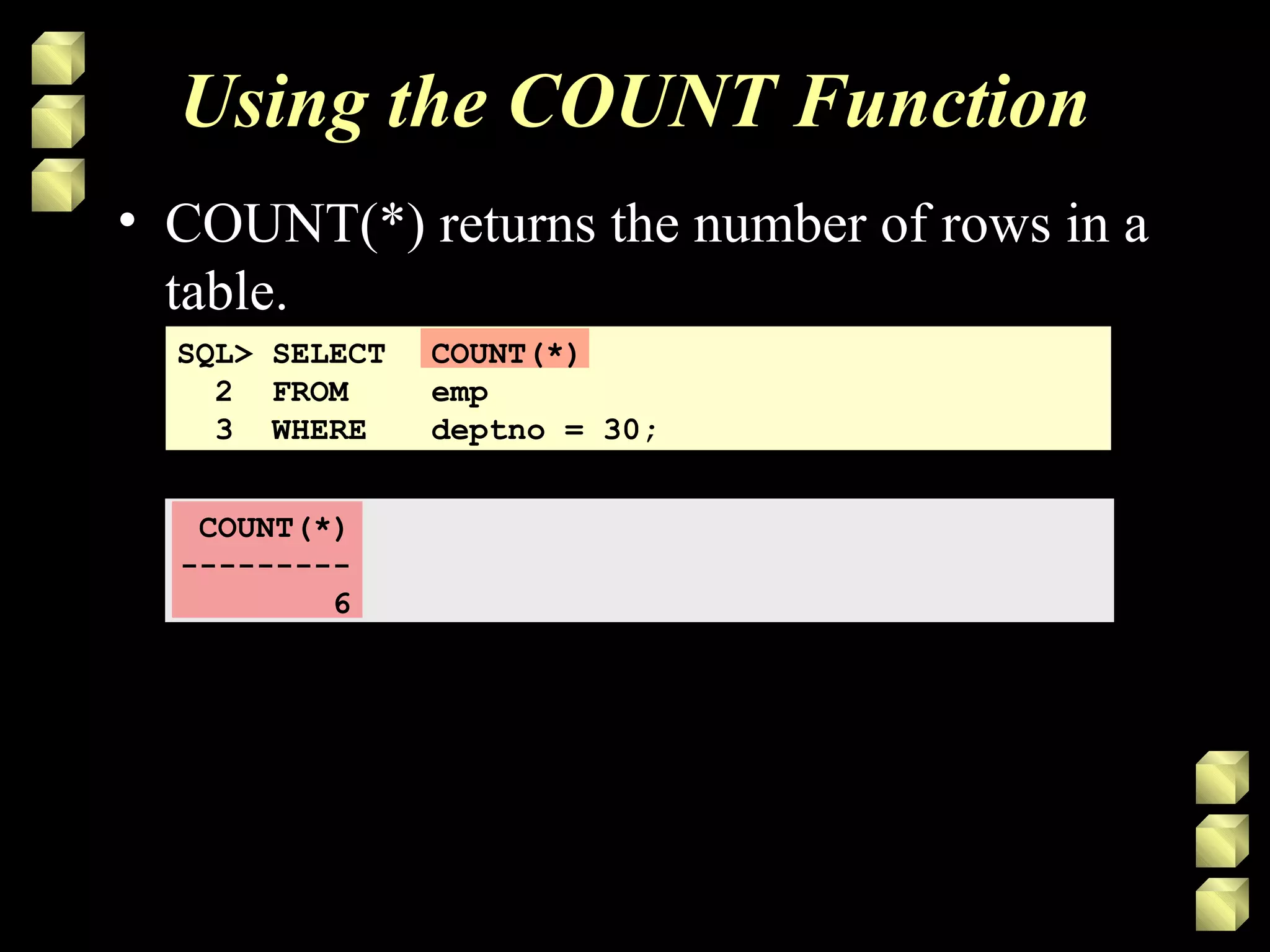
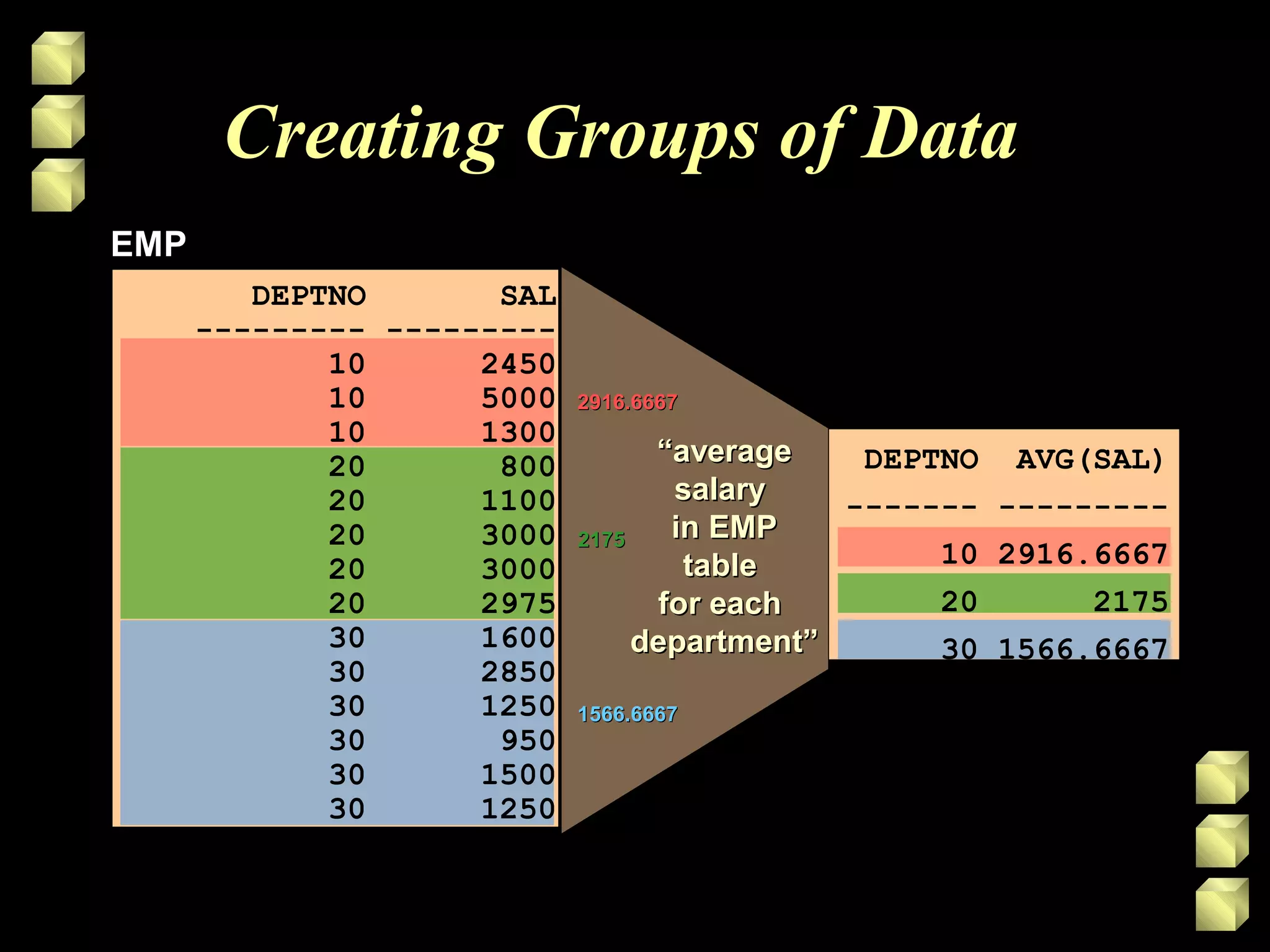
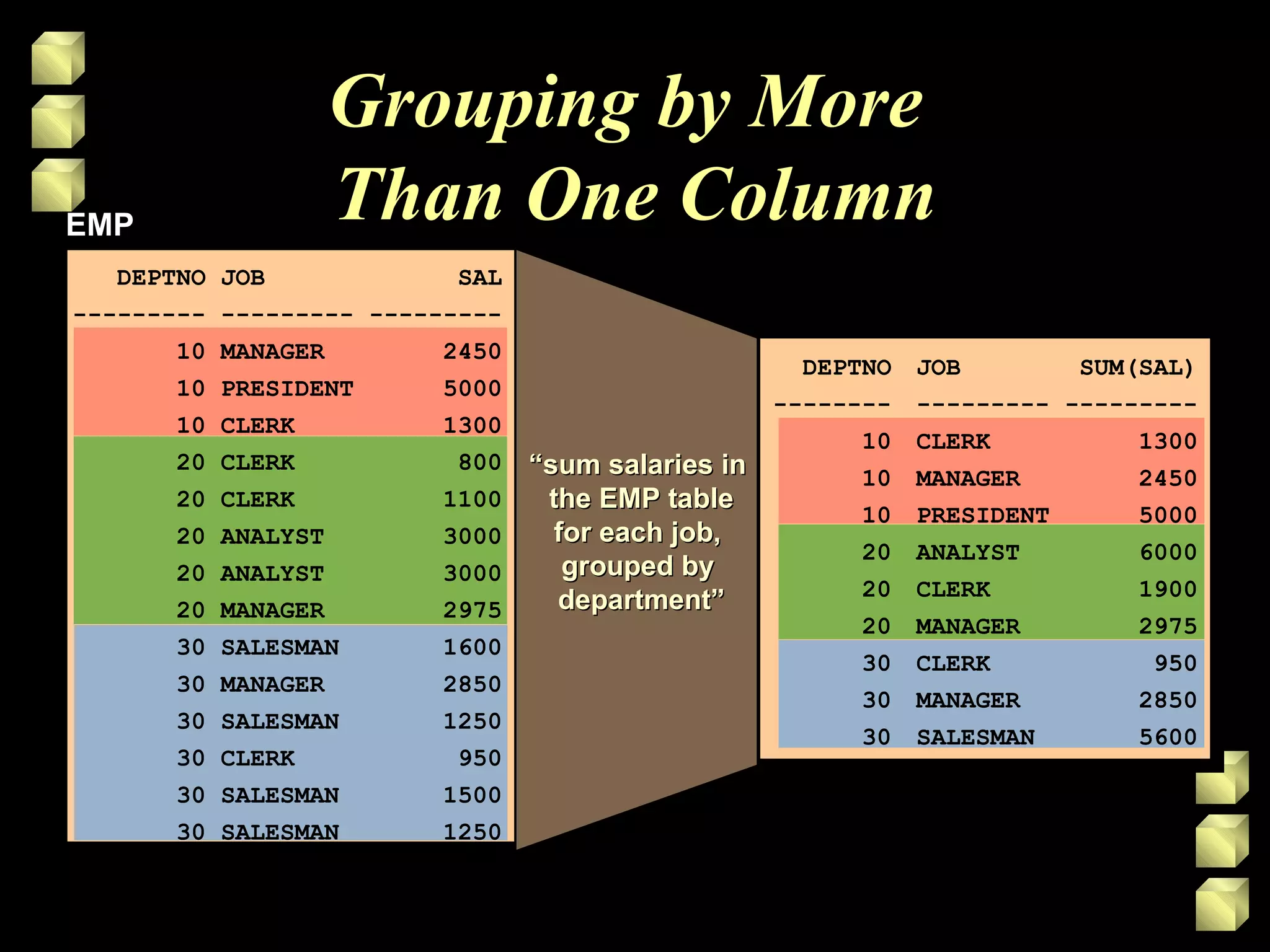
