




















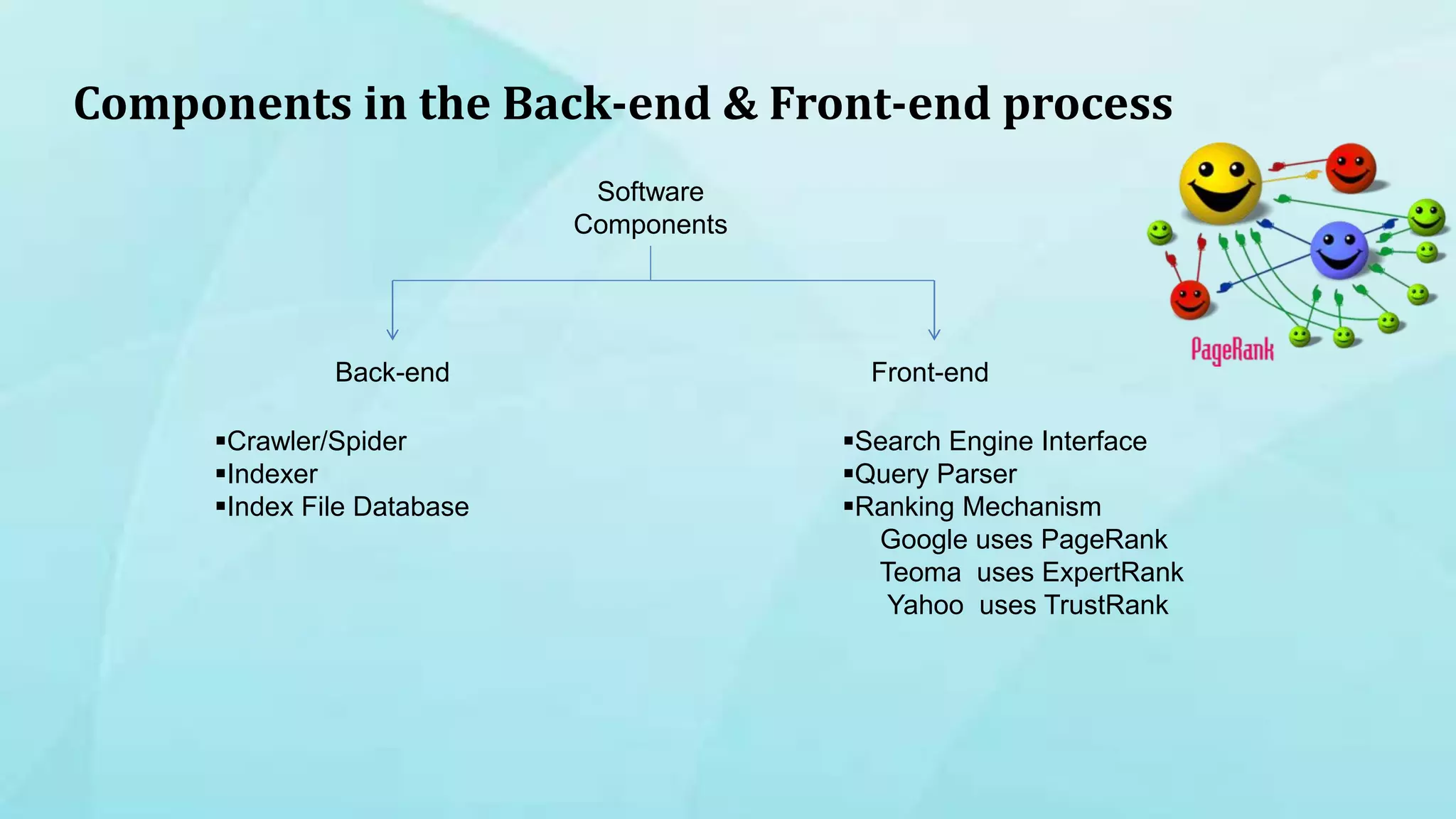
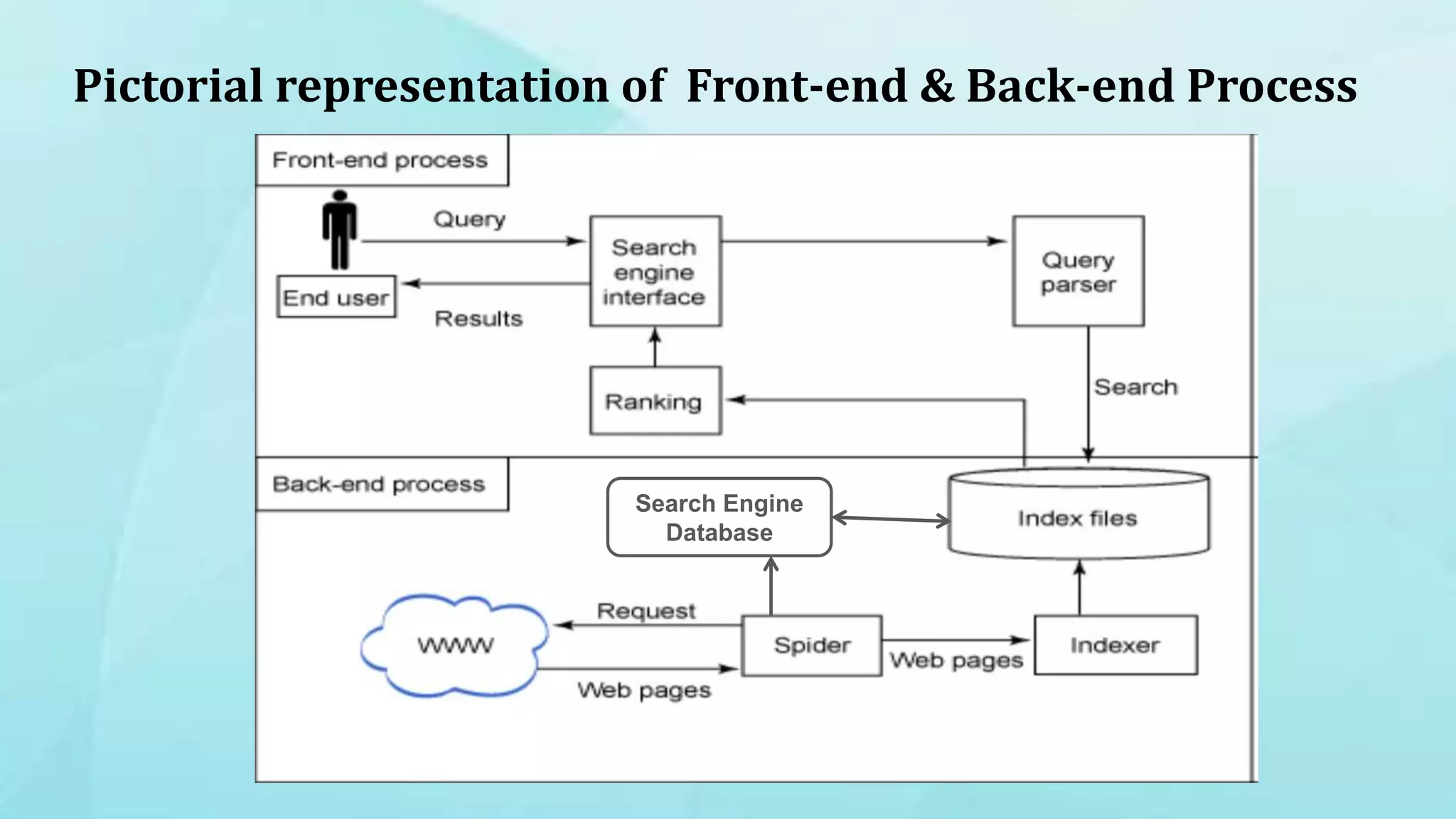
