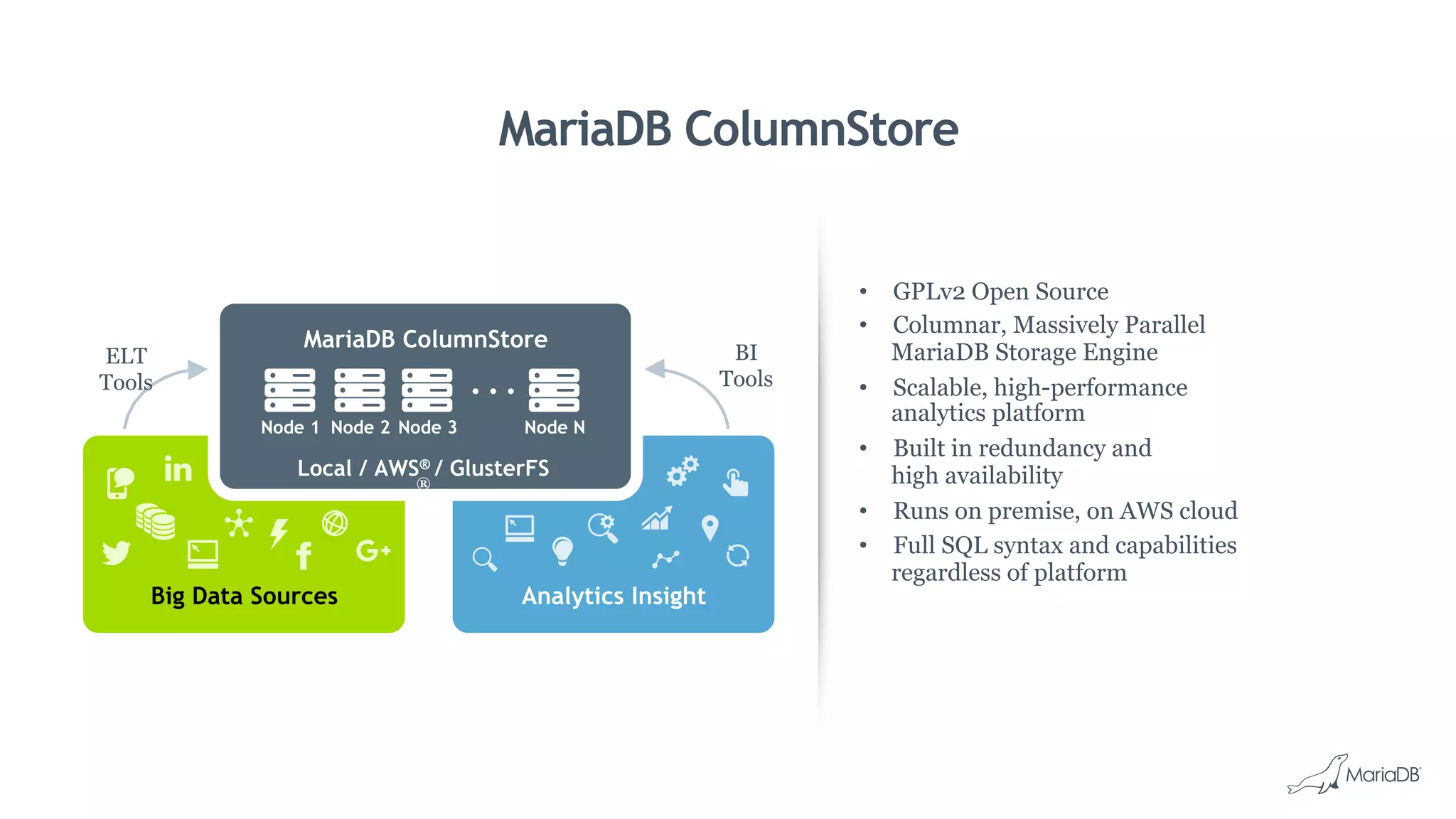
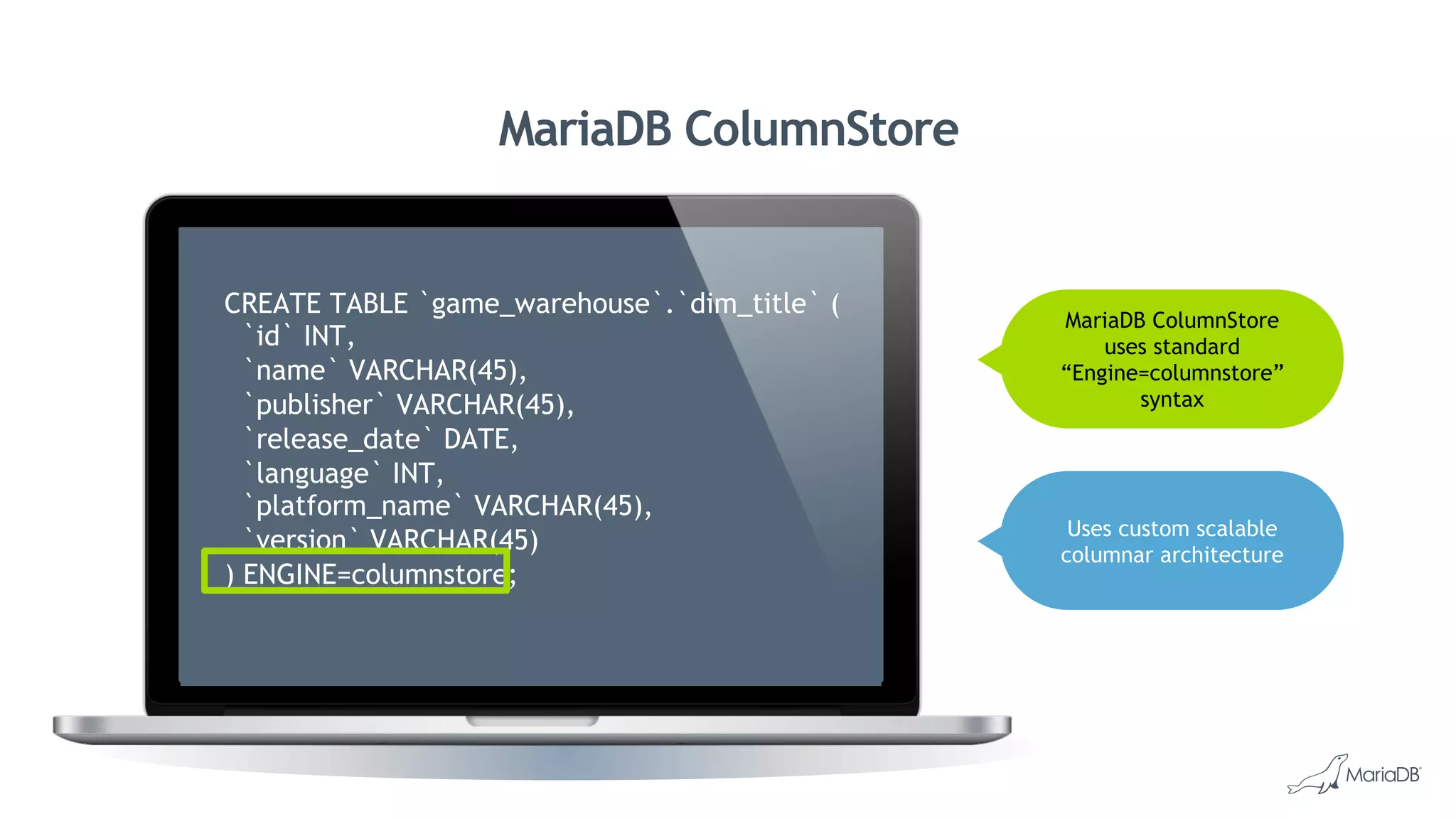
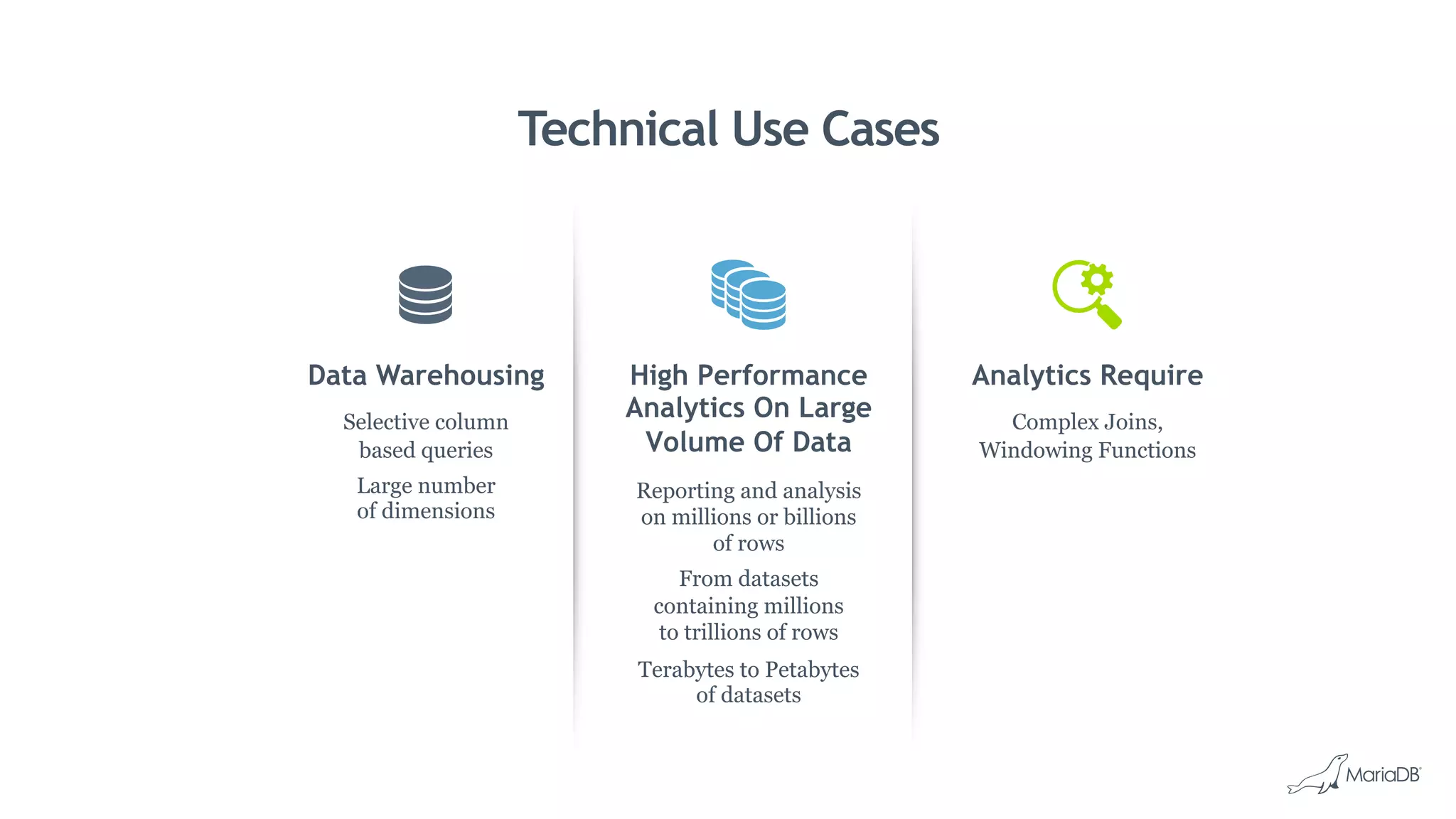
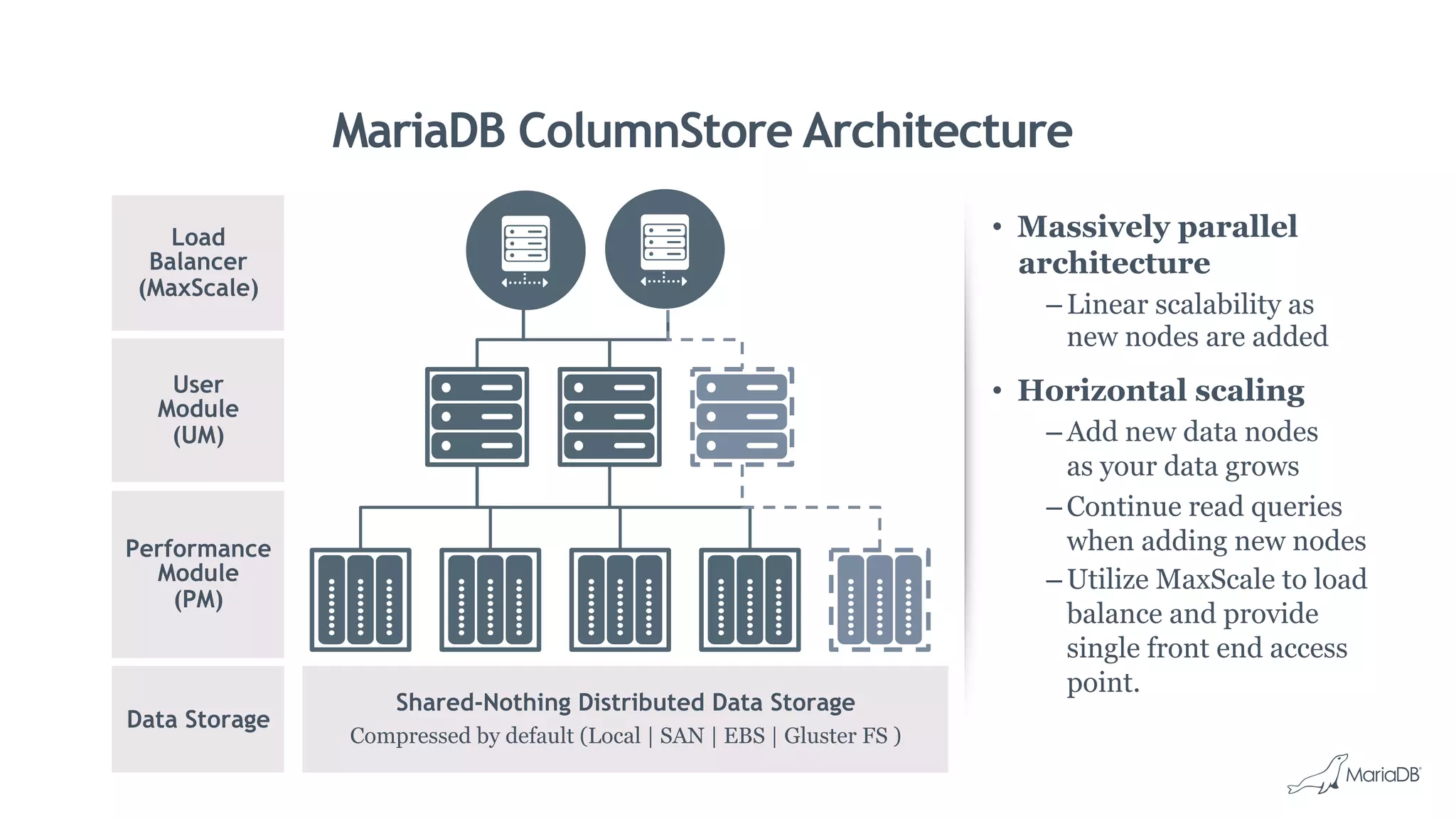
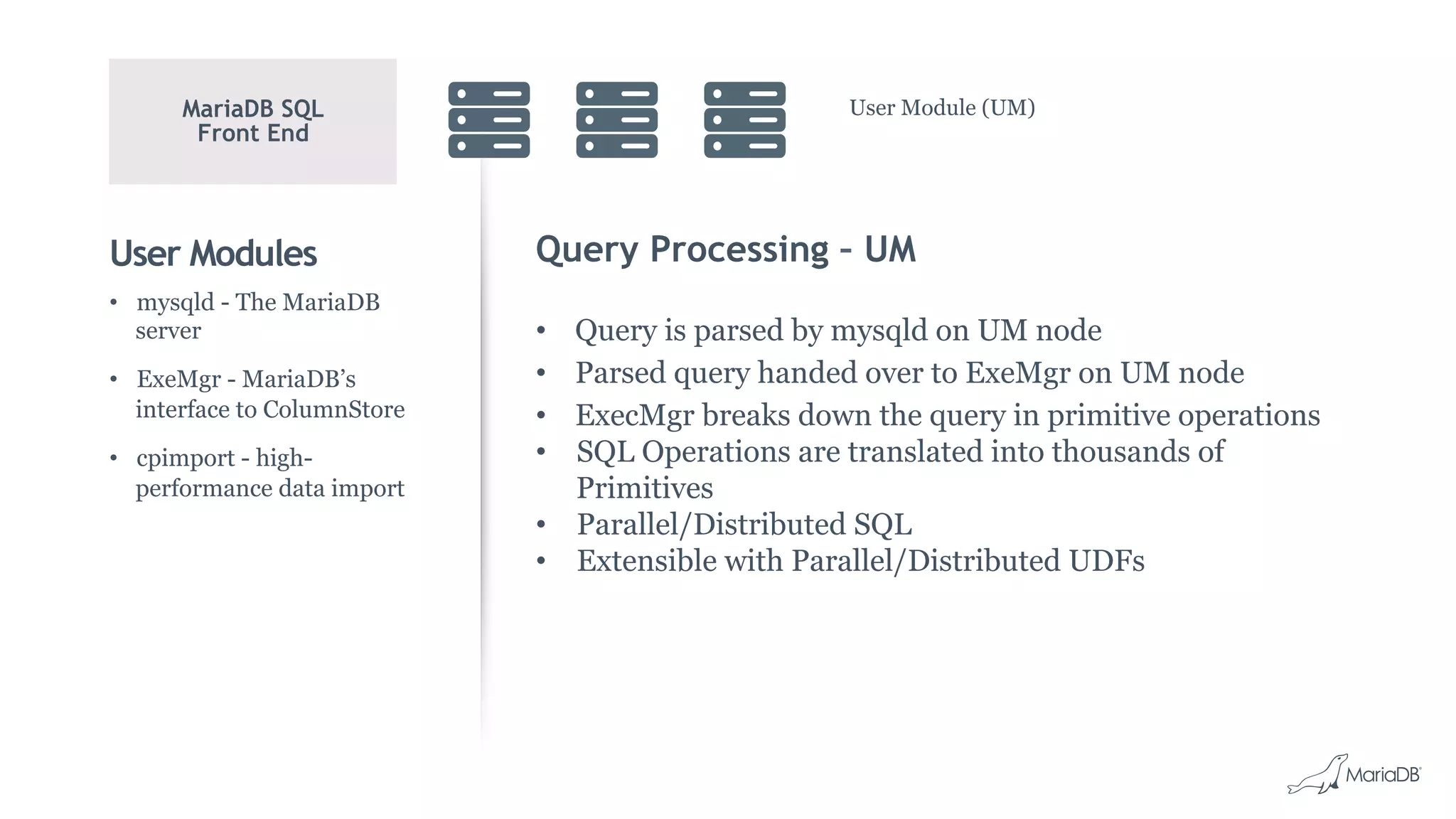
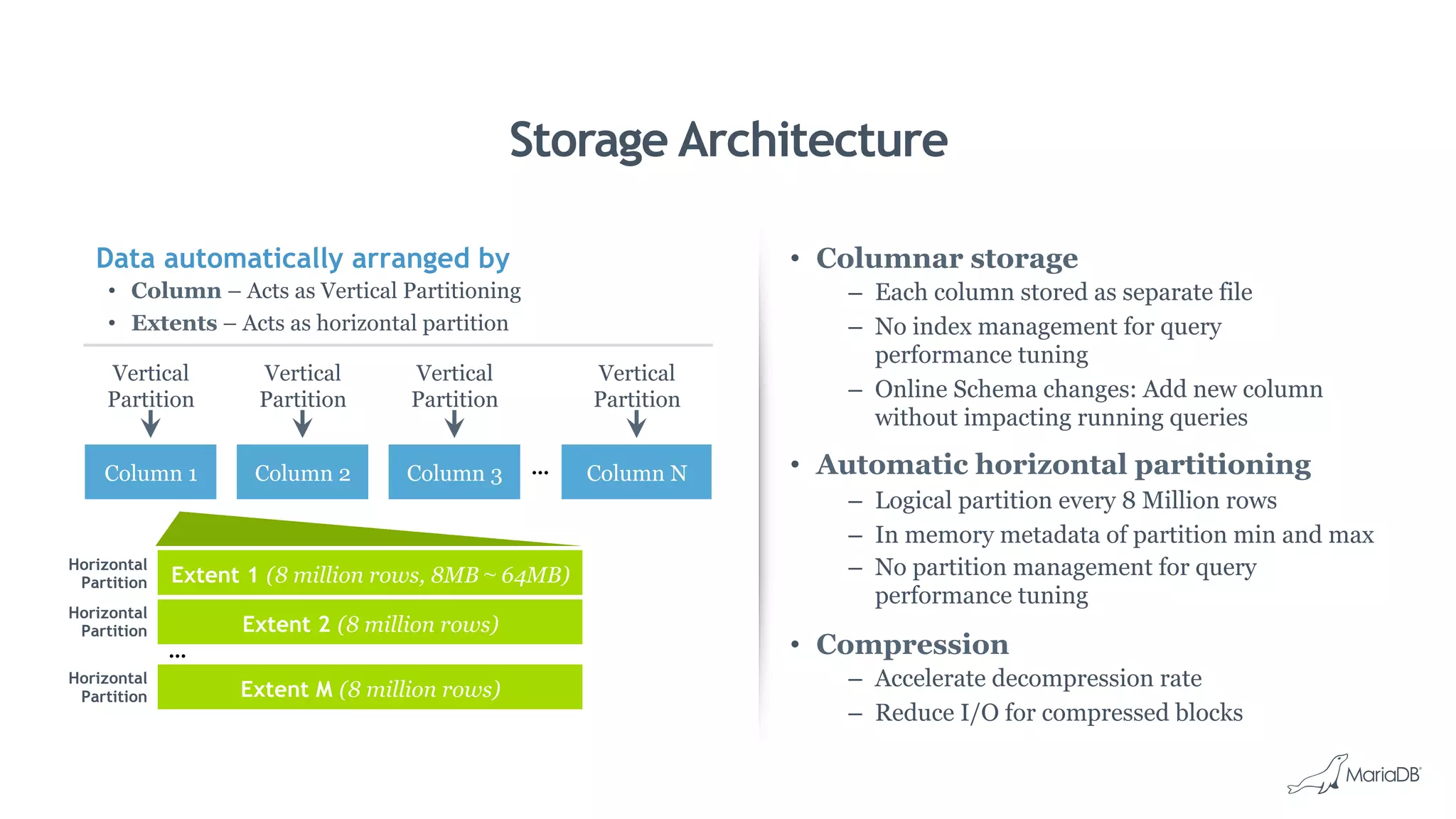
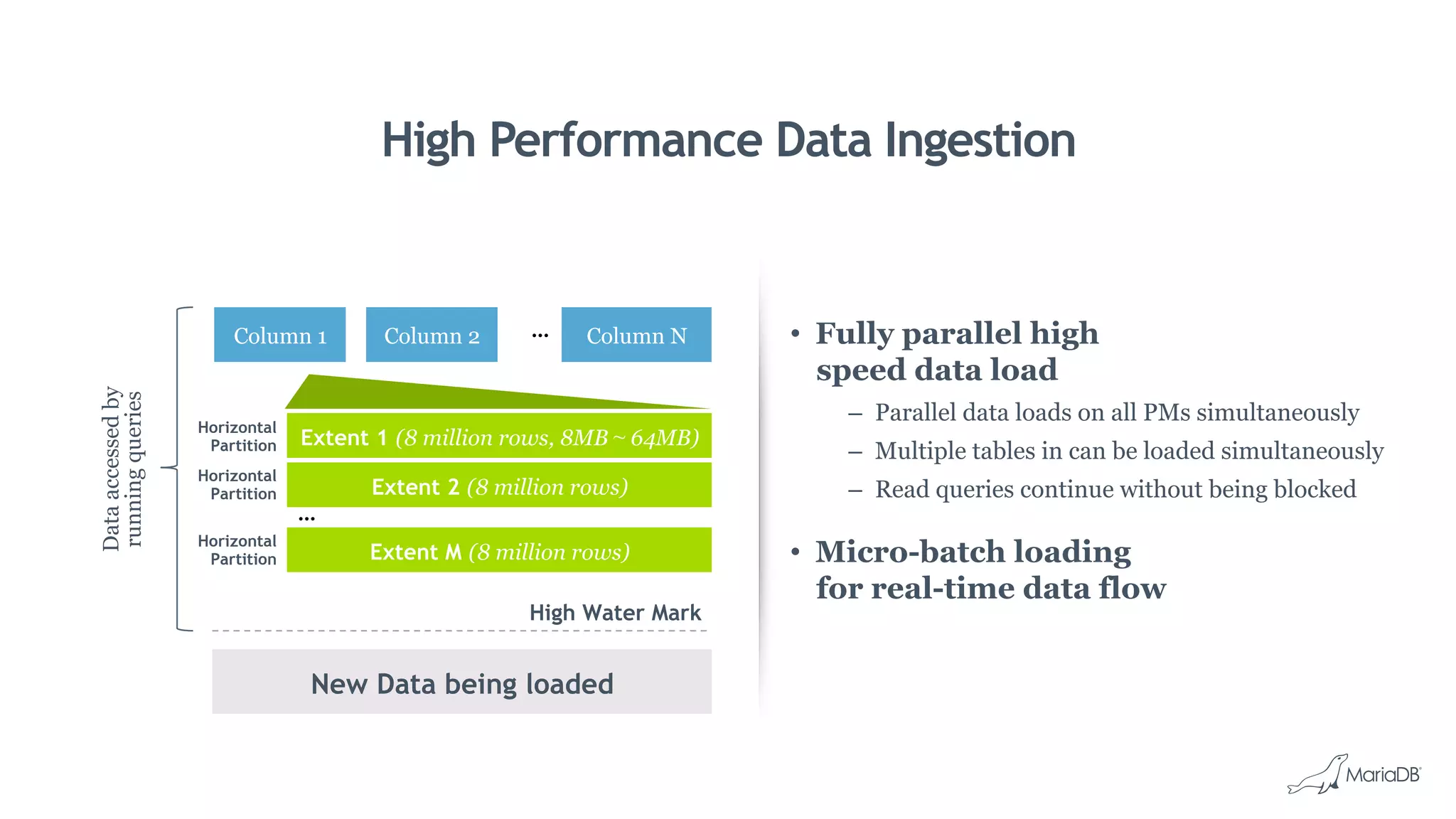
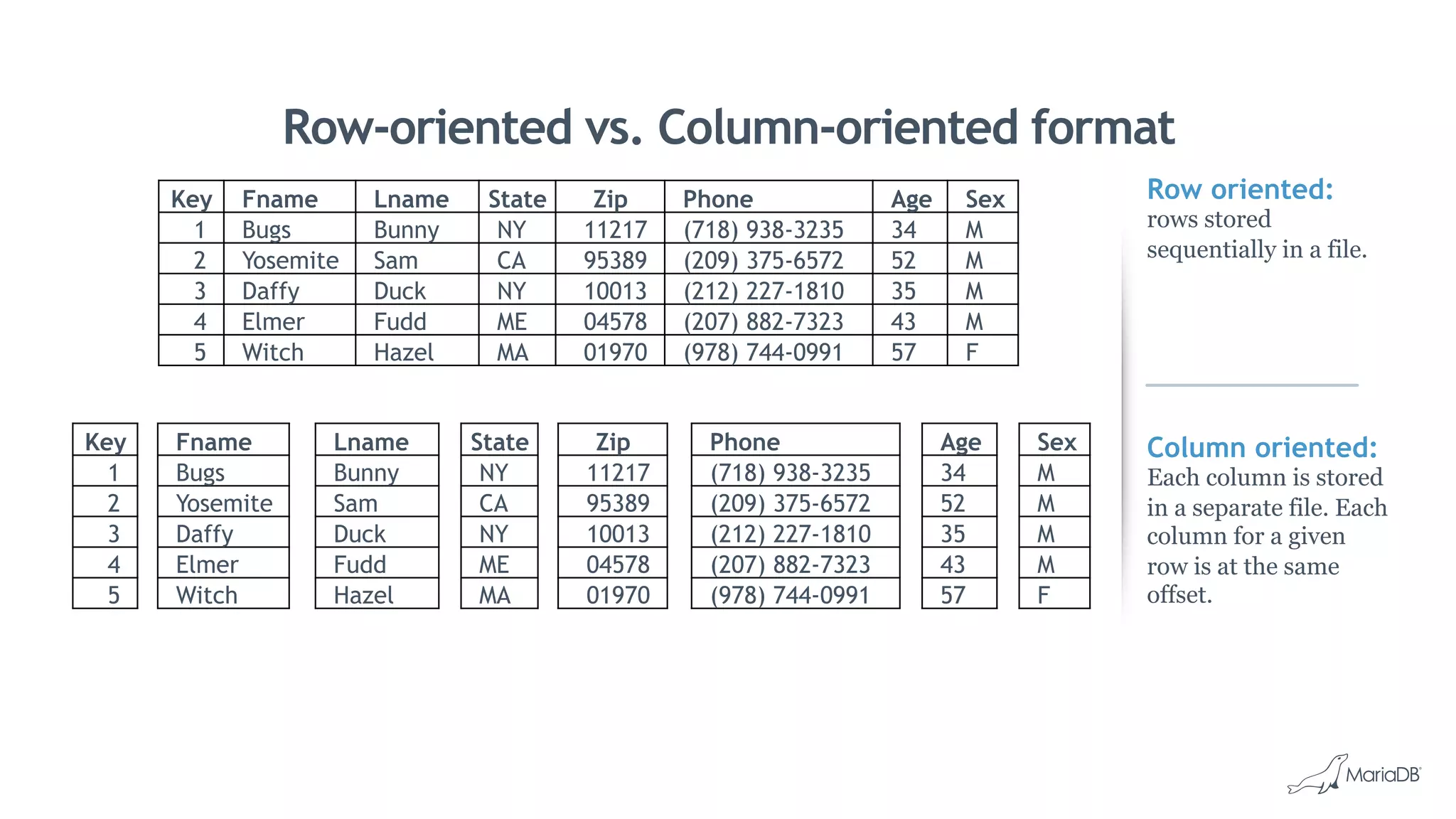
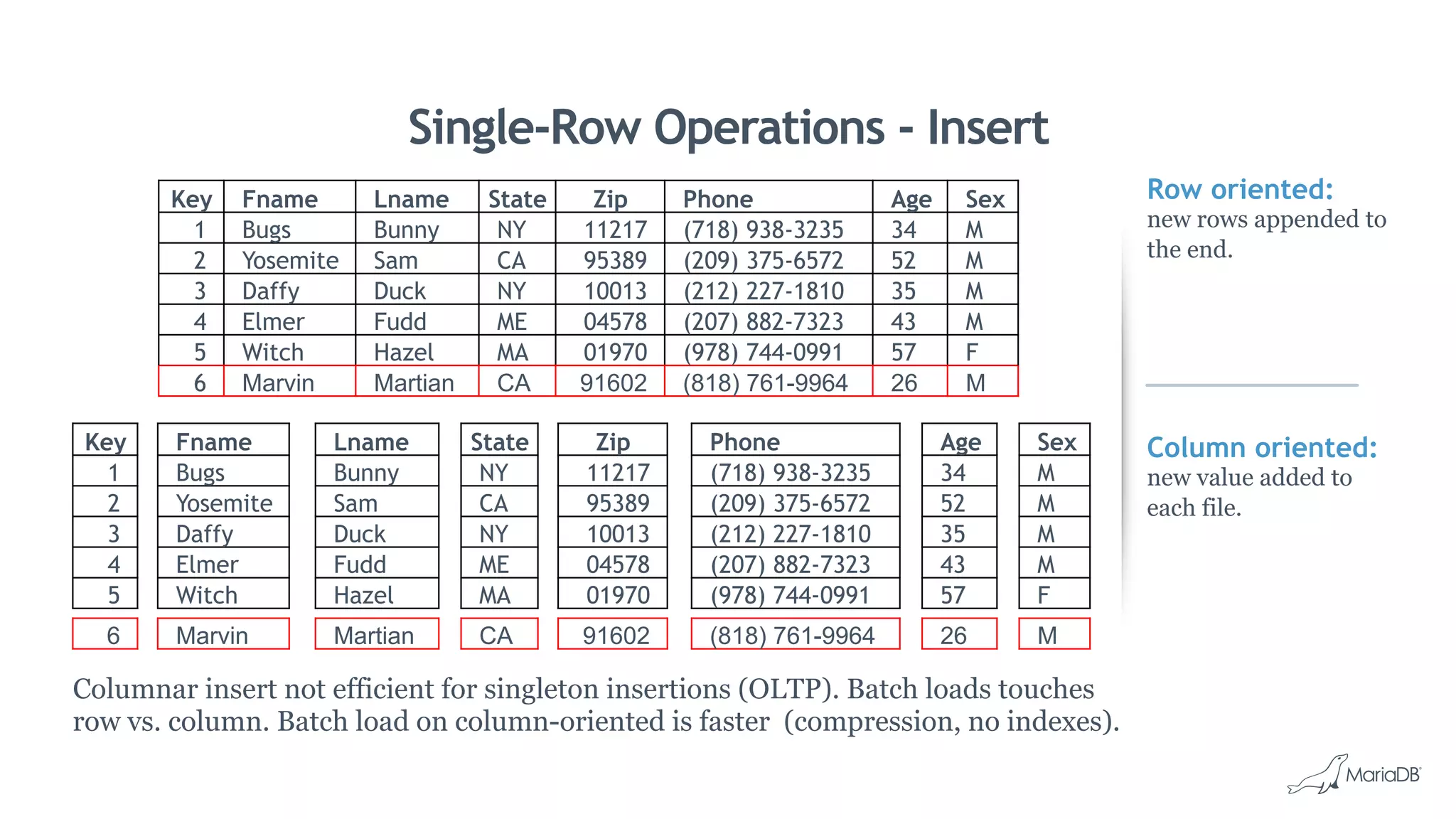
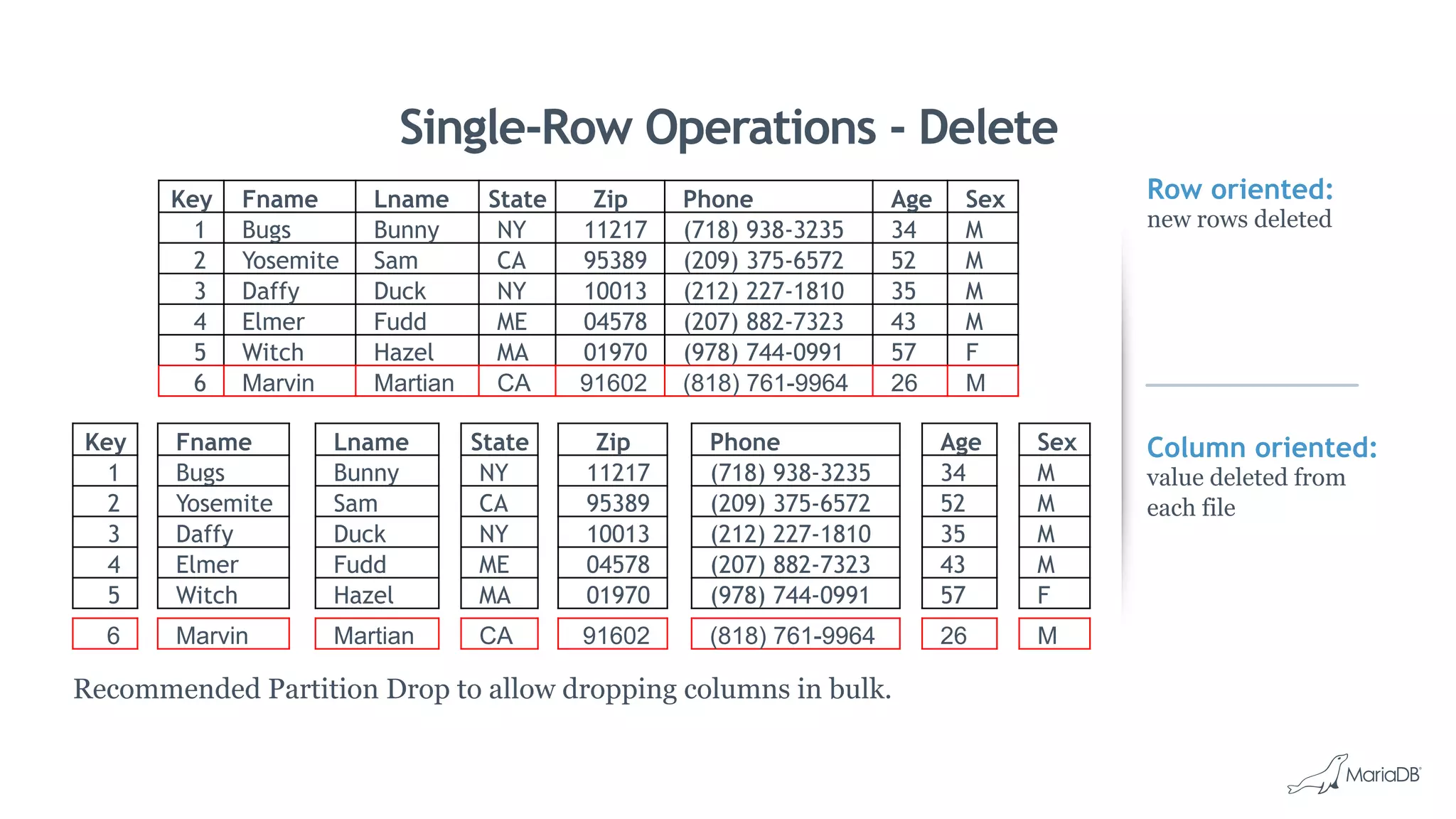
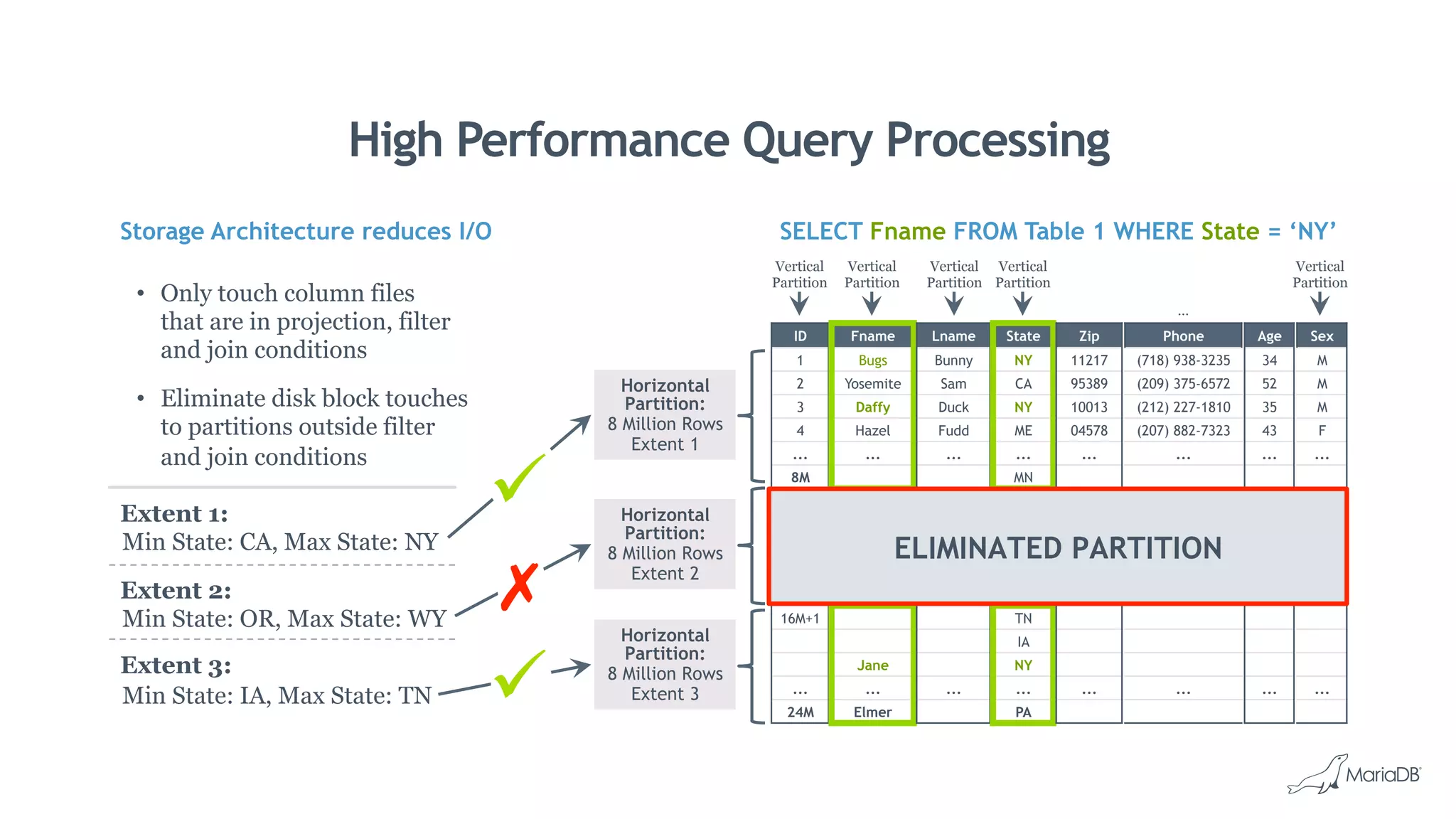
