Downloaded 14 times














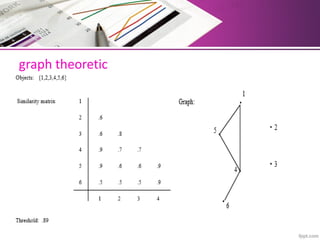


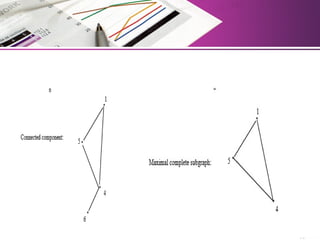


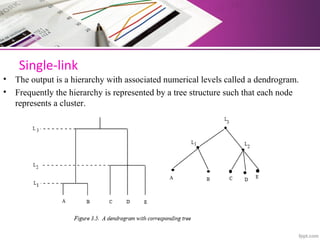







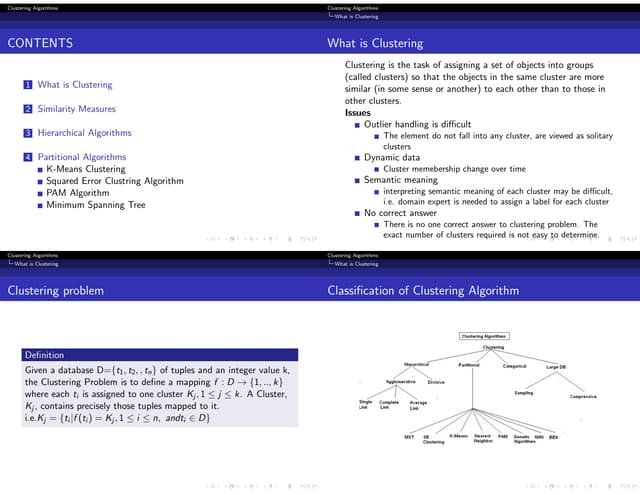
The document discusses automatic classification methods used in information retrieval, including clustering techniques and measures of association. It outlines various classification methods, their applications, and the importance of clustering in improving retrieval efficiency. Additionally, it explores the theoretical foundations and algorithms related to clustering, such as the single-link method and minimum spanning tree concepts.