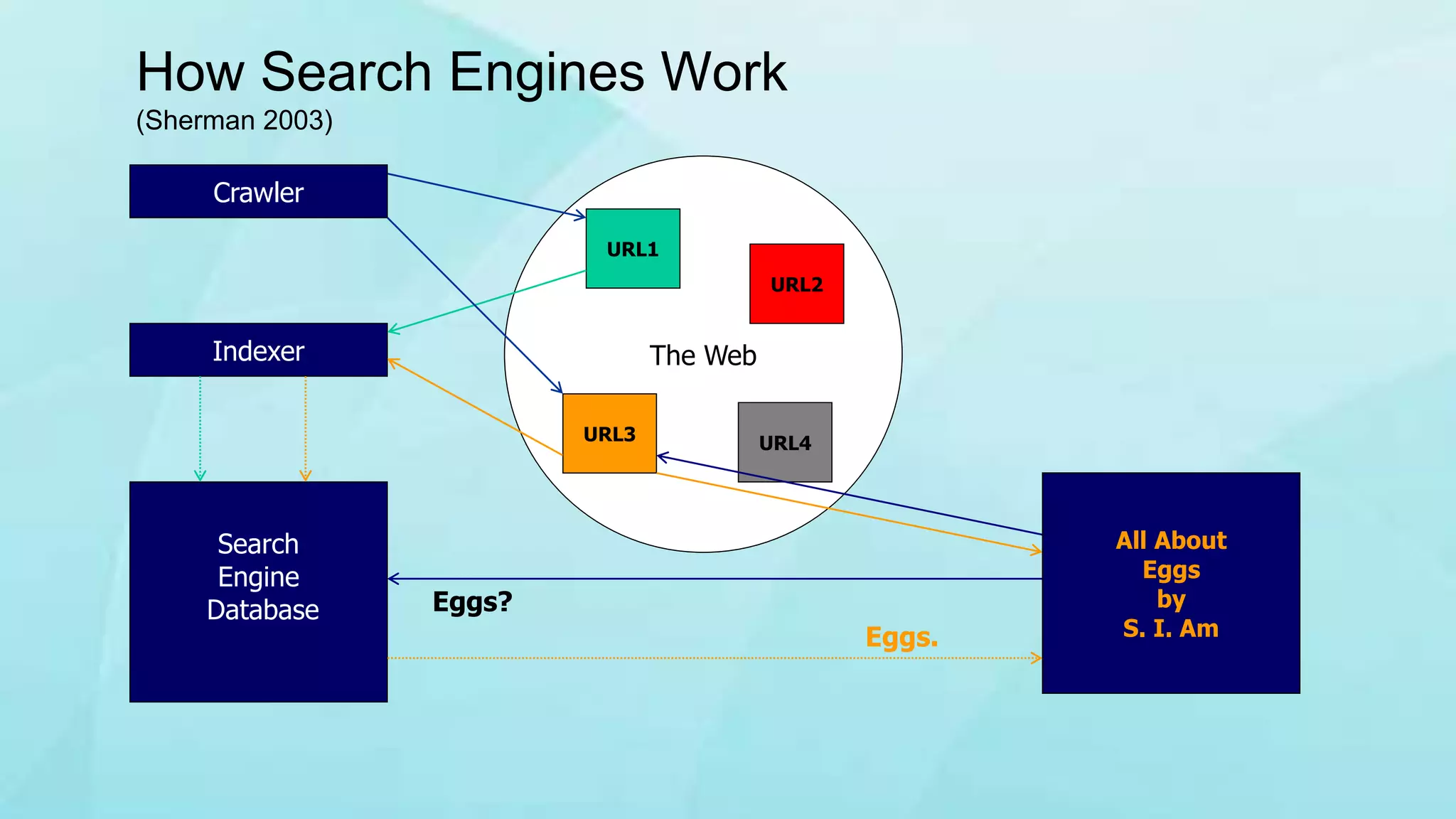


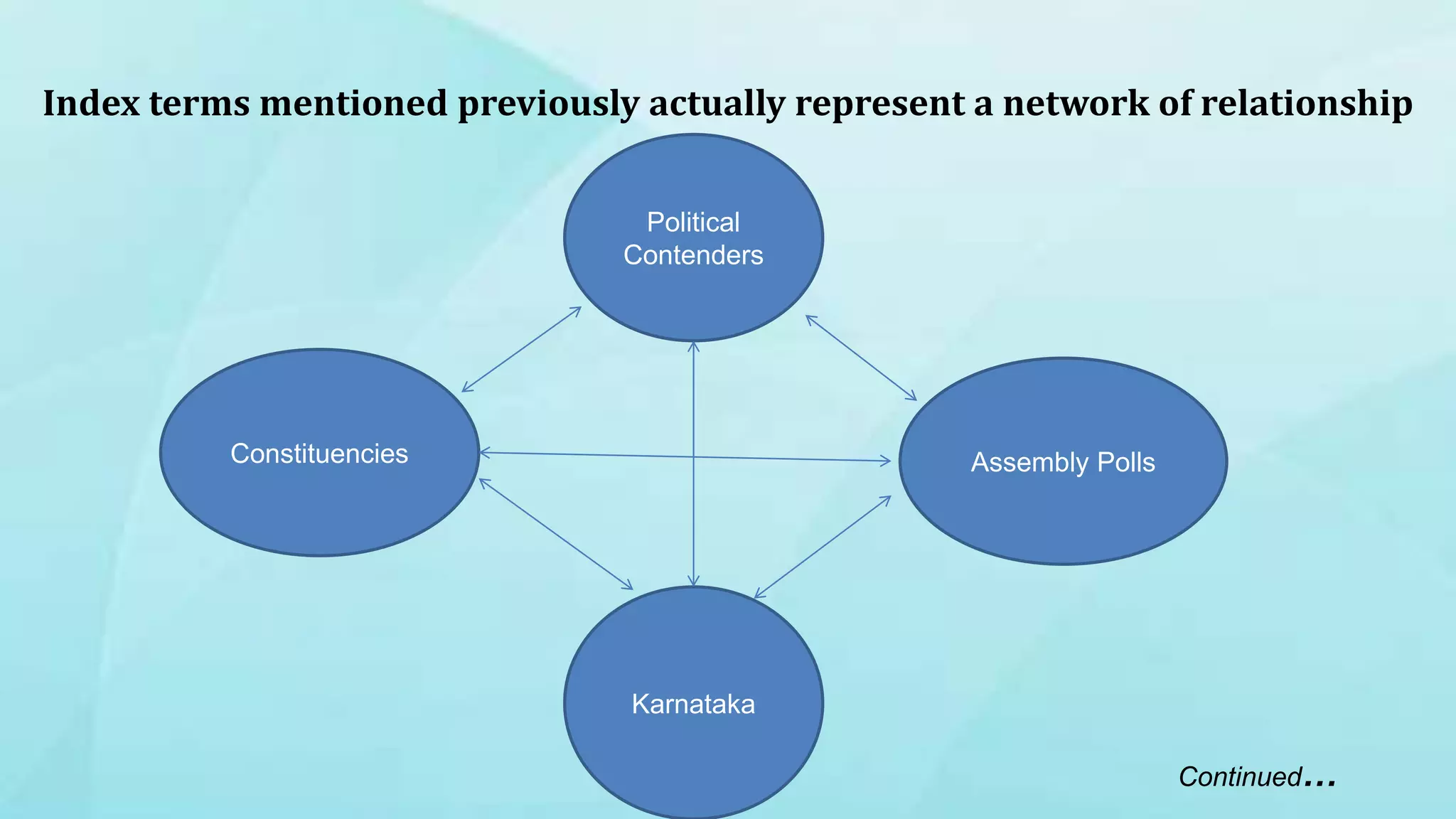
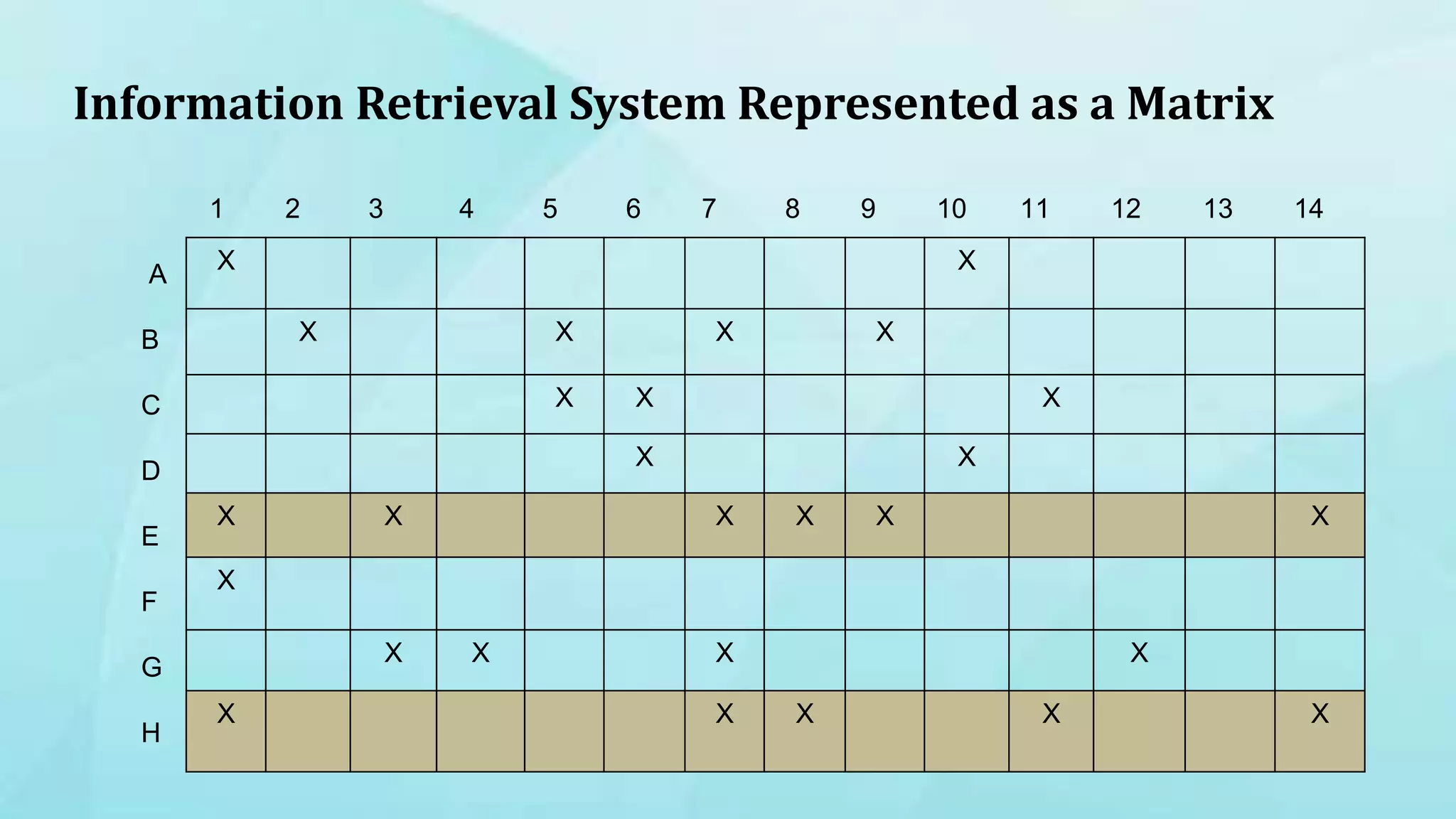






