Download as PDF, PPTX


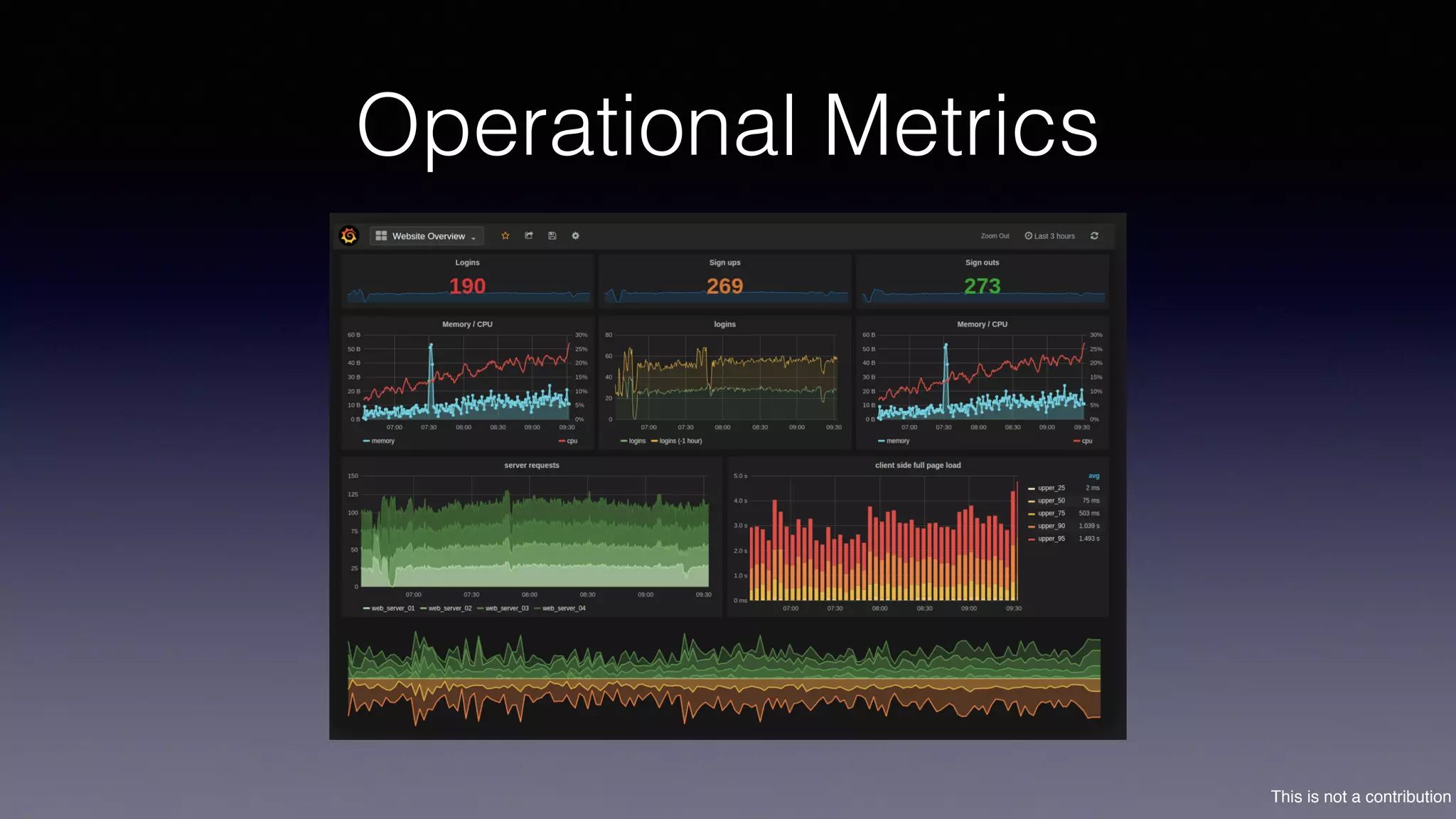



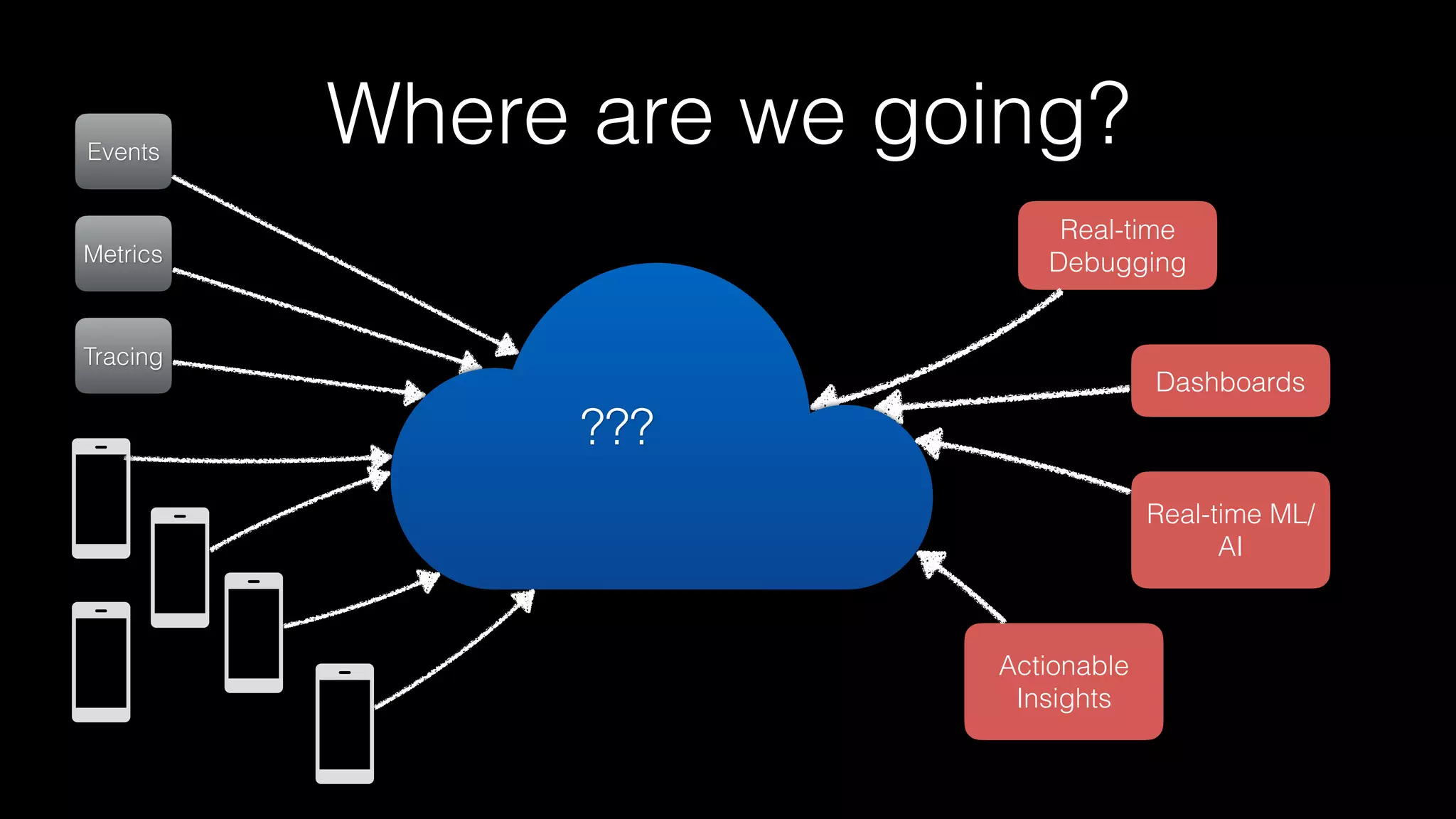





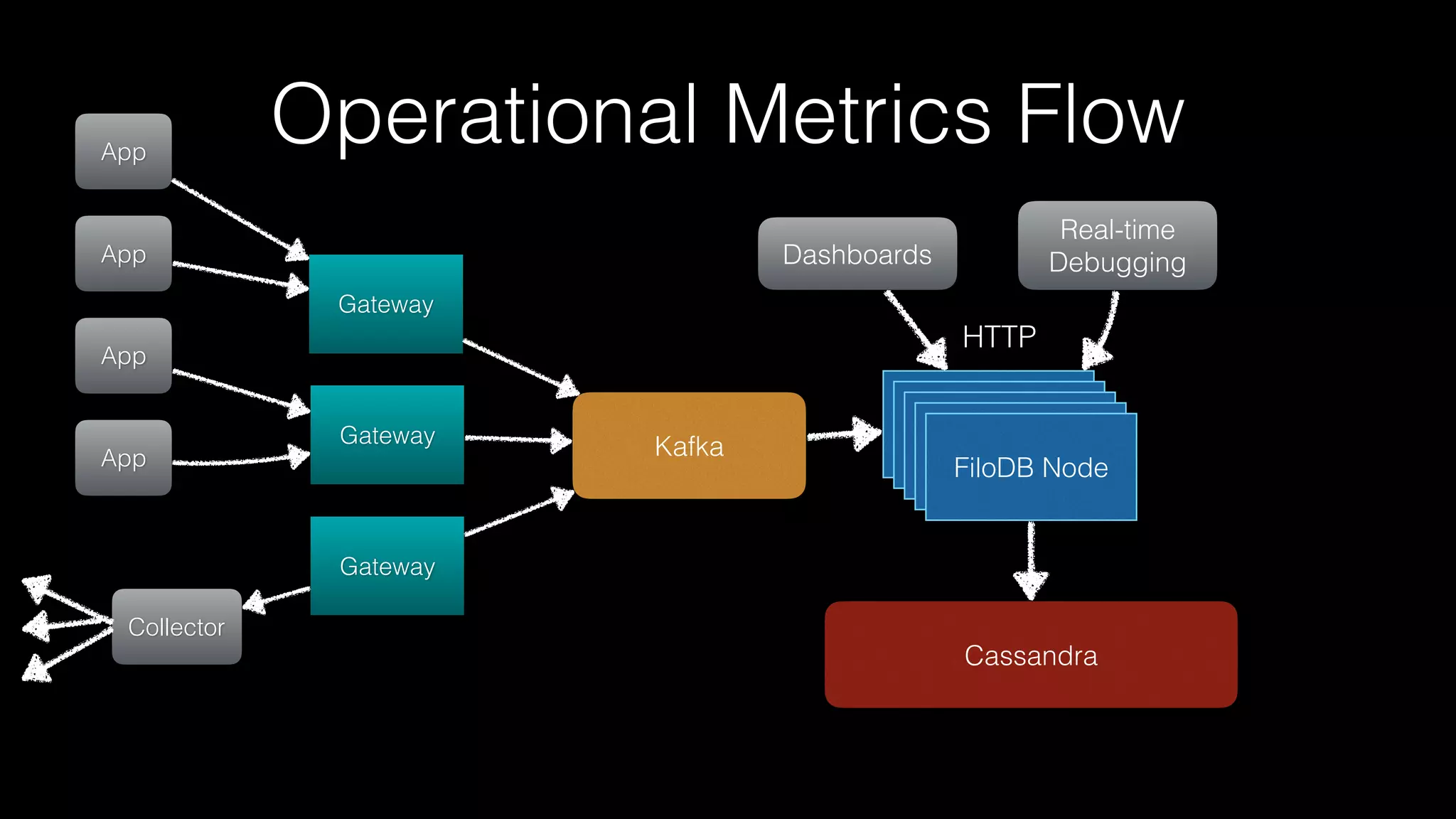
