Huffman Coding
Huffmancoding is a lossless data compression algorithm. The idea is to
assign variable-length codes to input characters, lengths of the assigned
codes are based on the frequencies of corresponding characters.
Most character code systems (ASCII, unicode) use fixed length encoding
The code length of a character depends on how frequently it occurs in the
given text.
The character which occurs most frequently gets the smallest code.
The character which occurs least frequently gets the largest code.
It is also known as Huffman Encoding.
compressing data (savings of 20% to 90%)
3.
Prefix Codes
TheHuffman code is a prefix-free
code.
No prefix of a code word is equal to
another codeword.
for example, we could not encode t as 01 and x as 01101 since 01 is
a prefix of 01101
By using a binary tree representation we will generate prefix codes
provided all letters are leaves
4.
Huffman Coding Process
Thereare two major steps in Huffman Coding-
a) Building a Huffman Tree from the input characters.
b)Assigning code to the characters by traversing the
Huffman Tree.
5.
Huffman Tree-
The stepsinvolved in the construction of Huffman Tree are as follows-
Step-01:
Create a leaf node for each character of the text.
Leaf node of a character contains the occurring frequency of that character.
Step-02:
Arrange all the nodes in increasing order of their frequency value.
Step-03:
Considering the first two nodes having minimum frequency,
Create a new internal node.
The frequency of this new node is the sum of frequency of those two nodes.
Make the first node as a left child and the other node as a right child of the newly
created node.
Step-04:
Keep repeating Step-02 and Step-03 until all the nodes form a single tree.
The tree finally obtained is the desired Huffman Tree.
6.
Fixed v/s Variablelength Memory usage
Huffman’s greedy algorithm uses a table of the
frequencies of occurrence of each character to
build up an optimal way of representing each
character as a binary string
C: Alphabet
7.
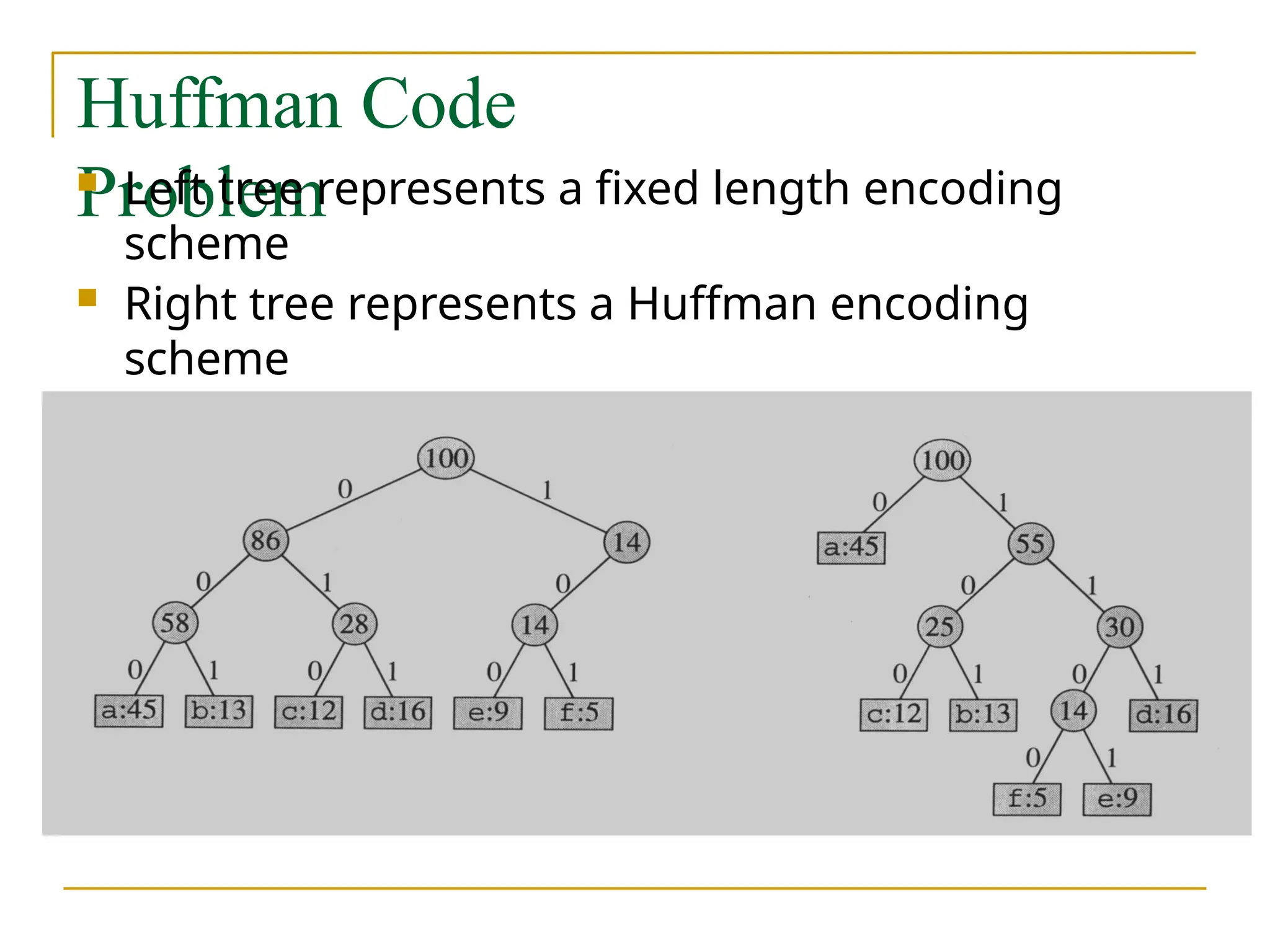
Huffman Code
Problem
Lefttree represents a fixed length encoding
scheme
Right tree represents a Huffman encoding
scheme
8.
