




![“
[Spark is a] Fast and general-purpose
cluster computing platform for large-scale
data processing](https://image.slidesharecdn.com/spark-migrationstory-151123134742-lva1-app6891/85/Spark-Migration-Story-5-320.jpg)
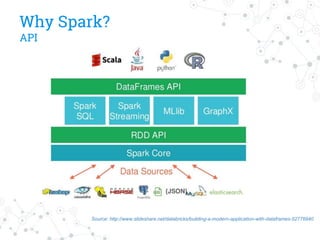
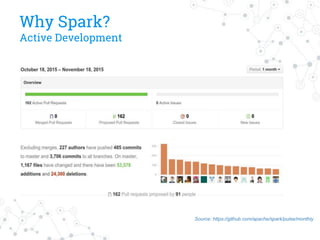
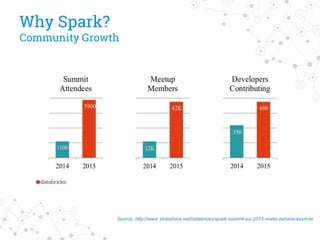



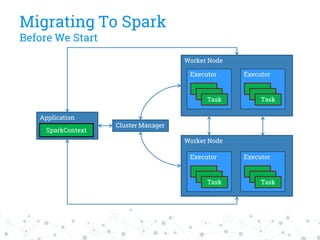



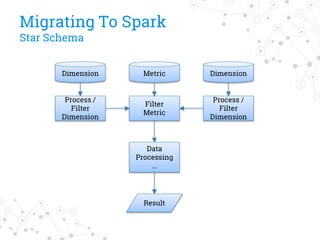




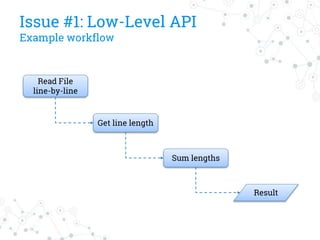




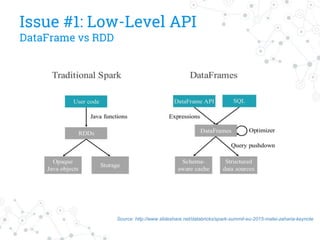
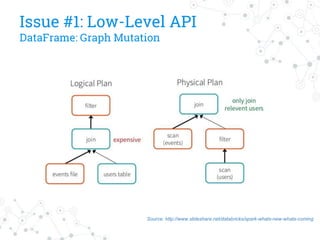



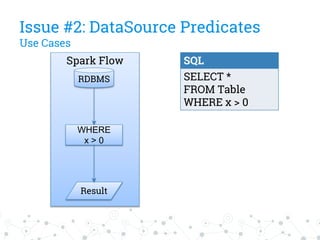
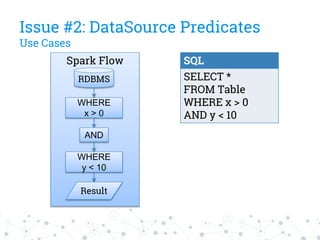
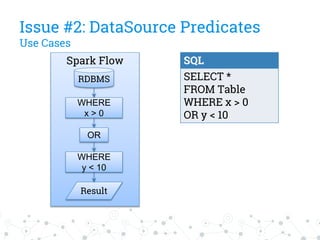
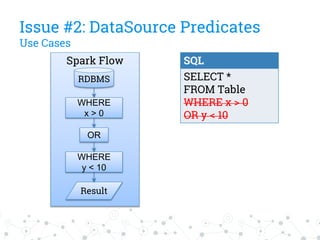







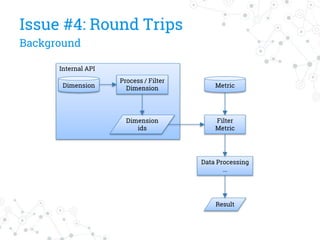
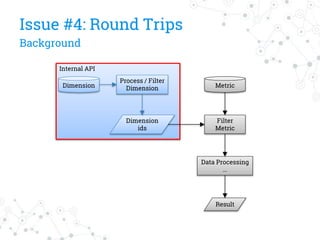

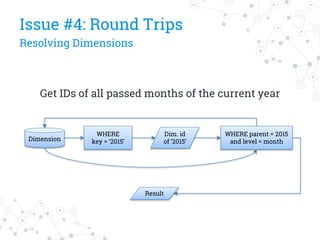
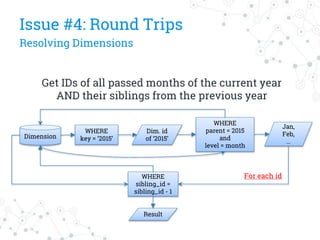













The document discusses a company's migration from their in-house computation engine to Apache Spark. It describes five key issues encountered during the migration process: 1) difficulty adapting to Spark's low-level RDD API, 2) limitations of DataSource predicates, 3) incomplete Spark SQL functionality, 4) performance issues with round trips between Spark and other systems, and 5) OutOfMemory errors due to large result sizes. Lessons learned include being aware of new Spark features and data formats, and designing architectures and data structures to minimize data movement between systems.





















































































