読 論文
John Schulman,Sergey Levine, Philipp Moritz, Michael I.
Jordan, Pieter Abbeel. Trust Region Policy Optimization.
ICML 2015.
▶ (深層)強化学習 話
▶ DQN(Deep Q-Network) [Mnih et al. 2015; Mnih et al.
2013] 異 ,価値関数 方策 NN 表現
最適化 (policy optimization)
参考文献 I
[1] ShamKakade and John Langford. “Approximately Optimal Approximate
Reinforcement Learning”. In: ICML 2002. 2002.
[2] Volodymyr Mnih et al. “Human-level control through deep reinforcement
learning”. In: Nature 518.7540 (2015), pp. 529–533.
[3] Volodymyr Mnih et al. “Playing Atari with Deep Reinforcement Learning”. In:
NIPS 2014 Deep Learning Workshop. 2013, pp. 1–9. arXiv:
arXiv:1312.5602v1.



![読 論文
John Schulman, Sergey Levine, Philipp Moritz, Michael I.
Jordan, Pieter Abbeel. Trust Region Policy Optimization.
ICML 2015.
▶ (深層)強化学習 話
▶ DQN(Deep Q-Network) [Mnih et al. 2015; Mnih et al.
2013] 異 ,価値関数 方策 NN 表現
最適化 (policy optimization)](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-3-320.jpg)

![Policy Optimization
▶ 決定過程 (S, A, P, c, ρ0, γ)
▶ S 状態集合
▶ A 行動集合
▶ P : S × A × S → R 遷移確率
▶ c : S → R 関数
▶ ρ0 : S → R 初期状態 s0 分布
▶ γ ∈ [0, 1] 割引率
▶ 方策(policy)π : S × A → [0, 1]
▶ 期待割引
η(π) = Es0,a0,...
[ ∞∑
t=0
γt
c(st)
]
, where
s0 ∼ ρ0, at ∼ π(· | st), st+1 ∼ P(st+1 | st, at)
▶ 目標:η(π) 小 π 求](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-5-320.jpg)
![価値関数
状態 先 期待割引 考 便利
▶ 状態価値関数 Vπ(st) = Eat ,st+1,...[
∑∞
l=0 γl
c(st+l )]
▶ st 先 π 従 行動 選
▶ 行動価値関数 Qπ(st, at) = Est+1,at+1,...[
∑∞
l=0 γl
c(st+l )]
▶ st at 選 先 π 従 行動 選
▶ 関数 Aπ(s, a) = Qπ(s, a) − Vπ(s)](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-6-320.jpg)
![Trust Region Policy Optimization(TRPO)
▶ 元 方策 πθold
KL 値 δ 以下
抑 制約付 最適化問題 解
方策 改善 提案
minimize
θ
Es∼ρθold
,a∼q
[
πθ(a | s)
q(a | s)
Qθold
(s, a)
]
subject to Es∼ρθold
[DKL(πθold
(· | s) ∥ πθ(· | s))] ≤ δ.
(15)
▶ 導出 説明 (時間 )](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-7-320.jpg)
![期待割引 最小化(1)
方策 π 元 , 良 方策 ˜π 求 考
▶ 方策 ˜π 期待割引 η(˜π) ,別 方策 π 期待割
引 対 表 (証
明 論文 Appendix 参照).
η(˜π) = η(π) + Es0,a0,...
[ ∞∑
t=0
γt
Aπ(st, at)
]
, where
s0 ∼ ρ0, at ∼ ˜π(· | st), st+1 ∼ P(st+1 | st, at). (1)
▶ 割引訪問頻度 ρπ(s) = (P(s0 = s) + γP(s1 = s) + . . . )
使 書
η(˜π) = η(π) +
∑
s
ρ˜π(s)
∑
a
˜π(a | s)Aπ(s, a). (2)
▶ 右辺 最小化 ˜π 求 ρ˜π 邪魔](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-8-320.jpg)

