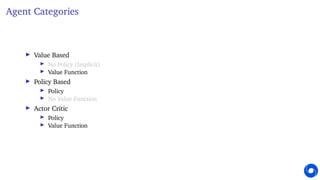
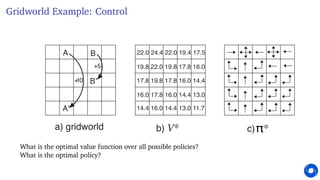
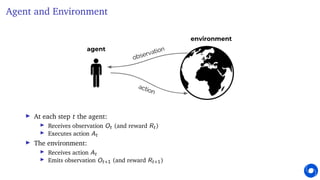
This document provides an introduction and overview of reinforcement learning. It discusses key concepts like the reinforcement learning problem formulation involving an agent and environment, rewards, values, and policies. It also covers core reinforcement learning concepts like prediction, control, learning, and planning. Example problems are presented for Atari games, mazes, and gridworlds to illustrate different reinforcement learning techniques. The course will focus on understanding fundamental principles and algorithms for learning through interaction, covering topics such as exploration, planning, model-free and model-based methods, and deep reinforcement learning.





















![Values
I We call the expected cumulative reward, from a state s, the value
v(s) = E [Gt | St = s]
= E [Rt+1 + Rt+2 + Rt+3 + ... | St = s]
I The value depends on the actions the agent takes
I Goal is to maximize value, by picking suitable actions
I Rewards and values define utility of states and action (no supervised feedback)
I Returns and values can be defined recursively
Gt = Rt+1 + Gt+1
v(s) = E [Rt+1 + v(St+1) | St = s]](https://image.slidesharecdn.com/lecture1-introduction-230423172039-d23a83a8/85/Lecture-1-introduction-pdf-23-320.jpg)

![Action values
I It is also possible to condition the value on actions:
q(s, a) = E [Gt | St = s, At = a]
= E [Rt+1 + Rt+2 + Rt+3 + ... | St = s, At = a]
I We will talk in depth about state and action values later](https://image.slidesharecdn.com/lecture1-introduction-230423172039-d23a83a8/85/Lecture-1-introduction-pdf-25-320.jpg)




















![Value Function
I The actual value function is the expected return
vπ (s) = E [Gt | St = s, π]
= E
Rt+1 + γRt+2 + γ2
Rt+3 + ... | St = s, π
I We introduced a discount factor γ ∈ [0, 1]
I Trades off importance of immediate vs long-term rewards
I The value depends on a policy
I Can be used to evaluate the desirability of states
I Can be used to select between actions](https://image.slidesharecdn.com/lecture1-introduction-230423172039-d23a83a8/85/Lecture-1-introduction-pdf-46-320.jpg)
![Value Functions
I The return has a recursive form Gt = Rt+1 + γGt+1
I Therefore, the value has as well
vπ (s) = E [Rt+1 + γGt+1 | St = s, At ∼ π(s)]
= E [Rt+1 + γvπ (St+1) | St = s, At ∼ π(s)]
Here a ∼ π(s) means a is chosen by policy π in state s (even if π is deterministic)
I This is known as a Bellman equation (Bellman 1957)
I A similar equation holds for the optimal (=highest possible) value:
v∗(s) = max
a
E [Rt+1 + γv∗(St+1) | St = s, At = a]
This does not depend on a policy
I We heavily exploit such equalities, and use them to create algorithms](https://image.slidesharecdn.com/lecture1-introduction-230423172039-d23a83a8/85/Lecture-1-introduction-pdf-47-320.jpg)



![Model
I A model predicts what the environment will do next
I E.g., P predicts the next state
P(s, a, s0
) ≈ p (St+1 = s0
| St = s, At = a)
I E.g., R predicts the next (immediate) reward
R(s, a) ≈ E [Rt+1 | St = s, At = a]
I A model does not immediately give us a good policy - we would still need to plan
I We could also consider stochastic (generative) models](https://image.slidesharecdn.com/lecture1-introduction-230423172039-d23a83a8/85/Lecture-1-introduction-pdf-51-320.jpg)