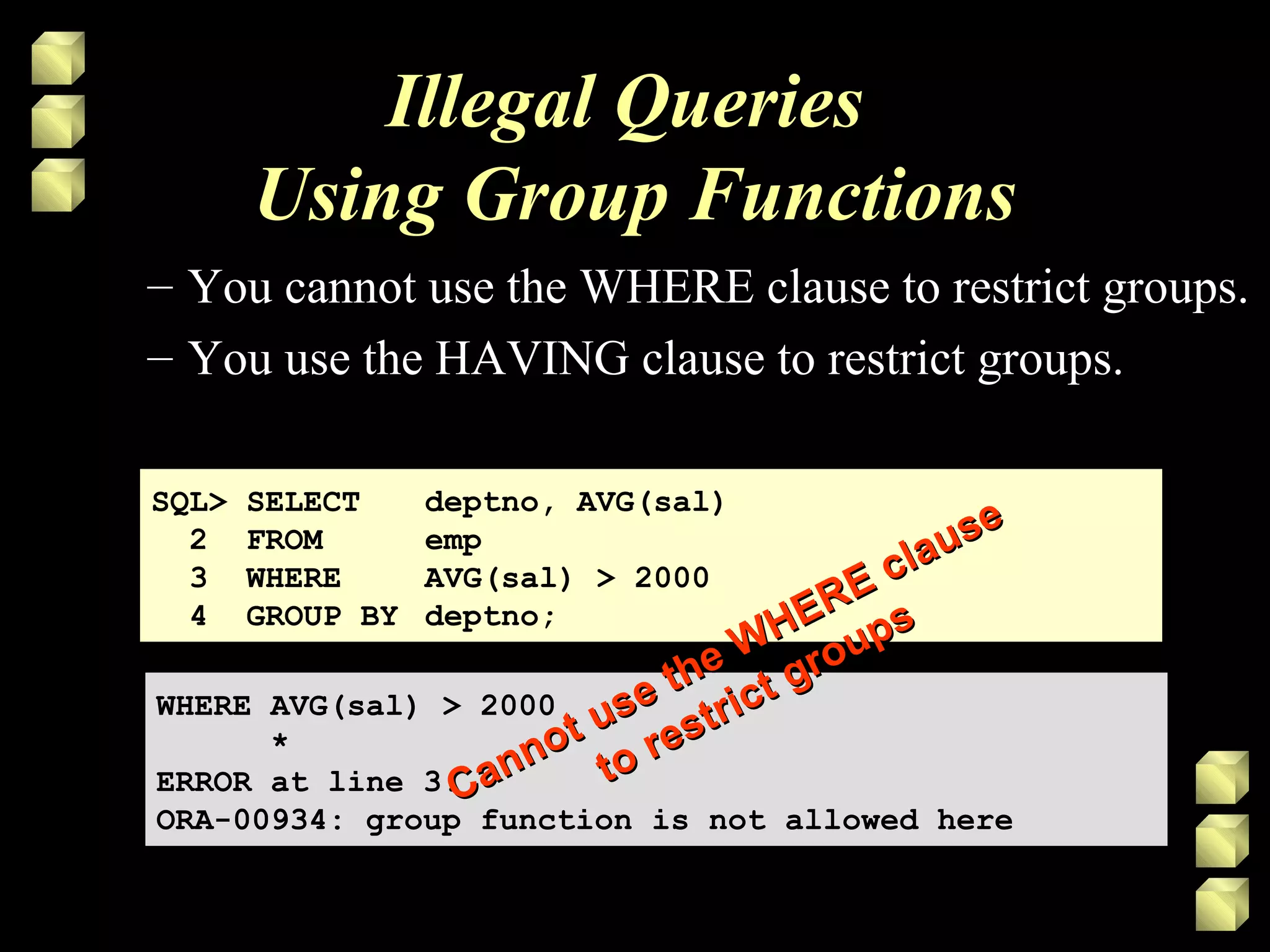
Group functions operate on sets of rows to give one result per group. Common group functions include COUNT, SUM, AVG, MIN, and MAX. The GROUP BY clause is used to divide rows into groups and the HAVING clause excludes groups based on a condition. Nesting group functions allows analyzing groups of groups, like finding the maximum of several averages.




