This document introduces the deep reinforcement learning model 'A3C' by Japanese.
Original literature is "Asynchronous Methods for Deep Reinforcement Learning" written by V. Mnih, et. al.
今回取り上げるのはこれ
[1] Volodymyr Mnih,Adria` Puigdome`nech Badia, Mehdi
Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David
Silver, and Koray Kavukcuoglu. Asynchronous methods for
deep reinforcement learning. In Proceedings of the 33rd
International Conference on Machine Learning (ICML), pp.
1928–1937, 2016.
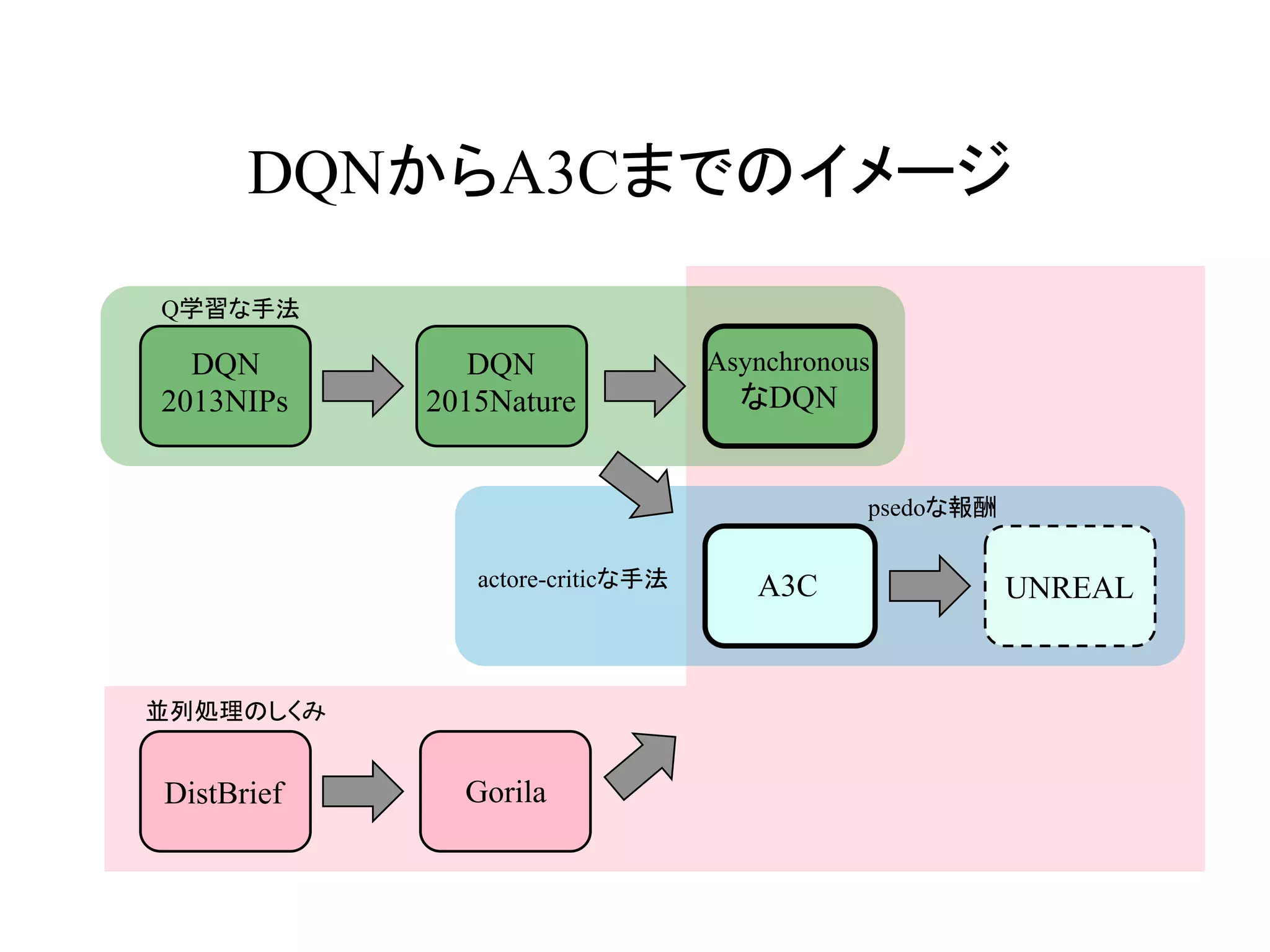
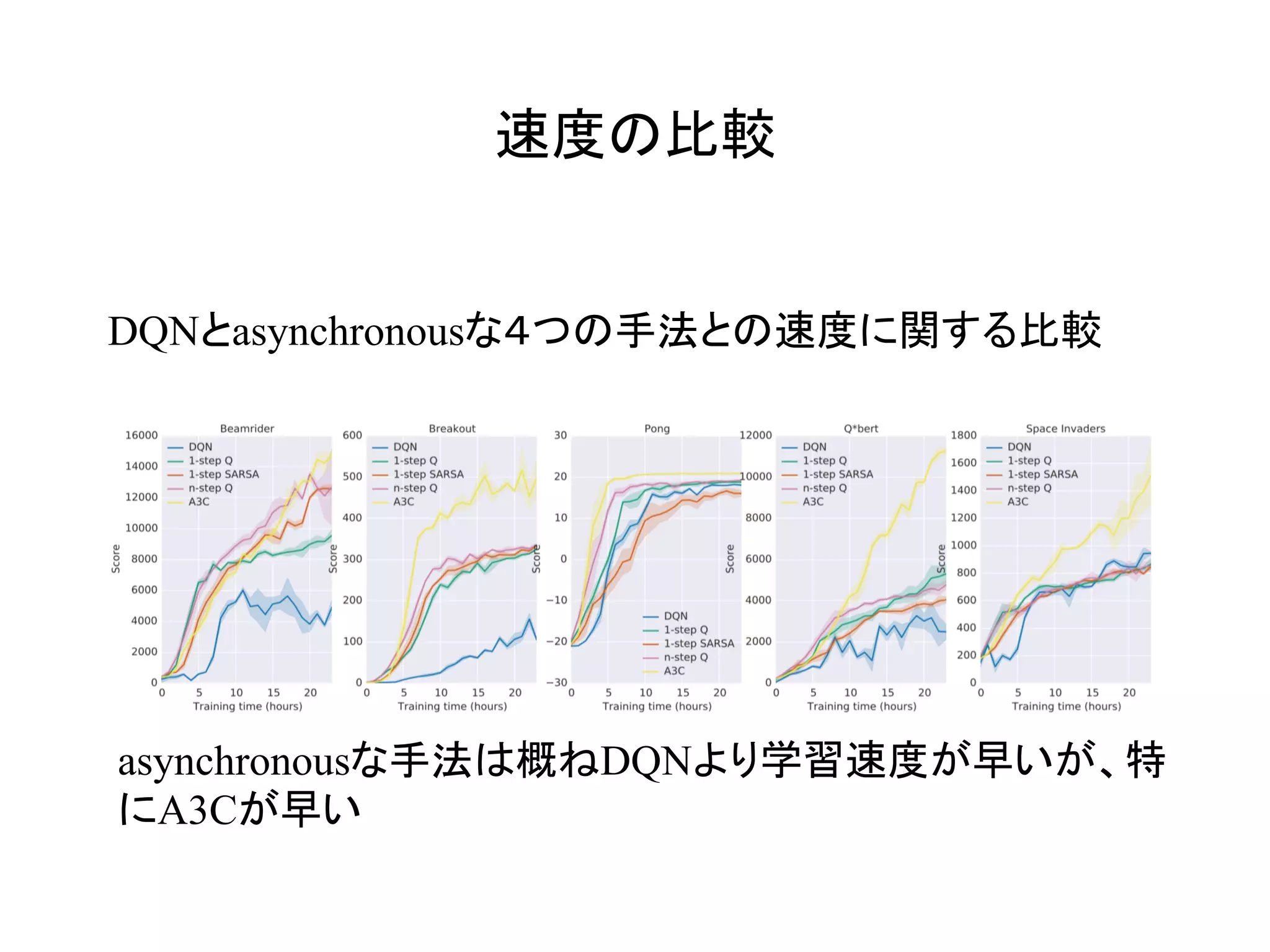
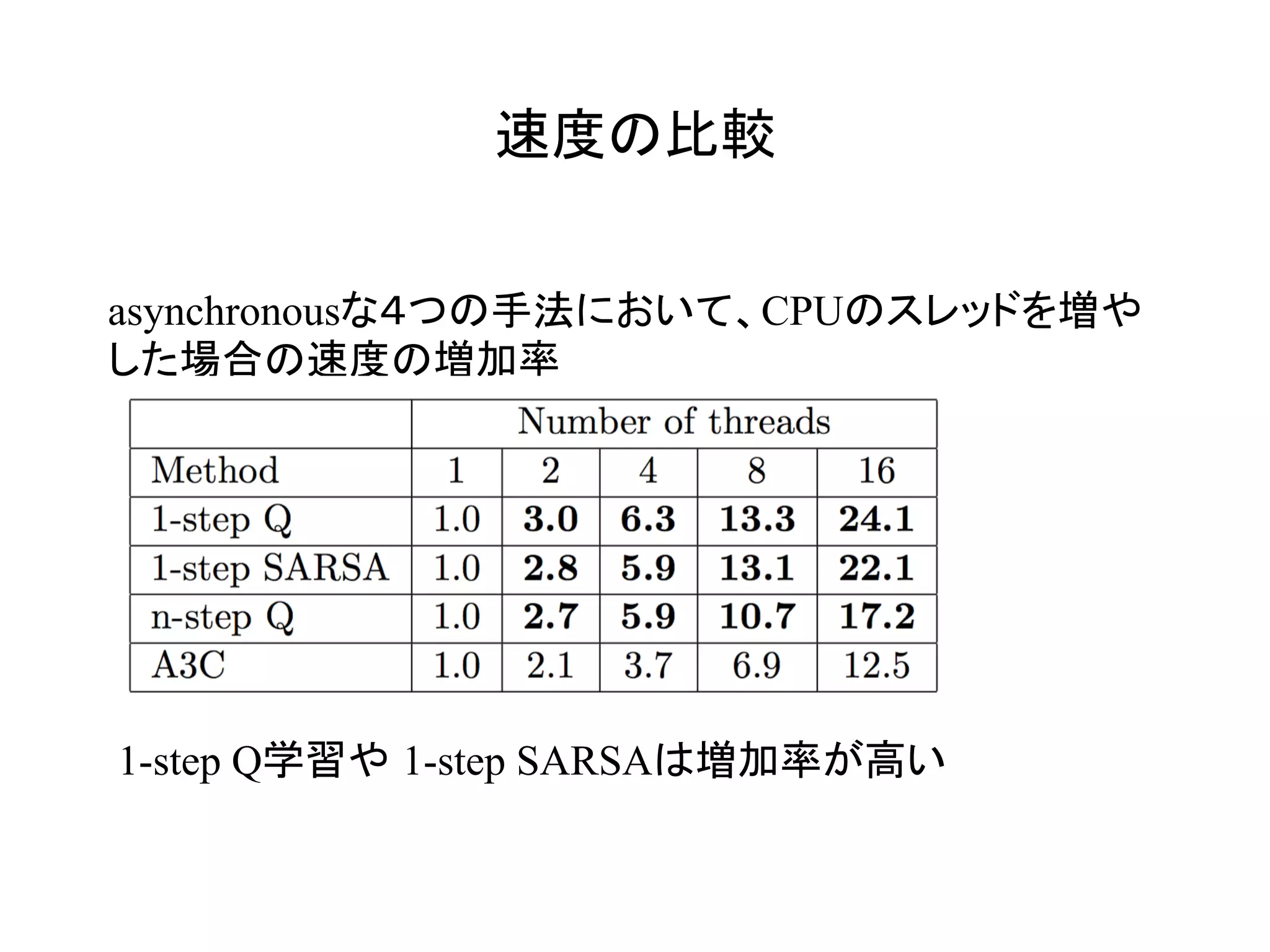
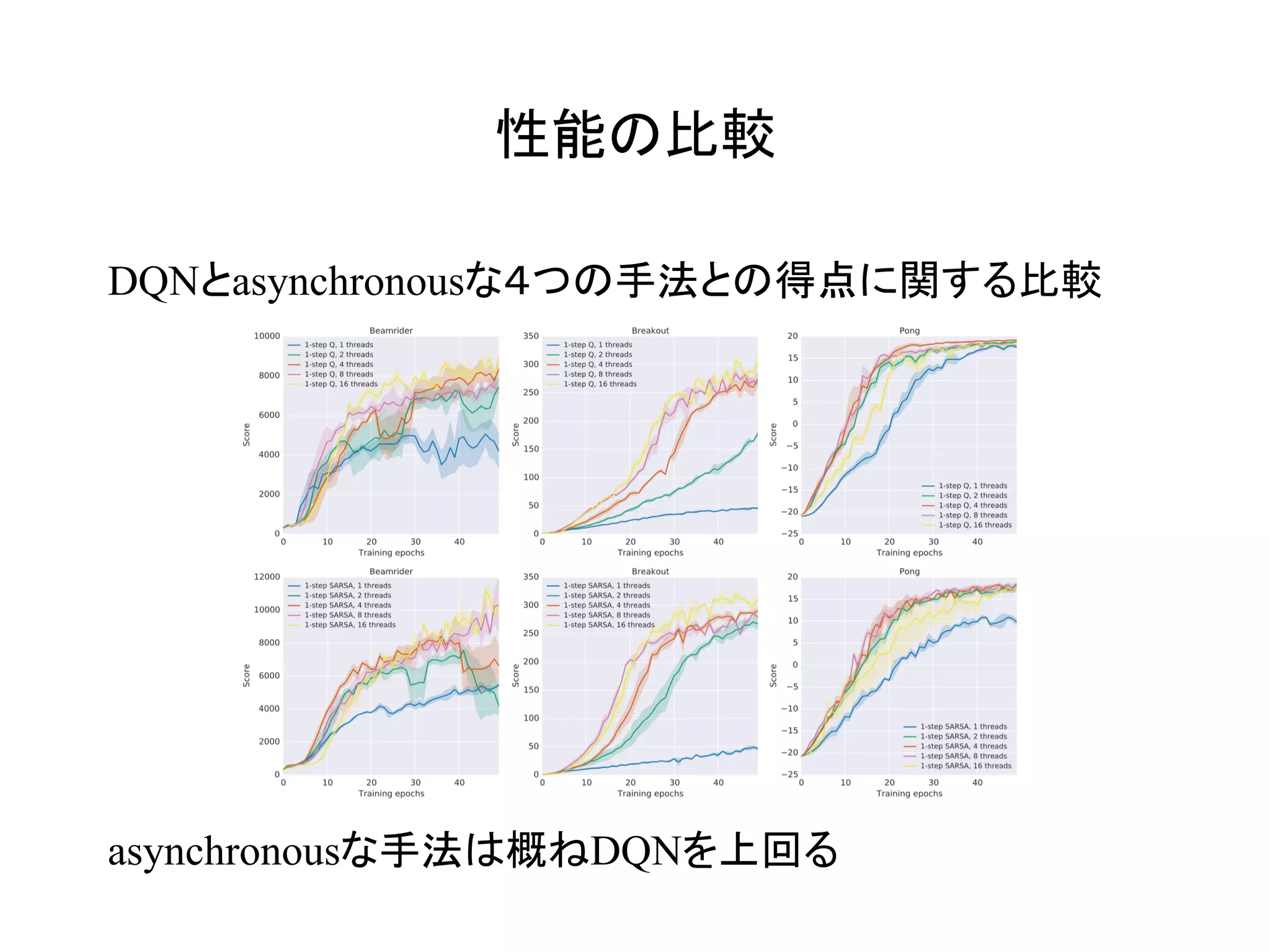
Asynchronousな手法によりreplay memoryを廃し、DQNより
高速かつ高精度な学習を達成した!
