Downloaded 17 times




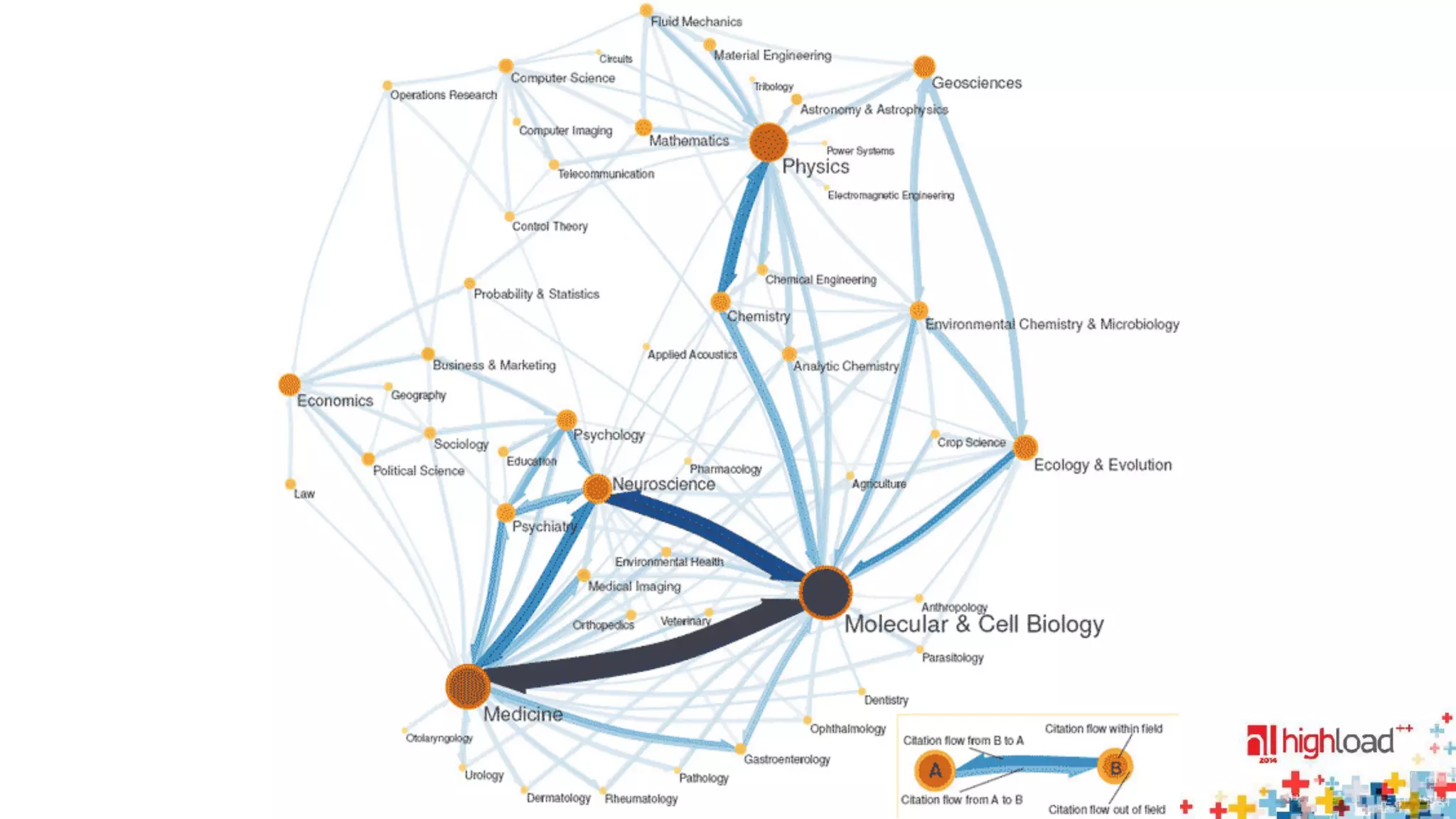



















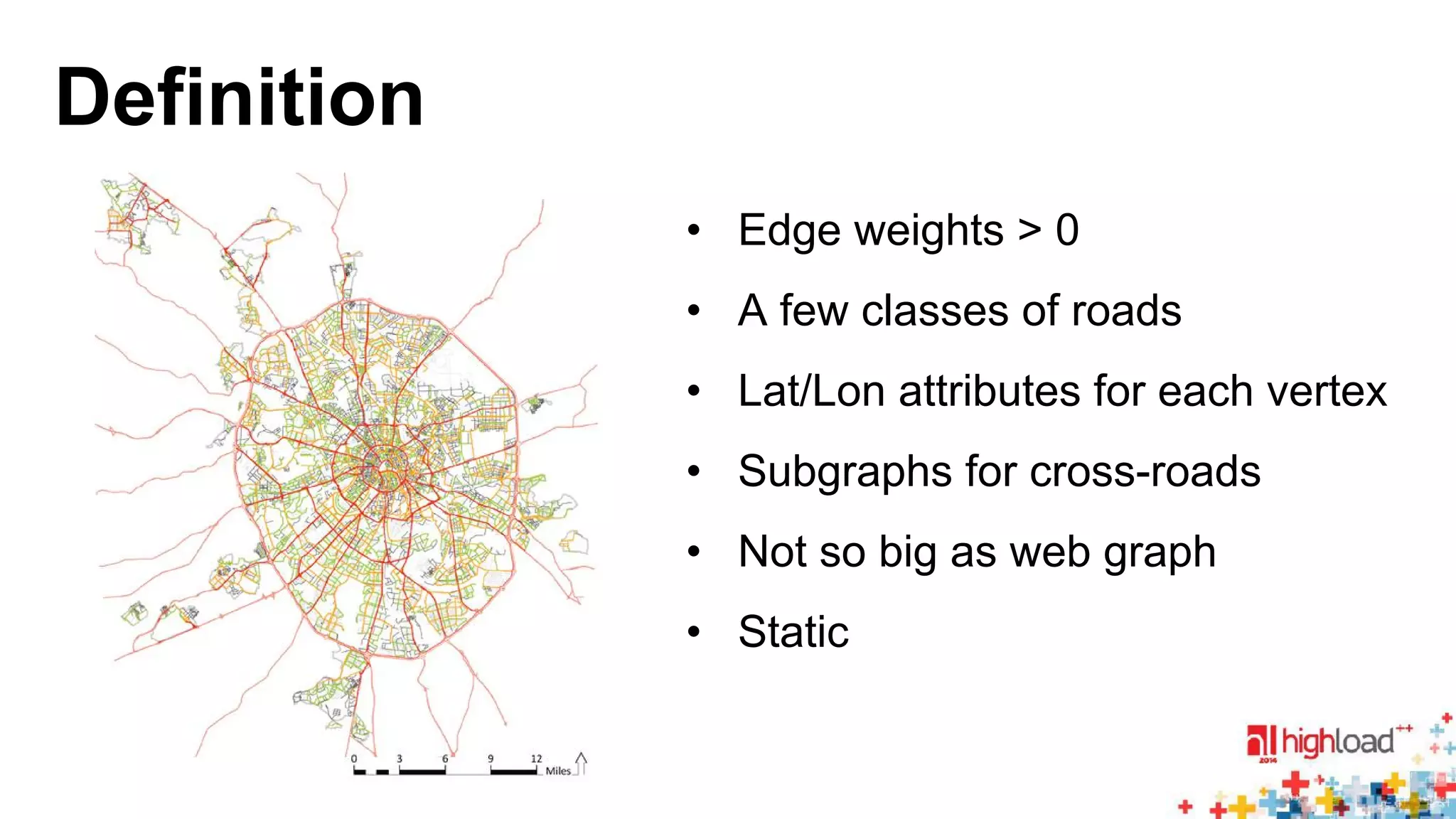
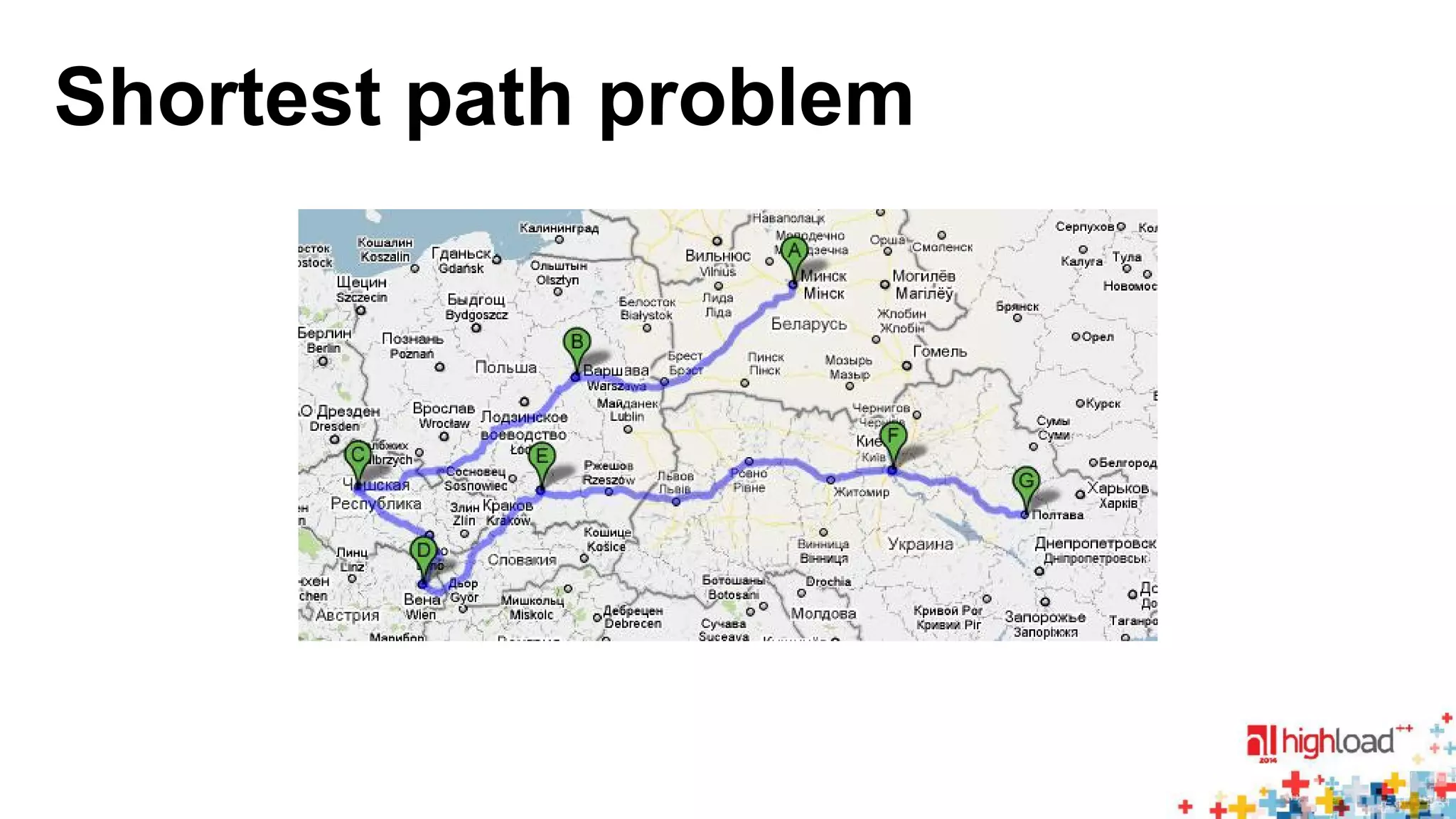



![EU Road network
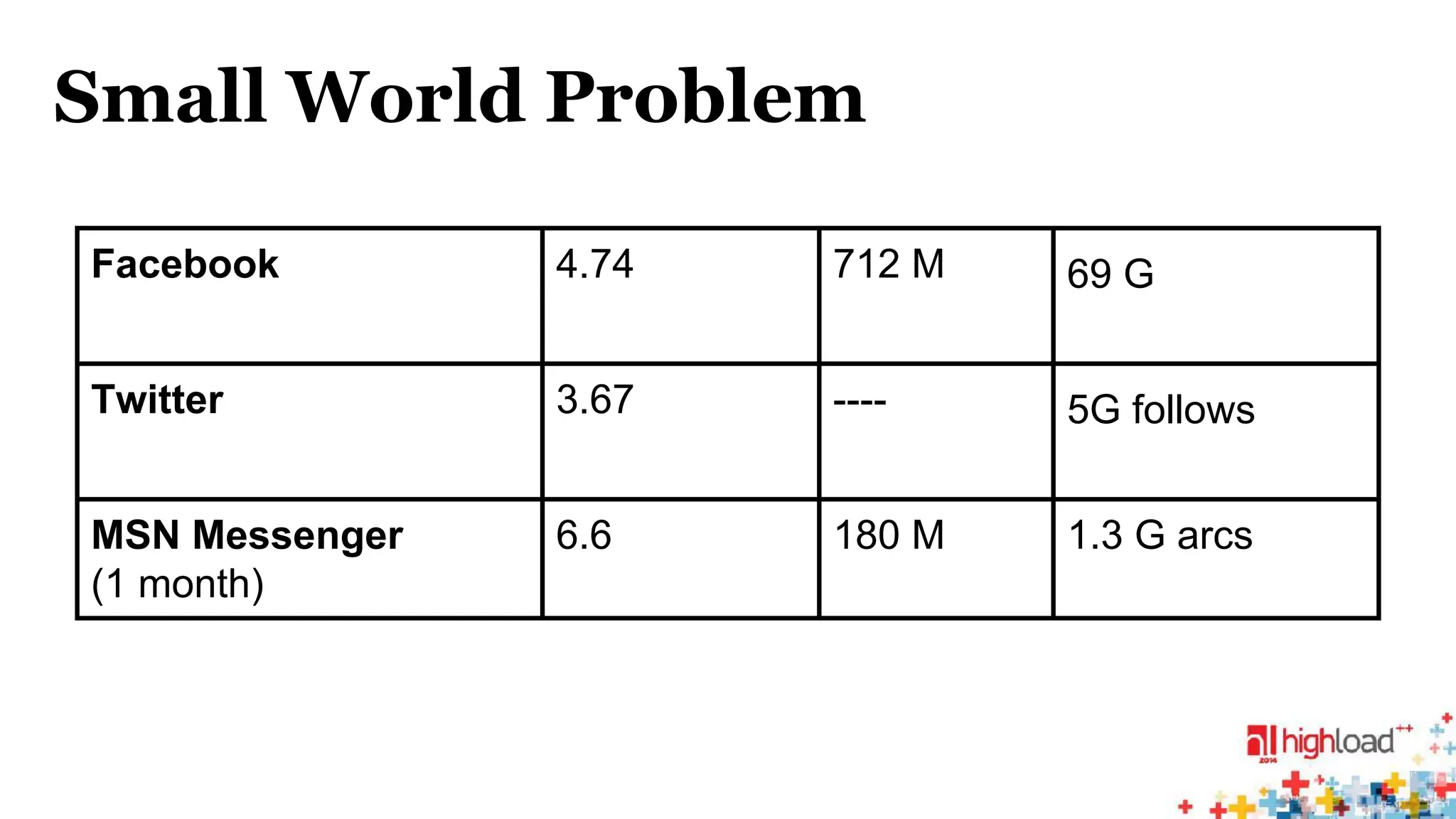
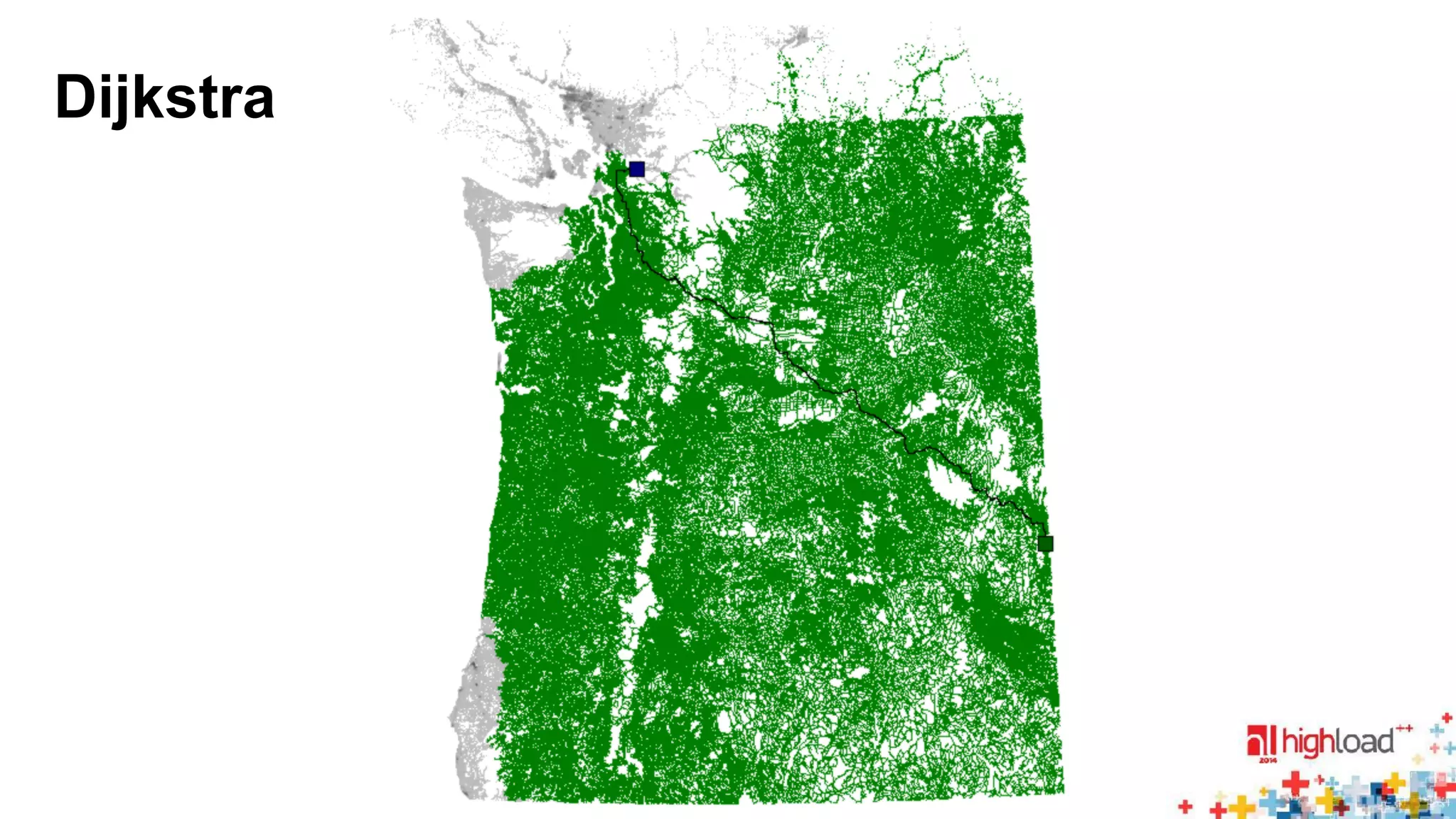