![Using Group Functions
SELECT [column,] group_function(column)
FROM table
[WHERE condition]
[GROUP BY column]
[ORDER BY column];](https://image.slidesharecdn.com/sql5-140515101643-phpapp02/75/Sql5-5-2048.jpg)





![Creating Groups of Data:
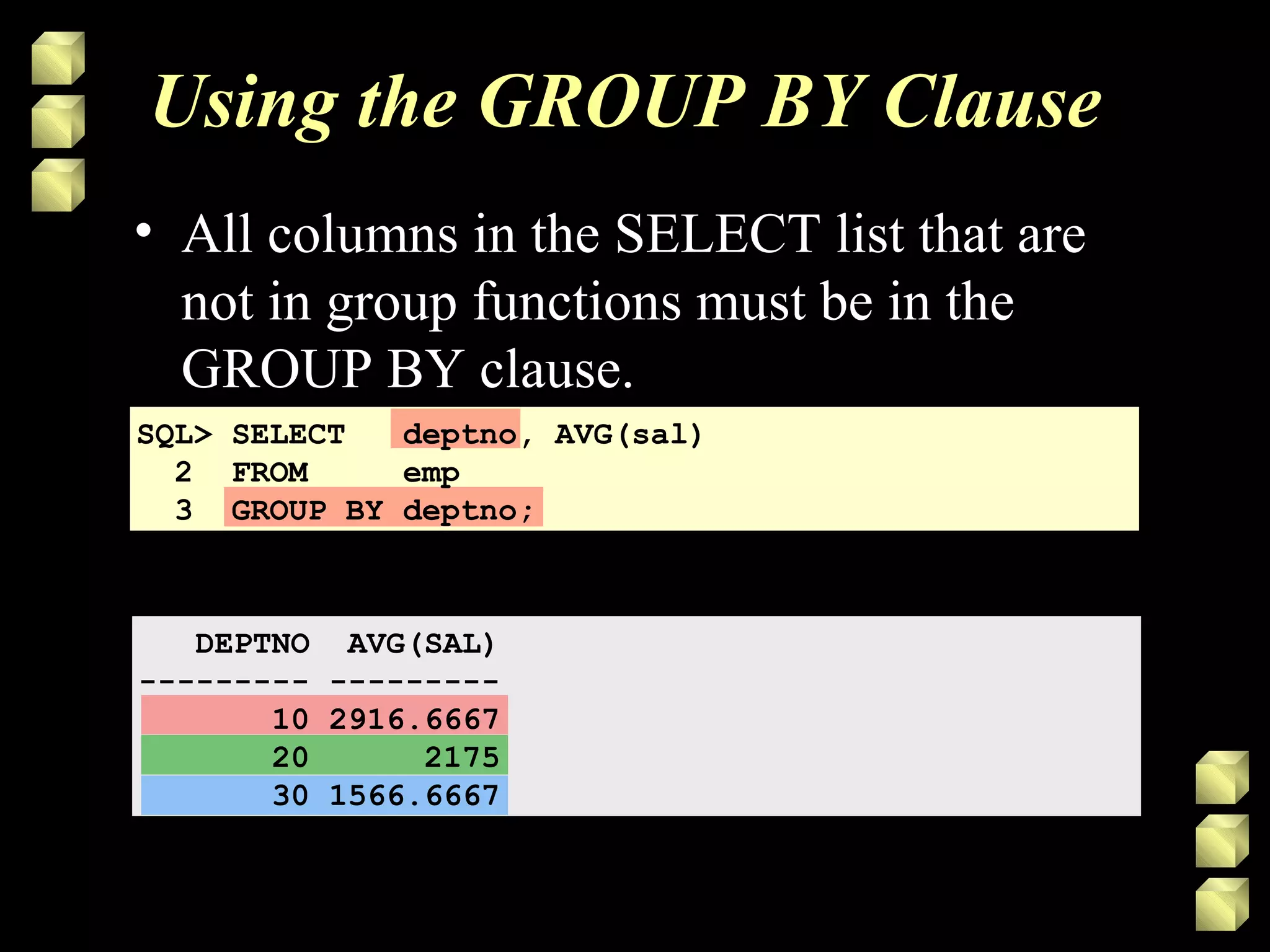
GROUP BY Clause
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
