Downloaded 20 times





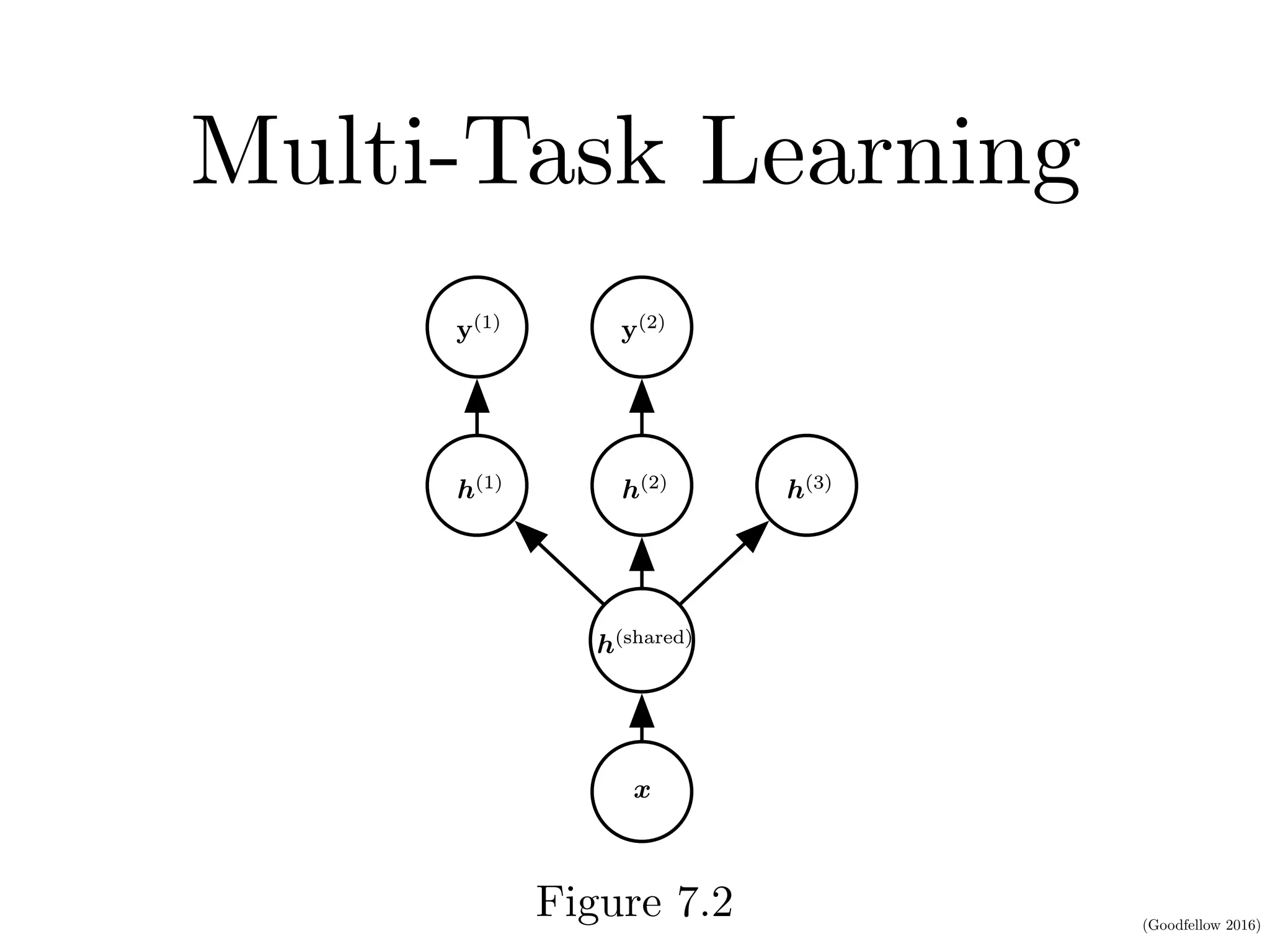
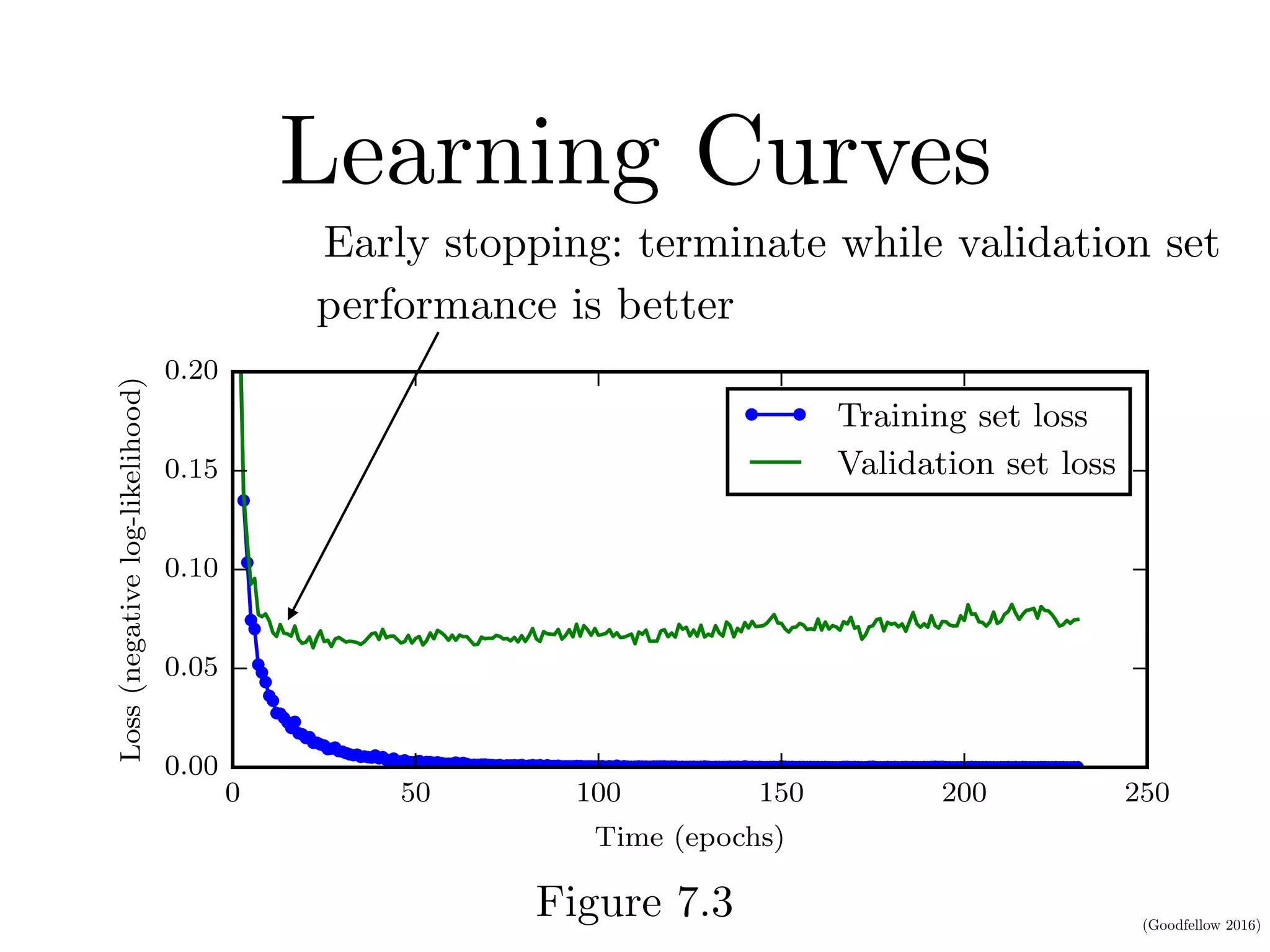
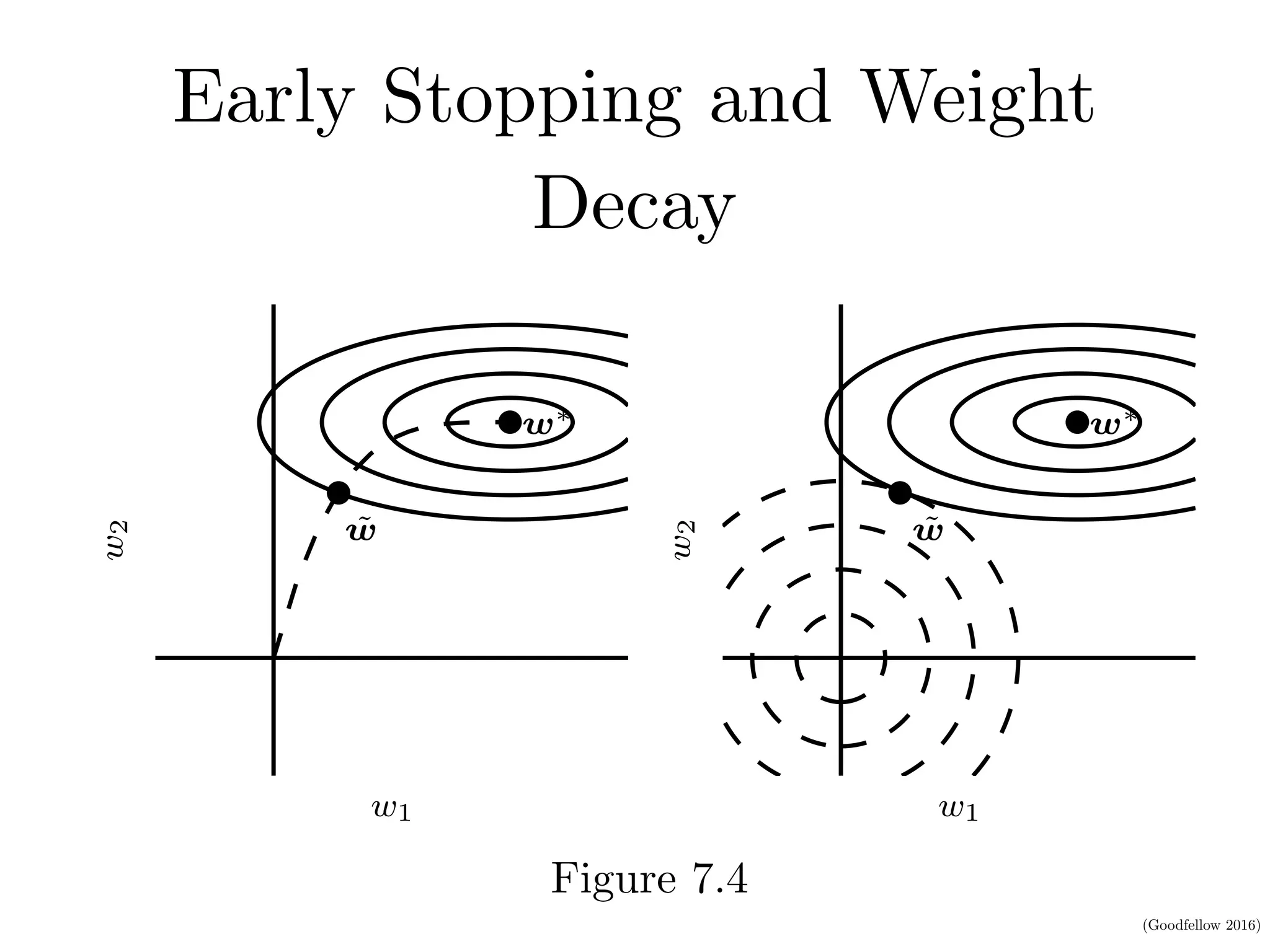