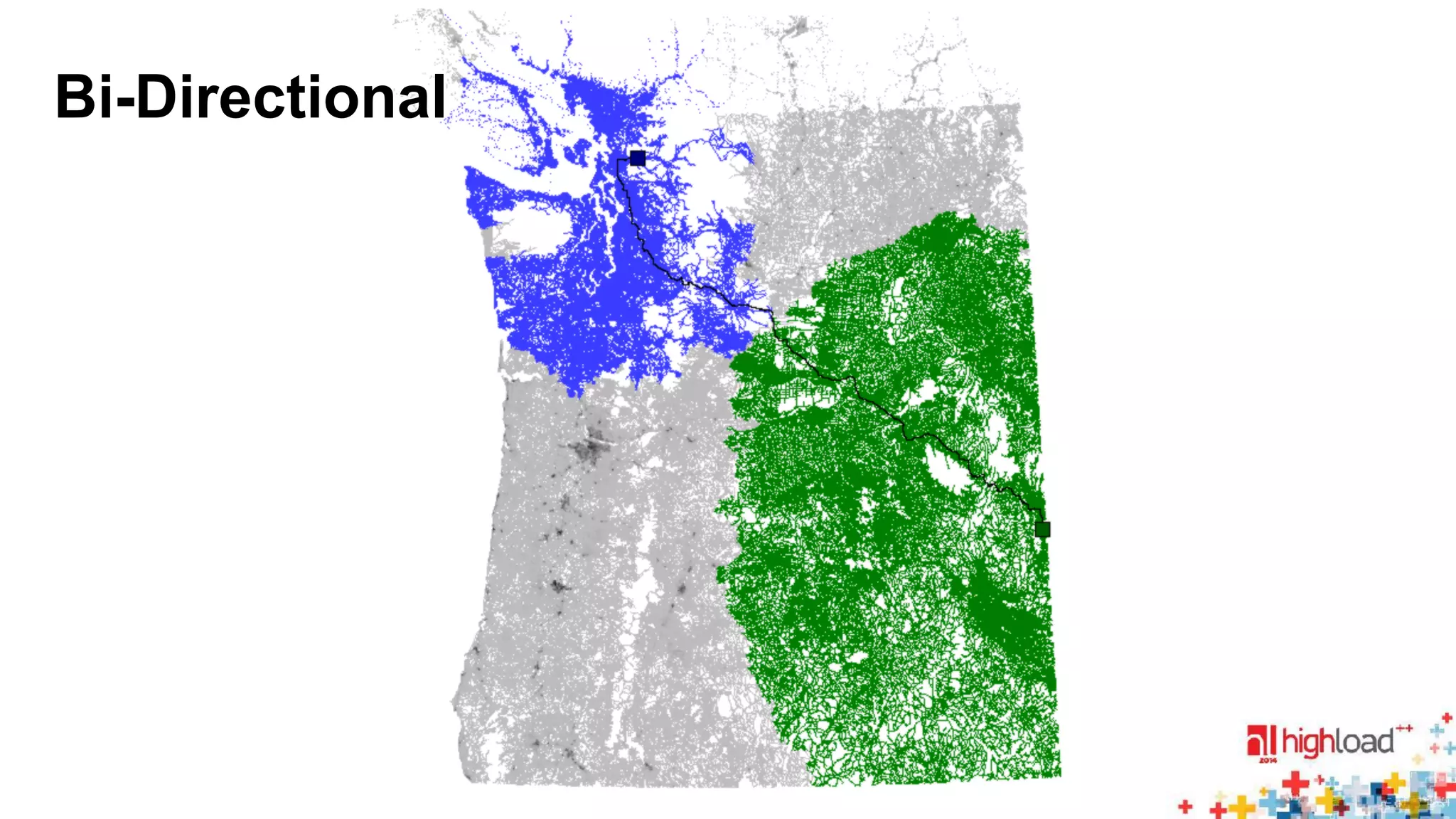
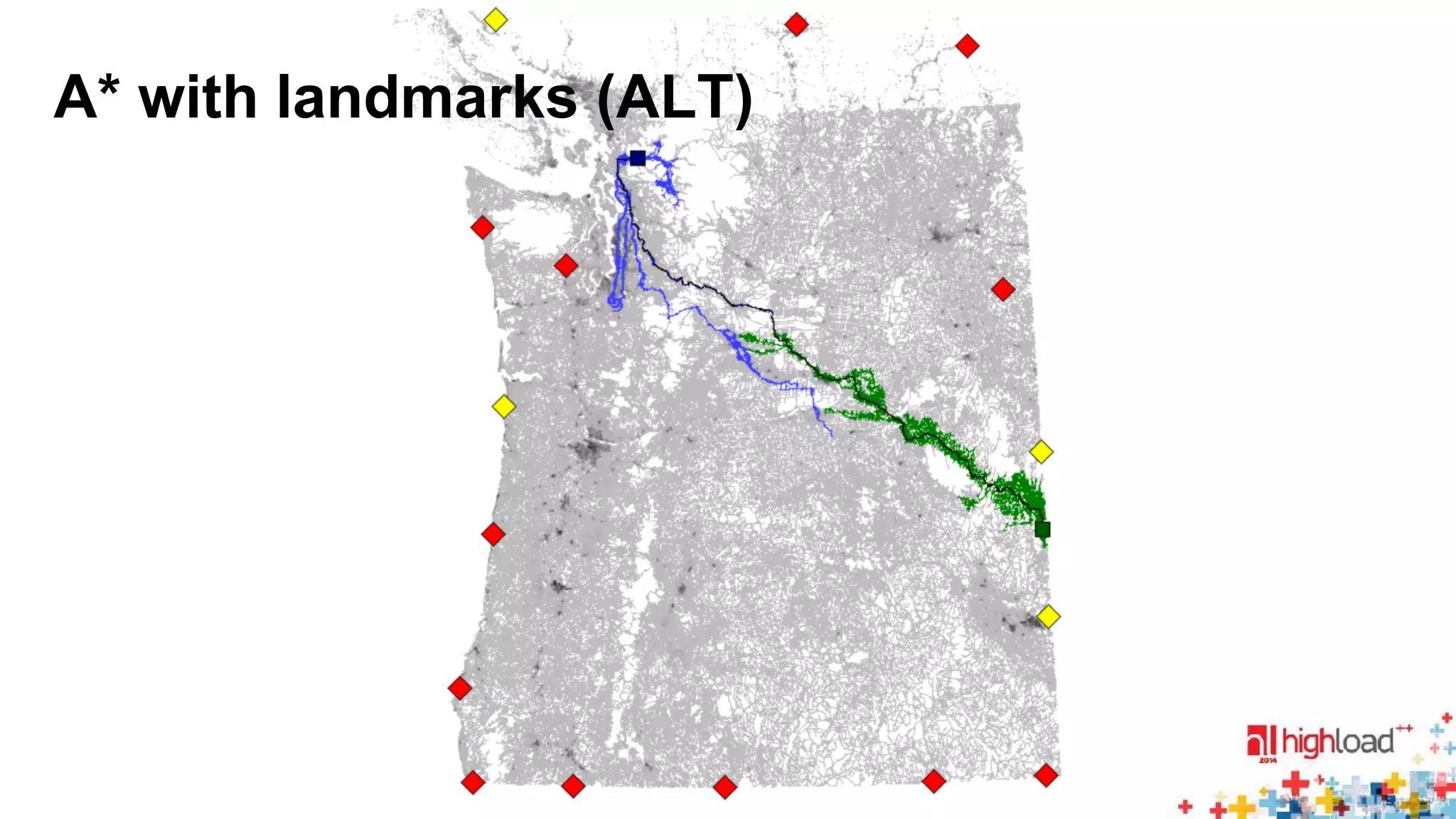
Dijkstra ALT RE HH CH TN HL
2 008 300 24 656 2444 462.0 94.0 1.8 0.3
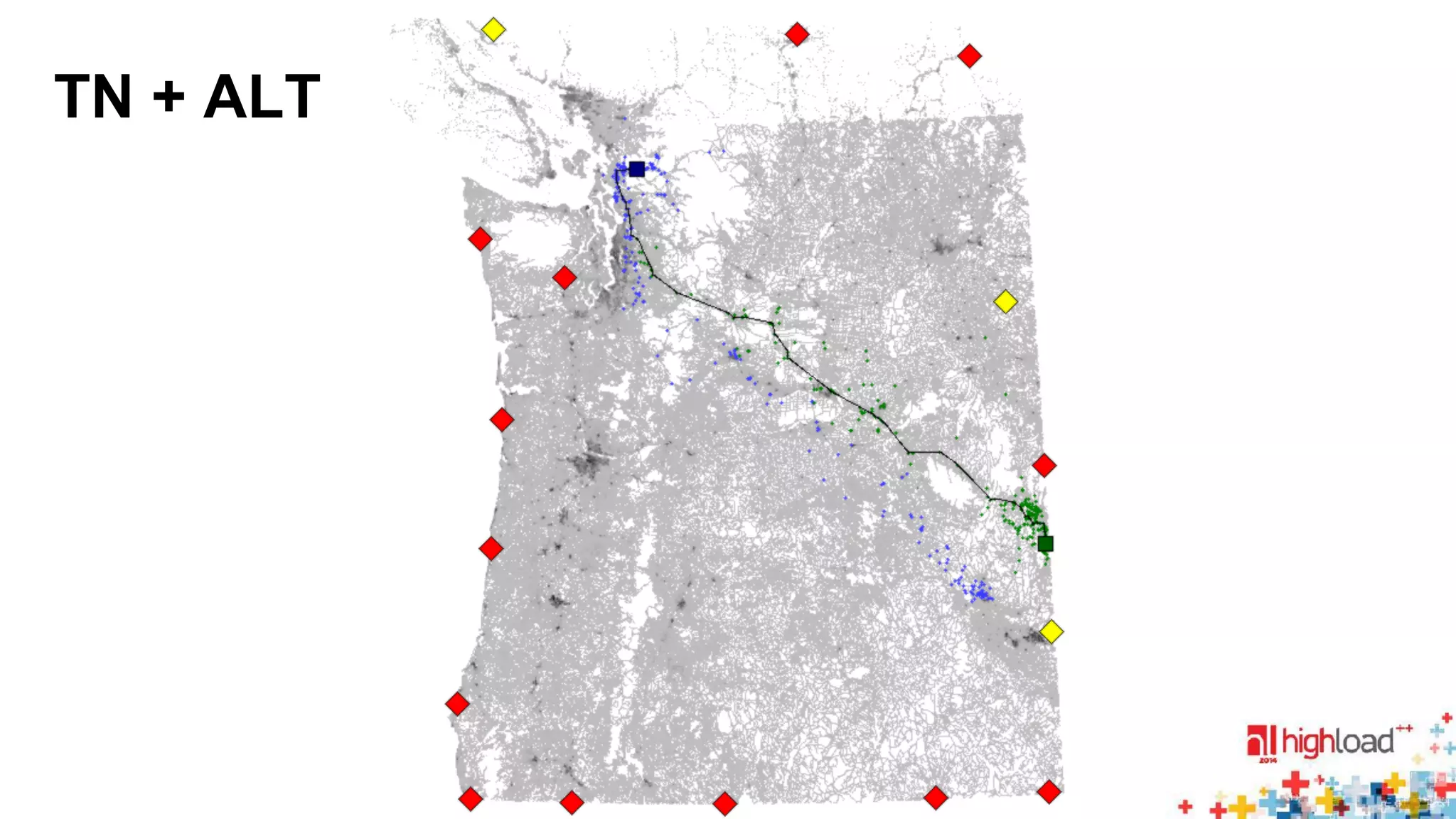
• ALT: [Goldberg & Harrelson 05], [Delling & Wagner 07]