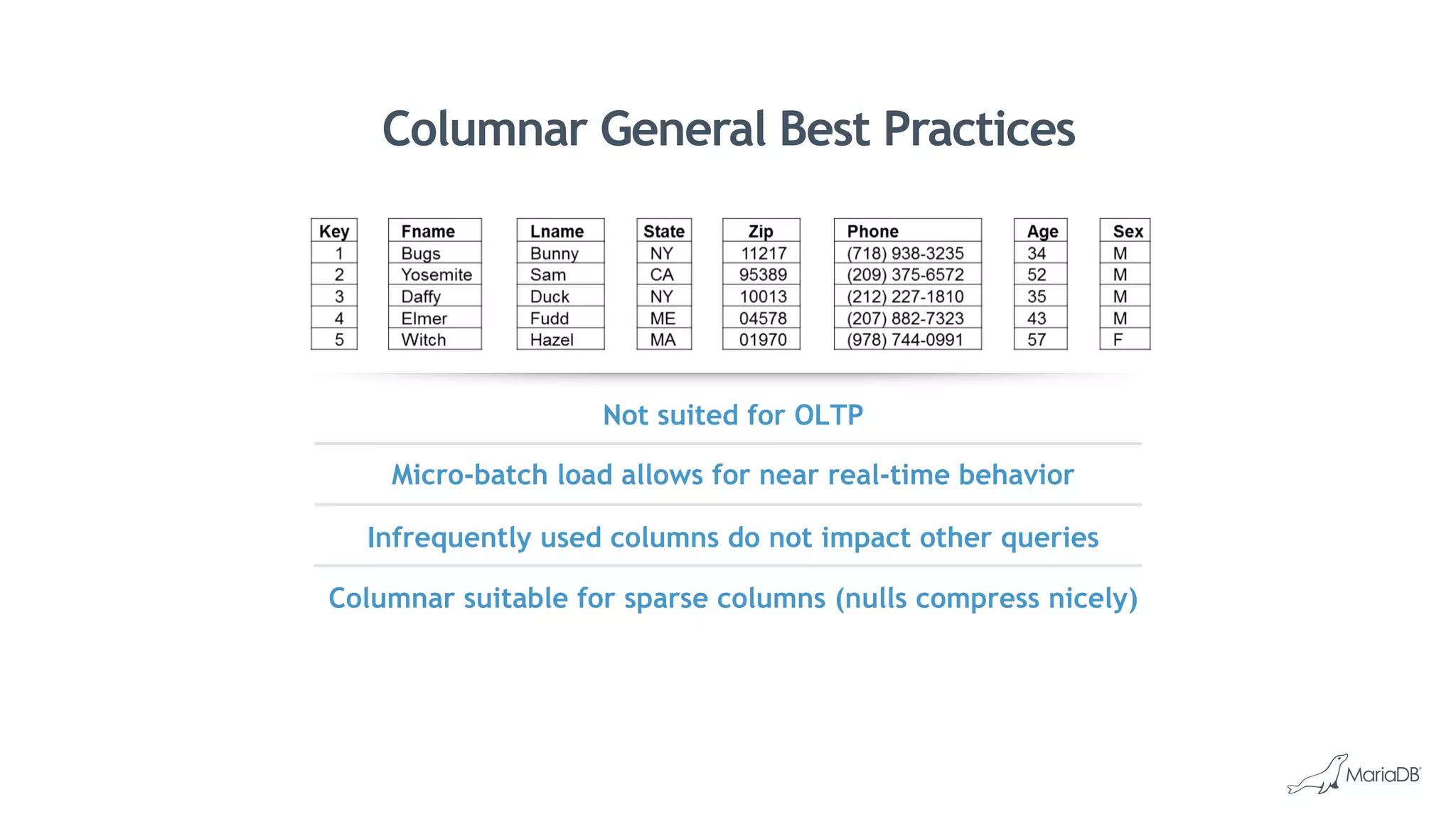
MariaDB ColumnStore is a column-oriented storage engine for MariaDB that provides massively parallel processing for analytics workloads involving large datasets. It stores each column of data as a separate file for improved performance on analytics queries. ColumnStore uses a distributed architecture that allows queries to be processed in parallel across nodes, and scales