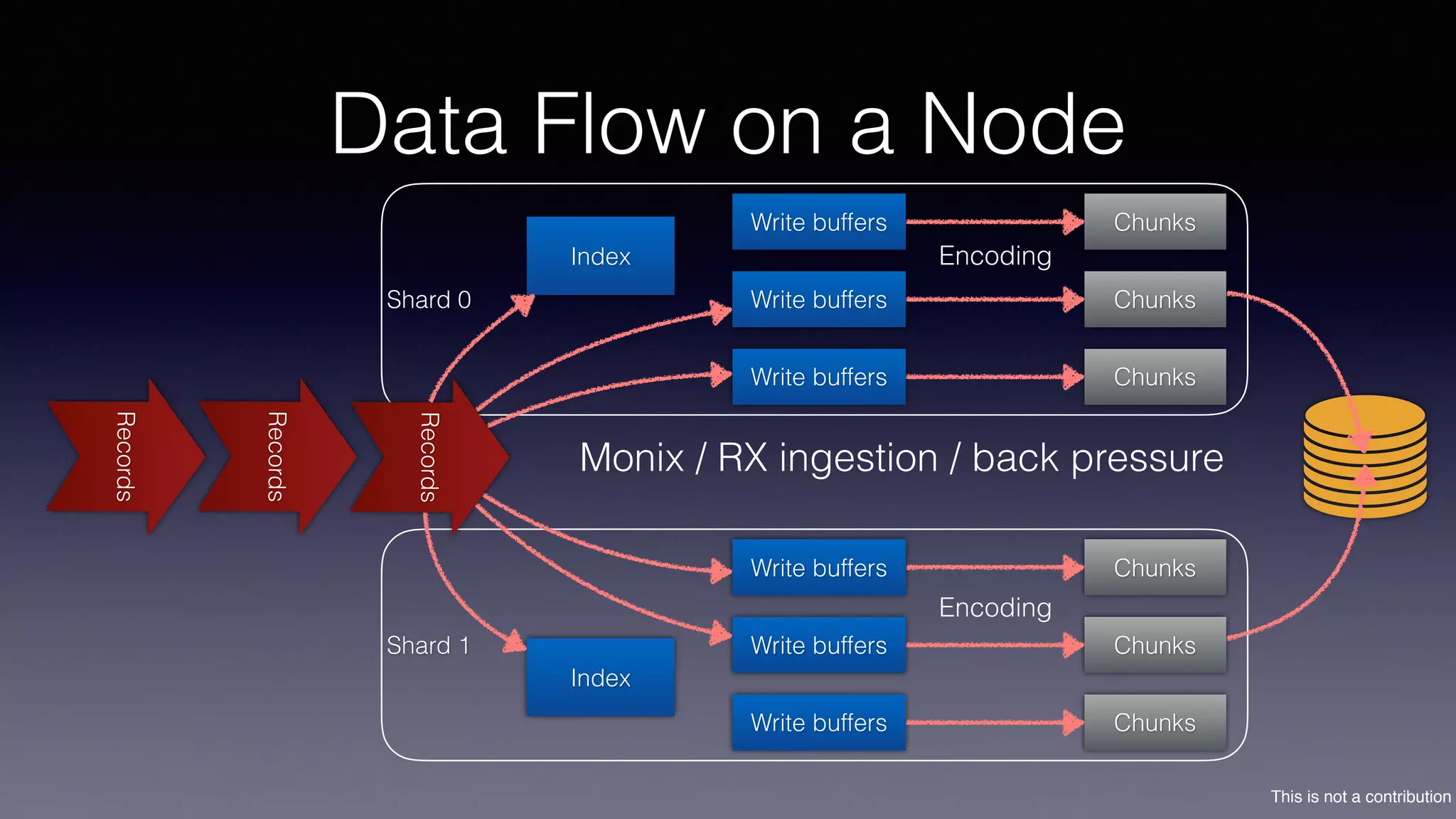

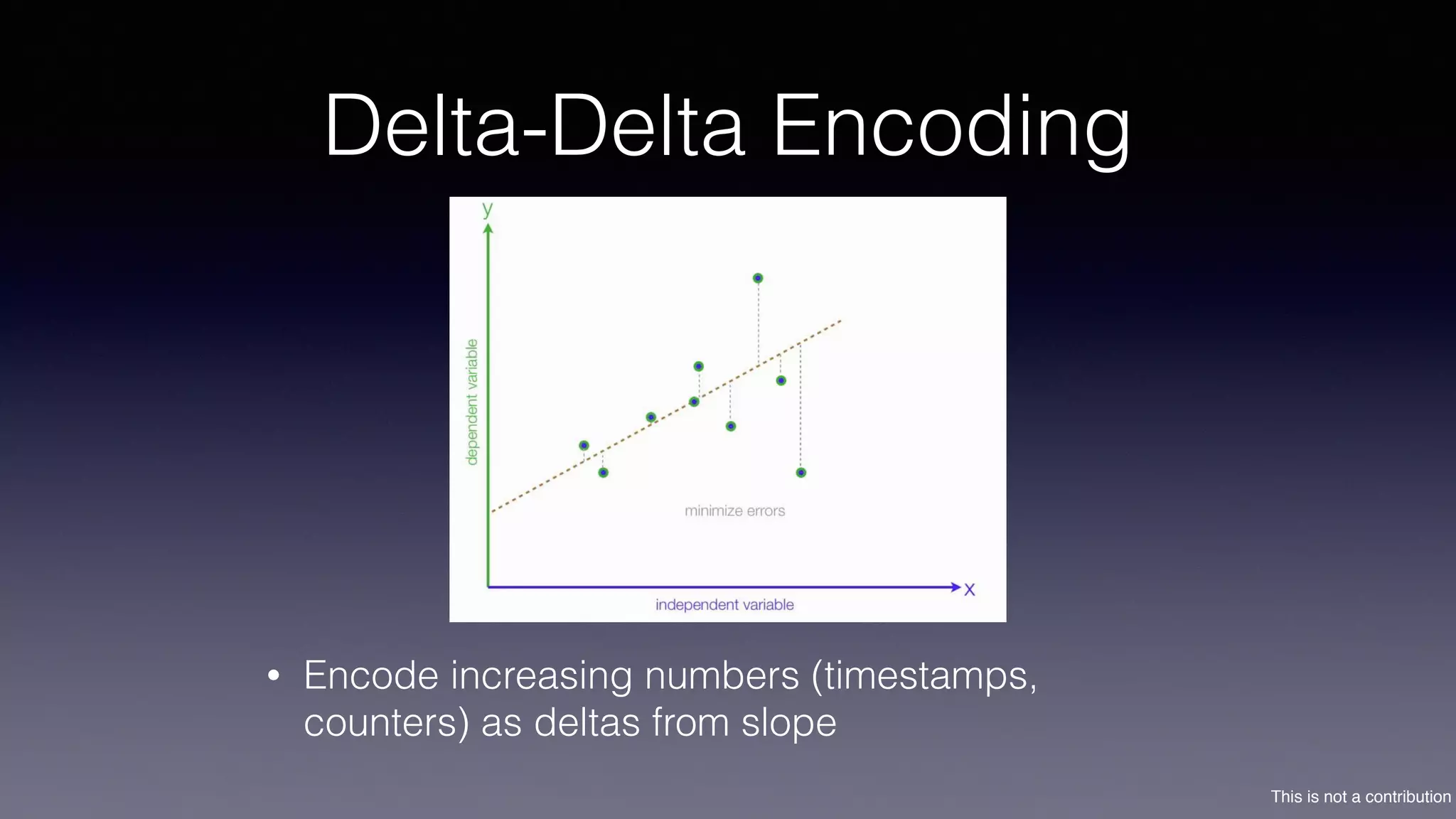



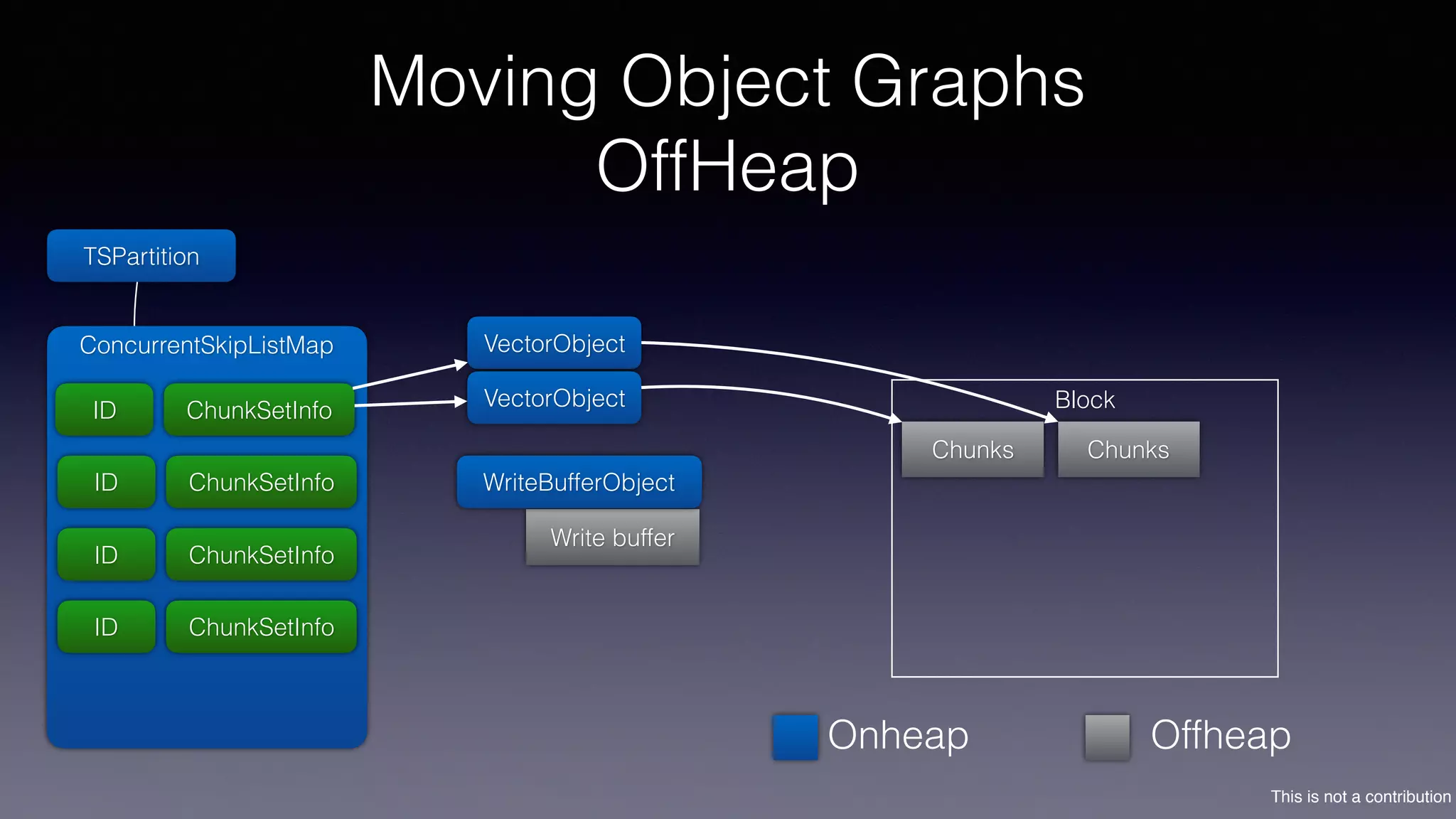
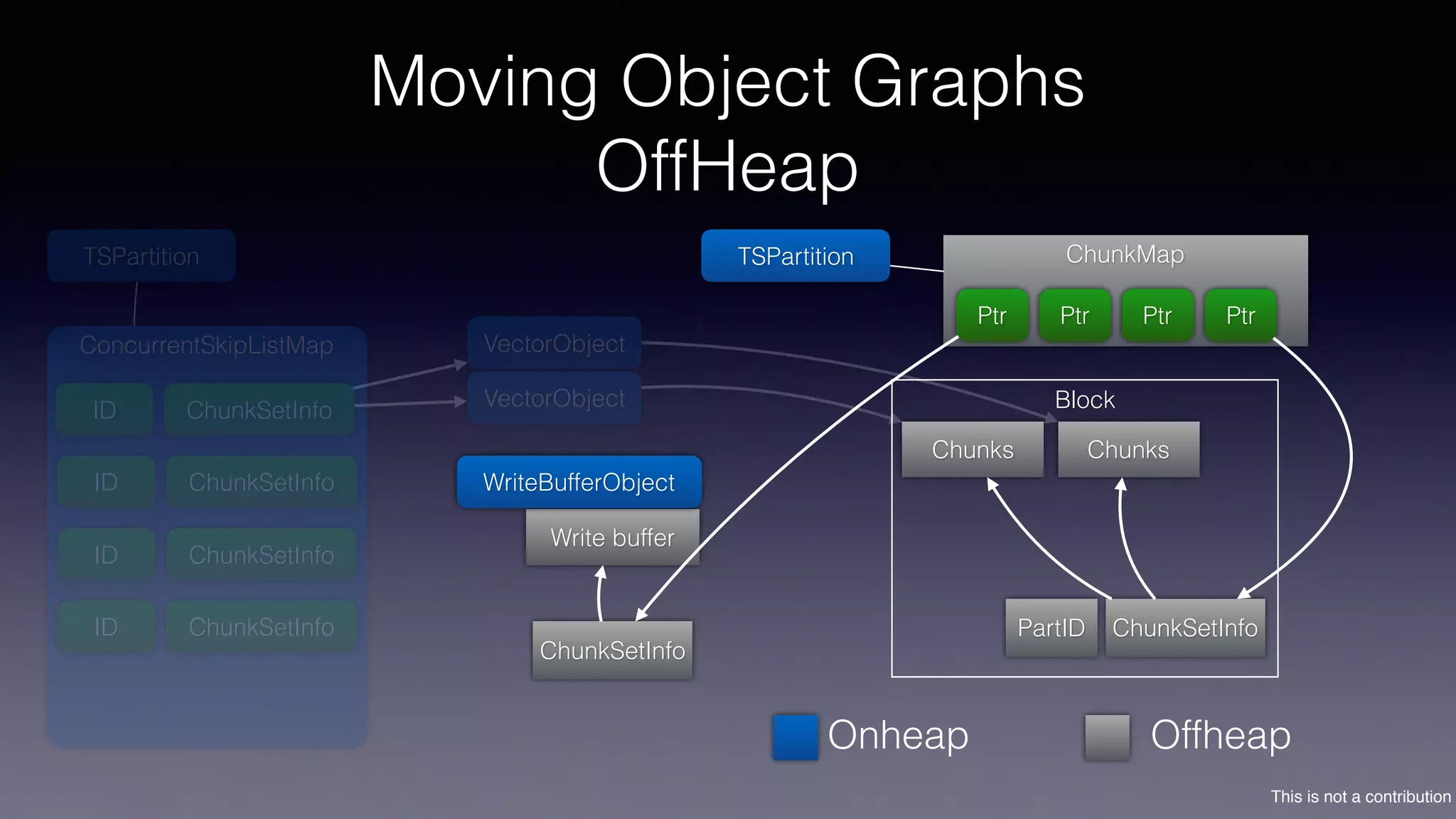