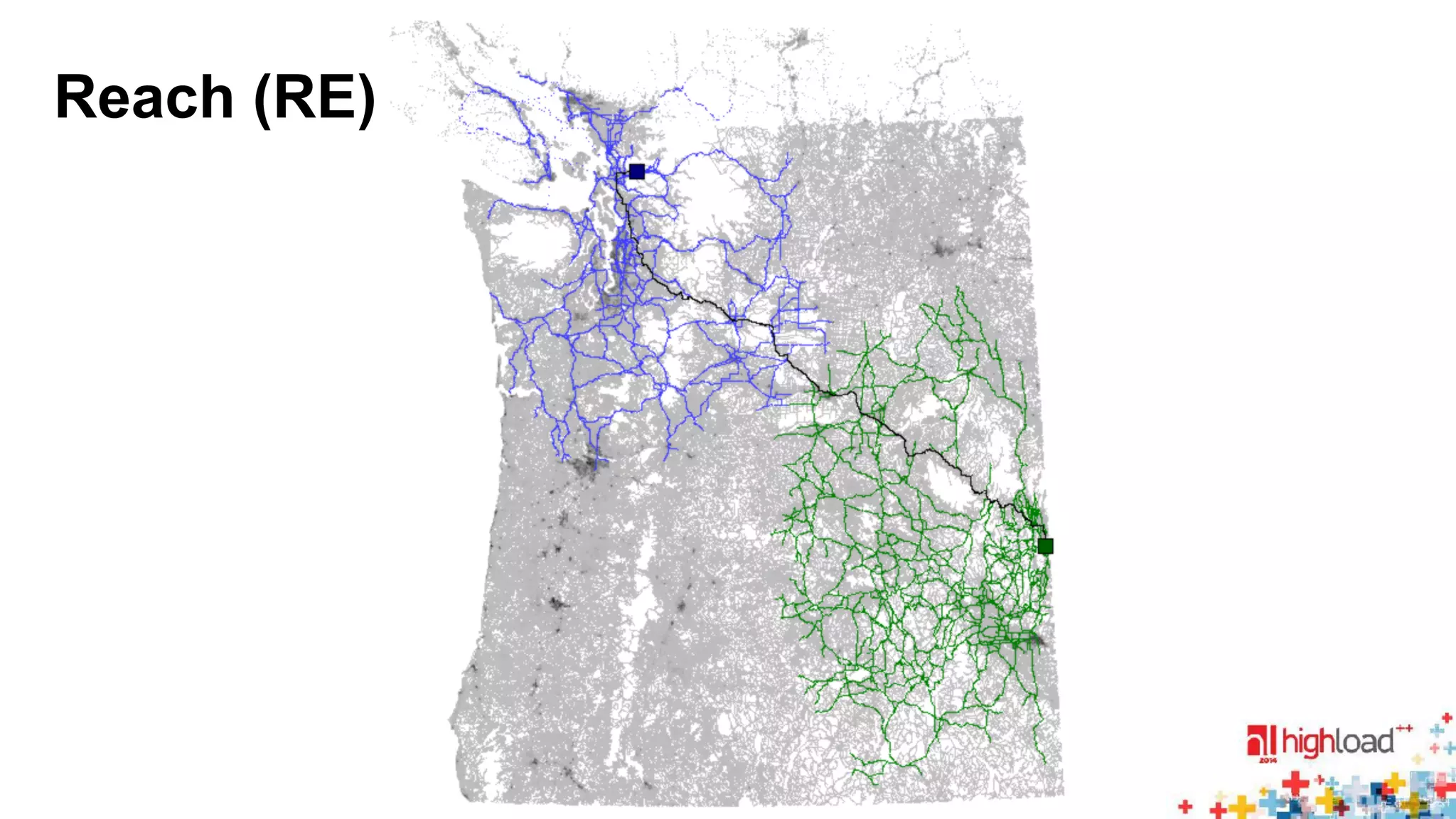
• RE: [Gutman 05], [Goldberg et al. 07]
• HH: [Sanders & Schultes 06]
• CH: [Geisberger et al. 08]
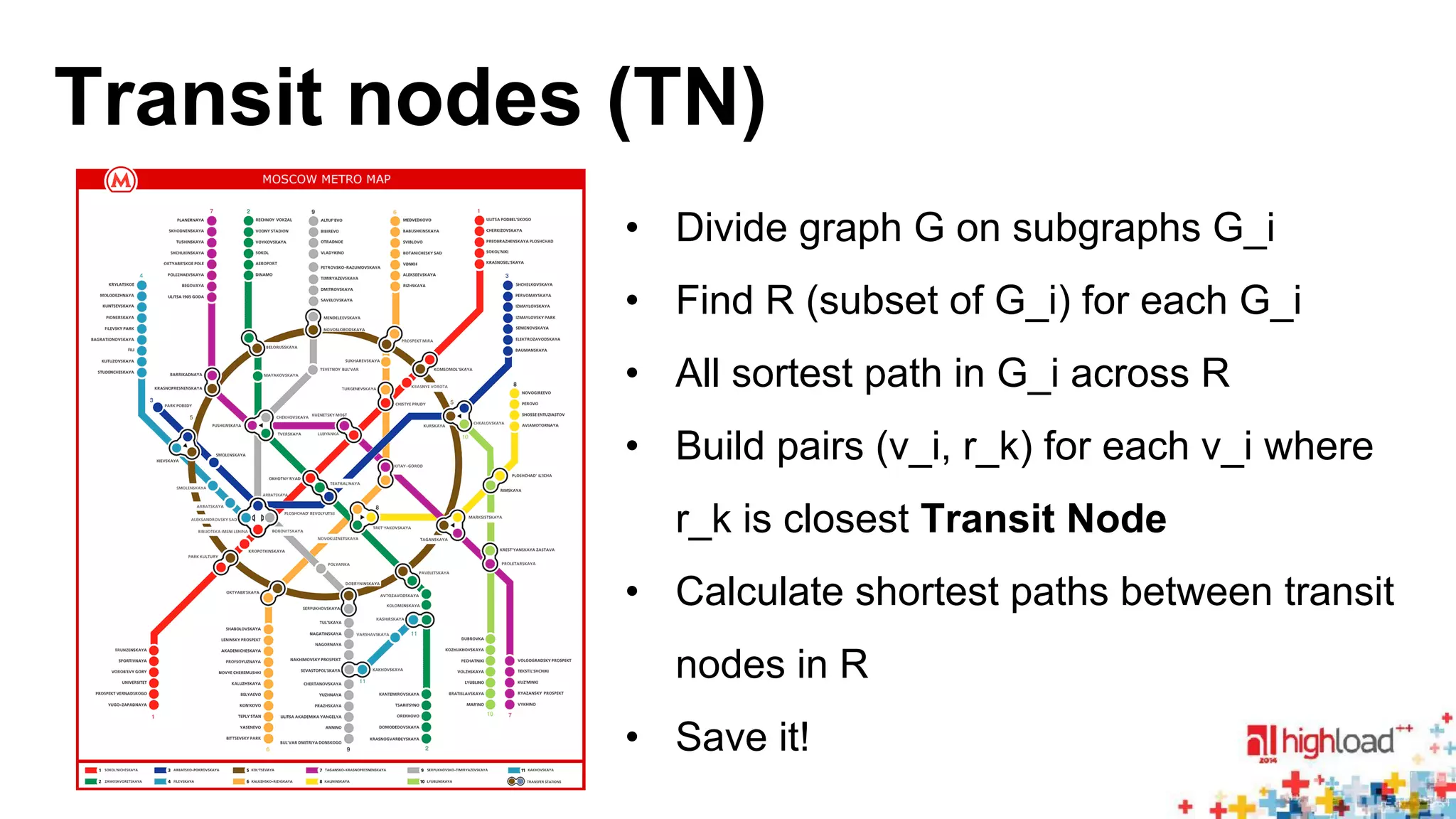
• TN: [Geisberger et al. 08]
