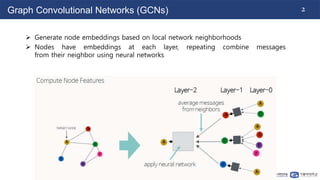
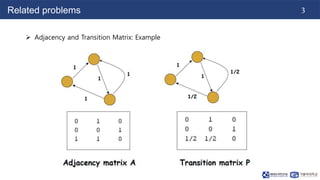
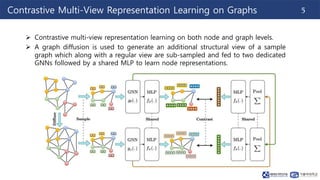
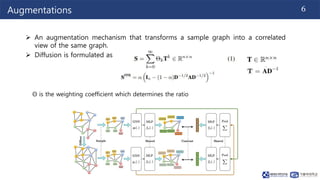
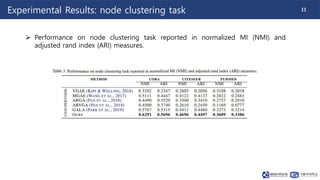
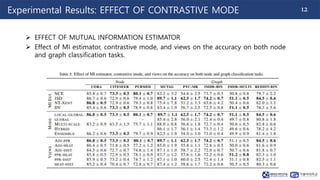
This document summarizes a paper on contrastive multi-view representation learning on graphs. It proposes generating two structural views of a graph, including encodings from first-order neighbors and a graph diffusion, and learning node and graph representations by contrasting the encodings from the two views using mutual information. The best performance is achieved with two views contrasting first-order neighbors and a graph diffusion. Increasing the number of views or contrasting multi-scale encodings does not further improve performance.



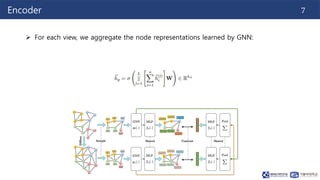
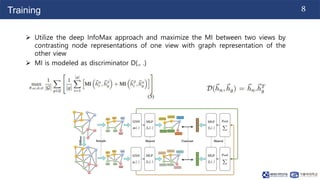
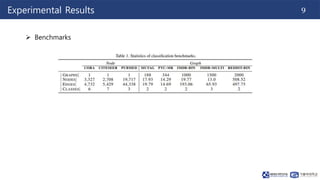
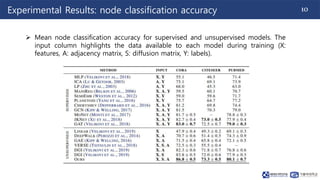


![240311_Thuy_Labseminar[Contrastive Multi-View Representation Learning on Graphs].pptx](https://image.slidesharecdn.com/240311thuylabseminar-240409105318-e4ddfee7/85/240311_Thuy_Labseminar-Contrastive-Multi-View-Representation-Learning-on-Graphs-pptx-15-320.jpg)














![[NS][Lab_Seminar_240617]A Survey on Graph Neural Networks and Graph Transform...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240617asurvey-240624082546-9e44d3fd-thumbnail.jpg?width=640&height=640&fit=bounds)




![250623_JW_labseminar[STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250623jwlabseminarcontextpred-250627073644-0949d35d-thumbnail.jpg?width=640&height=640&fit=bounds)



![251124_Thuy_Labseminar[Vision GNN: An Image is Worth Graph of Nodes].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thuylabseminar-251124113257-025487fe-thumbnail.jpg?width=640&height=640&fit=bounds)









![[NS][Lab_Seminar_260126]MIHC: Multi-View Interpretable Hypergraph Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar260126-260126110047-559006b2-thumbnail.jpg?width=640&height=640&fit=bounds)
![260119_SH_LabSeminar[ENGRAM]_최종2_최종3_4.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/260119shlabseminarengram234-260120052642-29f38c8f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NS][Lab_Seminar_260119][DHGFormer: Dynamic Hierarchical Graph Transformer fo...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar260119-260120052625-9b28e6ed-thumbnail.jpg?width=640&height=640&fit=bounds)




![260105_JH_LabSeminar[A Plant-Wide Industrial Process Control Problem].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/260105jhlabseminartep-260106063928-34e9f1f6-thumbnail.jpg?width=640&height=640&fit=bounds)
























