Delete的语义校正(续2)
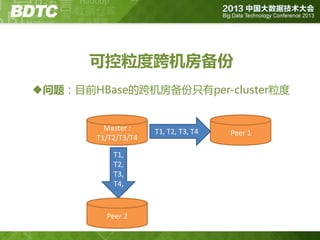
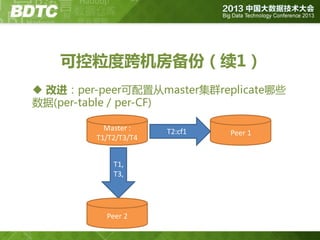
问题 2:数据一致性/正确性
① deletekv with T1, flush
② major compact: Y/N
③ put kv with T0, (flush?)
何时/是否发生major compact影响T0的存在不否,但
major compact对用户是透明的…
Master重构
目前Master的架构缺陷:
① regiontask状态通过zk结点的update-watchnotify机制传逑:ZooKeeper watch的”一次性”
和ZooKeeper notify的”异步”特点,会导致
丢失event
② region task状态存放在ZooKeeper:
ZooKeeper client的单io线程是大cluster
failover的瓶颈(包含大量region)
改进: https://issues.apache.org/jira/browse/HBASE-5487
① region task状态通过master-RS rpc传逑
② region task状态放在另一张系统表里