Downloaded 27 times

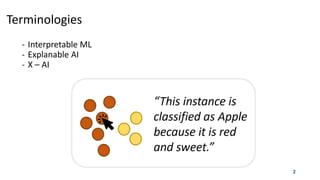



![Attention Mechanisms
Attention mechanisms guide deep neural networks to focus on
relevant input features, which allows to interpret how the model made
certain predictions.
9
[Bahdanau et al. 15] Neural Machine Translation by Jointly Learning to Align and Translate, ICLR 2015](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-9-320.jpg)








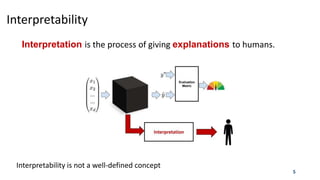
![Understanding Black-Box Predictions
Given a high-accuracy blackbox model and a prediction from it, can we
answer why the model made a certain prediction?
[Koh and Liang 17] tackles this question by training a model’s prediction through its learning algorithm
and back to the training data.
To formalize the impact of a training point on a prediction, they ask the counterfactual:
What would happen if we did not have this training point or if its value were slightly changed?
18
[Koh and Liang 17] Understanding Black-box Predictions via Influence Functions, ICML 2017](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-18-320.jpg)
![Interpretable Mimic Learning
This framework is mainly based on knowledge distillation from Neural
Networks.
However, they use Gradient Boosting Trees (GBT) instead of another neural
network as the student model since GBT satisfies our requirements for
both learning capacity and interpretability.
19[Che et al. 2016] Z. Che, S. Purushotham, R. Khemani, and Y. Liu. Interpretable Deep Models for
ICU outcome prediction, AMIA 2016.
Knowledge distillation
G. Hinton et al. 15](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-19-320.jpg)
![Interpretable Mimic Learning
The resulting simple model works even better than the best deep learning
model – perhaps due to suppression of the overfitting.
20[Che et al. 2016] Z. Che, S. Purushotham, R. Khemani, and Y. Liu. Interpretable Deep Models for
ICU outcome prediction, AMIA 2016.](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-20-320.jpg)
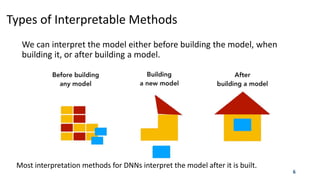
![Visualizing Convolutional Neural Networks
Propose Deconvolution Network (deconvnet) to inversely map the feature
activations to pixel space and provide a sensitivity analysis to point out
which regions of an image affect to decision making process the most.
21
[Zeiler and Fergus 14] Visualizing and Understanding Convolutional Networks, ECCV 2014](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-21-320.jpg)
![Prediction difference analysis
22
The visualization method shows which pixels of a specific input image are
evidence for or against a prediction
[Zintgraf et al. 2017] Visualizing Deep Neural Network Decisions: Prediction Difference Analysis, ICLR 2017
Shown is the evidence for (red) and against (blue) the prediction.
We see that the facial features of the cockatoo are most supportive for the decision, and
parts of the body seem to constitute evidence against it.](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-22-320.jpg)

![Understanding Data Through Examples
[Kim et al. 16] propose to interpret the given data by providing examples
that can show the full picture – majorities + minorities
[Kim et al. 16] Examples are not Enough, Learn to Criticize! Criticism for Interpretability 24](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-24-320.jpg)











![37
Over-generalization
Over-generalization is consistent with evolutionary
theory [Zebrowitz ‘10, Schaller’ 06]
algorithms can help against over-generalization](https://image.slidesharecdn.com/introductiontointerpretableml-giangnguyen-191118063830/85/Introduction-to-Interpretable-Machine-Learning-36-320.jpg)


















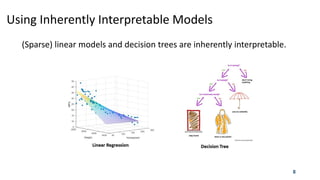
This document discusses interpretable machine learning and explainable AI. It begins with definitions of key terms and an overview of interpretable methods. Deep learning models are often treated as "black boxes" that are difficult to interpret. Interpretability can be achieved by using inherently interpretable models like linear models or decision trees, adding attention mechanisms, or interpreting models before, during or after building them. Later sections discuss specific interpretable techniques like understanding data through examples, MMD-Critic for learning prototypes and criticisms, and visualizing convolutional neural networks to understand predictions. The document emphasizes the importance of interpretability and explains several approaches to make machine learning models more transparent to humans.












































