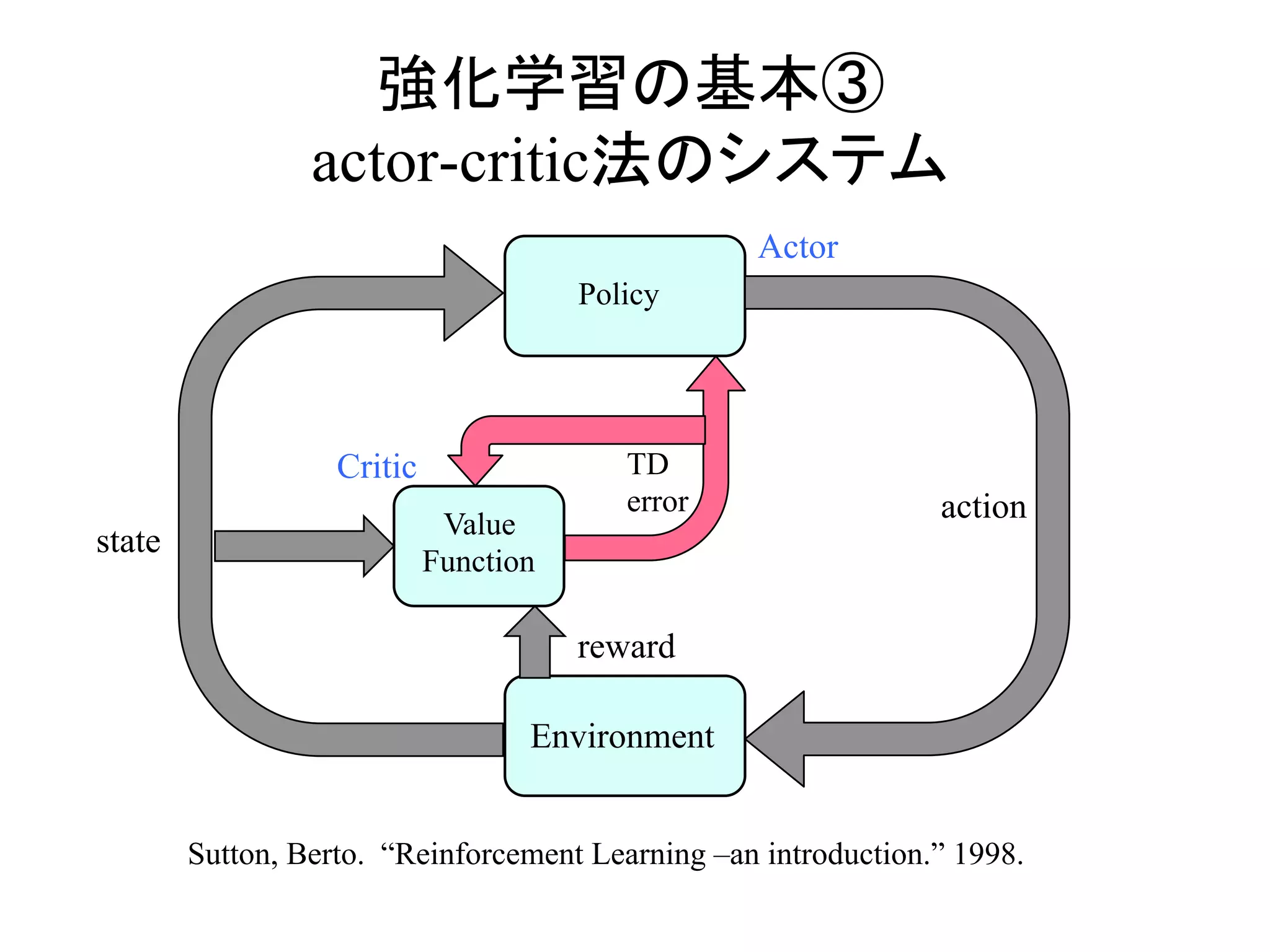
強化学習の基本①
Li θi( )=E r +γ max
a'
Q s',a';θi−1( )−Q s,a;θi( )( )
2
1-step Q学習の損失関数
actor-criticにおける
目的関数の勾配
1-step Sarsaの損失関数 Li θi( )= E r +γQ s',a';θi−1( )−Q s,a;θi( )( )
2
n-step Q学習の損失関数 Li θi( )= E γk
rt+k
k=0
n
∑ + maxγ
a'
n
Q s',a';θi−1( )−Q s,a;θi( )
⎛
⎝
⎜
⎞
⎠
⎟
2
∇θ J θ( )= E ∇θ logπ at | st;θ( ) Rt −Vπ
st( )( )⎡
⎣
⎤
⎦
r
γ Q s,a;θi( )
Vπ
st( )
:割引率
:報酬
:状態 s で行動 a を取る場合の行動価値関数
:状態 s の価値関数
5.
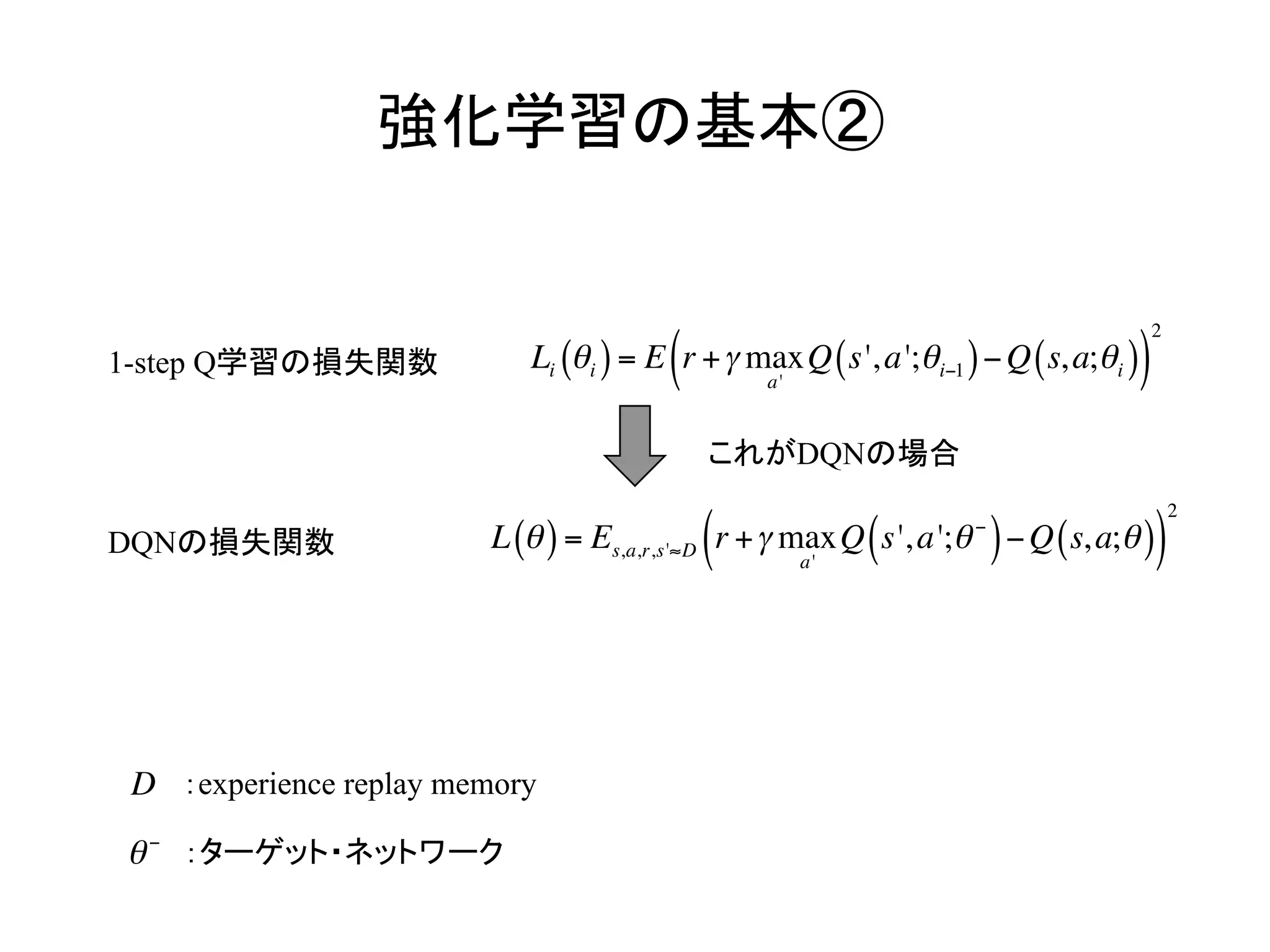
強化学習の基本②
Li θi( )=E r +γ max
a'
Q s',a';θi−1( )−Q s,a;θi( )( )
2
1-step Q学習の損失関数
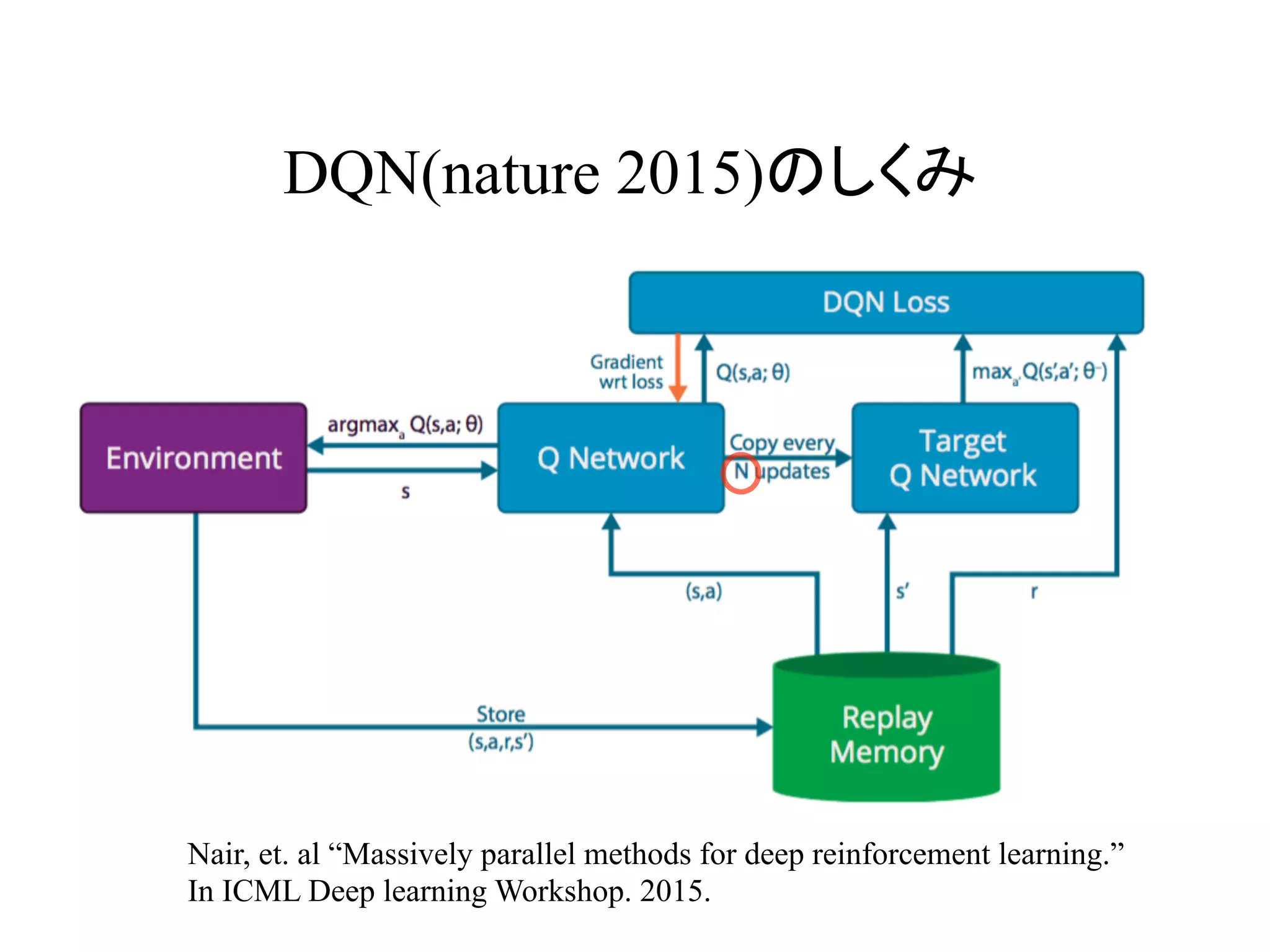
これがDQNの場合
L θ( )= Es,a,r,s'≈D r +γ max
a'
Q s',a';θ−
( )−Q s,a;θ( )( )
