Downloaded 24 times





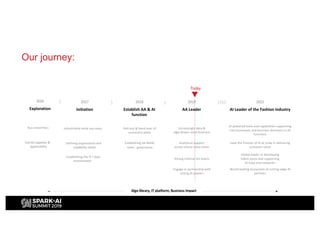




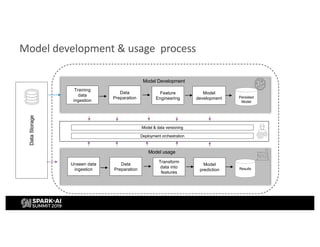
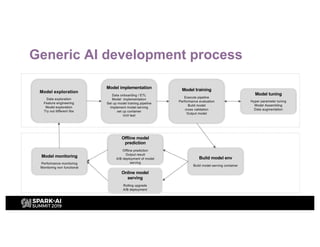
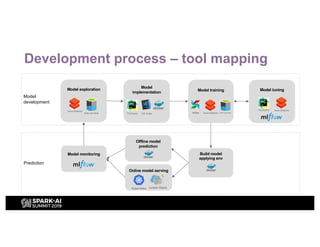
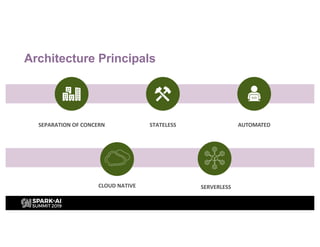
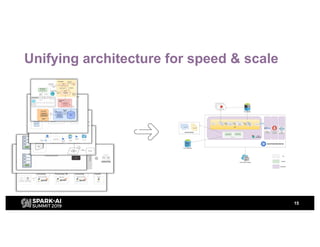

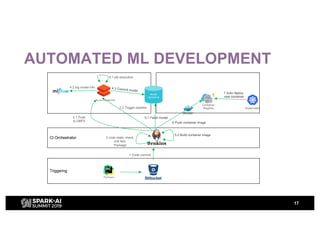
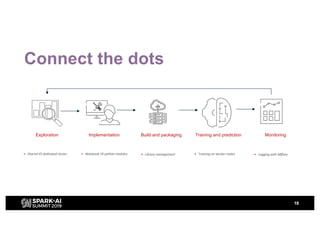

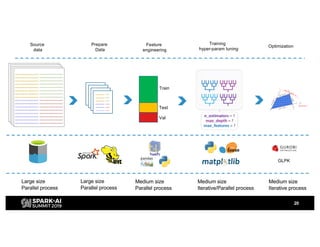

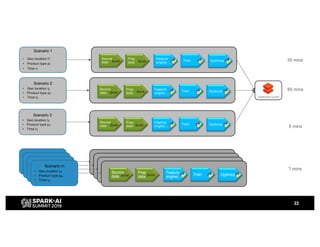
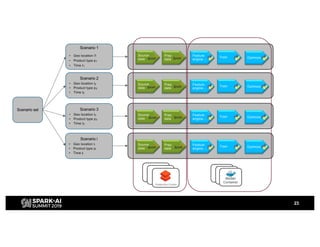

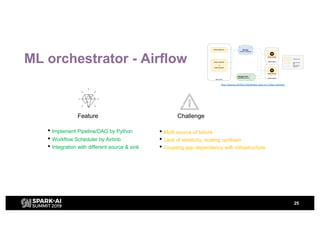
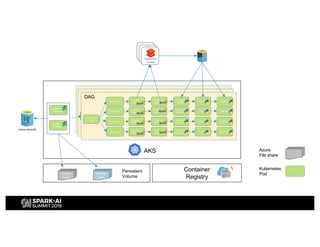



H&M's AI journey showcases their efforts in automating machine learning and enhancing analytics across various functions, emphasizing data-driven retail. The agenda includes a machine learning blueprint and automated ML development processes to optimize operations and customer experience. H&M aims to be a global leader in AI by fostering talent and forming partnerships within a pioneering AI ecosystem.























































