Example to findHuffman coding
Assume we are given a data file that contains only 6
symbols,
namely a, b, c, d, e, f With the following frequency table:
Find a variable length prefix-free encoding
scheme/huffman encoding that
compresses this data file as much as possible?
9.
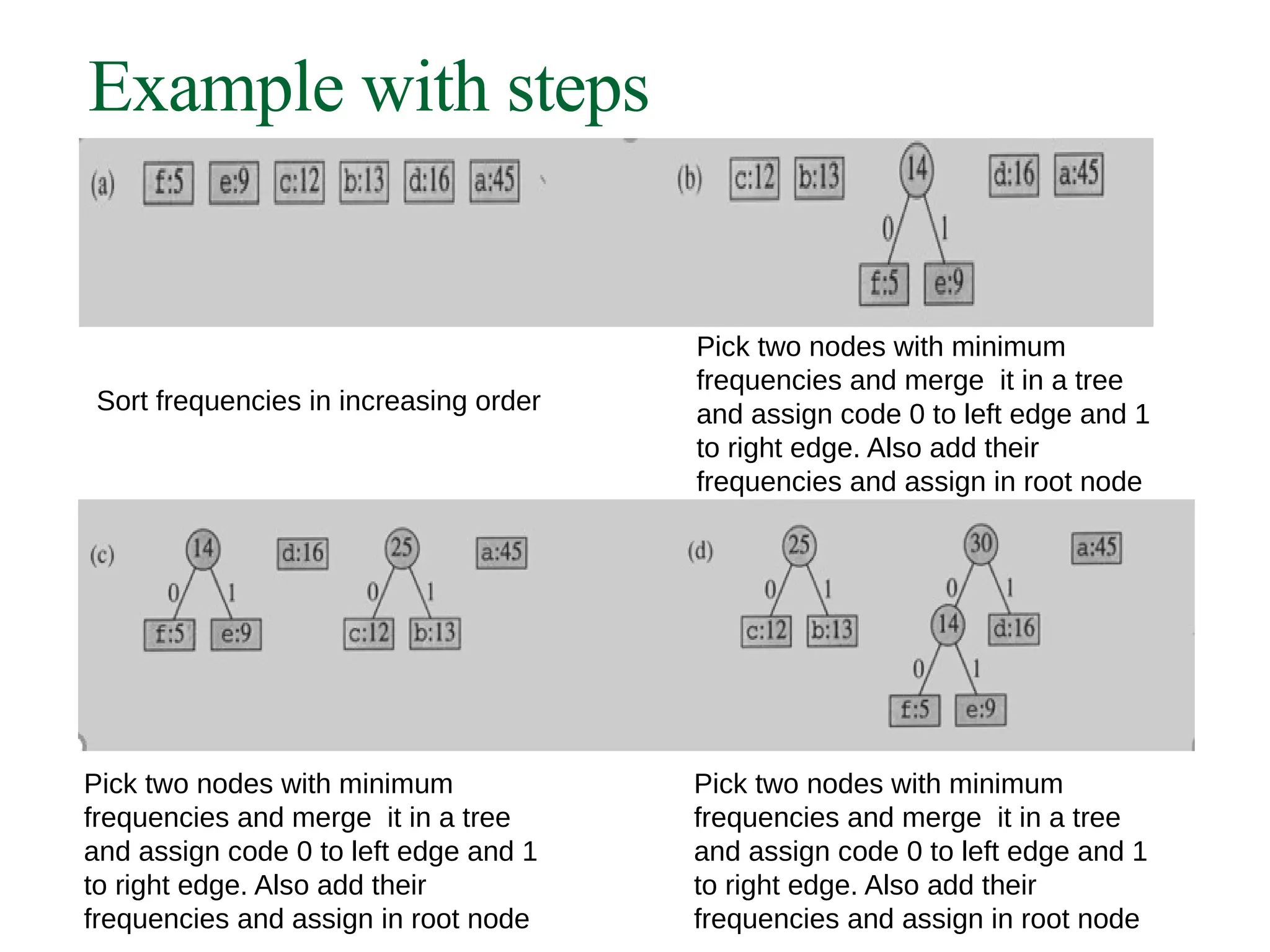
Example with steps
Sortfrequencies in increasing order
Pick two nodes with minimum
frequencies and merge it in a tree
and assign code 0 to left edge and 1
to right edge. Also add their
frequencies and assign in root node
Pick two nodes with minimum