2
DQNの損失関数
:experience replay memory
:ターゲット・ネットワーク
D
θ−
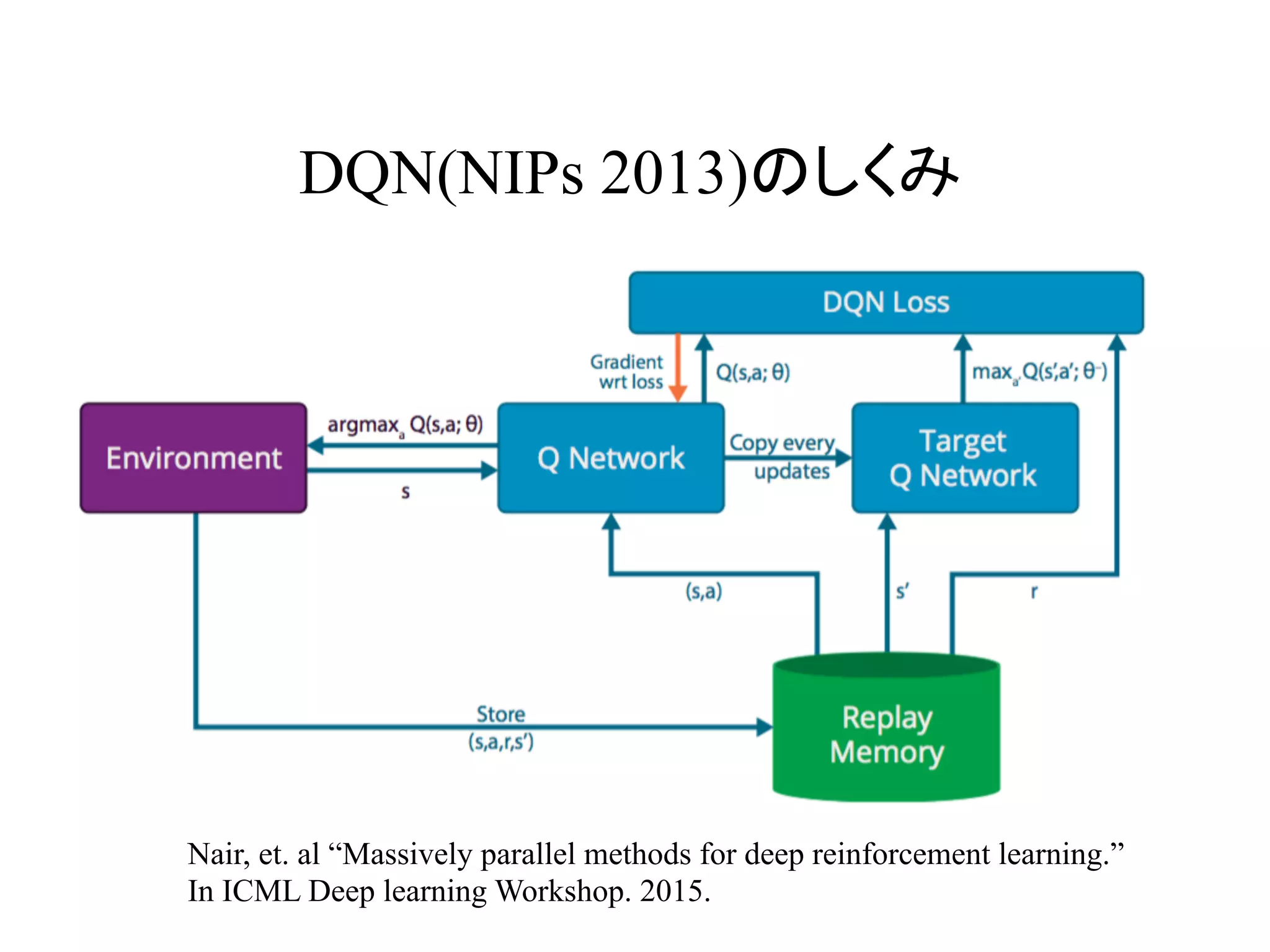
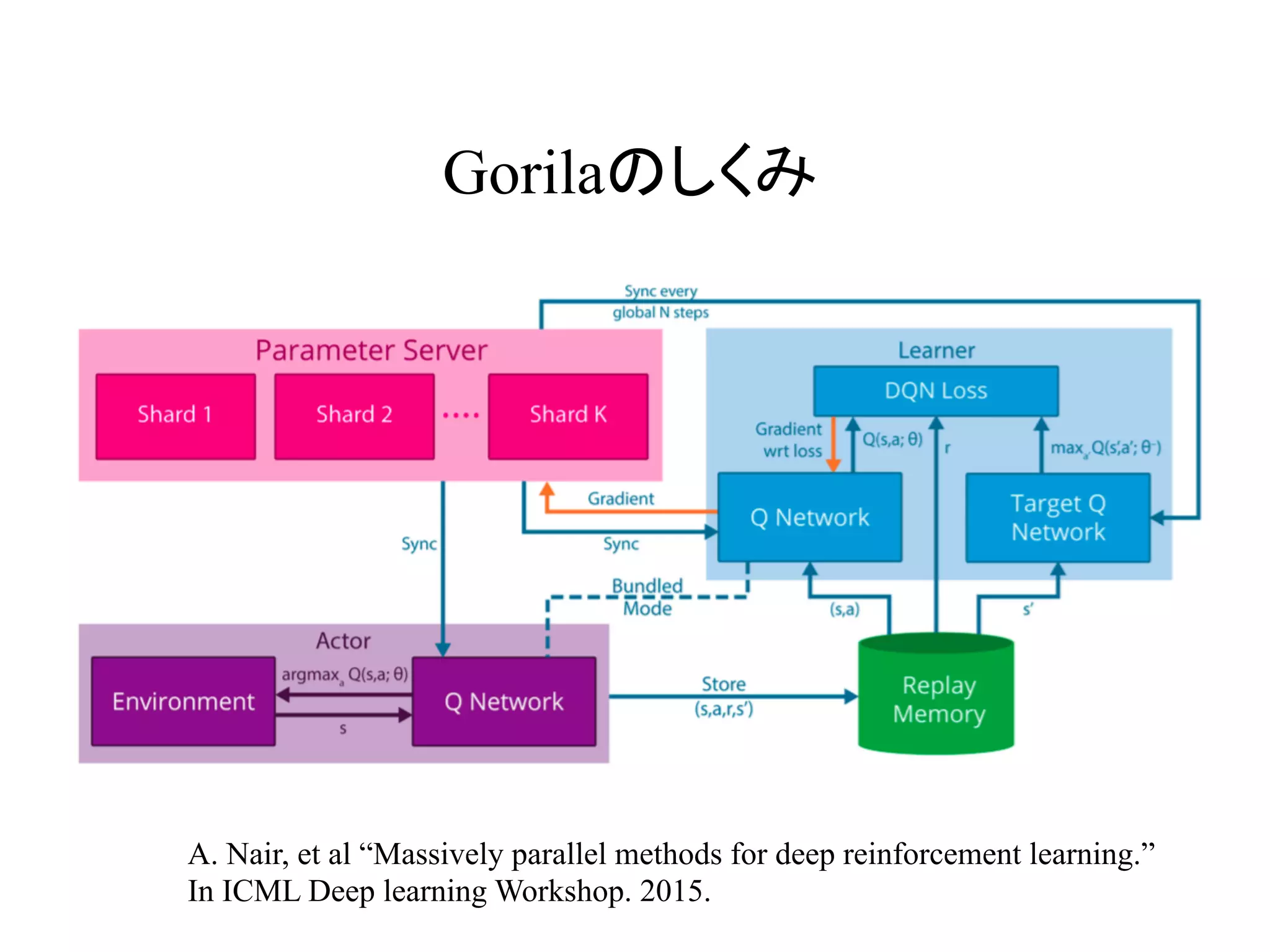
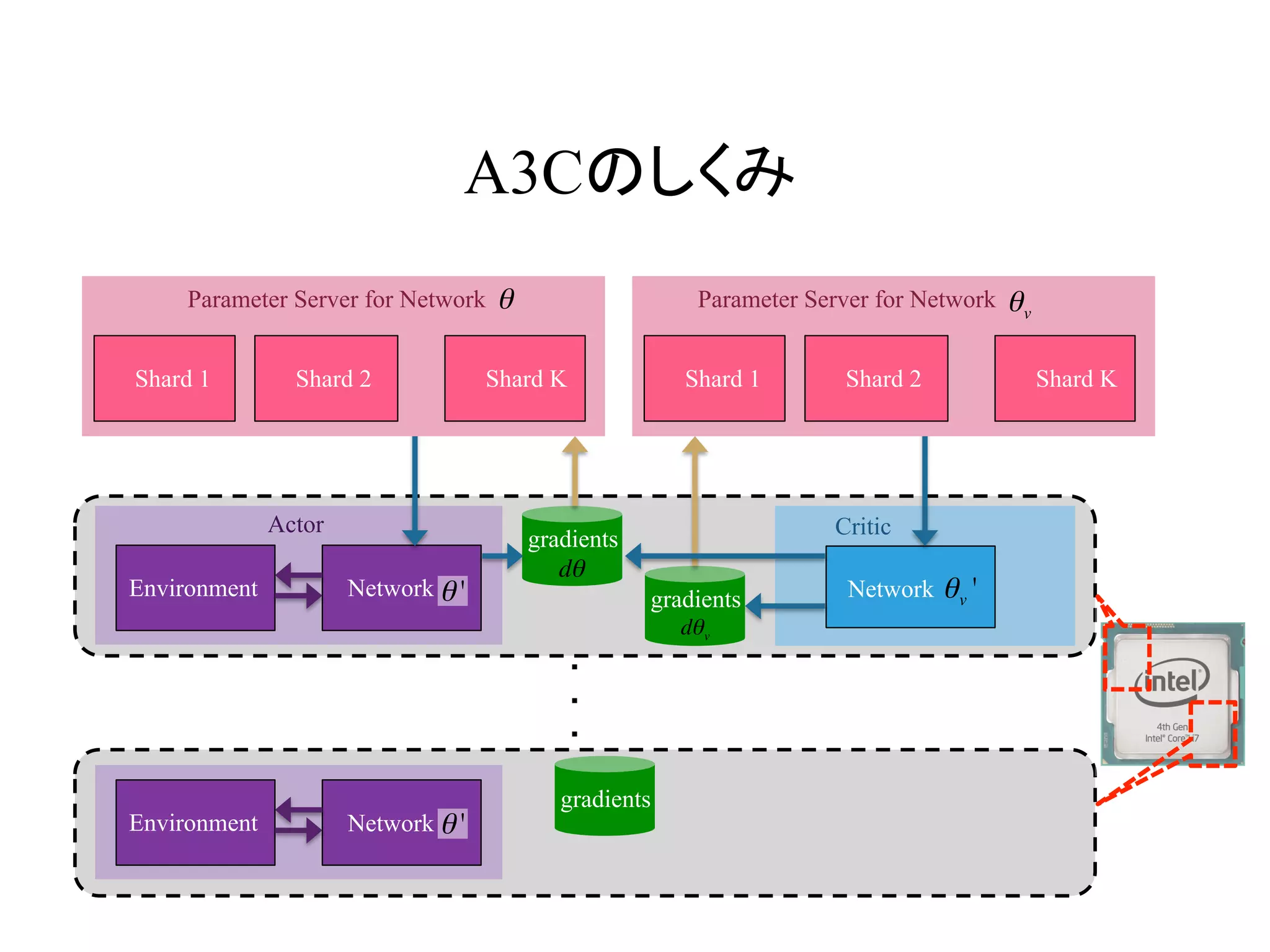
Gorilaのしくみ
A. Nair, etal “Massively parallel methods for deep reinforcement learning.”
In ICML Deep learning Workshop. 2015.
13.
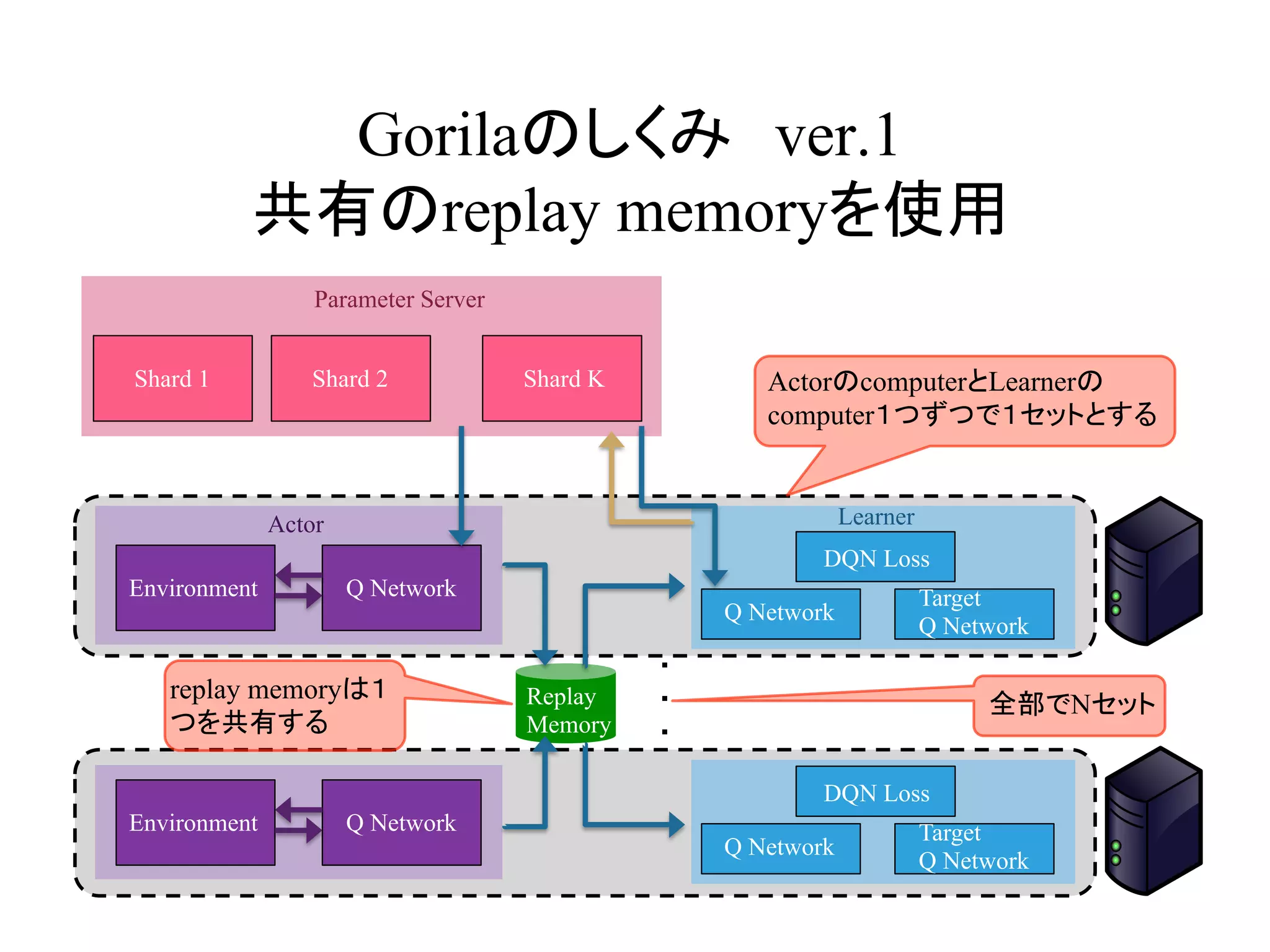
Gorilaのしくみ ver.1
共有のreplay memoryを使用
Environment QNetwork
Shard 1 Shard 2 Shard K
Q Network
Target
Q Network
DQN Loss
Parameter Server
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