• HL: [Abraham et al. 11]](https://image.slidesharecdn.com/thornypathtothelarge-scalegraphprocessing-141111075114-conversion-gate01/75/Thorny-Path-to-the-Large-Scale-Graph-Processing-54-2048.jpg)





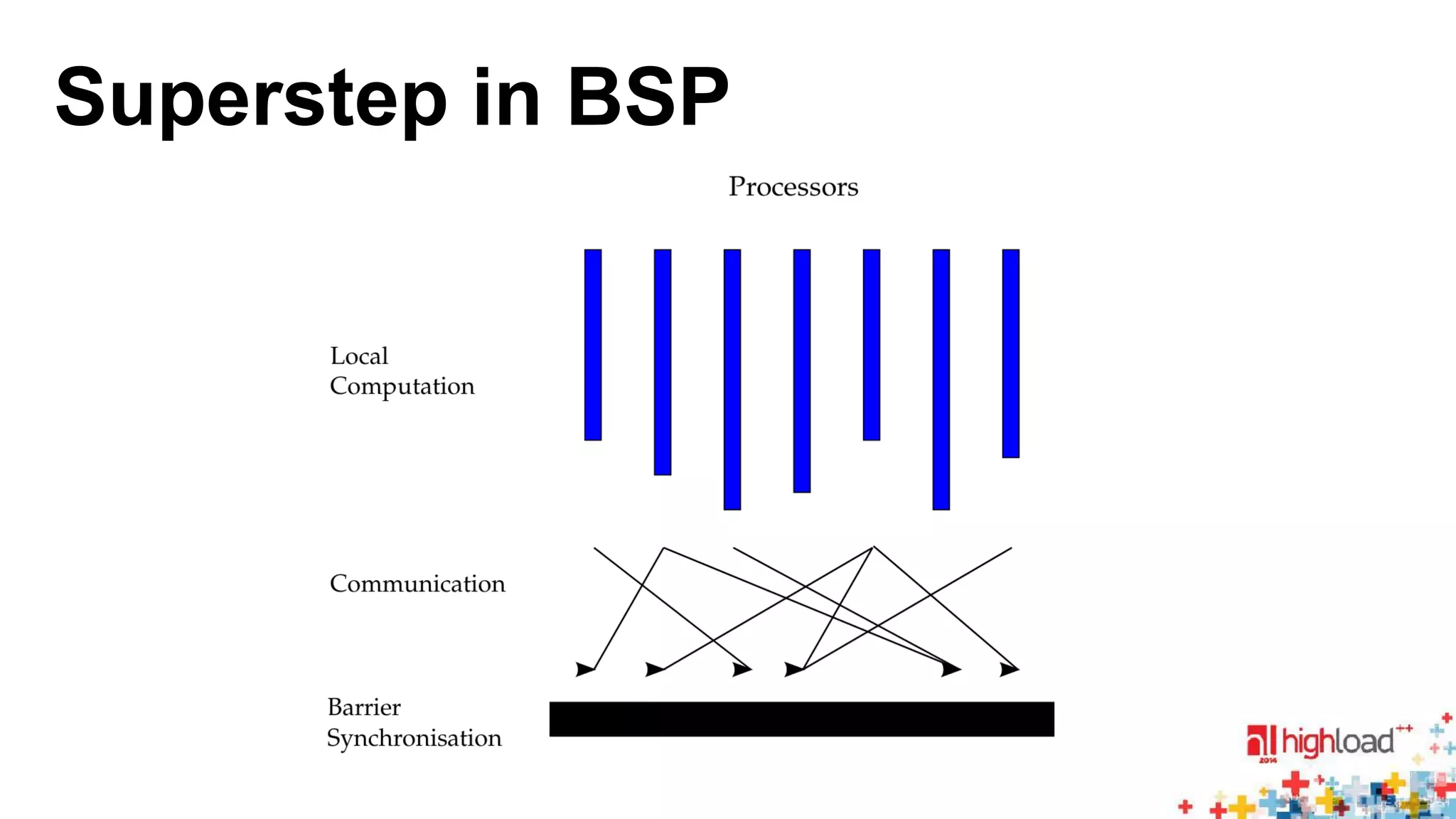
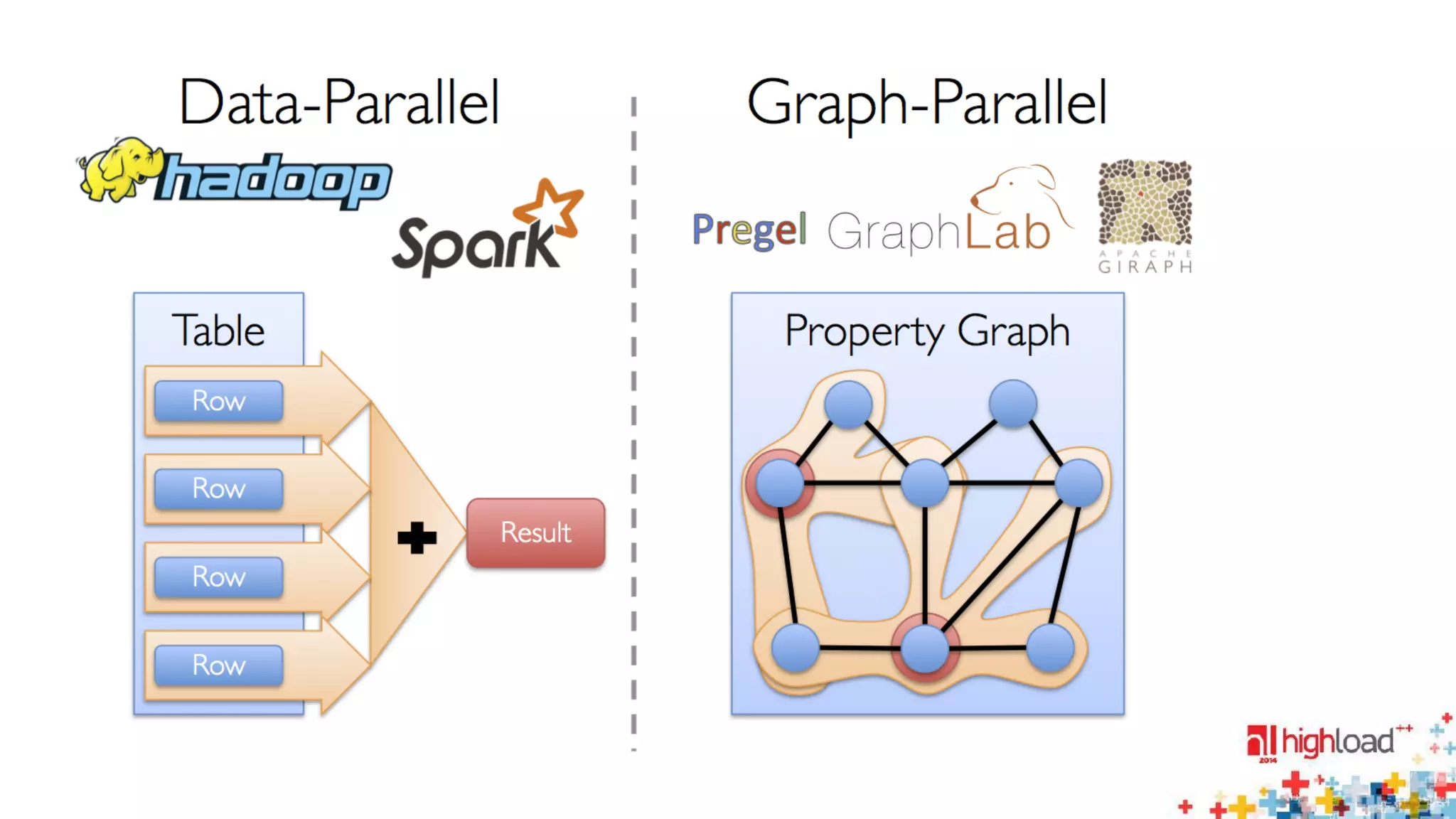