linearly as new nodes are added. It provides faster analytics than row-oriented databases through its columnar format and compression.


























![Industry Category Use Case
Gaming Behavior Analytics Projecting and predicting user behavior based on past and current data
Advertising Customer Analytics Customer behavior data for market segmentation and predictive analytics.
Advertising Loyalty Analytics Customer analytics focusing on a person’s commitment to a product, company, or brand.
Web, E-
commerce
Click Stream Analytics
Web activity analysis, software testing, market research with analytics on data about the clicks areas of web pages while
web browsing [Deal News]
Marketing Promotional Testing Using marketing and campaign management data to identify the best criteria to be used for a particular marketing offer.
Social Network Network Analytics Relationship analytics among network nodes
Financial Fraud Analytics
Monitoring user financial transactions and identifying patterns of behaviour to predict and detect abnormal or
fraudulent activity to prevent damage to user and institution.
Healthcare Patient Analytics Analyzing patient medical records to identify patterns to be used for improved medical treatment.
Healthcare Clinical Analytics Analyzing clinical data and its impact on patients to identify patterns to be used for improved medical treatment.
Telco
Network and Application
Performance Analytics
Streaming data from network devices and applications enriched with business operations data to uncover actionable
insights for network planning, operations and marketing analytics
Aviation Flight analytics
Proactively project parts replacement, maintenance and air-plane retirement based on real-time and historically
collected flight parameter data [Boeing]
Customer Use Cases](https://image.slidesharecdn.com/042017emearoadshowmilanmariadbcolumnstore-170511203815/75/04-2017-emea_roadshowmilan_mariadb-columnstore-43-2048.jpg)

























![[db tech showcase Tokyo 2017] C37: MariaDB ColumnStore analytics engine : use...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstoreusecases1-170911080447-thumbnail.jpg?width=640&height=640&fit=bounds)








![[db tech showcase OSS 2017] A25: Replacing Oracle Database at DBS Bank by Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628030047-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A23: Analytics with MariaDB ColumnStore by MariaD...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628024921-thumbnail.jpg?width=640&height=640&fit=bounds)



