ActorのcomputerとLearnerの
computer1つずつで1セットとする
Actor Learner
全部でNセット
replay memoryは1
つを共有する
Replay
Memory
14.
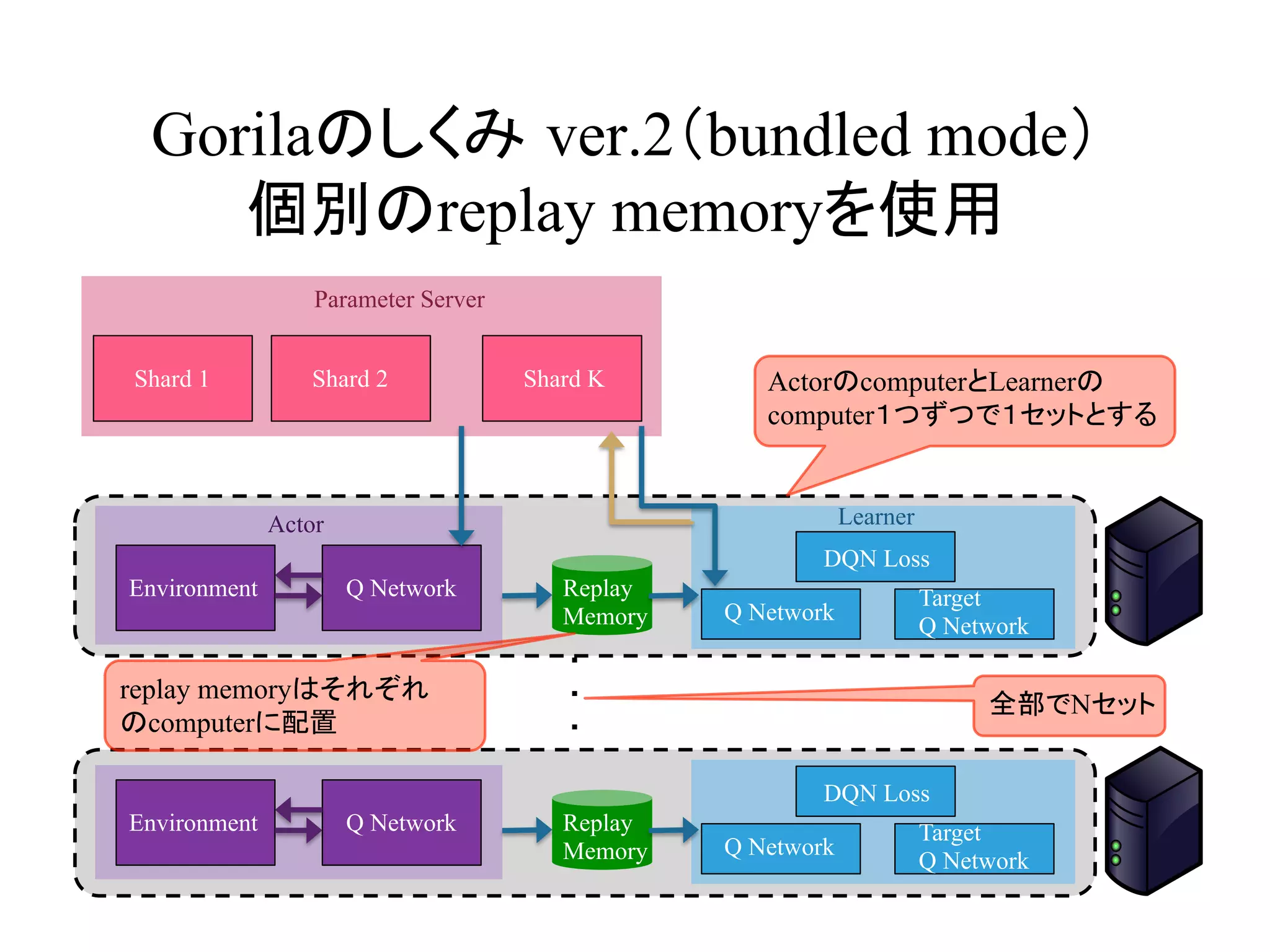
Gorilaのしくみ ver.2(bundled mode)
個別のreplaymemoryを使用
Environment Q Network
Shard 1 Shard 2 Shard K
Q Network
Target
Q Network
DQN Loss
Replay
Memory
Parameter Server
Environment Q Network
Q Network
Target
Q Network
DQN Loss
Replay
Memory
・
・
・
ActorのcomputerとLearnerの
computer1つずつで1セットとする
Actor Learner
全部でNセット
replay memoryはそれぞれ
のcomputerに配置
15.