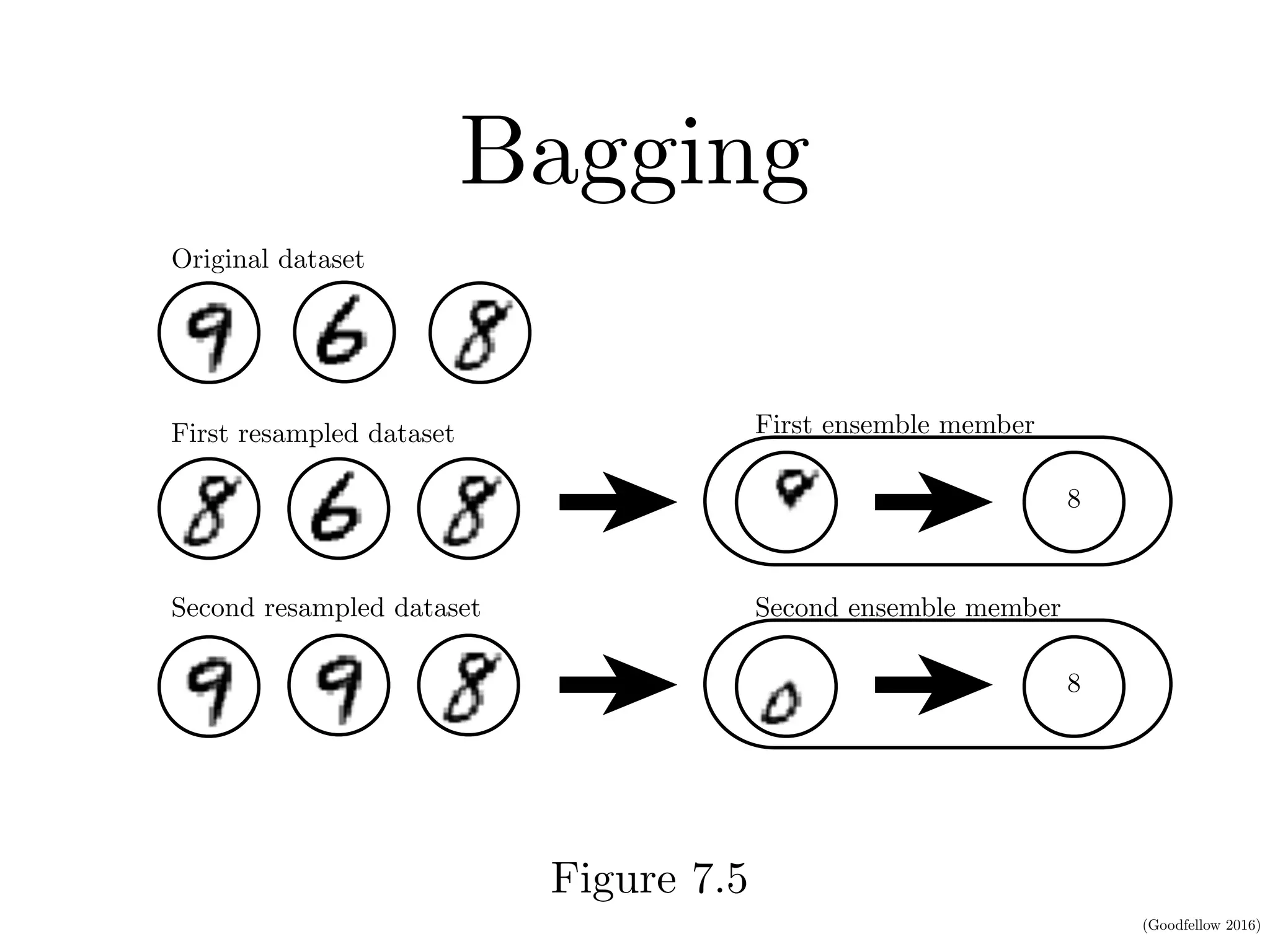
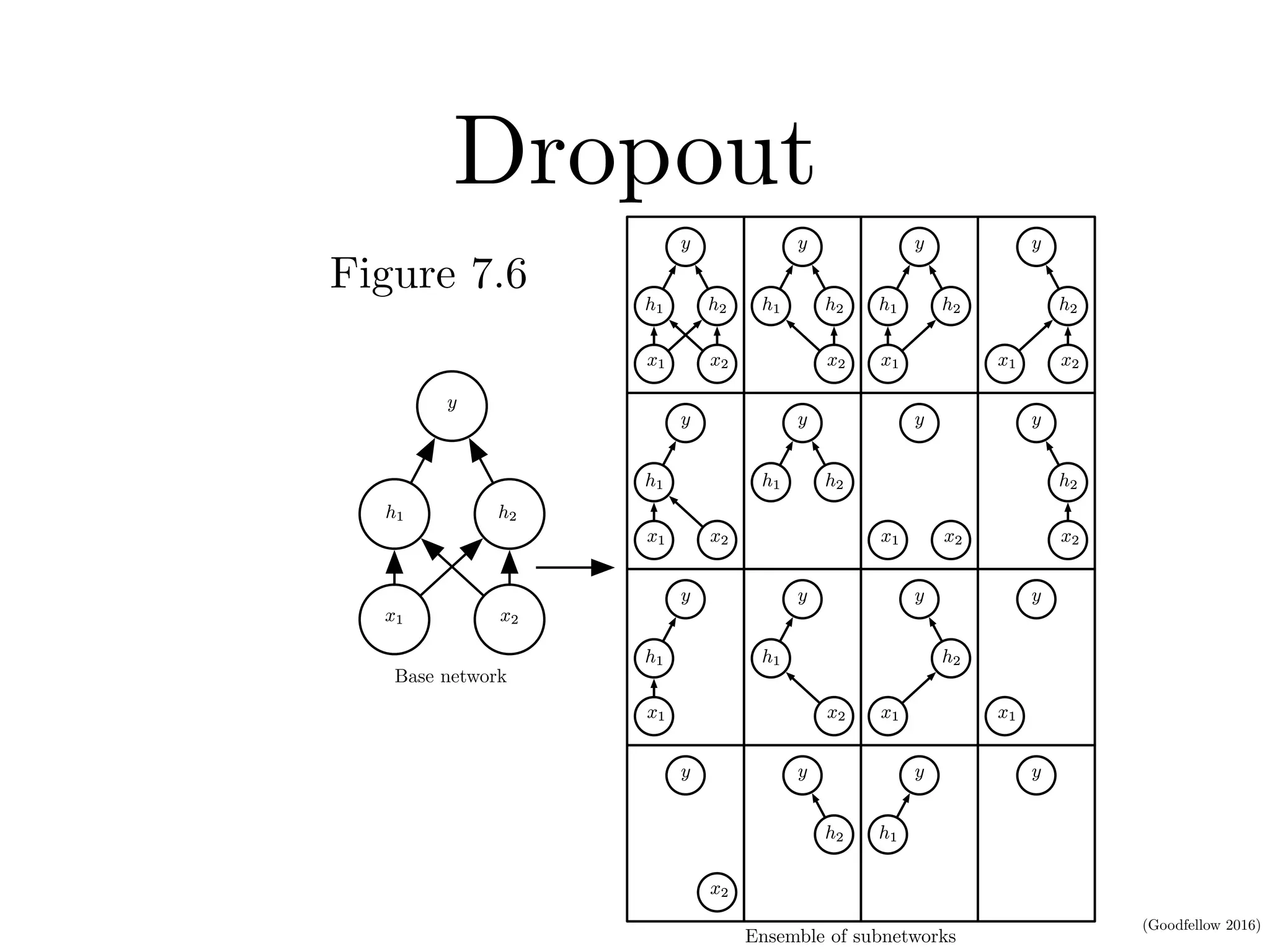

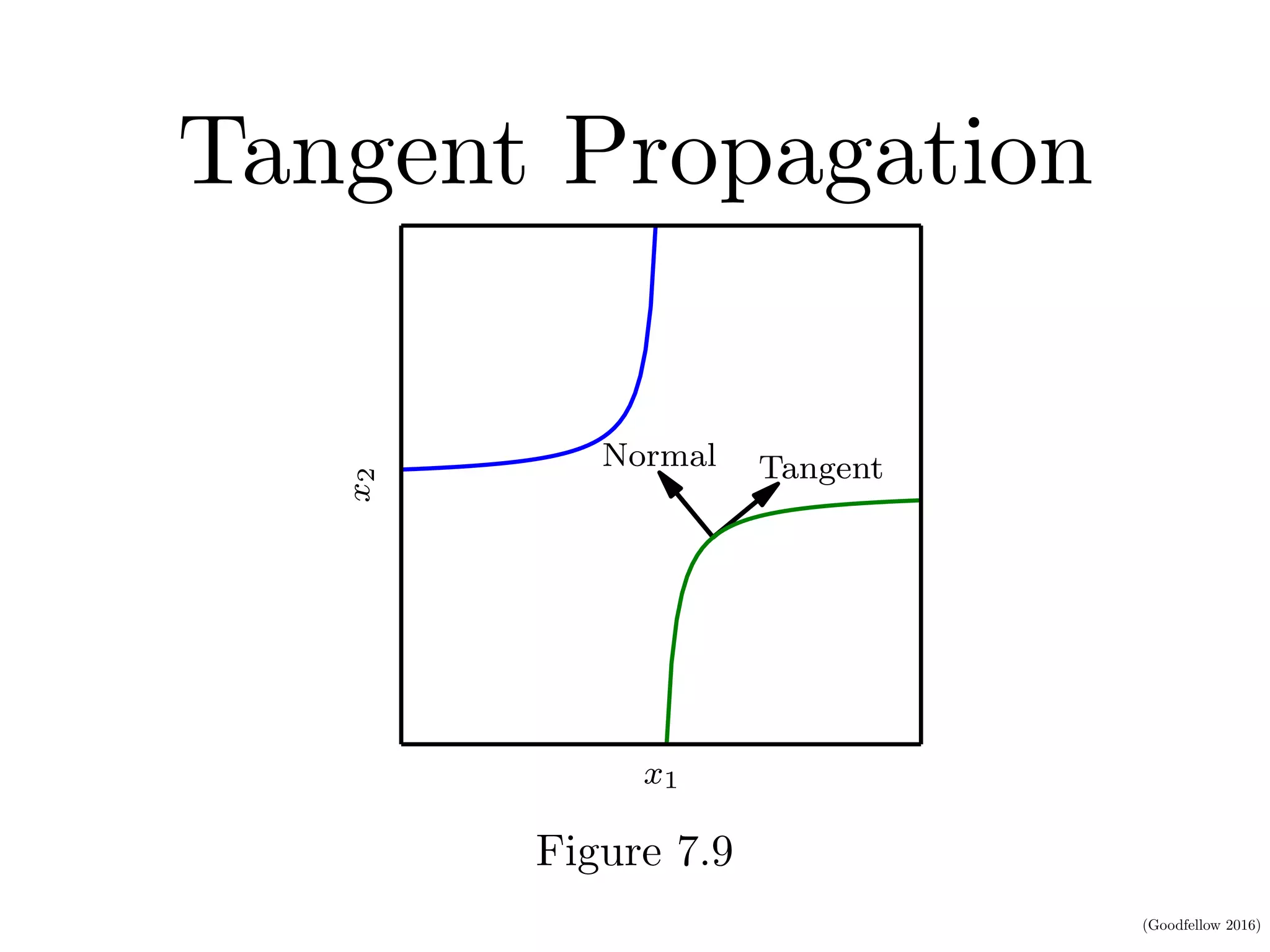

This document discusses various regularization techniques for deep learning models. It defines regularization as any modification to a learning algorithm intended to reduce generalization error without affecting training error. It then describes several specific regularization methods, including weight decay, norm penalties, dataset augmentation, early stopping, dropout, adversarial training, and tangent propagation. The goal of regularization is to reduce overfitting and improve generalizability of deep learning models.


















































































