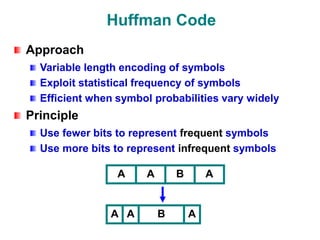
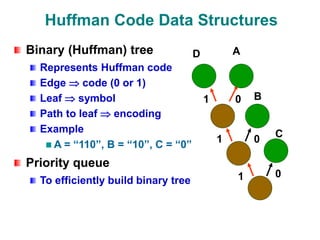
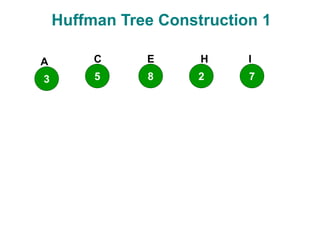
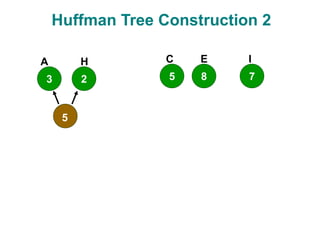
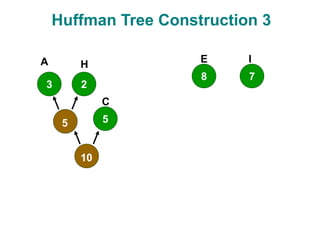
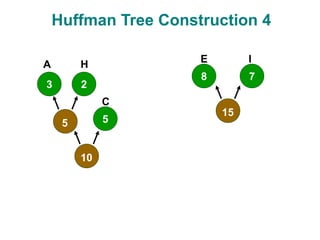
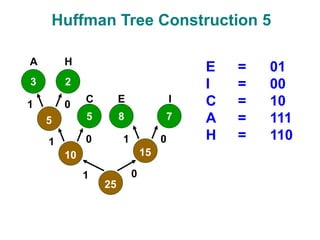
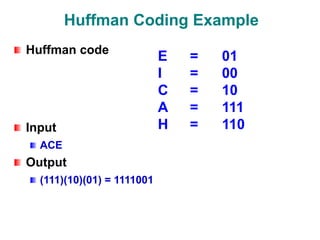
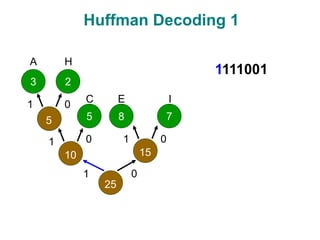
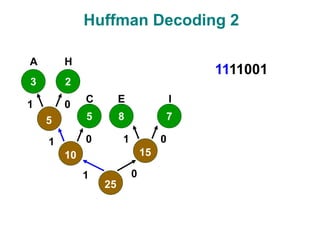
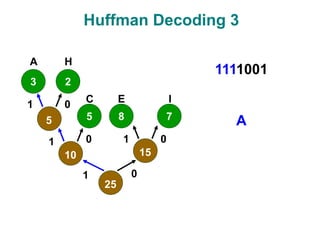
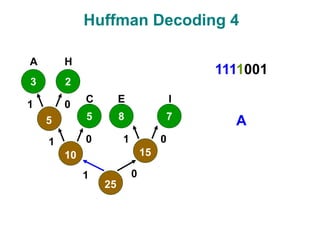
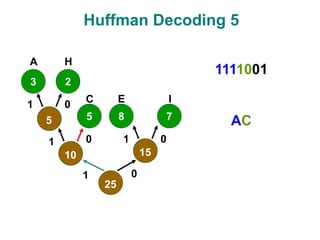
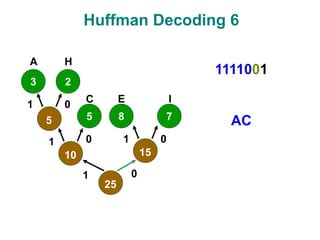
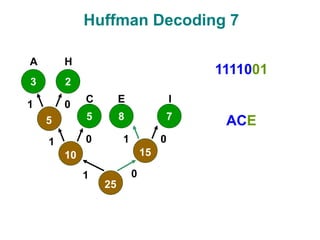
The document discusses data compression techniques, specifically focusing on lossless and lossy compression methods, and the principles behind Huffman coding. It explains how Huffman coding uses variable-length codes based on the frequency of symbols to efficiently encode data, alongside the tree structure used for encoding and decoding. Key methods for building Huffman trees and the properties of optimal prefix codes are also highlighted.