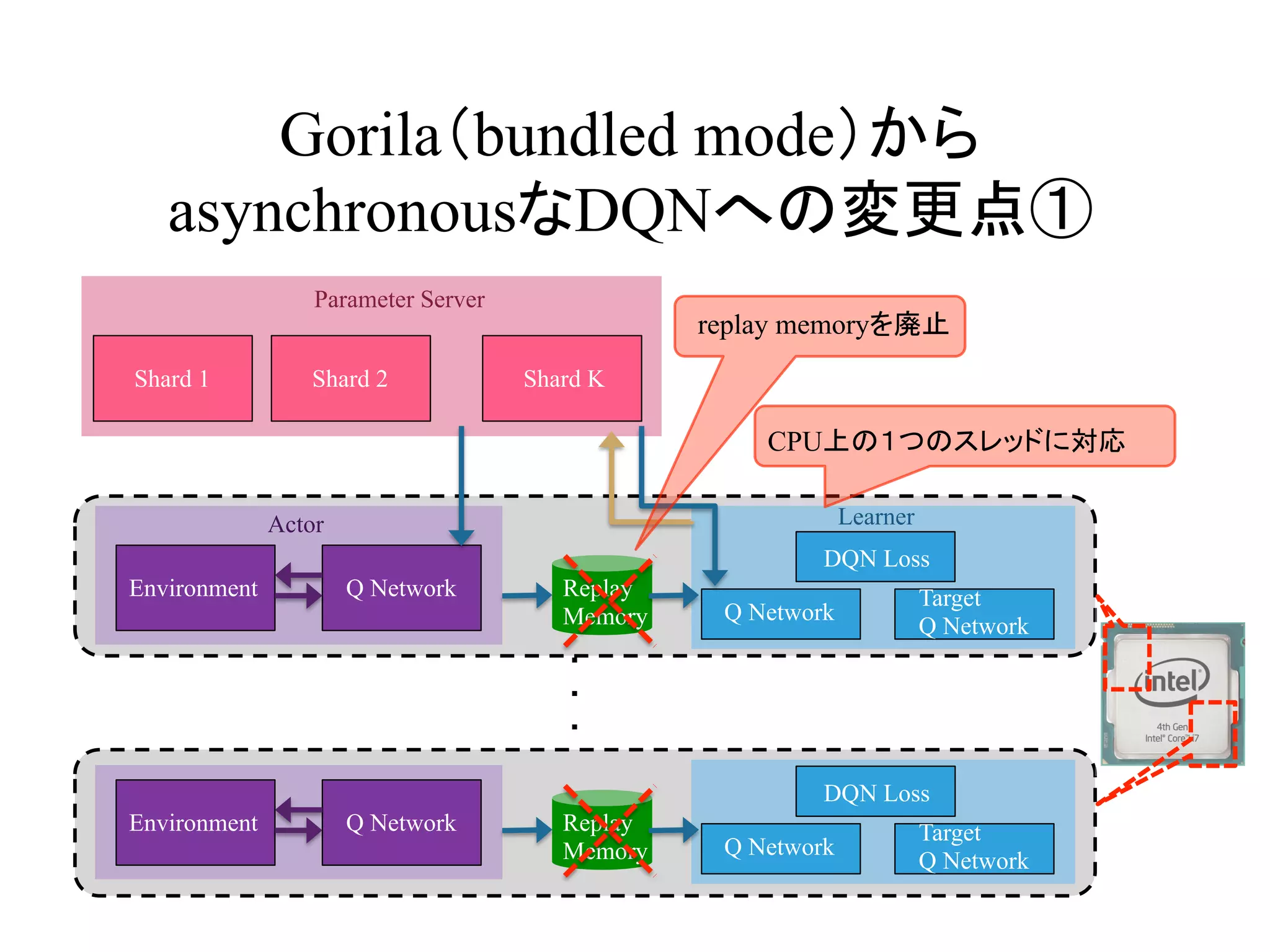
Gorila(bundled mode)から
asynchronousなDQNへの変更点①
Environment QNetwork
Shard 1 Shard 2 Shard K
Q Network
Target
Q Network
DQN Loss
Replay
Memory
Parameter Server
Environment Q Network
Q Network
Target
Q Network
DQN Loss
Replay
Memory
・
・
・
CPU上の1つのスレッドに対応
Actor Learner
replay memoryを廃止
16.
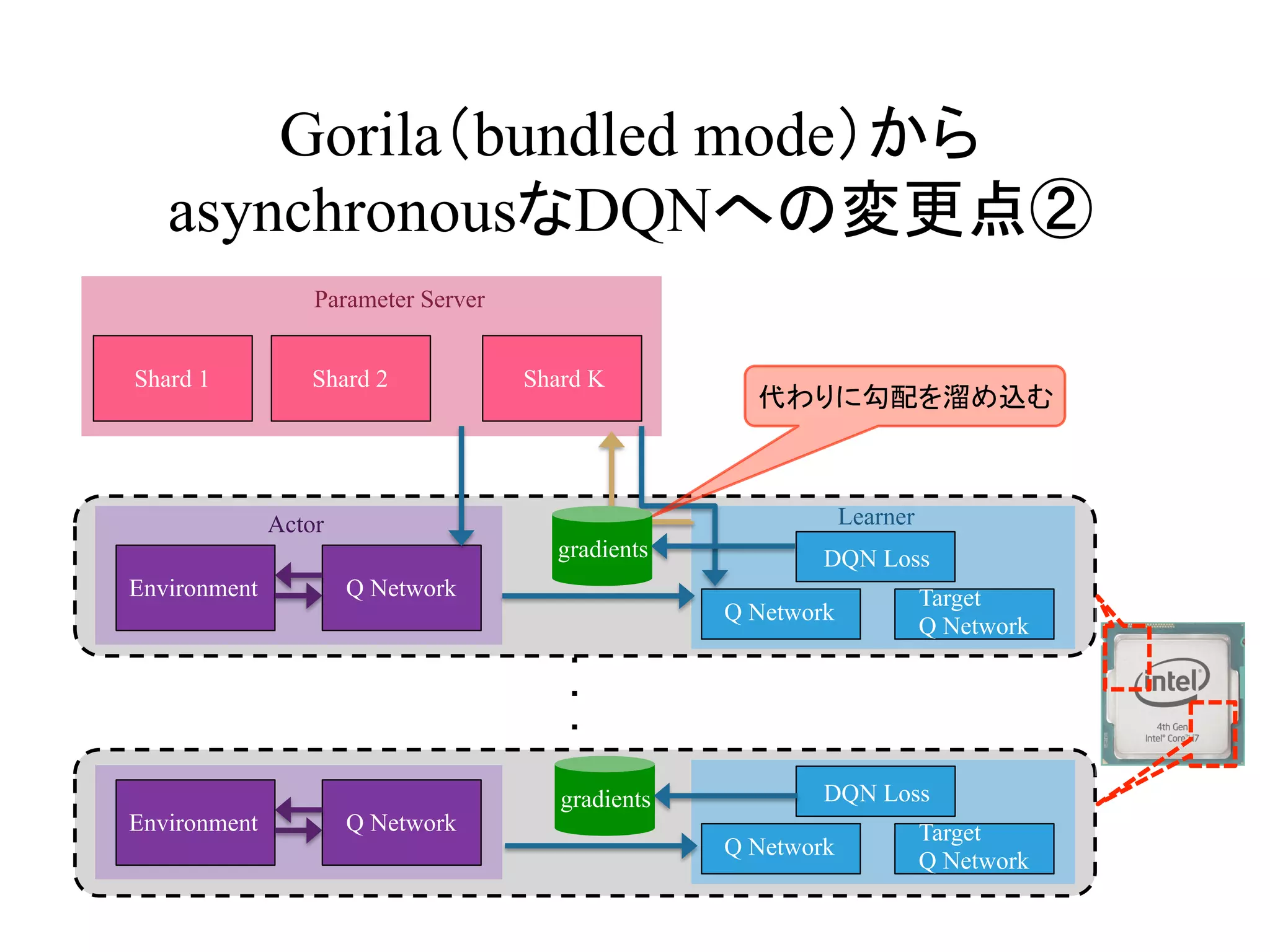
Gorila(bundled mode)から
asynchronousなDQNへの変更点②
Environment QNetwork
Shard 1 Shard 2 Shard K
Q Network
Target
Q Network
DQN Loss
Parameter Server
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
代わりに勾配を溜め込む
gradients
gradients
17.
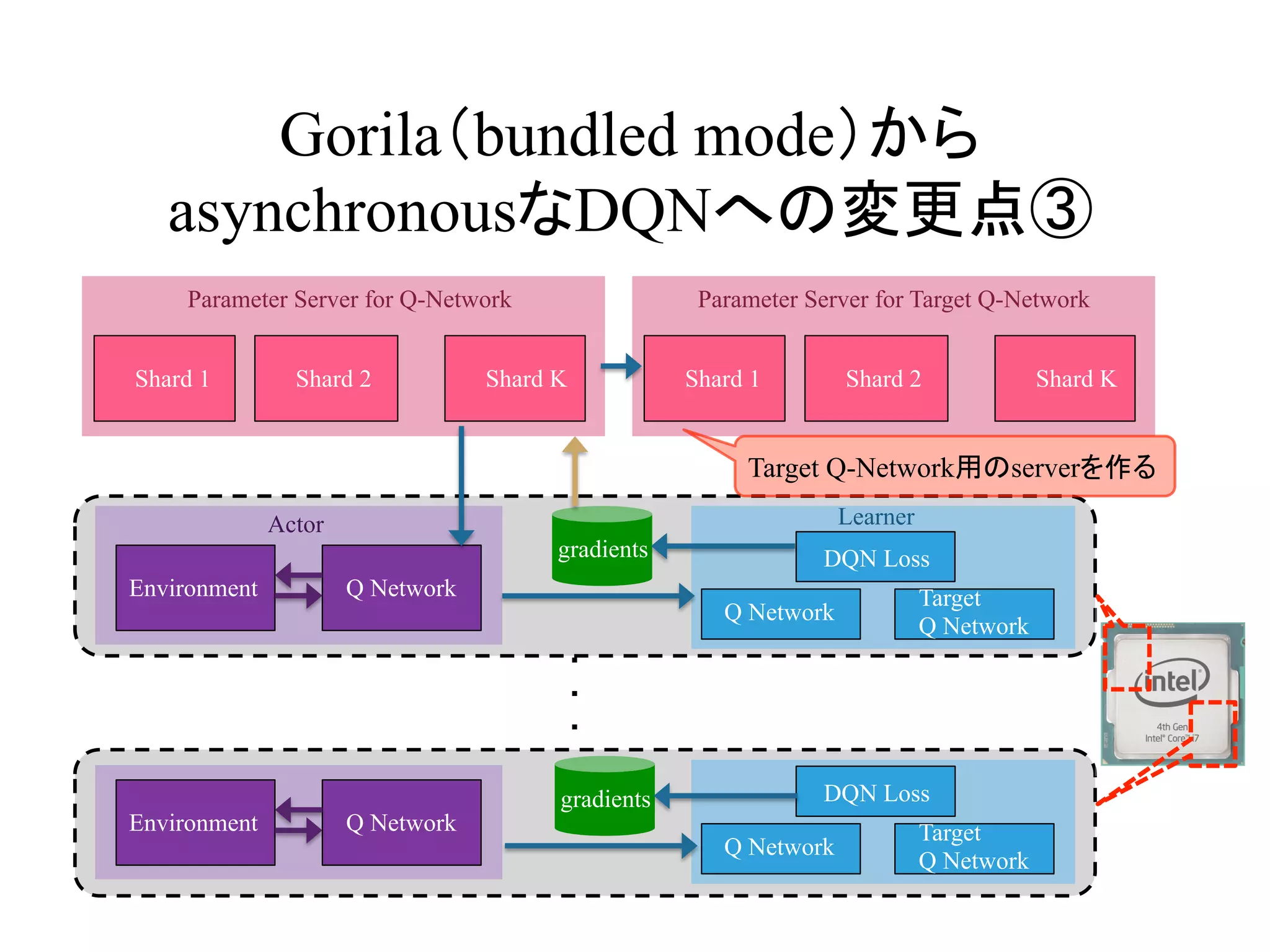
Gorila(bundled mode)から
asynchronousなDQNへの変更点③
Environment QNetwork
Shard 1 Shard 2 Shard K
Q Network
Target
Q Network
DQN Loss
Parameter Server for Q-Network
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
gradients
gradients
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
Target Q-Network用のserverを作る
18.
