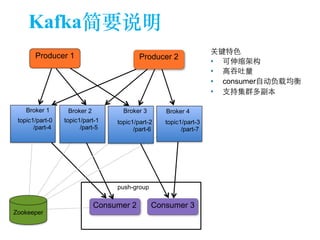
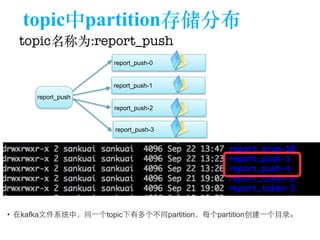
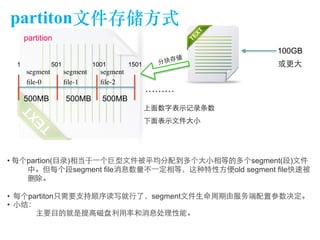
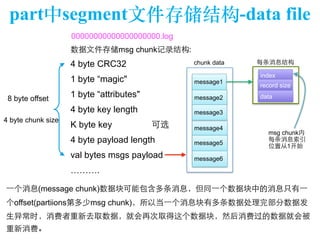
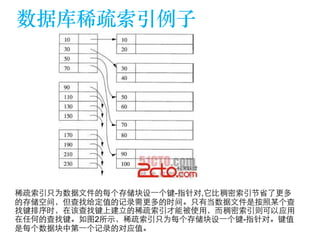
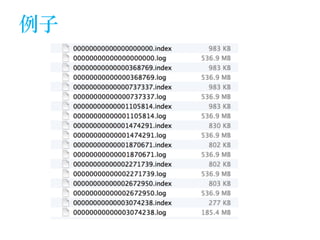
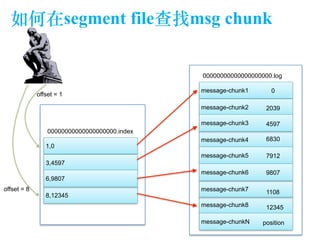
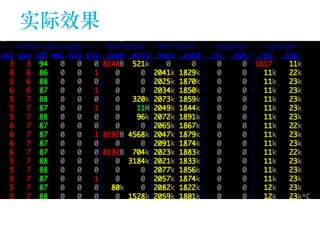
The document discusses the design of a Kafka file system, covering topics such as partition storage distribution, segment file structures, and methods for rapid segment file location. It highlights key features like scalability, high throughput, and automatic load balancing for consumers. The internal structure of segment files and sparse indexing is also described, emphasizing the efficiency of data processing and disk space utilization.