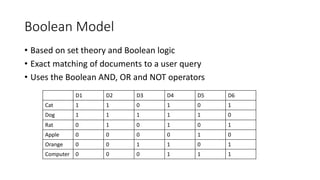
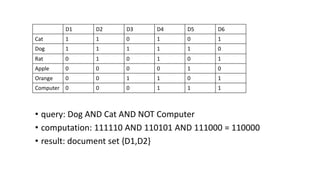
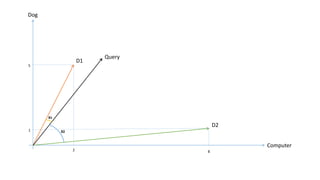
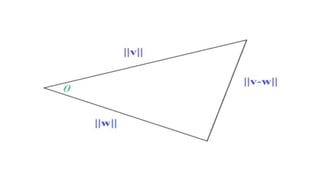
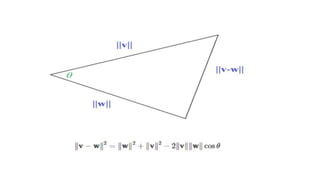
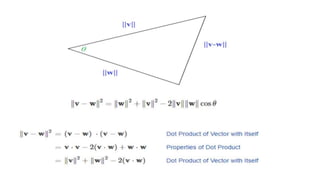
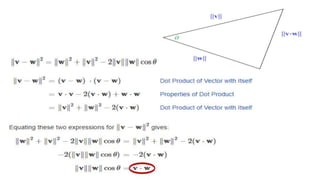
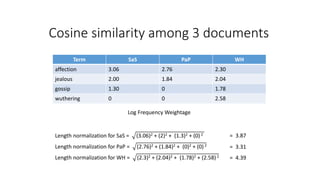
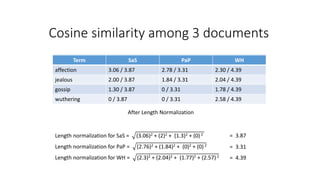
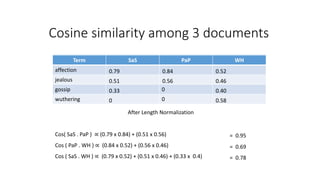
The document compares the Boolean model and the vector space model for information retrieval. The Boolean model emphasizes exact matching using Boolean operators but lacks ranking and synonymy considerations, while the vector space model represents documents and queries as vectors, allowing for similarity computation through cosine similarity. Both models have advantages and disadvantages in terms of implementation, scalability, and processing speed.


































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)