Shard 1 Shard2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
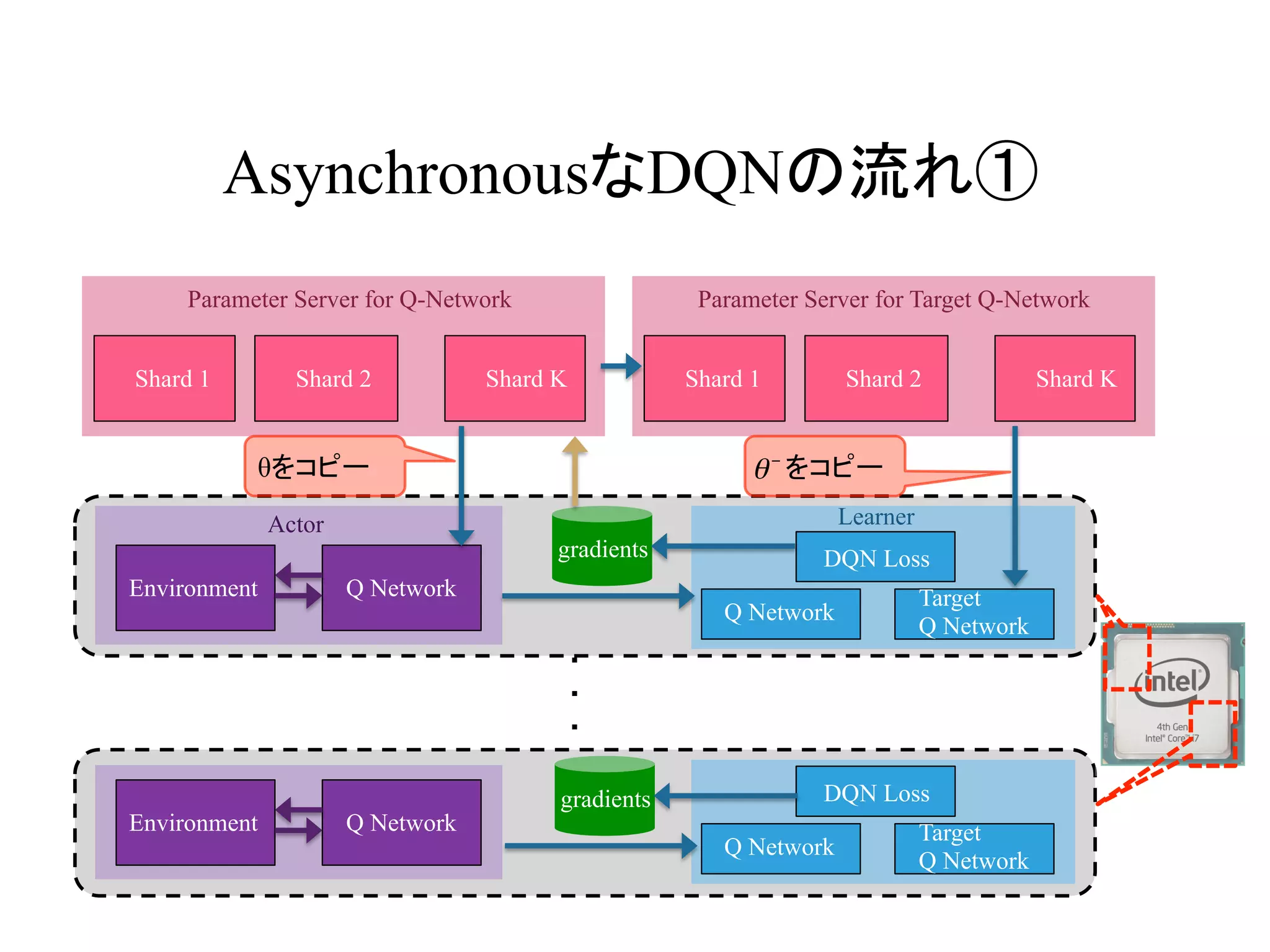
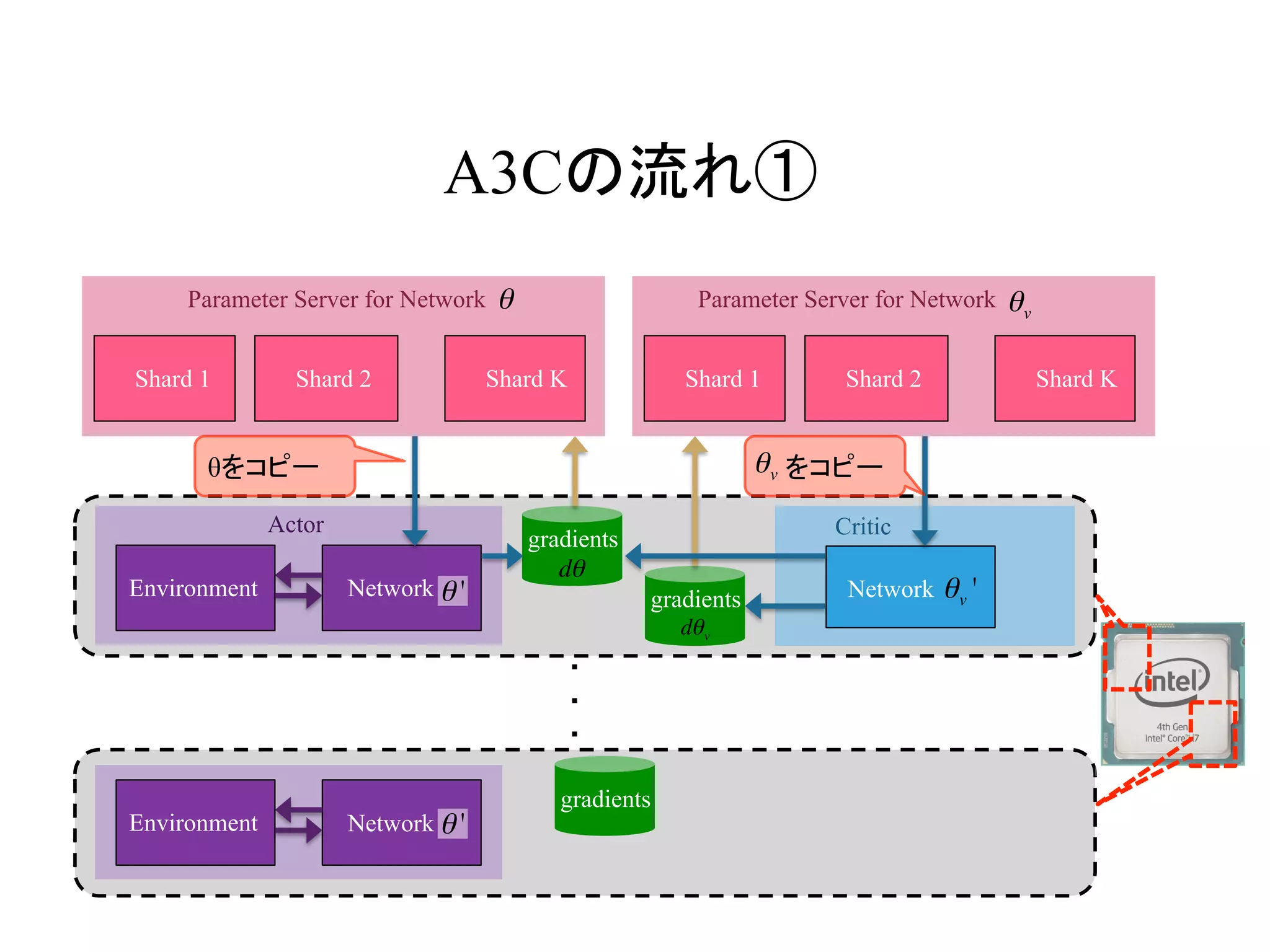
AsynchronousなDQNの流れ①
Environment Q Network
Q Network
Target
Q Network
DQN Loss
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
θをコピー をコピー
gradients
gradients
θ−
19.
Shard 1 Shard2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
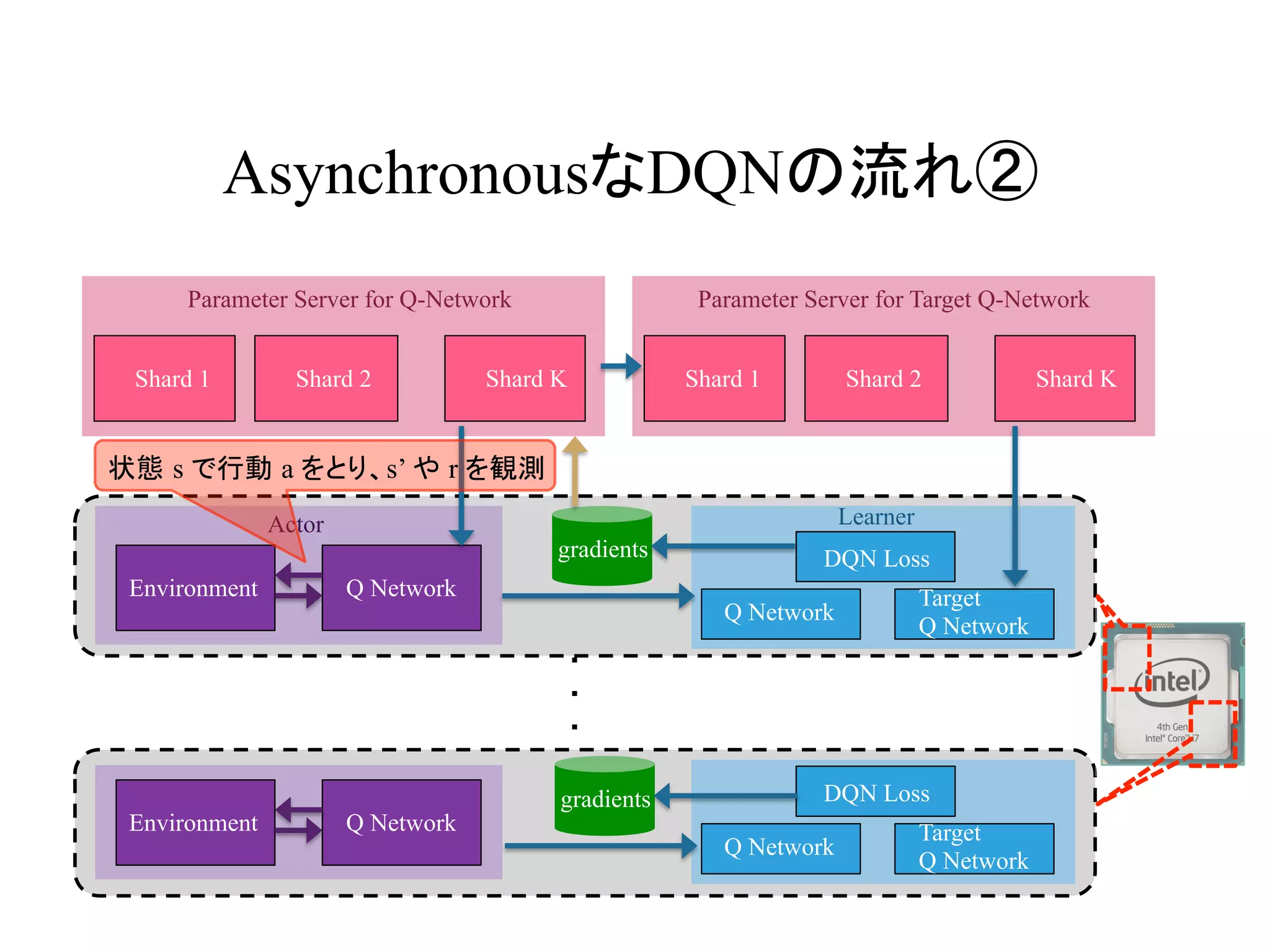
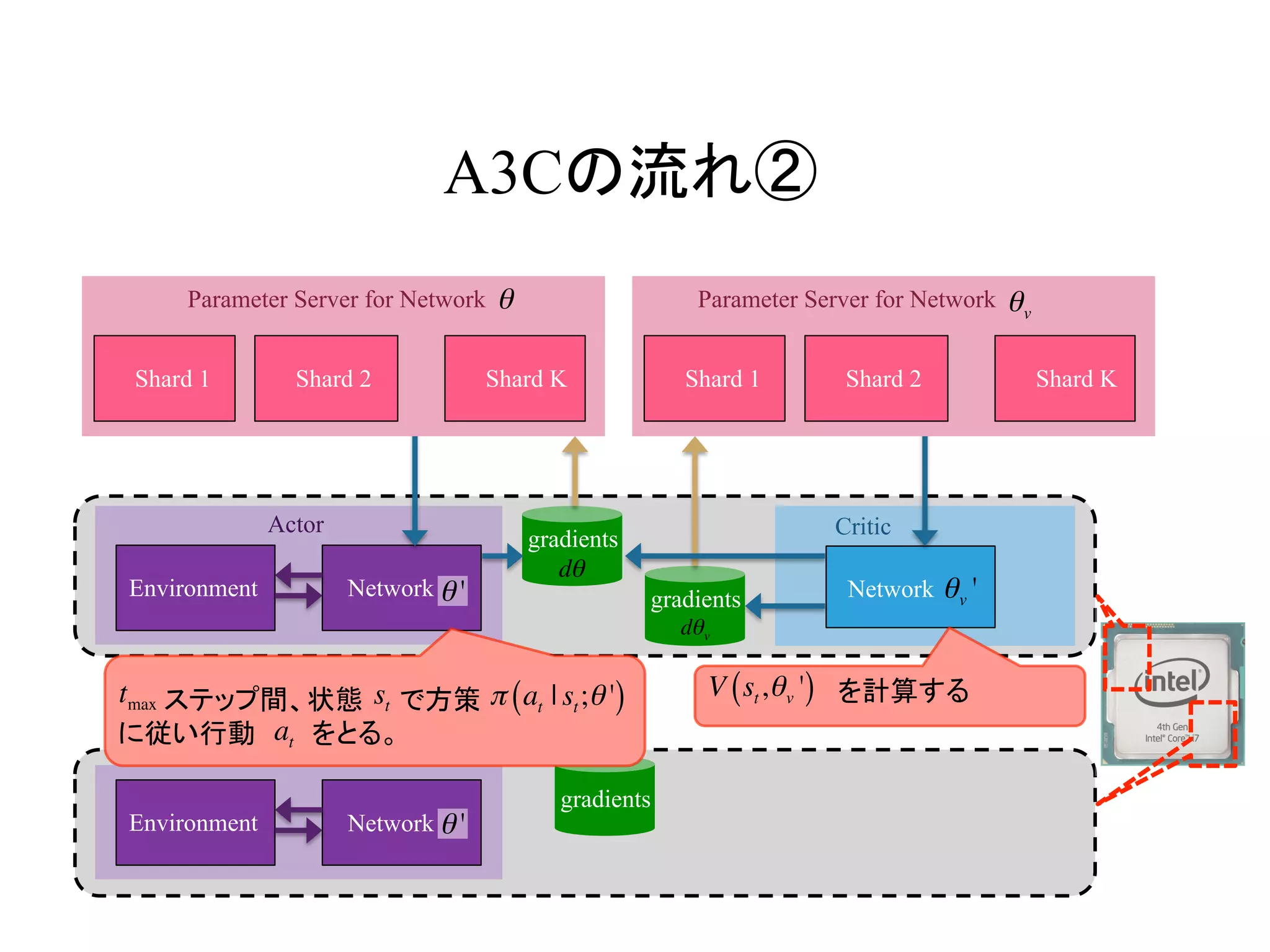
AsynchronousなDQNの流れ②
Environment Q Network
Q Network
Target
Q Network
DQN Loss gradients
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
状態 s で行動 a をとり、s’ や r を観測
gradients
20.