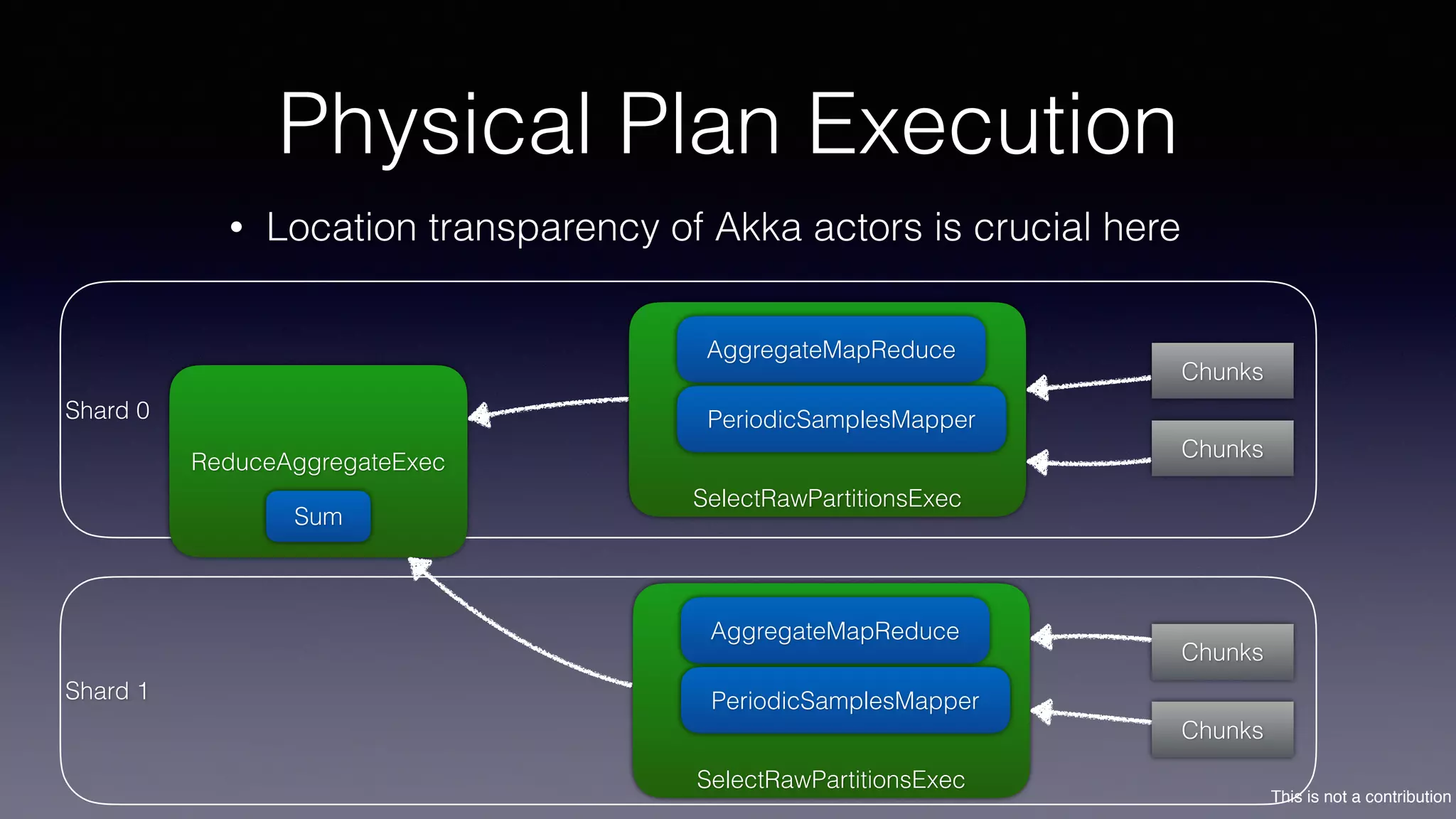
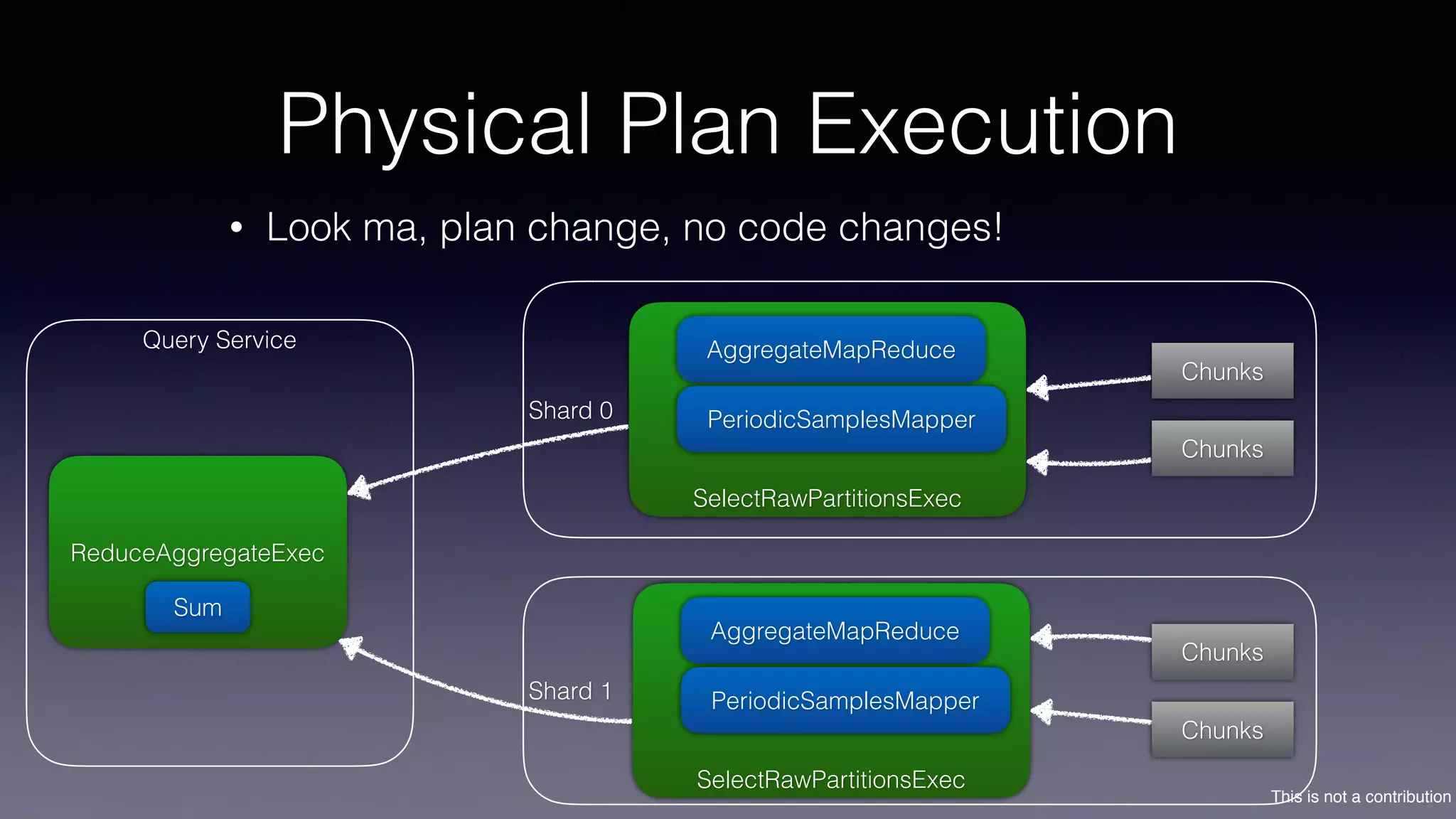
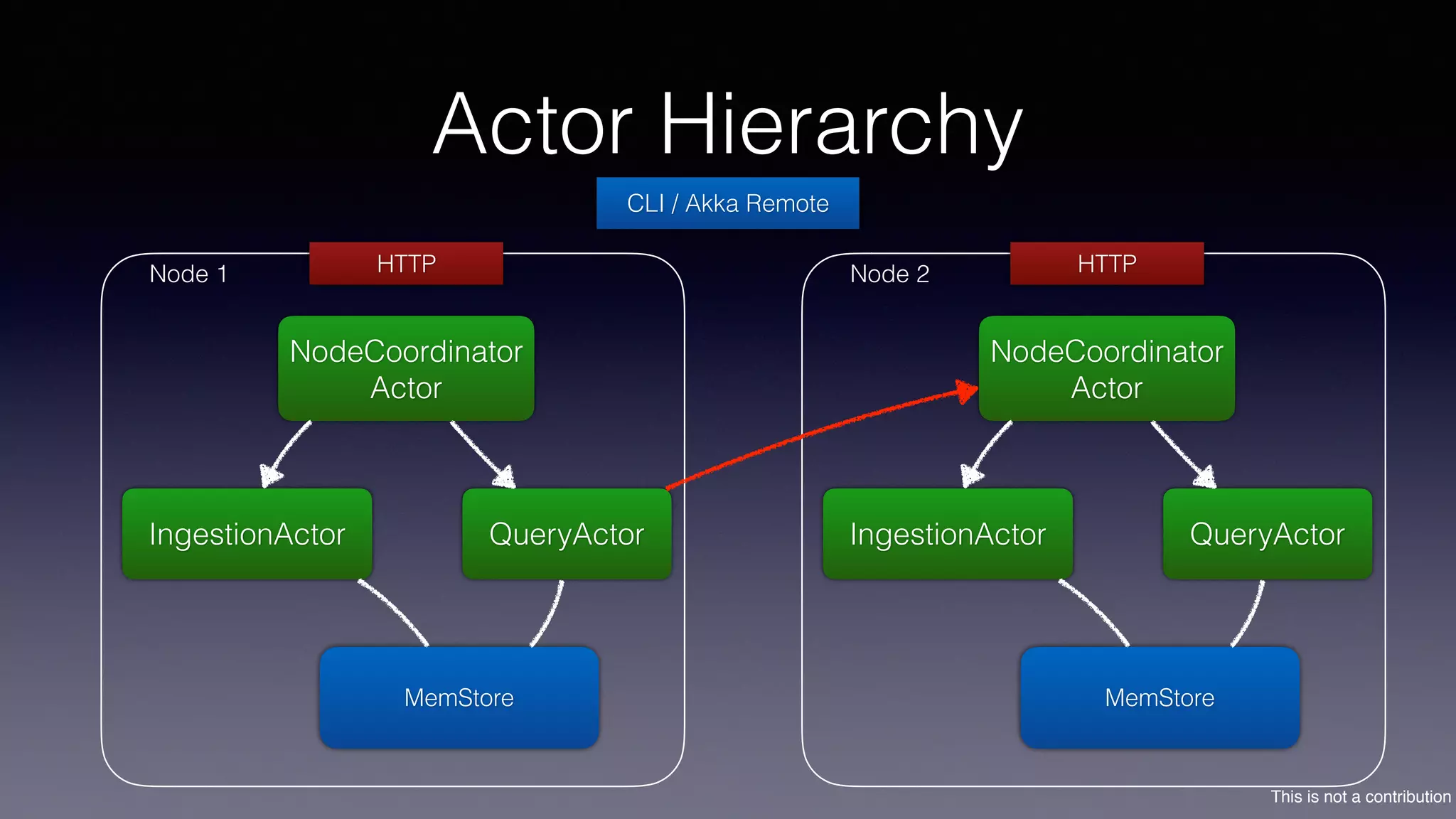







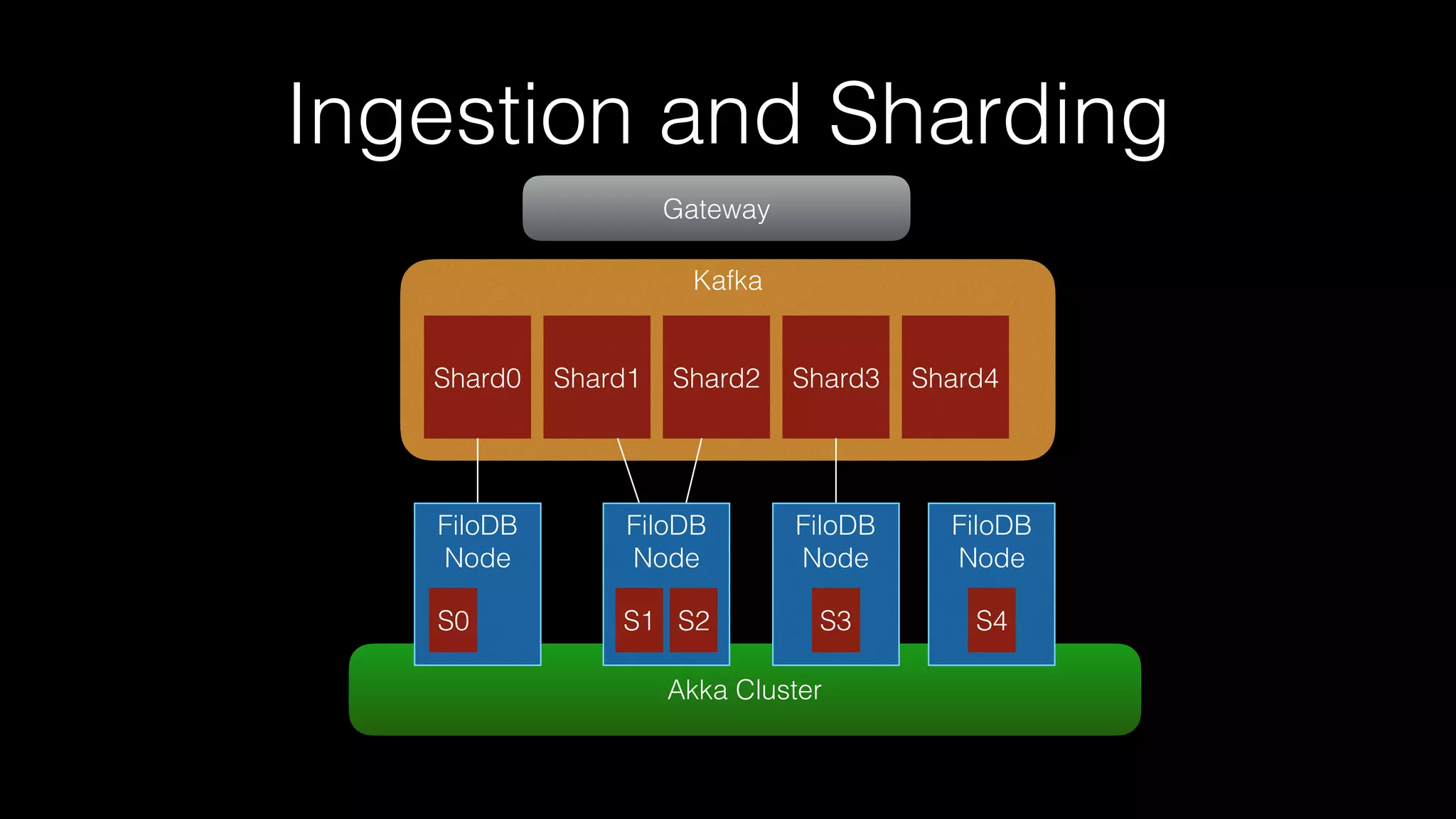
