


















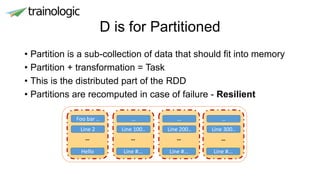



![Example
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint(checkpoint.toString())
val dstream: DStream[Int] =
ssc.textFileStream(s"file://$folder/").map(_.trim.toInt)
dstream.print()
ssc.start()
ssc.awaitTermination()](https://image.slidesharecdn.com/0dfuuwwfqbmy9bij4oha-signature-27b3b313f112532fd24e7fa8fdfd0f39d25921d6241d5d791077eefaf35afca1-poli-170628142455/85/Stream-processing-from-single-node-to-a-cluster-24-320.jpg)

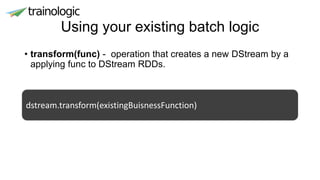
![Updating the state
• All the operations so far didn't have state
• How do I accumulate results with the current batch?
• updateStateByKey(updateFunc) – a transformation that
creates a new DStream with key-value where the value is
updated according to the state and the new values.
def updateFunction(newValues: Seq[Int], count: Option[Int]): Option[Int] = {
runningCount.map(_ + newValues.sum).orElse(Some(newValues.sum))
}](https://image.slidesharecdn.com/0dfuuwwfqbmy9bij4oha-signature-27b3b313f112532fd24e7fa8fdfd0f39d25921d6241d5d791077eefaf35afca1-poli-170628142455/85/Stream-processing-from-single-node-to-a-cluster-27-320.jpg)







The document discusses stream processing, highlighting its definition, challenges, and solutions such as reactive streams and implementations with Akka Streams and Spark Streaming. It explains different processing techniques like synchronous and asynchronous processing, as well as the use of graphs in Akka Streams to handle data effectively. Additionally, it details the micro-batching approach in Spark Streaming, focusing on its versatility and fault tolerance through checkpoints.




































![Introduction to Akka Streams [Part-I]](https://cdn.slidesharecdn.com/ss_thumbnails/babystepsinakkastreampart-i-171117070802-thumbnail.jpg?width=640&height=640&fit=bounds)






