Shard 1 Shard2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
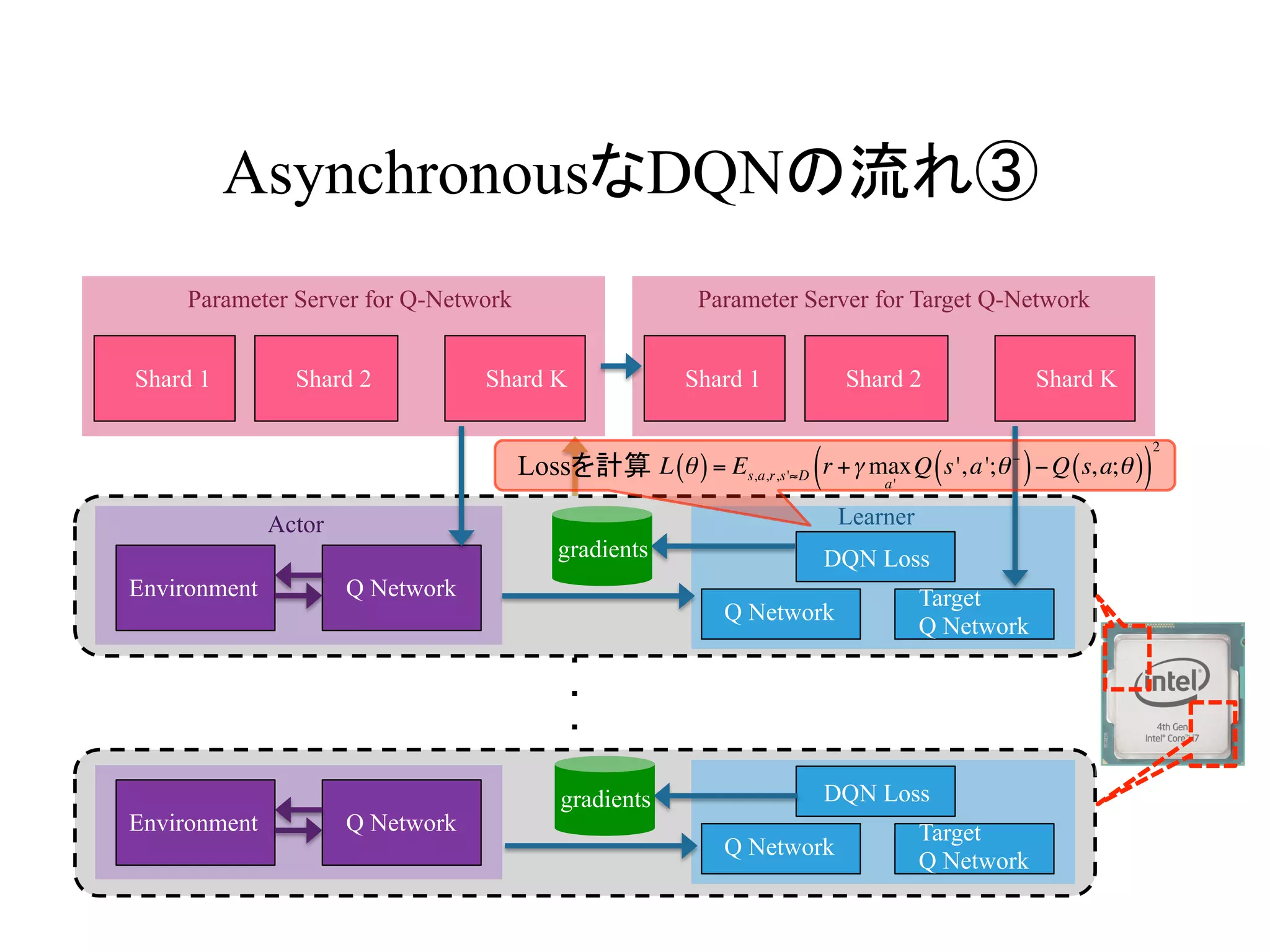
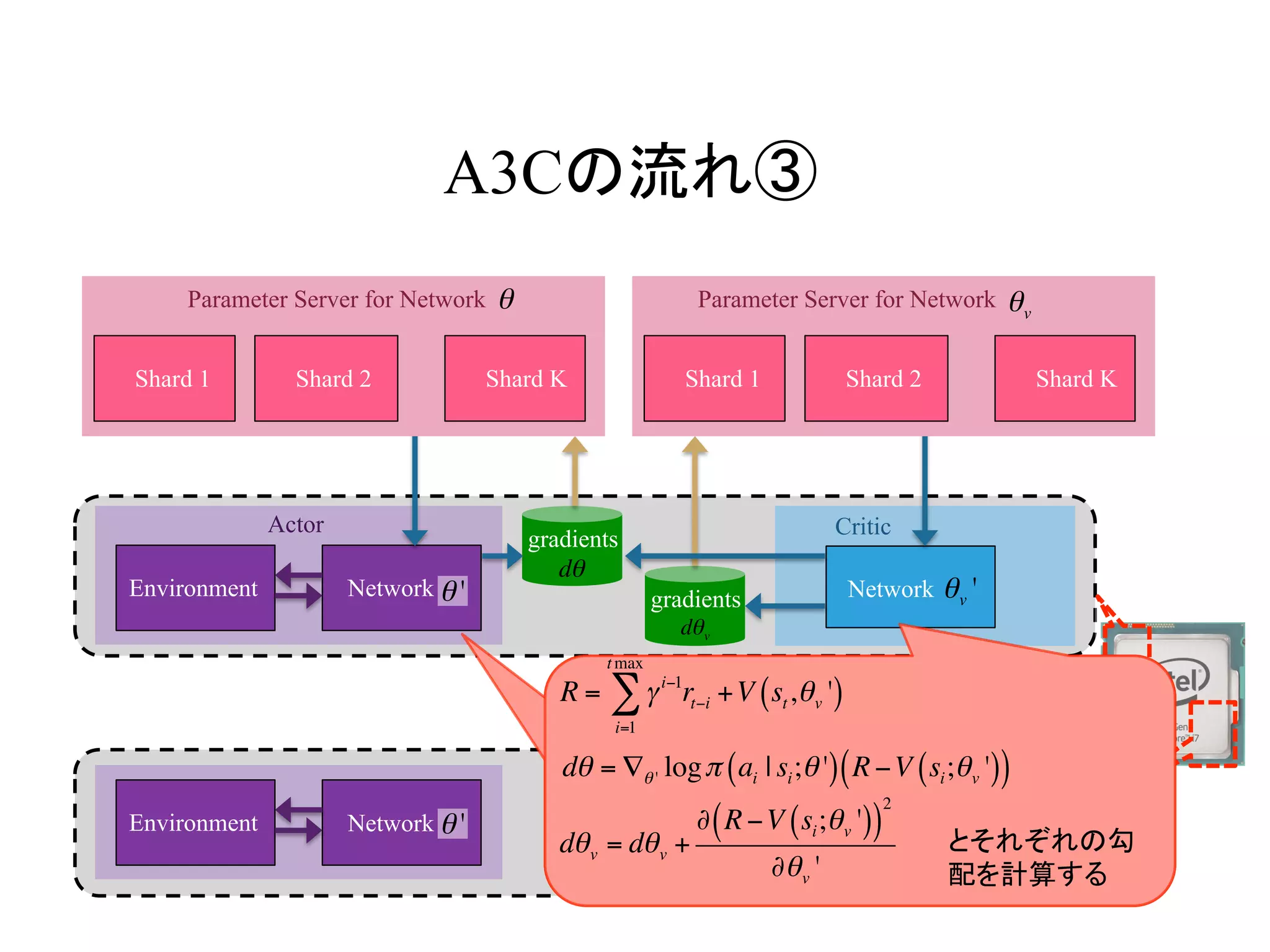
AsynchronousなDQNの流れ③
Environment Q Network
Q Network
Target
Q Network
DQN Loss gradients
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
gradients
L θ( )= Es,a,r,s'≈D r +γ max
a'
Q s',a';θ−
( )−Q s,a;θ( )( )
2
Lossを計算
21.
Shard 1 Shard2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
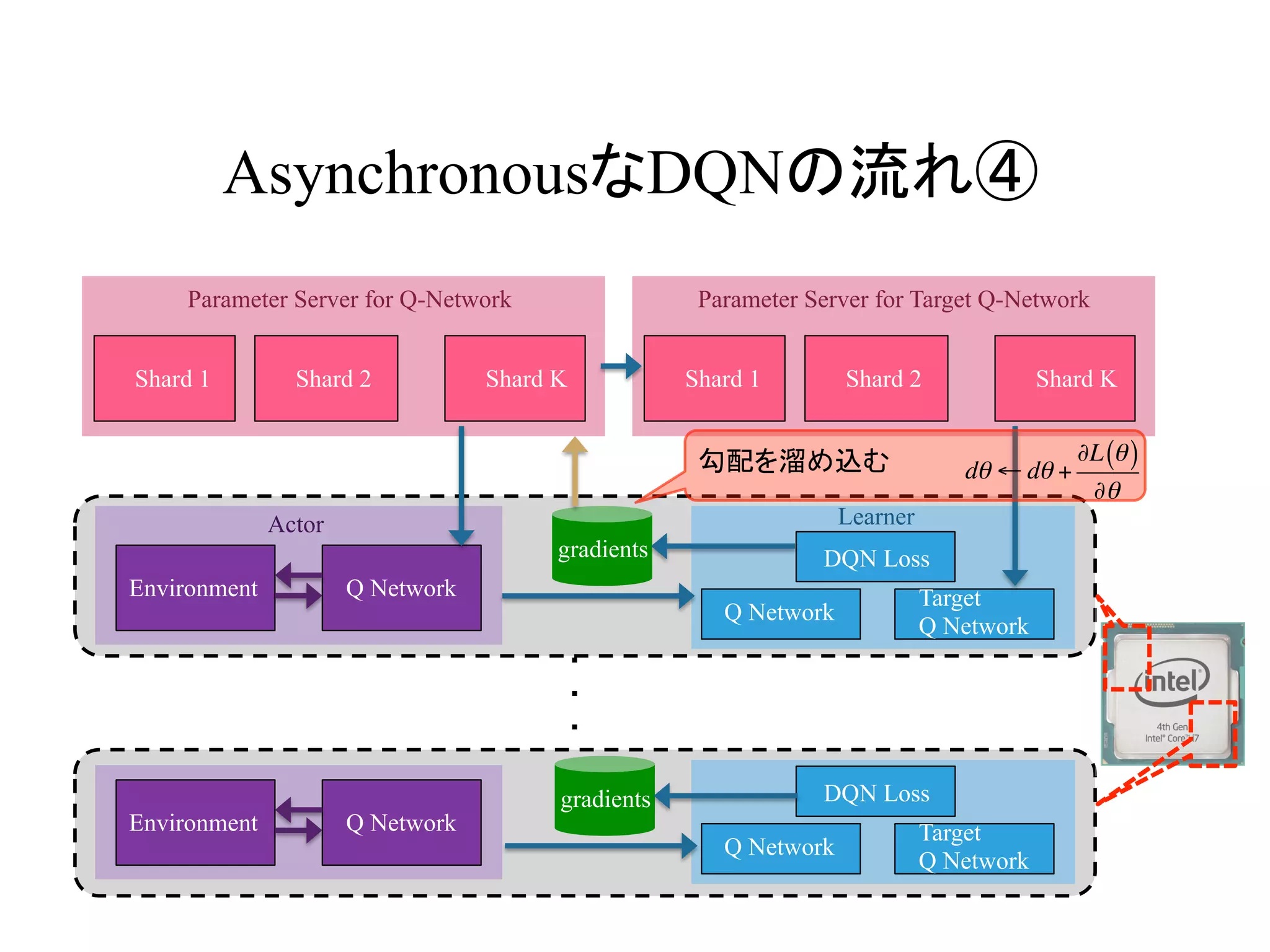
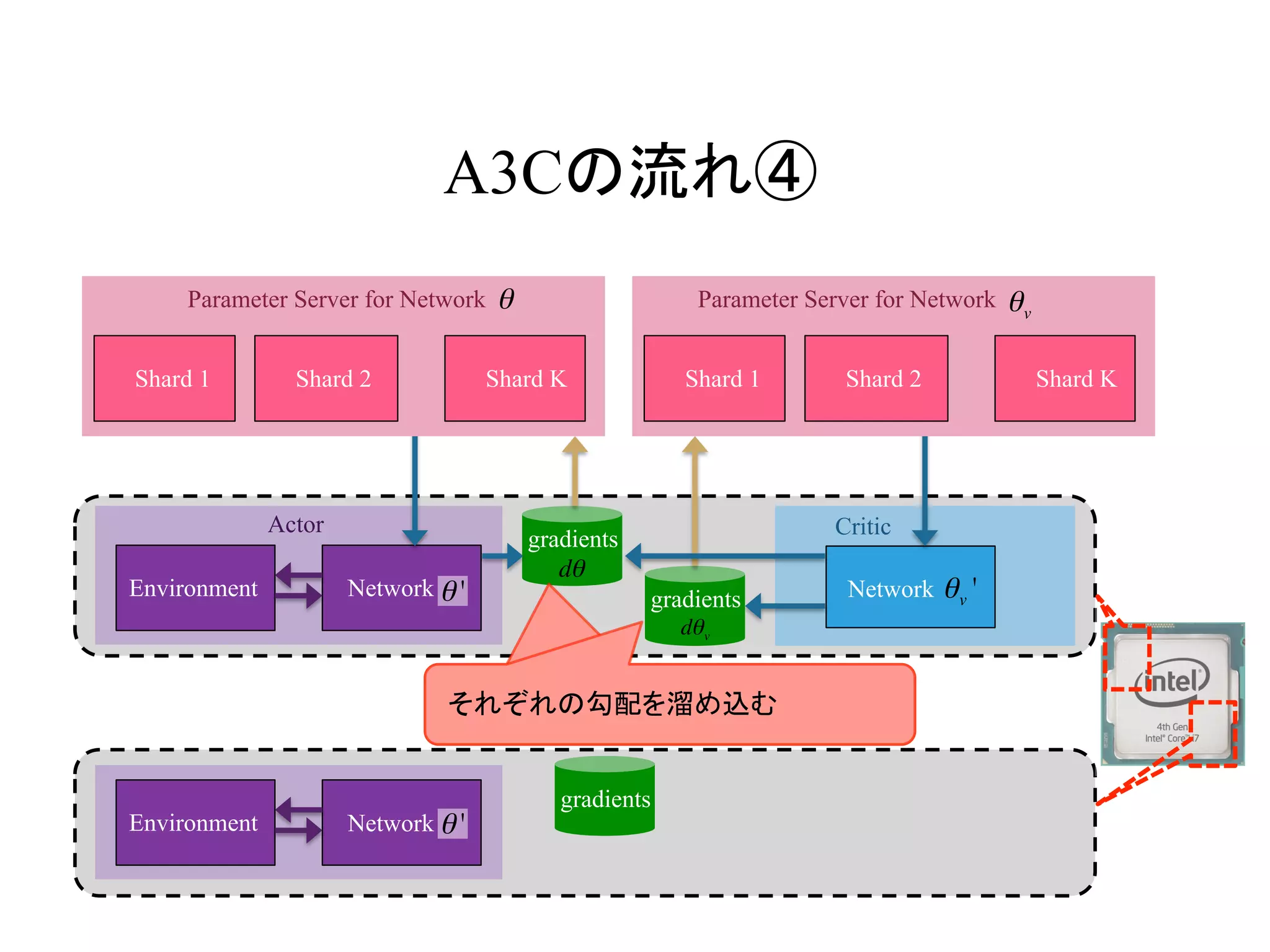
AsynchronousなDQNの流れ④
Environment Q Network
Q Network
Target
Q Network
DQN Loss gradients
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
gradients
勾配を溜め込む dθ ← dθ +
∂L θ( )
∂θ
22.
Shard 1 Shard2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
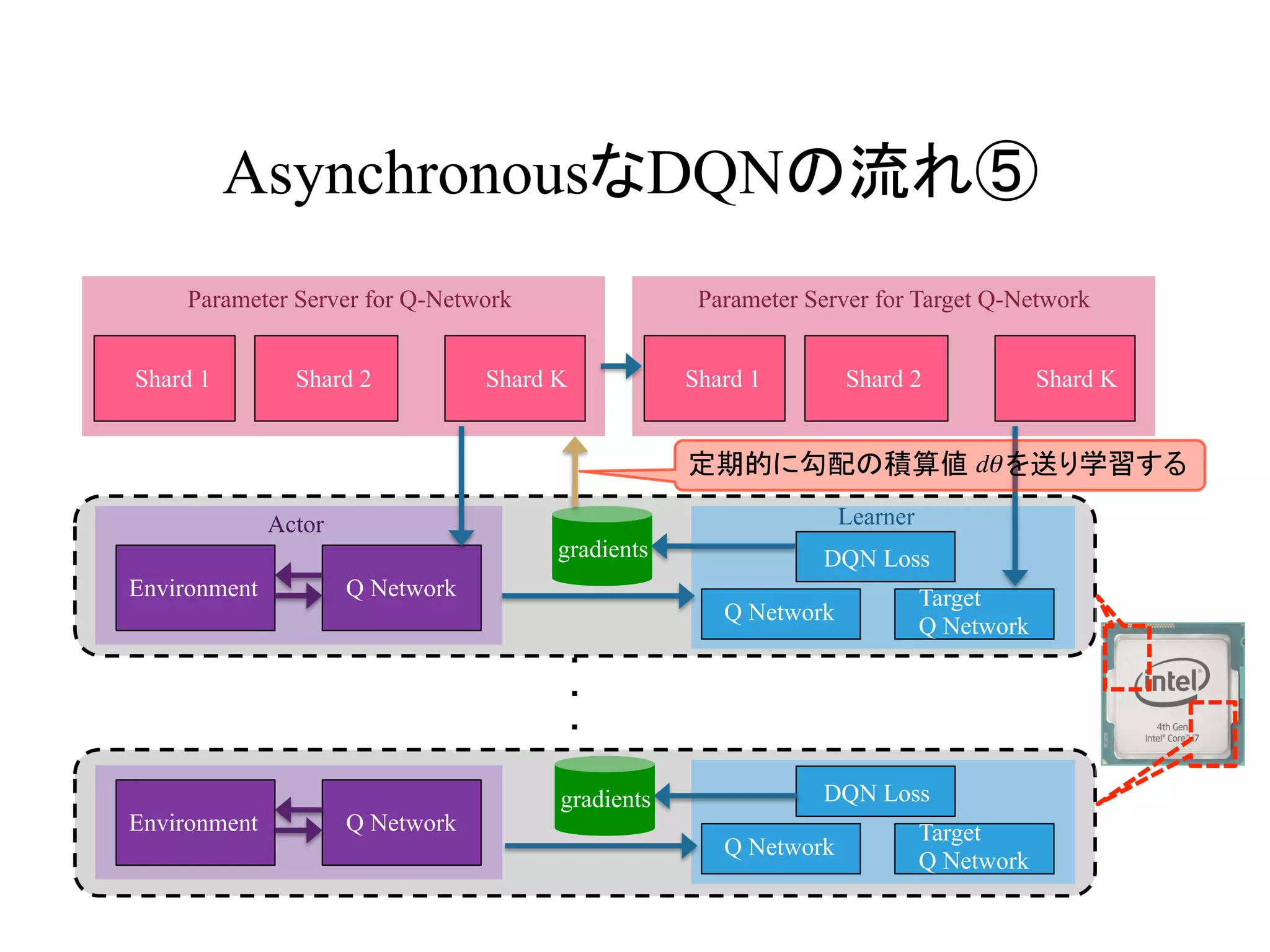
AsynchronousなDQNの流れ⑤
Environment Q Network
Q Network
Target