frequencies and merge it in a tree
and assign code 0 to left edge and 1
to right edge. Also add their
frequencies and assign in root node
Pick two nodes with minimum
frequencies and merge it in a tree
and assign code 0 to left edge and 1
to right edge. Also add their
frequencies and assign in root node
10.
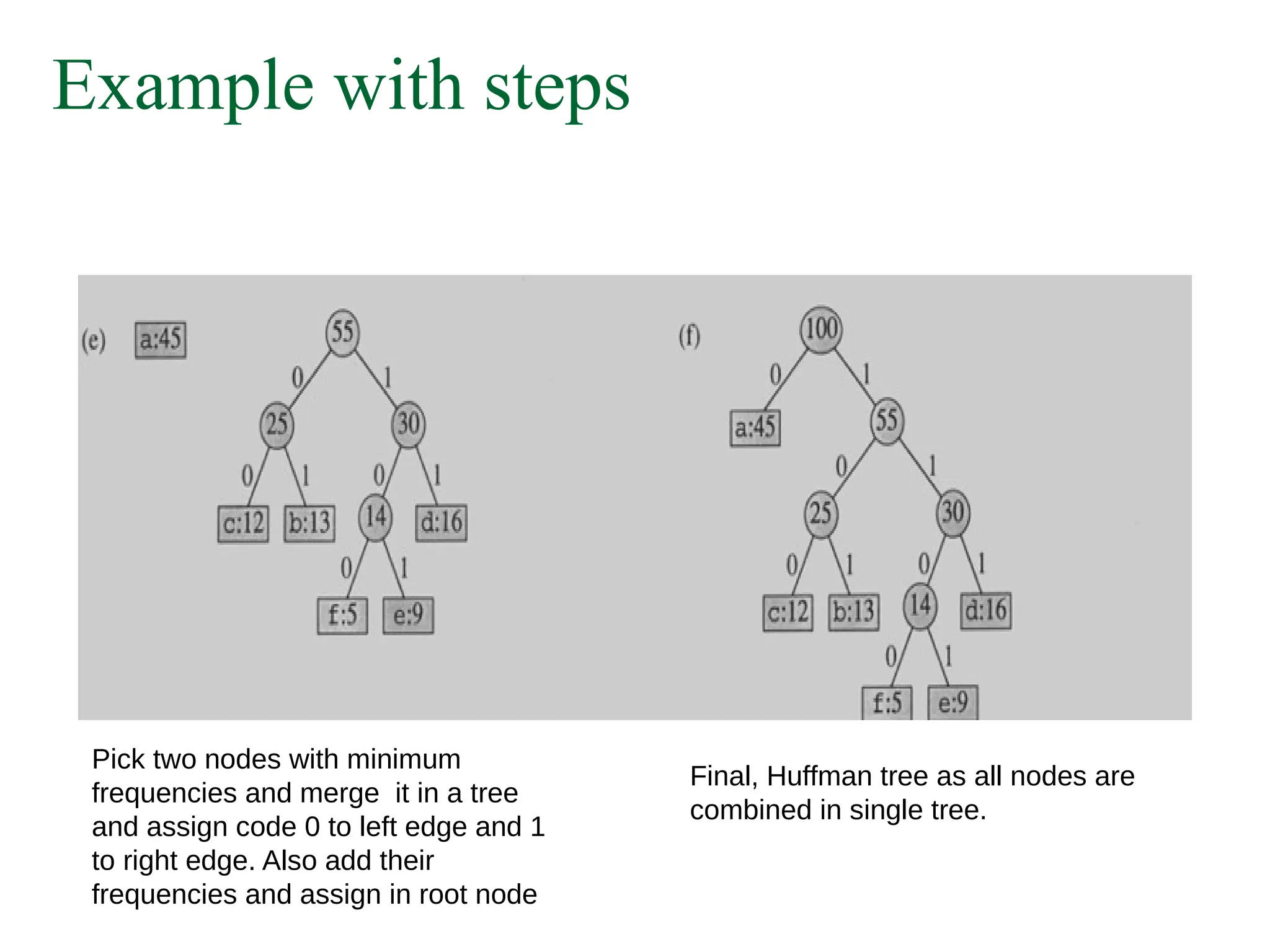
Example with steps
Picktwo nodes with minimum
frequencies and merge it in a tree
and assign code 0 to left edge and 1
to right edge. Also add their
frequencies and assign in root node
Final, Huffman tree as all nodes are
combined in single tree.