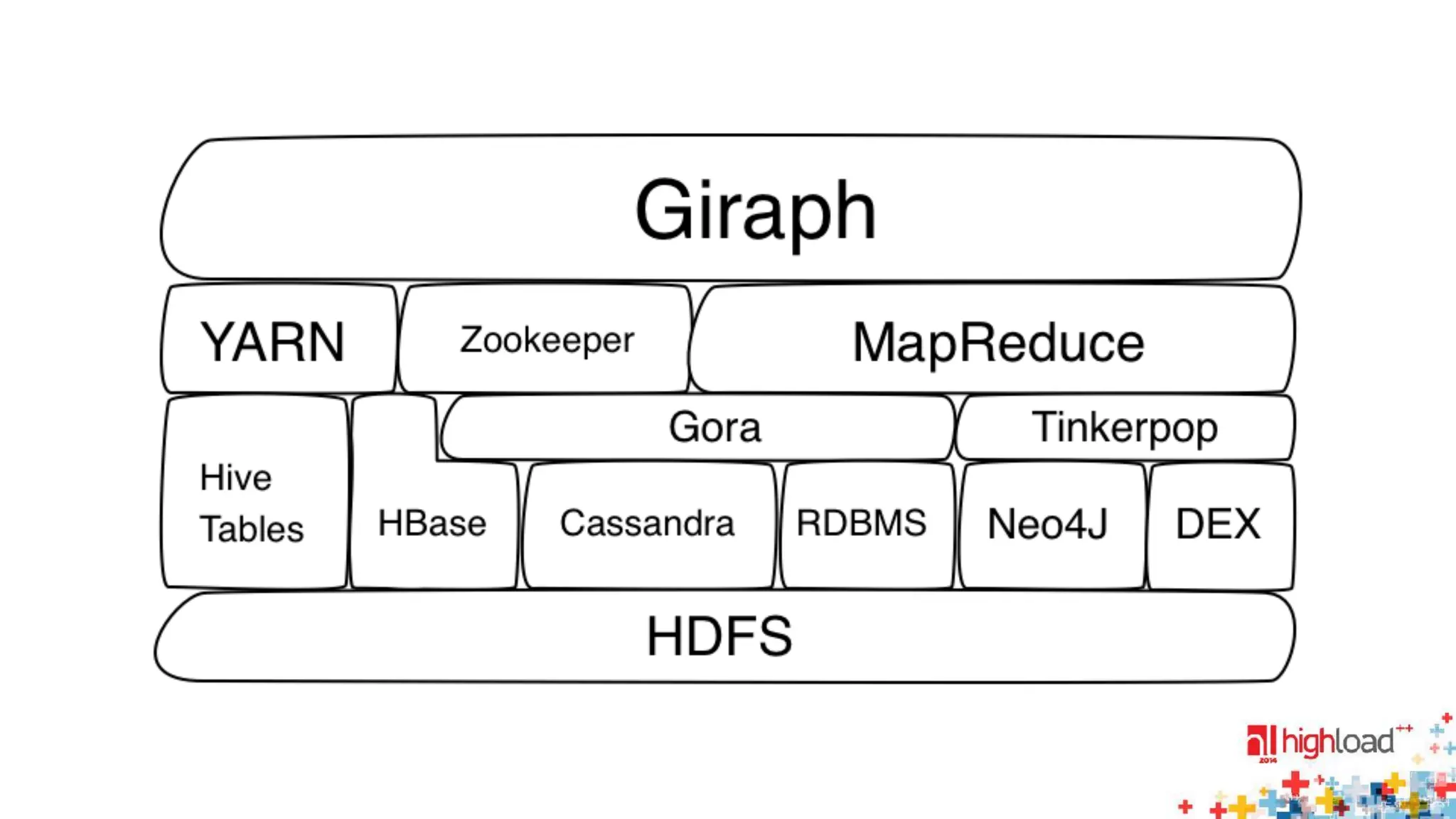
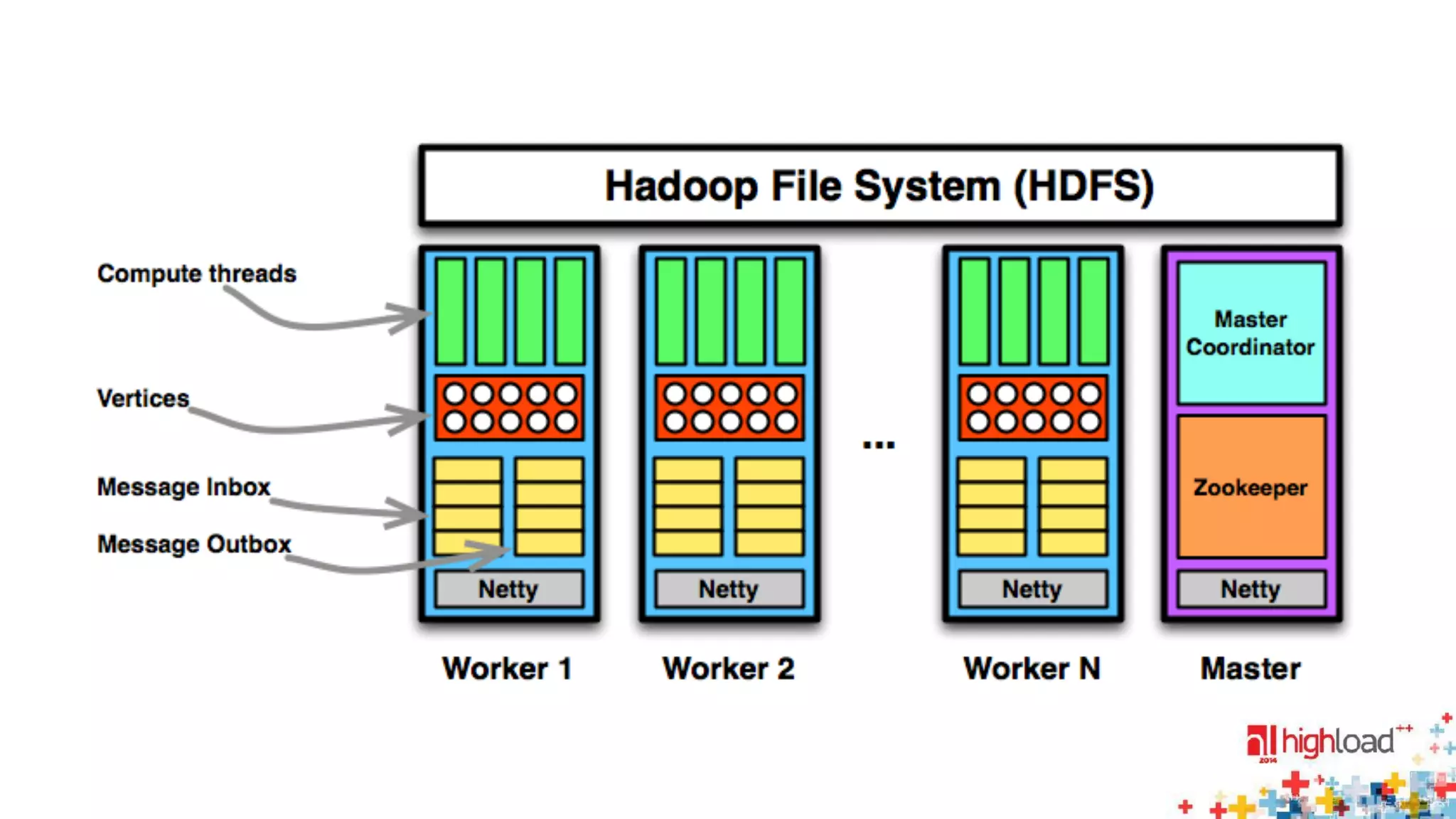
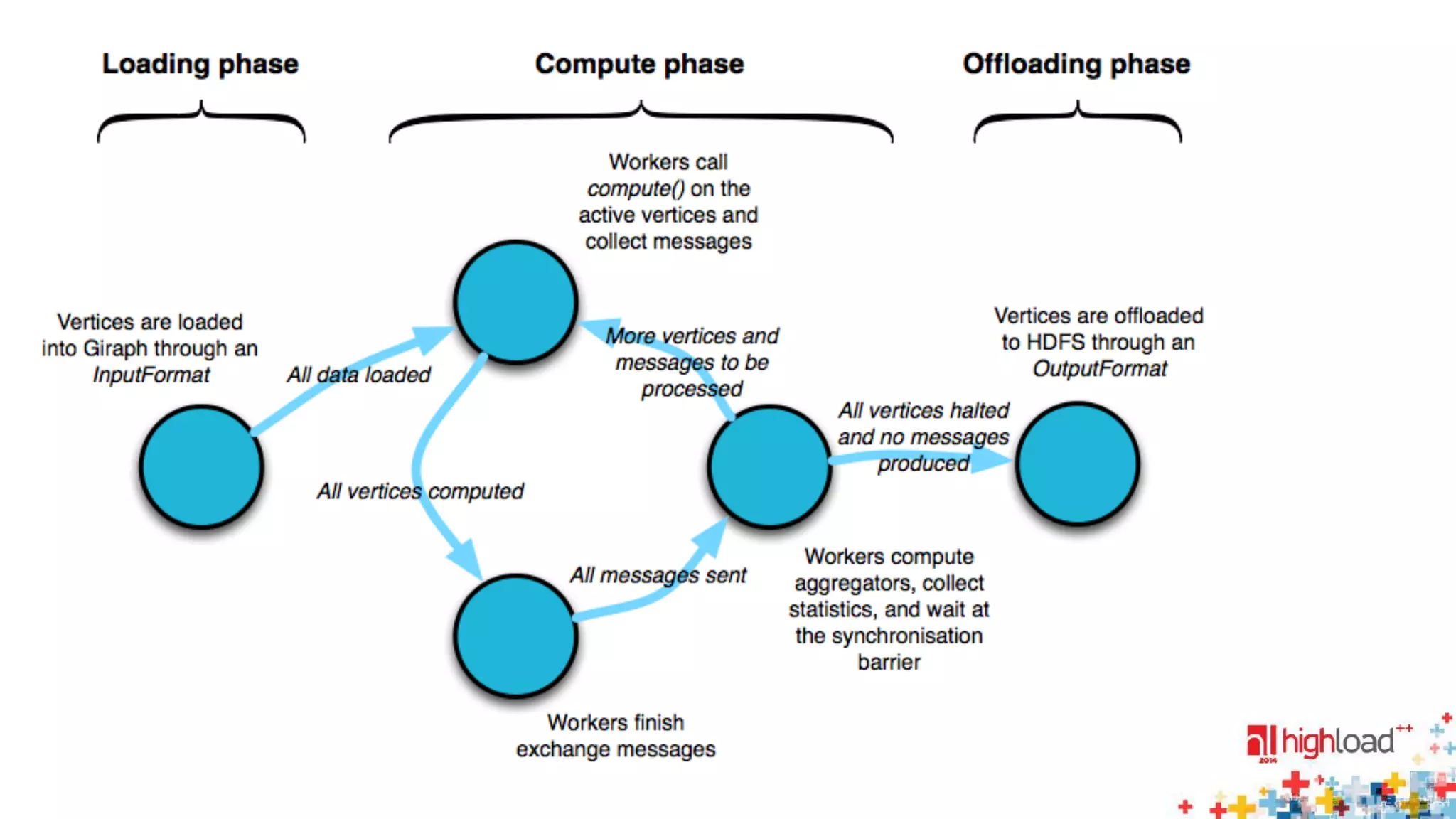
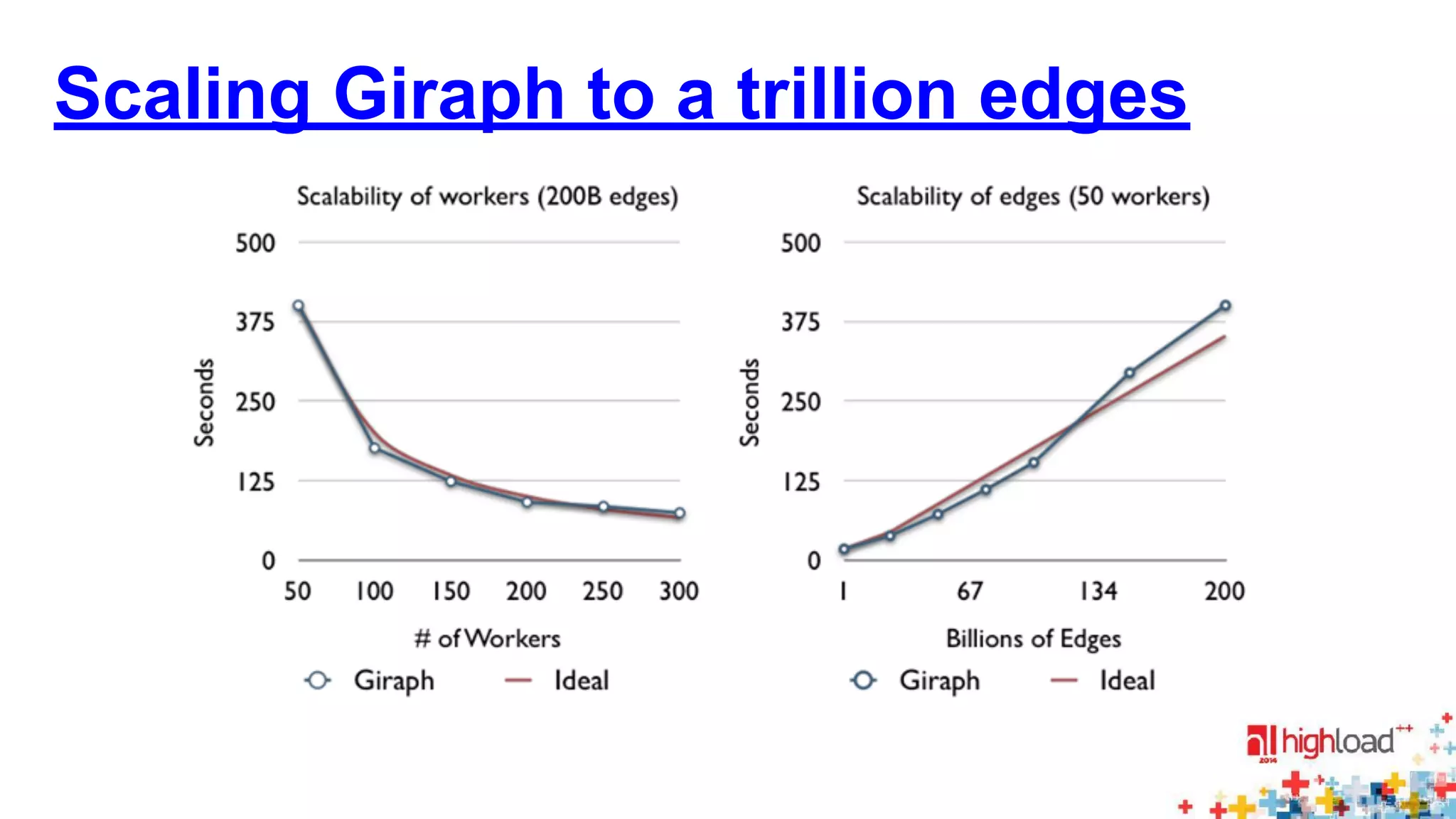
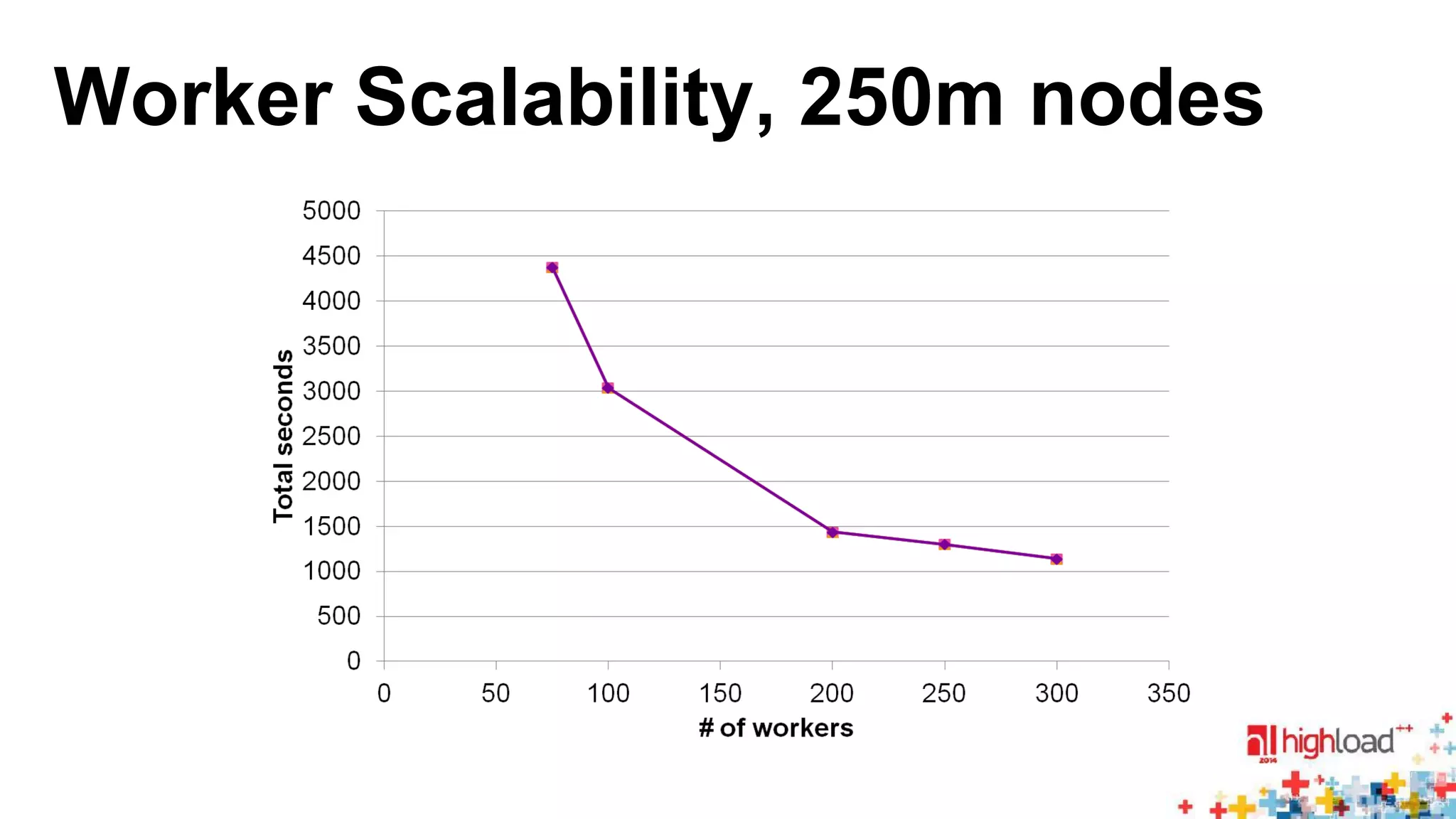
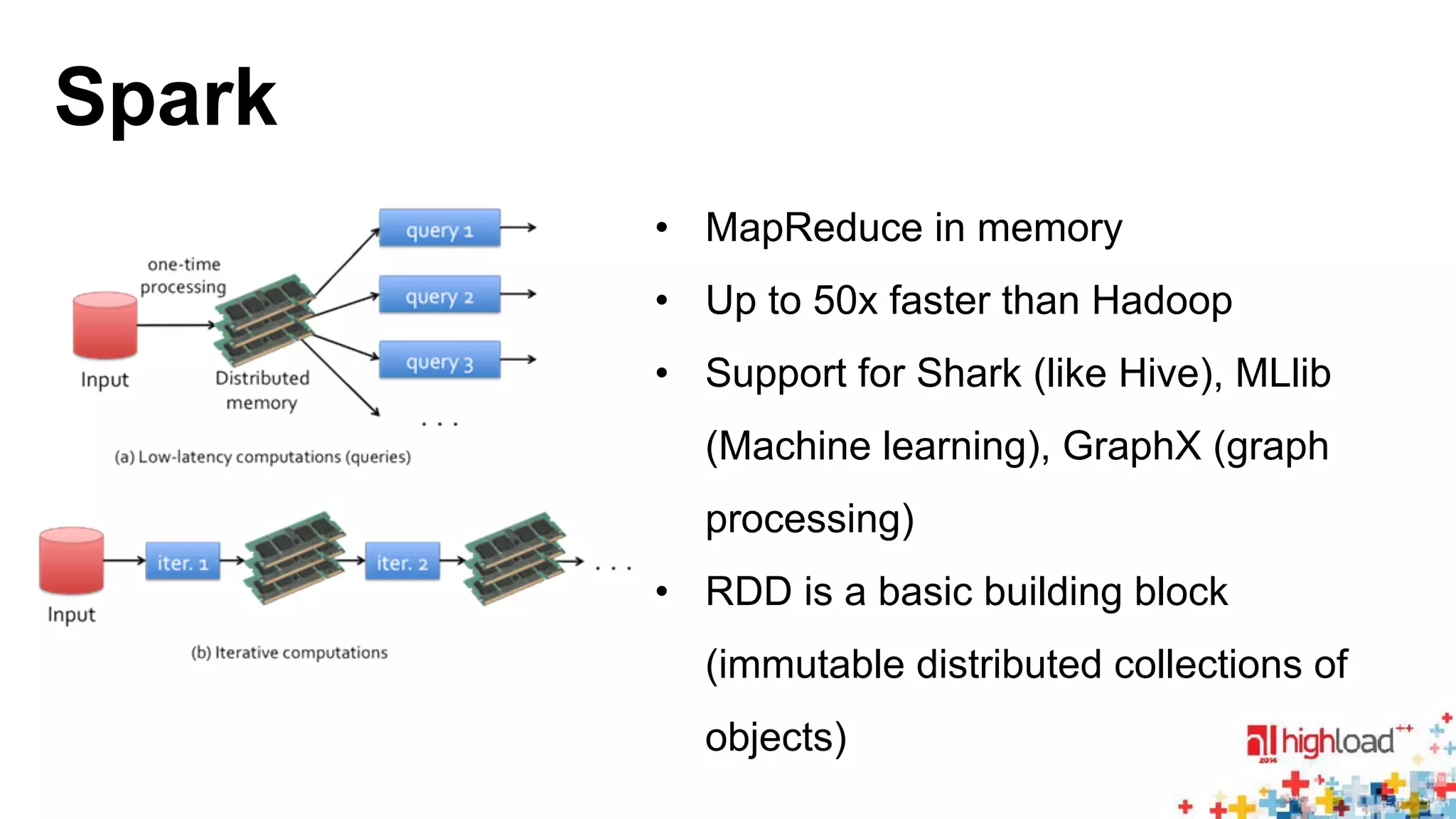