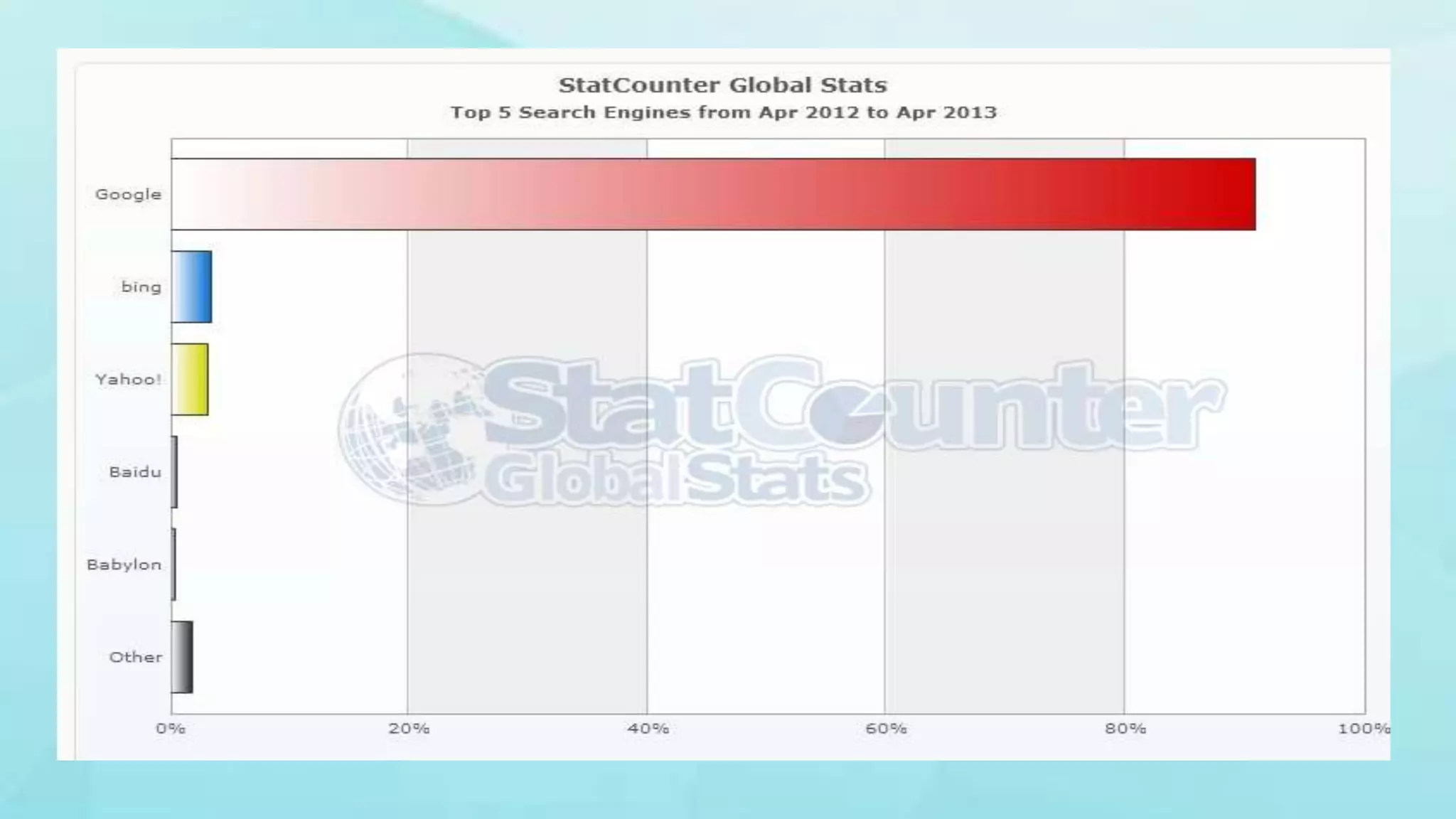
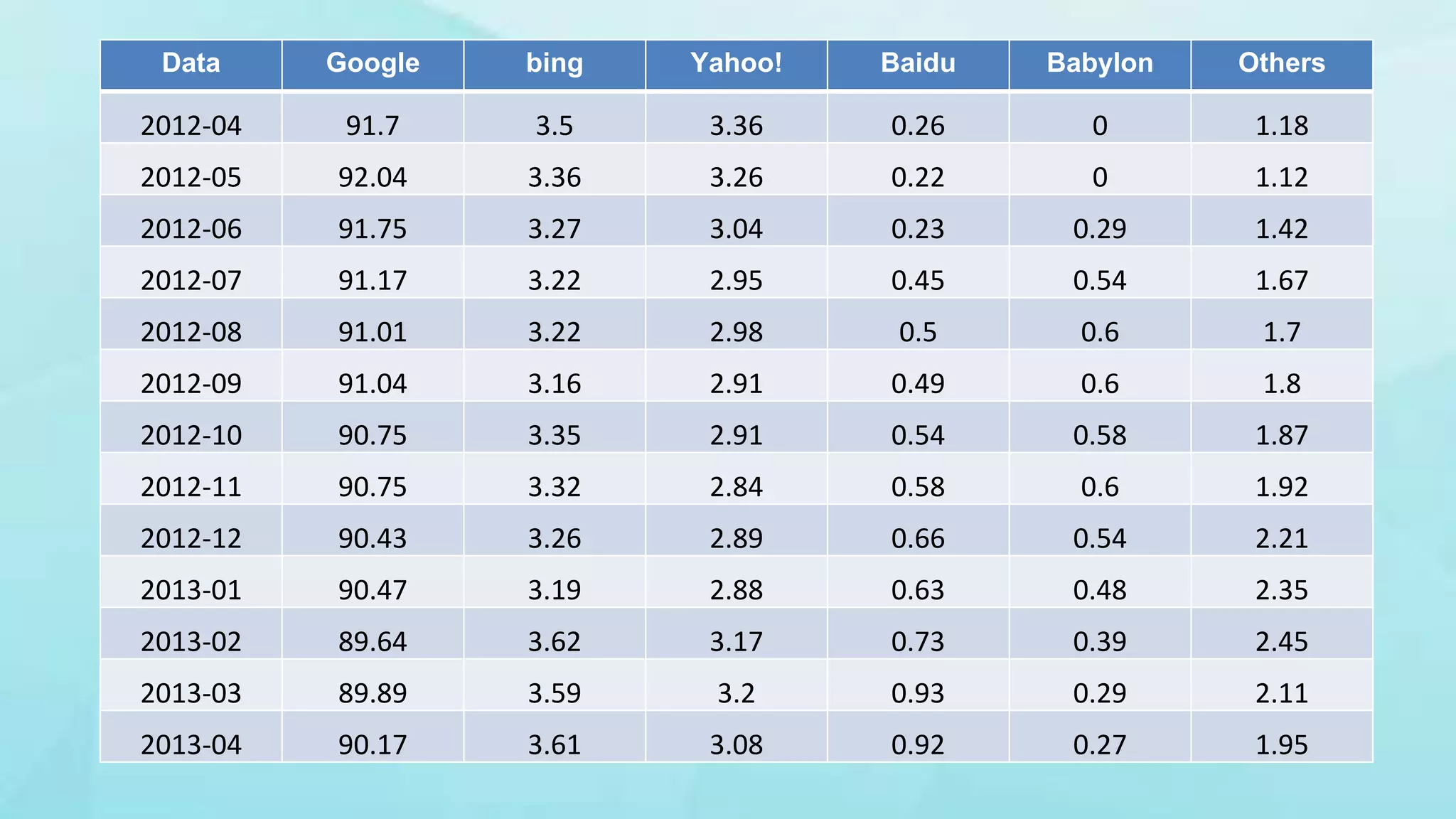










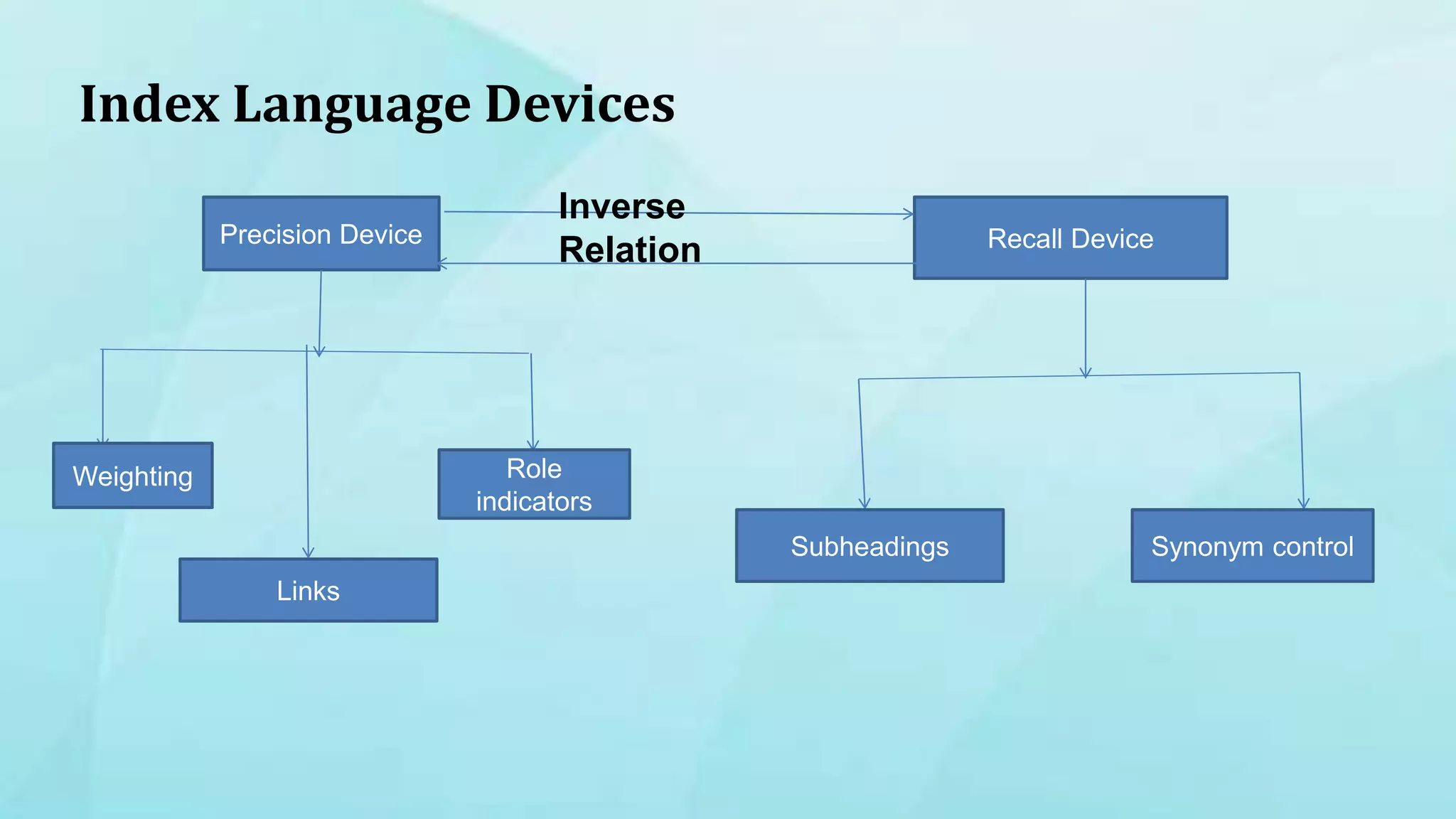




1. The document discusses indexing techniques and their usage in modern search engines. It covers the transition from manual to automated indexing and different indexing methods. 2. Current trends in indexing and information retrieval are discussed such as XML indexing and its components. Future applications for indexers are also mentioned. 3. The conclusion emphasizes enhancements to indexing procedures like weighted indexing and linking of terms to improve retrieval of accurate information.






















































