11.
Example with Steps
HuffmanCode For Characters-
To write Huffman Code for any character, traverse the Huffman Tree
from root node to the leaf node of that character.
Following this rule, the Huffman Code for each character is-
a = 0
c =100
b= 101
f = 1100
e = 1101
d = 111
Find Average Code Length-
Using formula-01, we have-
Average code length
= ∑ ( frequencyi x code lengthi ) / ∑ ( frequencyi )
= { (10 x 3) + (15 x 2) + (12 x 2) + (3 x 5) + (4 x 4) + (13 x 2) + (1 x 5) } /
(10 + 15 + 12 + 3 + 4 + 13 + 1)
=
12.
3. Length ofHuffman Encoded Message-
Using formula-02, we have-
Total number of bits in Huffman encoded message
= Total number of characters in the message x Average code length per
character
= 58 x 2.52
= 146.16
≅ 147 bits
13.
Huffman Coding Algorithm
//C is a set of n characters
// Q is implemented as a binary min-heap O(n)
Total computation time = O(n lg n)
O(lg n)
O(lg n)
O(lg n)
14.
Huffman Code
Problem
In thepseudocode that follows:
we assume that C is a set of n characters and
that each character c €C is an object with a
defined frequency f [c].
The algorithm builds the tree T corresponding to
the optimal code
A min-priority queue Q, is used to identify the
two least-frequent objects to merge together.
The result of the merger of two objects is a
new object whose frequency is the sum of the
frequencies of the two objects that were
merged.
15.
Running time ofHuffman's
algorithm
The running time of Huffman's algorithm
assumes that Q is implemented as a binary
min-heap.
For a set C of n characters, the initialization of
Q in line 2 can be performed in O(n) time using
the BUILD-MINHEAP
The for loop in lines 3-8 is executed exactly n -
1 times, and since each heap operation
requires time O(lg n), the loop contributes O(n
lg n) to the running time. Thus, the total
running time of HUFFMAN on a set of n
characters is O(n lg n).
16.
Prefix
Code
Prefix(-free) code:no codeword is also a prefix of some
other codewords (Un-ambiguous)
An optimal data compression achievable by a
character code can
always be achieved with a prefix code
Simplify the encoding (compression) and decoding
Encoding: Given the characters and their
frequencies, perform the algorithm and generate a
code. Write the characters using the code
example abc 0 . 101. 100 = 0101100
Decoding: Given the Huffman tree, figure out what
each character is (possible because of prefix
property)
example 001011101 = 0. 0. 101. 1101 aabe
Use binary tree to represent prefix codes for
easy decoding
17.
Application on Huffmancode
Both the .mp3 and .jpg file formats
use Huffman coding at one stage of
the compression










![Huffman Code
Problem
In the pseudocode that follows:
we assume that C is a set of n characters and
that each character c €C is an object with a
defined frequency f [c].
The algorithm builds the tree T corresponding to
the optimal code
A min-priority queue Q, is used to identify the
two least-frequent objects to merge together.
The result of the merger of two objects is a
new object whose frequency is the sum of the
frequencies of the two objects that were
merged.](https://image.slidesharecdn.com/huffmancoding-250908180959-871446f0/75/huffman-coding-_-14-2048.jpg)






































