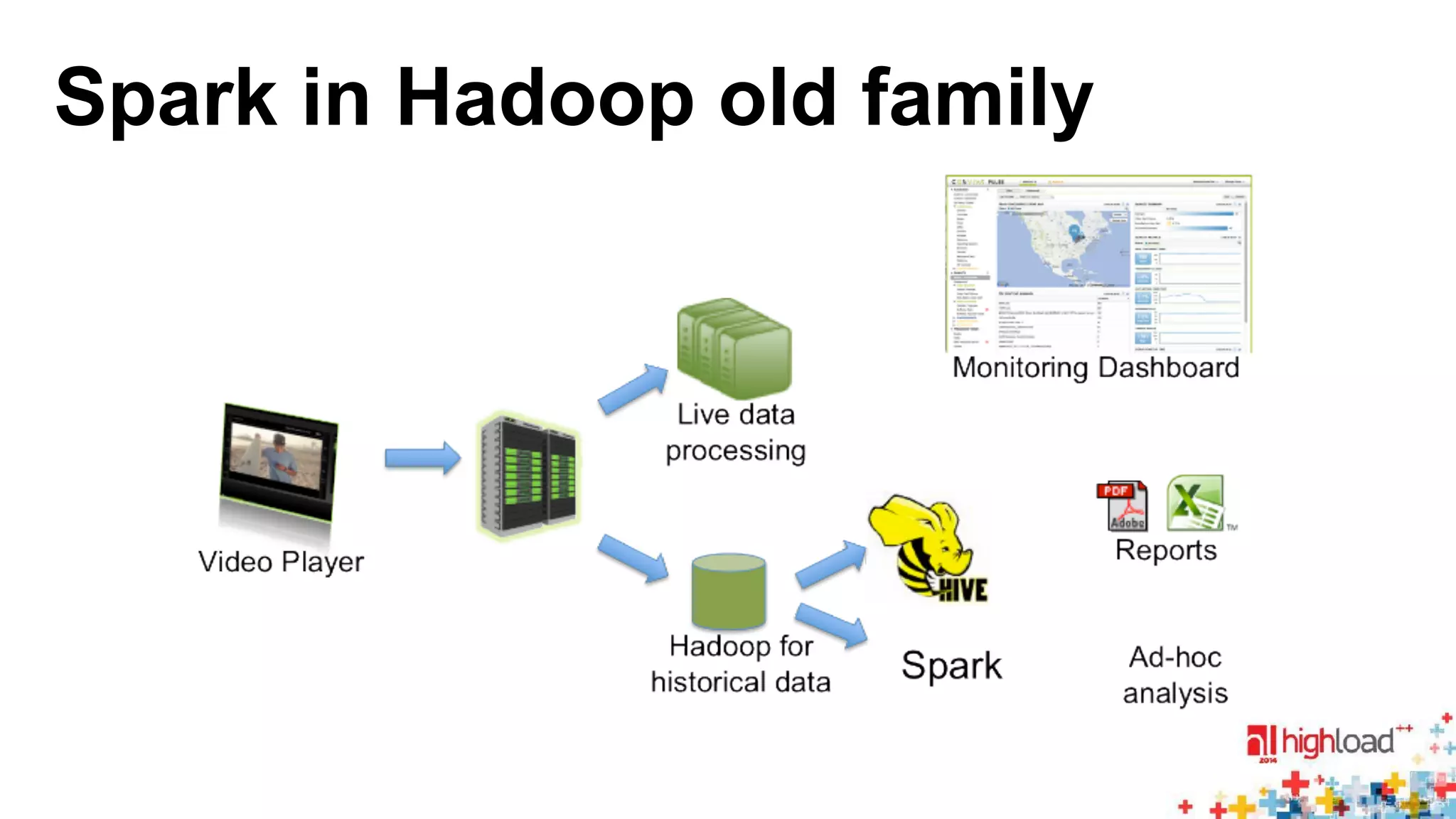
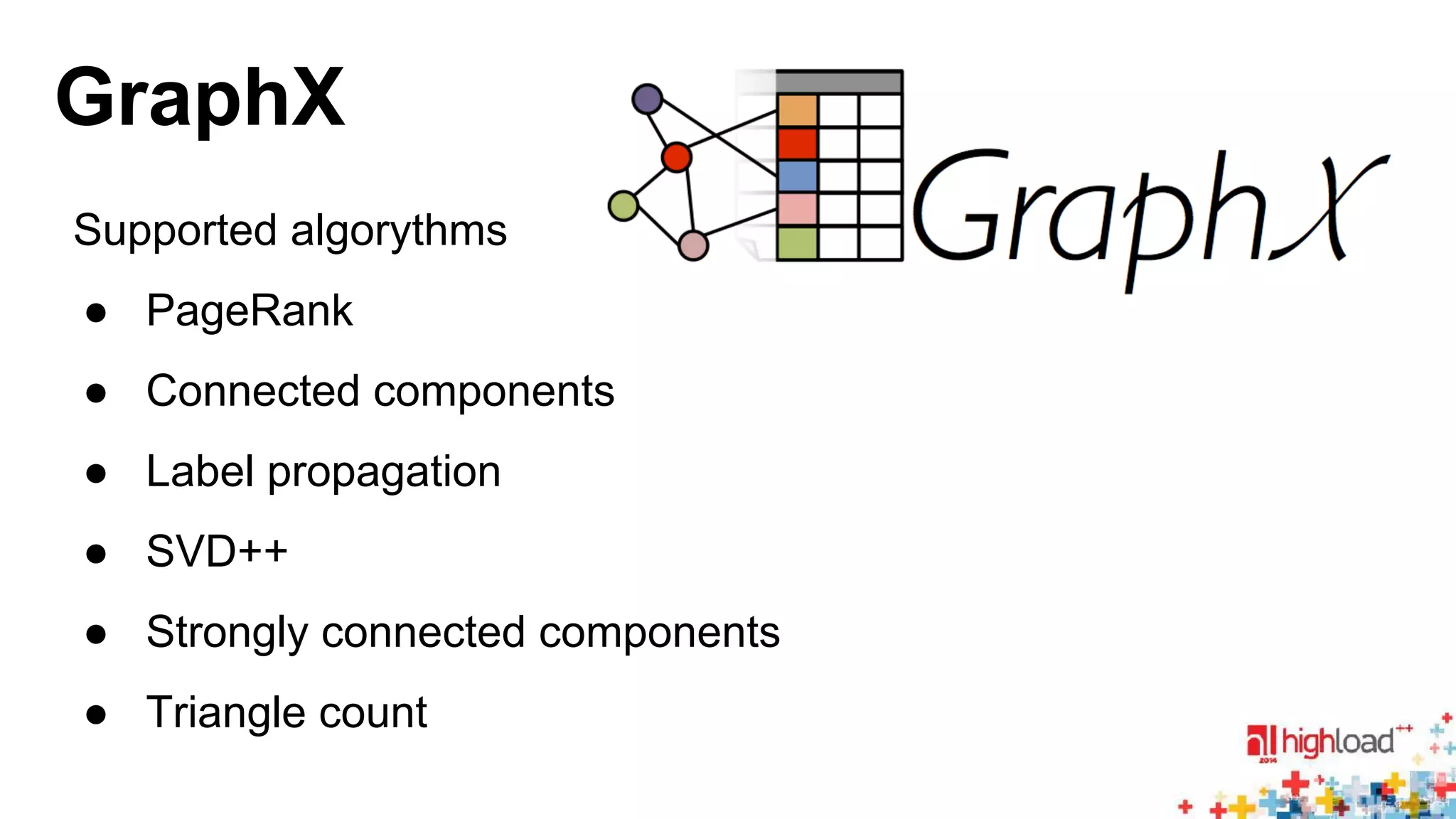
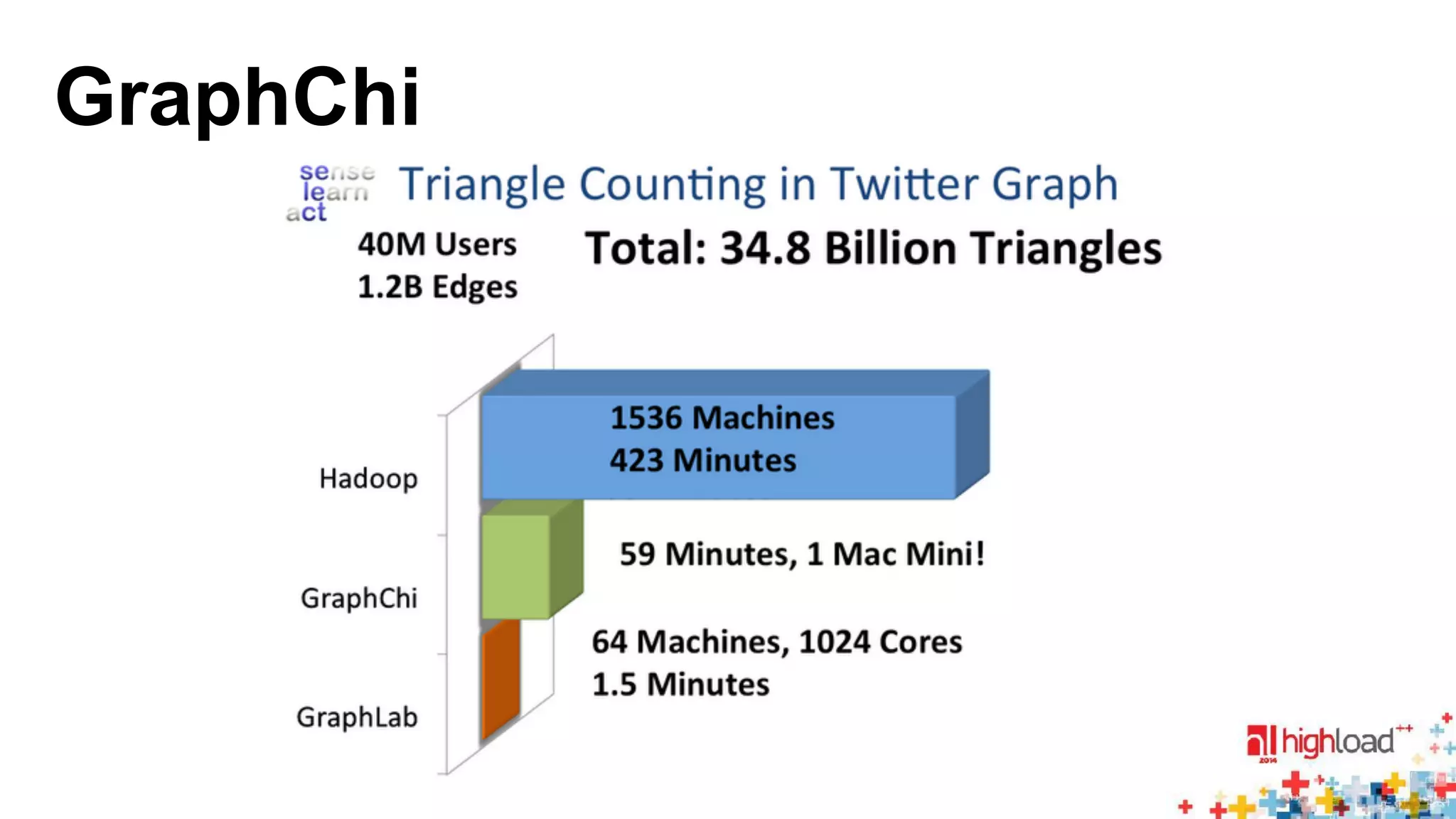
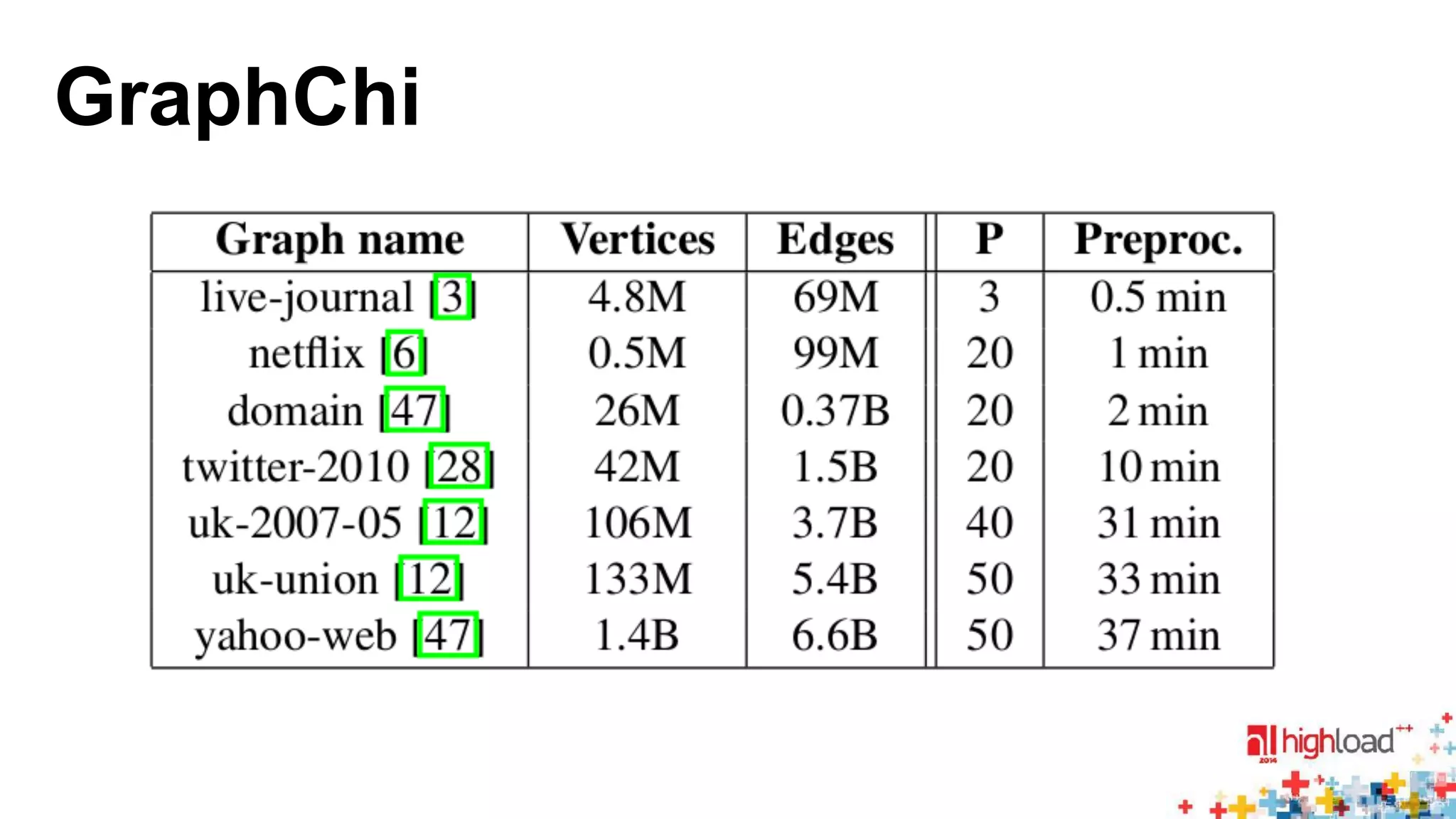
The document discusses large-scale graph processing and summarizes several graph processing tools and techniques. It describes Google's Pregel framework, which introduced the bulk synchronous parallel computation model. It also discusses Apache Giraph, an open-source implementation of Pregel, and how it uses Hadoop and ZooKeeper. Finally, it summarizes more recent tools like Spark and GraphX that can perform graph analytics in-memory at faster speeds.






































































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)