![Conservative Policy Iteration(CPI) [Kakade and
Langford 2002]
▶ π′
= arg minπ′ Lπold
(π′
) πold 混合方策
πnew(a | s) = (1 − α)πold(a | s) + απ′
(a | s) (5)
期待割引 η(πnew) 次 保証 得
.
η(πnew) ≤ Lπold
(πnew) +
2ϵγ
(1 − γ)2
α2
(8)
( α ∈ [0, 1), ϵ = maxs |Ea∼π′(a|s)[Aπold
(s, a)]|)
▶ η(πnew) < η(πold) α 計算
混合方策 求 繰 返 単調改善](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-10-320.jpg)


![化 方策 最適化(1)
化 方策 πθ(a | s) 考 .
▶ 結果
minimize
θ
[CDmax
KL (θold, θ) + Lθold
(θ)]
解 η θold 改善 保証 .
▶ , C 値 実際 大 ,更新
量 小 ,代
minimize
θ
Lθold
(θ)
subject to Dmax
KL (θold, θ) ≤ δ.
(12)
(信頼領域)制約付 最適化問題 .](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-13-320.jpg)
![化 方策 最適化(2)
▶ ,Dmax
KL 制約 ,制約 数 多
実用的 ,平均 KL
¯Dρ
KL(θ1, θ2) := Es∼ρ[DKL(πθ1 (· | s) ∥ πθ2 (· | s))]
代 使 ,解 最適化問題
minimize
θ
Lθold
(θ)
subject to ¯D
ρθold
KL (θold, θ) ≤ δ.
(13)](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-14-320.jpg)
![近似
▶ 先 最適化問題 期待値 形 書 , 分布
q(a | s) importance sampling 使
minimize
θ
Es∼ρθold
,a∼q
[
πθ(a | s)
q(a | s)
Qθold
(s, a)
]
subject to Es∼ρθold
[DKL(πθold
(· | s) ∥ πθ(· | s))] ≤ δ.
(15)
▶ 期待値 有限 近似 ,Qθ(s, a)
推定値 計算
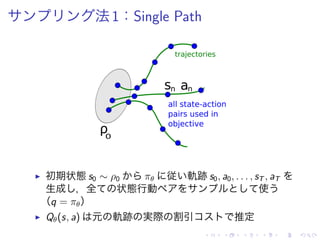
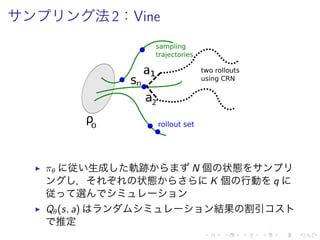
▶ 2 種類 方 提案:Single Path, Vine](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-15-320.jpg)


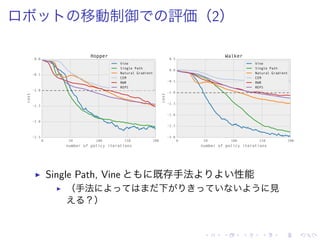
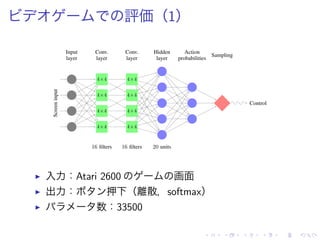
![評価(2)
▶ 一部 DQN ( [Mnih et al. 2013] )
上回 達成
▶ Vine > DQN:Pong, Q*bert
▶ Single Path > DQN:Enduro, Pong, Q*bert, Seaquest](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-22-320.jpg)


![参考文献 I
[1] Sham Kakade and John Langford. “Approximately Optimal Approximate
Reinforcement Learning”. In: ICML 2002. 2002.
[2] Volodymyr Mnih et al. “Human-level control through deep reinforcement
learning”. In: Nature 518.7540 (2015), pp. 529–533.
[3] Volodymyr Mnih et al. “Playing Atari with Deep Reinforcement Learning”. In:
NIPS 2014 Deep Learning Workshop. 2013, pp. 1–9. arXiv:
arXiv:1312.5602v1.](https://image.slidesharecdn.com/slides-150820112417-lva1-app6891/85/Trust-Region-Policy-Optimization-25-320.jpg)






![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Hybrid Reward Architecture for Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl20170630-170707003146-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)








