Downloaded 14 times
















![Lecture 1: Introduction to Reinforcement Learning
The RL Problem
State
Information State
An information state (a.k.a. Markov state) contains all useful
information from the history.
Definition
A state St is Markov if and only if
P[St+1 | St] = P[St+1 | S1, ..., St]
“The future is independent of the past given the present”
H1:t → St → Ht+1:∞
Once the state is known, the history may be thrown away
i.e. The state is a sufficient statistic of the future
The environment state Se
t is Markov
The history Ht is Markov](https://image.slidesharecdn.com/introrl-180217013047/85/Intro-rl-21-320.jpg)


![Lecture 1: Introduction to Reinforcement Learning
The RL Problem
State
Partially Observable Environments
Partial observability: agent indirectly observes environment:
A robot with camera vision isn’t told its absolute location
A trading agent only observes current prices
A poker playing agent only observes public cards
Now agent state = environment state
Formally this is a partially observable Markov decision process
(POMDP)
Agent must construct its own state representation Sa
t , e.g.
Complete history: Sa
t = Ht
Beliefs of environment state: Sa
t = (P[Se
t = s1
], ..., P[Se
t = sn
])
Recurrent neural network: Sa
t = σ(Sa
t−1Ws + OtWo)](https://image.slidesharecdn.com/introrl-180217013047/85/Intro-rl-24-320.jpg)

![Lecture 1: Introduction to Reinforcement Learning
Inside An RL Agent
Policy
A policy is the agent’s behaviour
It is a map from state to action, e.g.
Deterministic policy: a = π(s)
Stochastic policy: π(a|s) = P[At = a|St = s]](https://image.slidesharecdn.com/introrl-180217013047/85/Intro-rl-26-320.jpg)


![Lecture 1: Introduction to Reinforcement Learning
Inside An RL Agent
Model
A model predicts what the environment will do next
P predicts the next state
R predicts the next (immediate) reward, e.g.
Pa
ss = P[St+1 = s | St = s, At = a]
Ra
s = E [Rt+1 | St = s, At = a]](https://image.slidesharecdn.com/introrl-180217013047/85/Intro-rl-29-320.jpg)
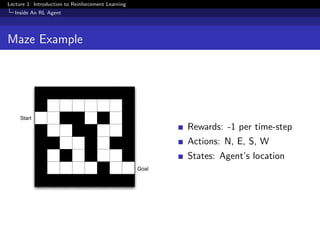



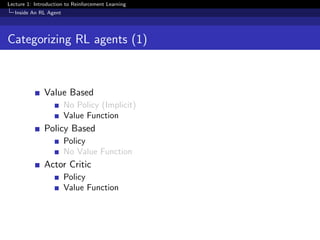

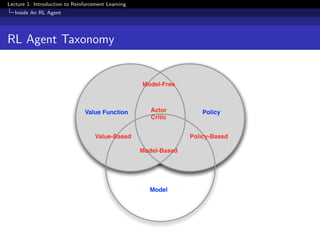








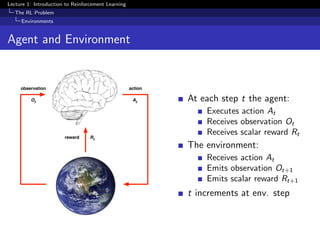
This document provides an overview of an introductory lecture on reinforcement learning. The key points covered include: - Reinforcement learning involves an agent learning through trial-and-error interactions with an environment by receiving rewards. - The goal of reinforcement learning is for the agent to select actions that maximize total rewards. This involves making decisions to balance short-term versus long-term rewards. - Major components of a reinforcement learning agent include its policy, which determines its behavior, its value function which predicts future rewards, and its model which represents its understanding of the environment's dynamics.

















































