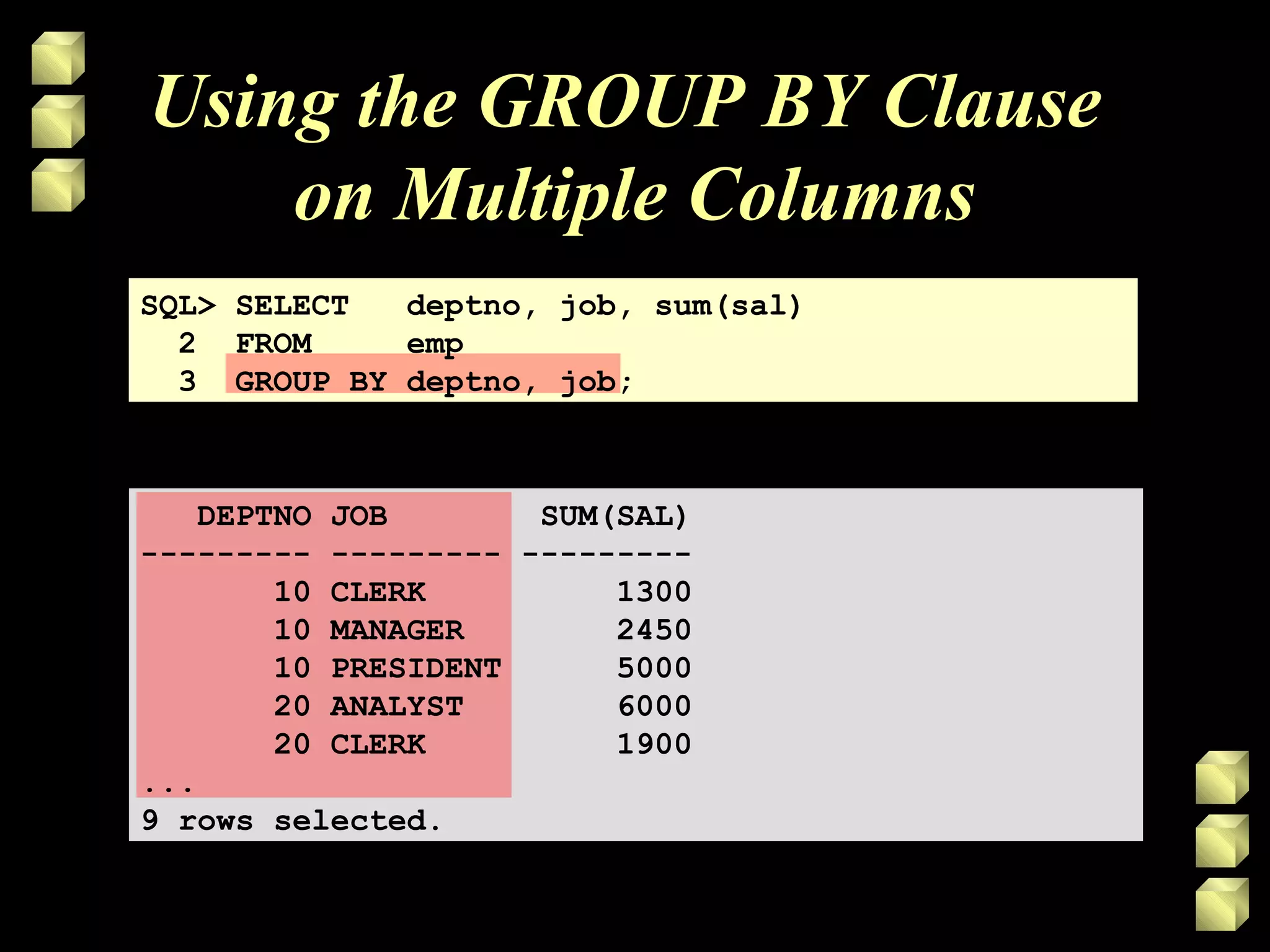
• Divide rows in a table into smaller groups
by using the GROUP BY clause.](https://image.slidesharecdn.com/sql5-140515101643-phpapp02/75/Sql5-13-2048.jpg)


![Excluding Group Results:
HAVING Clause
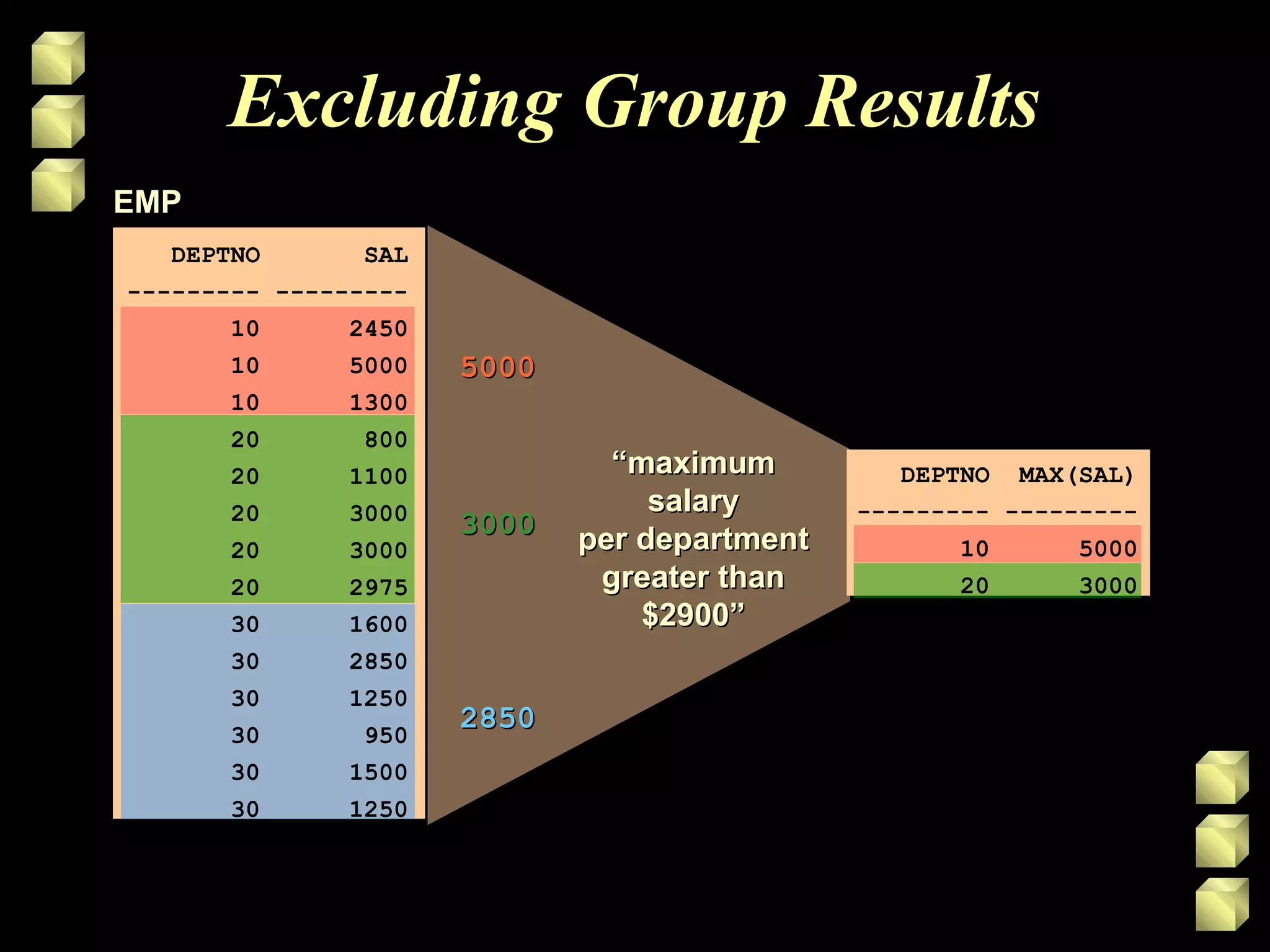
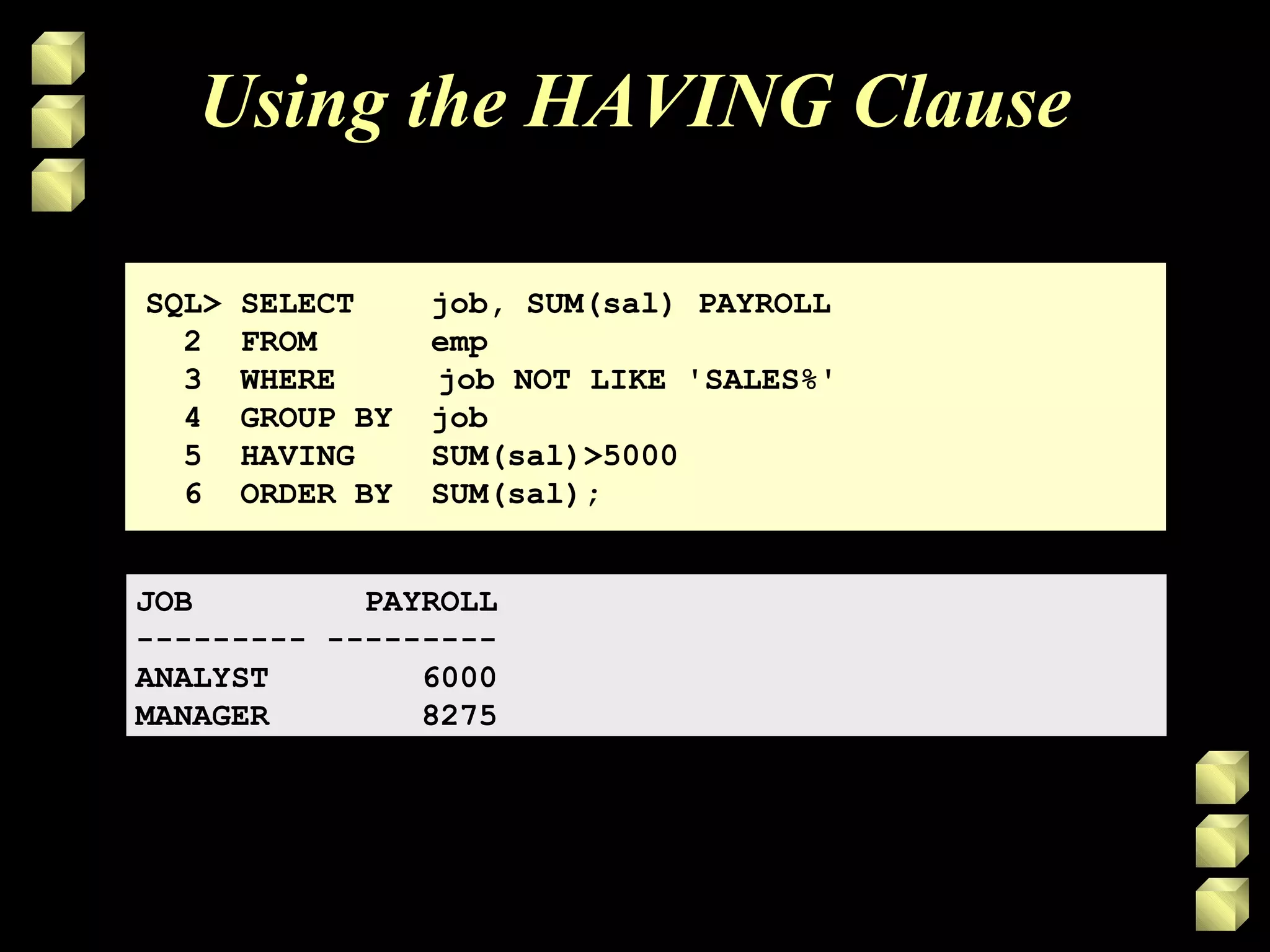
• Use the HAVING clause to restrict groups
• Rows are grouped.
• The group function is applied.
• Groups matching the HAVING clause are
displayed.
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];](https://image.slidesharecdn.com/sql5-140515101643-phpapp02/75/Sql5-21-2048.jpg)


![Summary
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];
• Order of evaluation of the clauses:
– WHERE clause
– GROUP BY clause
– HAVING clause](https://image.slidesharecdn.com/sql5-140515101643-phpapp02/75/Sql5-25-2048.jpg)






















































![Les05[1]Aggregating Data Using Group Functions](https://cdn.slidesharecdn.com/ss_thumbnails/les051-220214144213-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)









