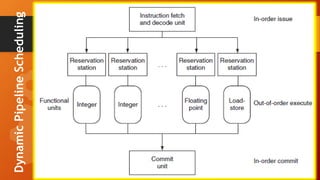
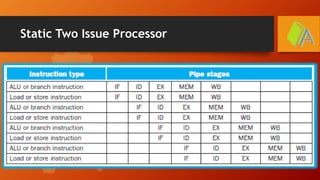
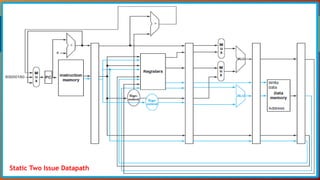
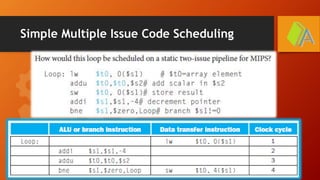
The document discusses instruction level parallelism (ILP) and methods to enhance it, including increasing pipeline depth and implementing multiple issue processors. It outlines static and dynamic approaches to multiple-issue processing, detailing requirements for packaging instructions and managing hazards. Additionally, it introduces speculation and dynamic pipeline scheduling as techniques for optimizing instruction execution and minimizing stalls.








![Loop Unrolling for Multiple-Issue Pipeline
for (i=0; i<4; i++)
{
Y[i] = A[i] * B[i];
}
for (i=0; i<2; i++)
{
Y[i] = A[i] * B[i];
Y[i+2] = A[i+2] * B[i+2];
}
for (i=0; i<100; i++)
{
Y[i] = A[i] * B[i];
}
for (i=0; i<25; i++)
{
Y[i] = A[i] * B[i];
Y[i+25] = A[i+25] * B[i+25];
Y[i+50] = A[i+50] * B[i+50];
Y[i+75] = A[i+75] * B[i+75];
}](https://image.slidesharecdn.com/6-200907134354/85/Instruction-Level-Parallelism-Static-Multiple-Issue-Dynamic-Multiple-Issue-Processors-11-320.jpg)