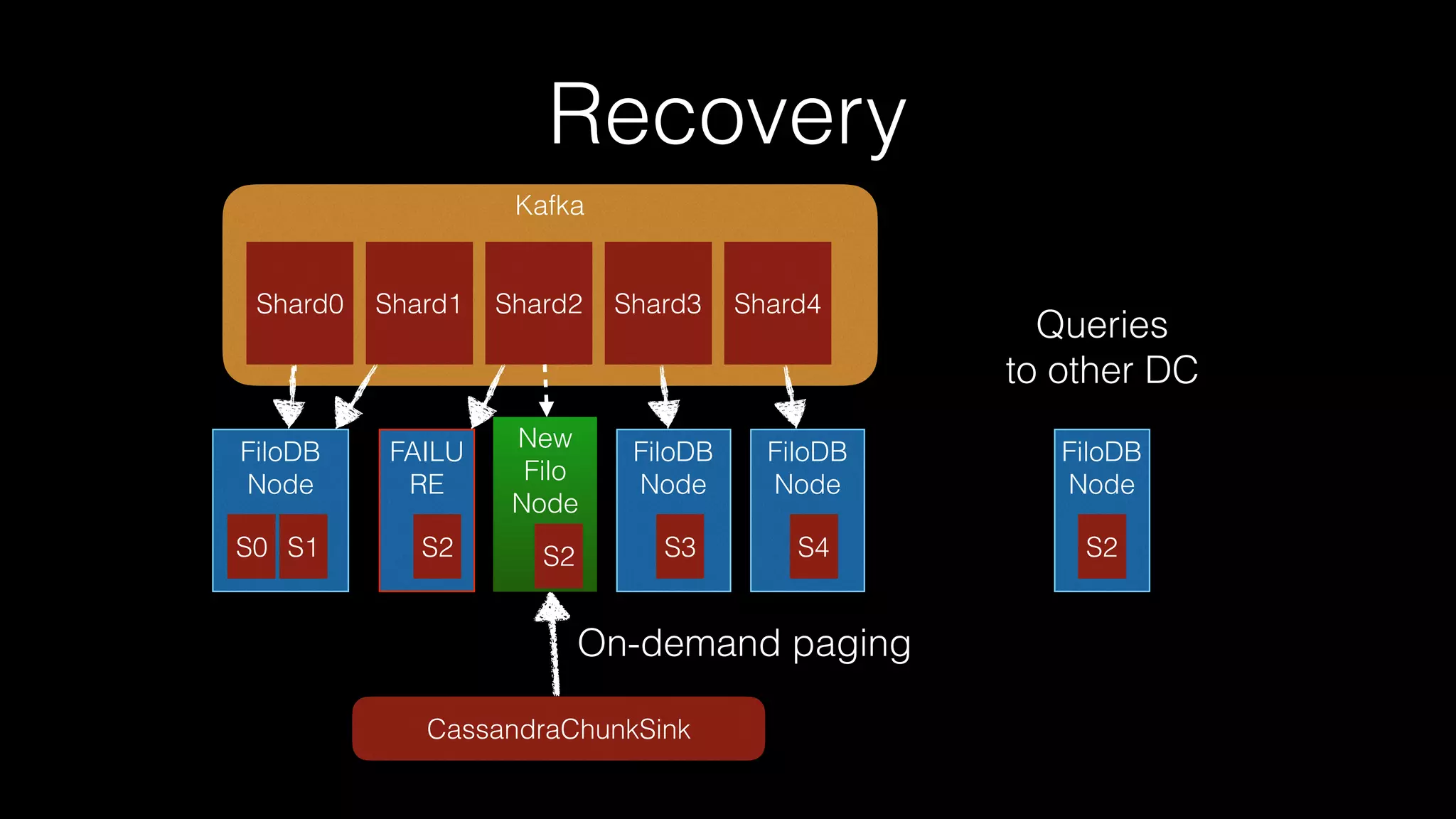



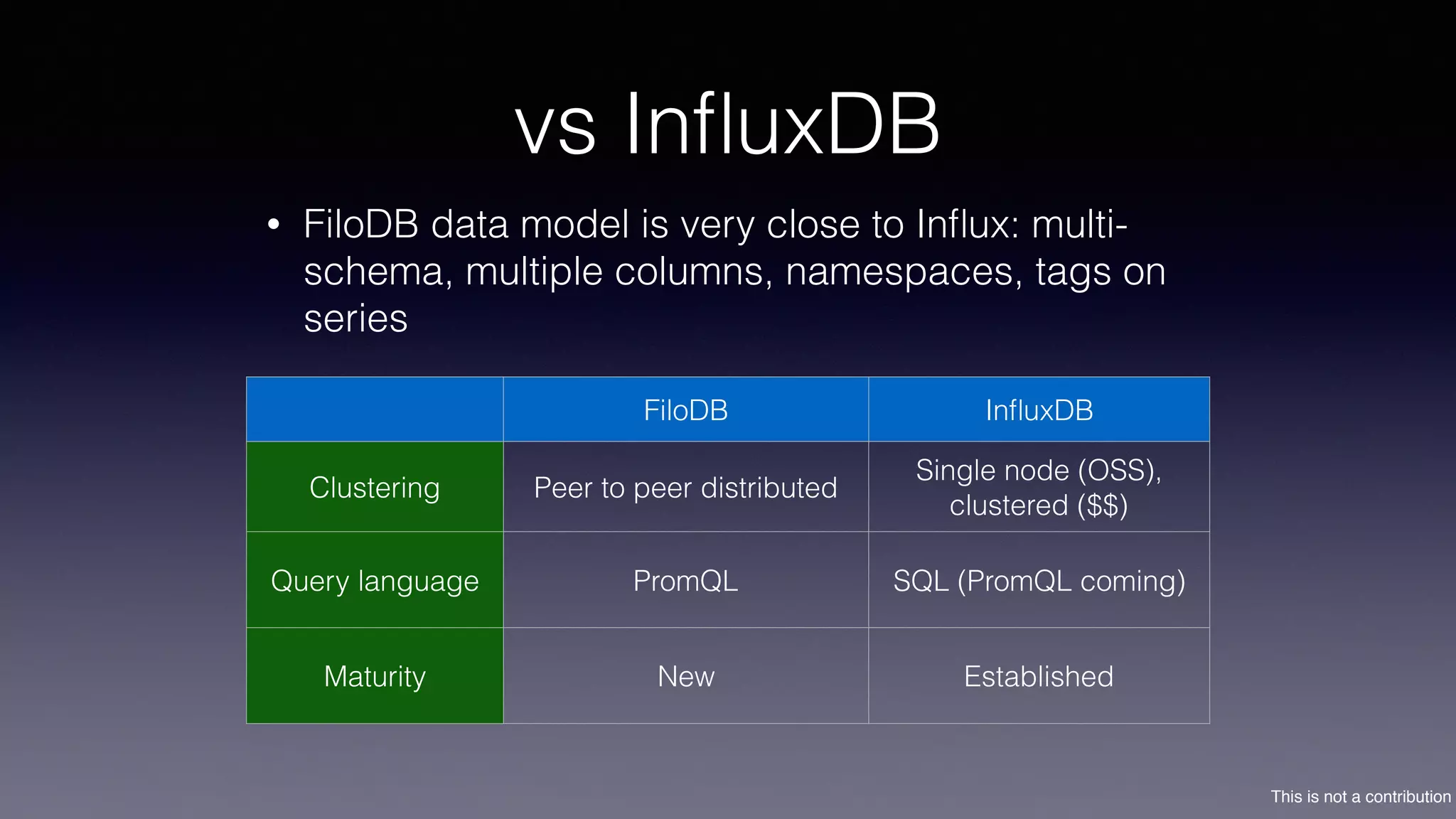

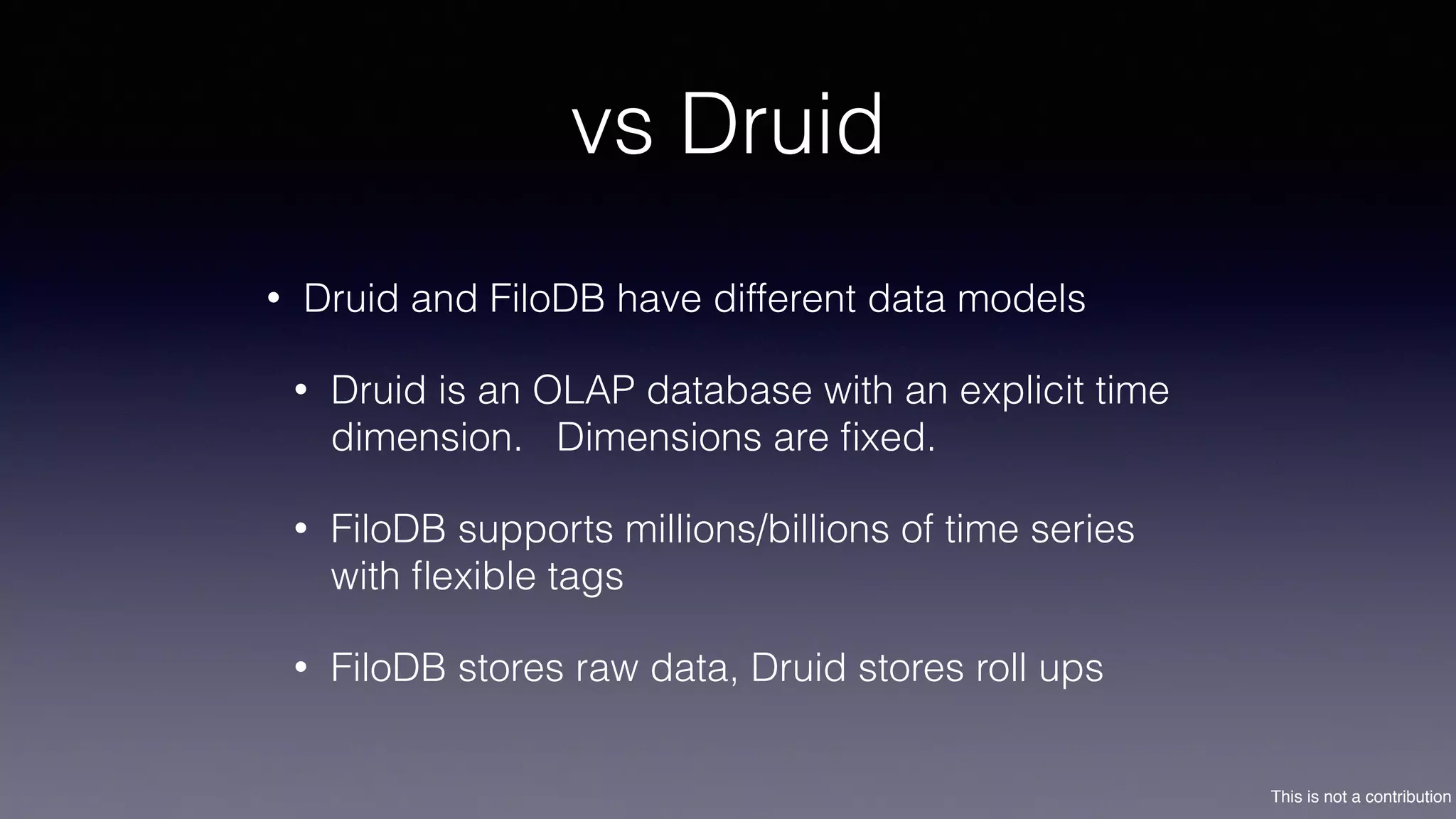








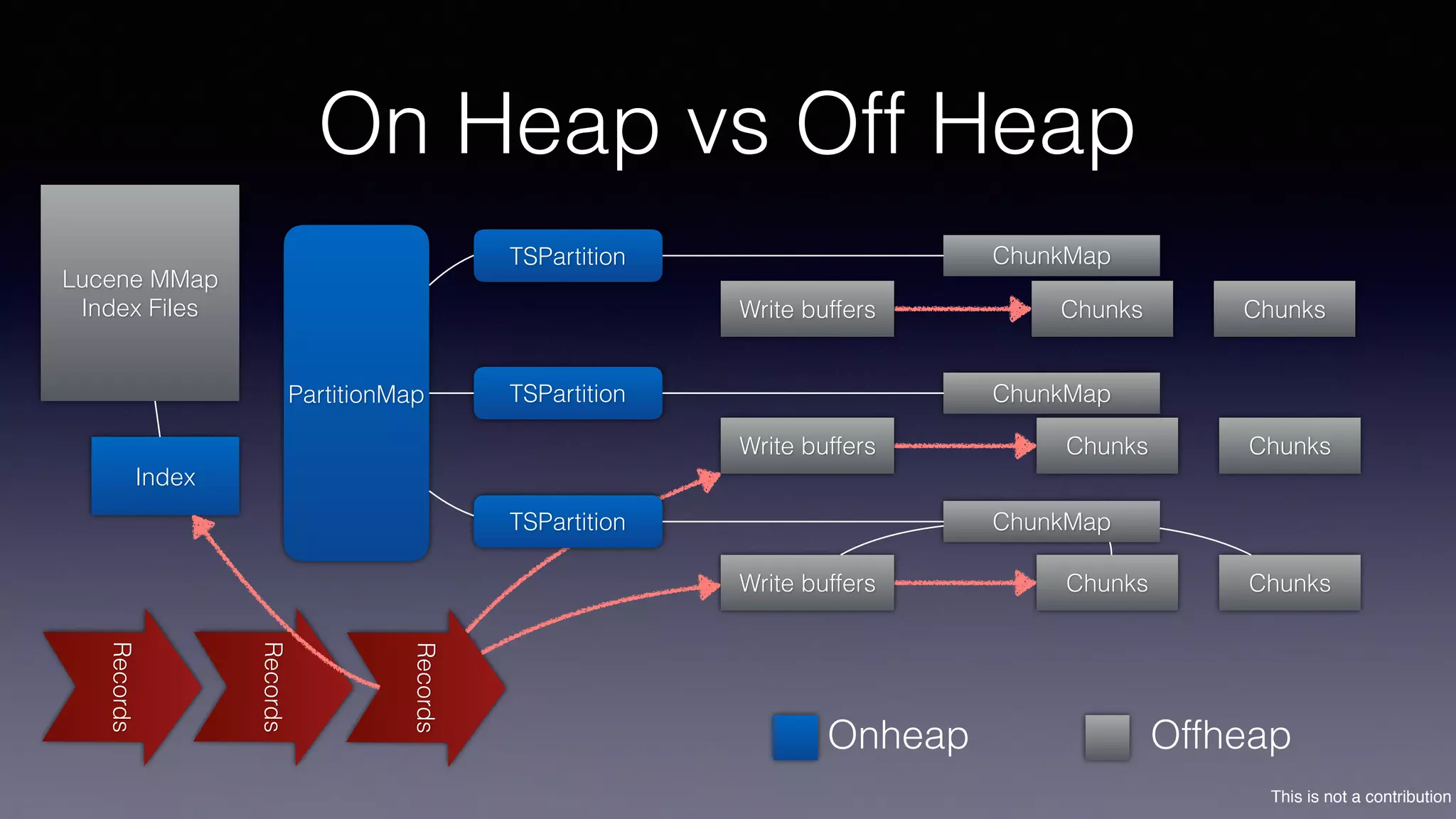

The document discusses the introduction of Filodb, an open-source, distributed, in-memory time series database designed for high scalability and efficiency in handling massive data volumes. It highlights key features such as Prometheus compatibility, flexible data modeling with tag-based querying, robust ingestion rates, and efficient recovery mechanisms utilizing technologies like Apache Kafka and Cassandra. Additionally, it compares Filodb's capabilities with existing systems, emphasizing its advantages in multi-tenancy and complex querying capabilities.








































