Q Network
DQN Loss gradients
Environment Q Network
Q Network
Target
Q Network
DQN Loss
・
・
・
Actor Learner
gradients
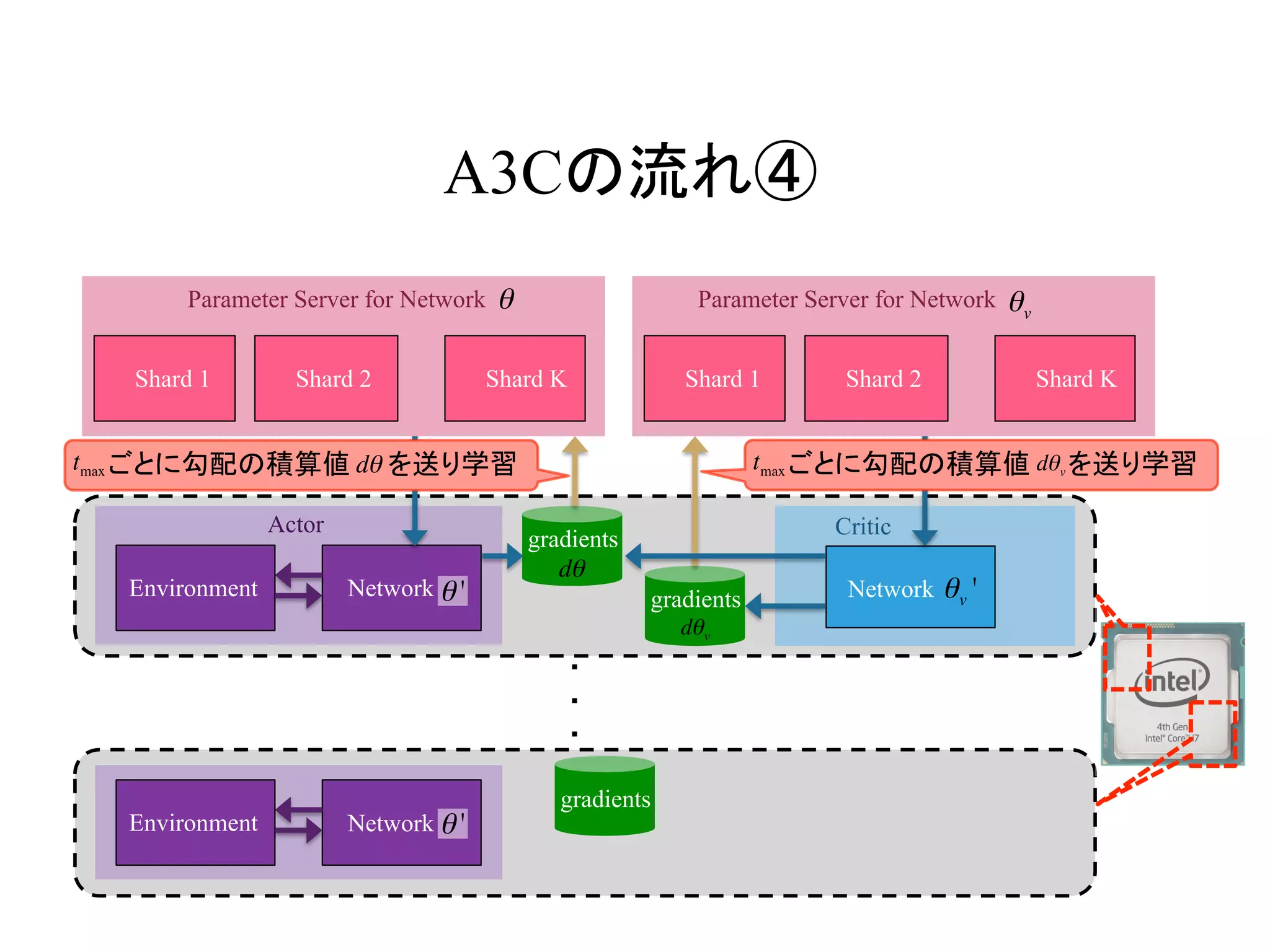
定期的に勾配の積算値 を送り学習する dθ

![今回取り上げるのはこれ
[1] Volodymyr Mnih, Adria` Puigdome`nech Badia, Mehdi
Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David
Silver, and Koray Kavukcuoglu. Asynchronous methods for
deep reinforcement learning. In Proceedings of the 33rd
International Conference on Machine Learning (ICML), pp.
1928–1937, 2016.
Asynchronousな手法によりreplay memoryを廃し、DQNより
高速かつ高精度な学習を達成した!](https://image.slidesharecdn.com/a3cpdf-170115092158/75/Introduction-to-A3C-model-2-2048.jpg)



![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]大規模分散強化学習の難しい問題設定への適用](https://cdn.slidesharecdn.com/ss_thumbnails/drlapplication-180921001838-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)






































