

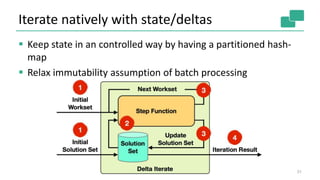
![Program compilation
4
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
Master
Workers
Data Source
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow Graph
Independent of
batch or
streaming job
deploy
operators
track
intermediate
results
Layered Architecture
allows plugging of
components](https://image.slidesharecdn.com/june10145pmdataartisanstzoumasmetzger-150619220955-lva1-app6892/85/Apache-Flink-Deep-Dive-4-320.jpg)



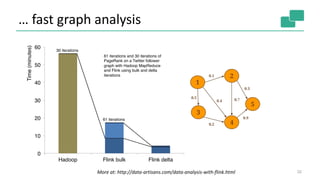
![Expressive APIs
13
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ").map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ").map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/june10145pmdataartisanstzoumasmetzger-150619220955-lva1-app6892/85/Apache-Flink-Deep-Dive-13-320.jpg)


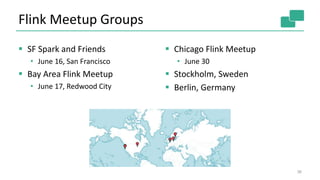
![Optimizer
Cost-based optimizer
Select data shipping strategy (forward, partition, broadcast)
Local execution (sort merge join/hash join)
Caching of loop invariant data (iterations)
19
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type extraction
stack
Pre-flight (Client)
Data
Source
orders.tbl
Filter
Map
DataSourc
e
lineitem.tbl
Join
Hybrid Hash
build
HT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow
Graph](https://image.slidesharecdn.com/june10145pmdataartisanstzoumasmetzger-150619220955-lva1-app6892/85/Apache-Flink-Deep-Dive-19-320.jpg)
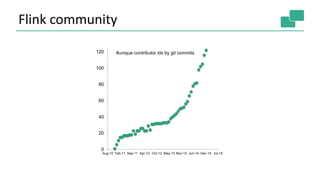
![Two execution plans
20
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
broadcast forward
Combine
GroupRed
sort
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
hash-part [0,1]
GroupRed
sort
forward
Best plan
depends on
relative sizes
of input files](https://image.slidesharecdn.com/june10145pmdataartisanstzoumasmetzger-150619220955-lva1-app6892/85/Apache-Flink-Deep-Dive-20-320.jpg)













![Two execution plans
49
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
broadcast forward
Combine
GroupRed
sort
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
hash-part [0,1]
GroupRed
sort
forwardBest plan
depends on
relative sizes
of input files](https://image.slidesharecdn.com/june10145pmdataartisanstzoumasmetzger-150619220955-lva1-app6892/85/Apache-Flink-Deep-Dive-48-320.jpg)







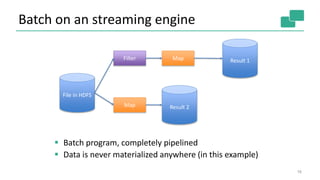
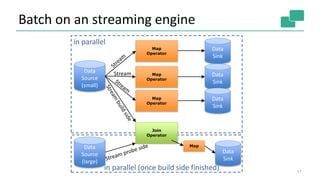
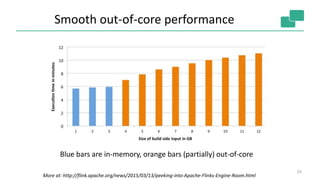
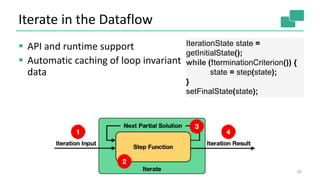
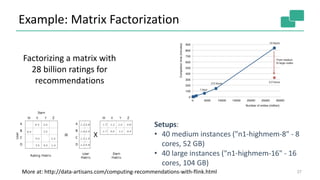
Flink provides unified batch and stream processing. It natively supports streaming dataflows, long batch pipelines, machine learning algorithms, and graph analysis through its layered architecture and treatment of all computations as data streams. Flink's optimizer selects efficient execution plans such as shipping strategies and join algorithms. It also caches loop-invariant data to speed up iterative algorithms and graph processing.




























![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)













































































