Downloaded 10 times




![Motivation: Why PHP?
• Top websites [http://www.alexa.com/topsites]:
1. Google
2. Youtube
3. Facebook
4. Baidu
5. Wikipedia
6. Yahoo
5
PHP](https://image.slidesharecdn.com/9-161115135634/75/HHVM-Efficient-and-Scalable-PHP-Hack-Execution-Guilherme-Ottoni-Facebook-5-2048.jpg)

![Motivation: Why HHVM?
• Top websites [http://www.alexa.com/topsites]:
1. Google
2. Youtube
3. Facebook
4. Baidu
5. Wikipedia
6. Yahoo
8
HHVM
• Many other adopters, e.g. Box, Etsy, Slack, Wordpress
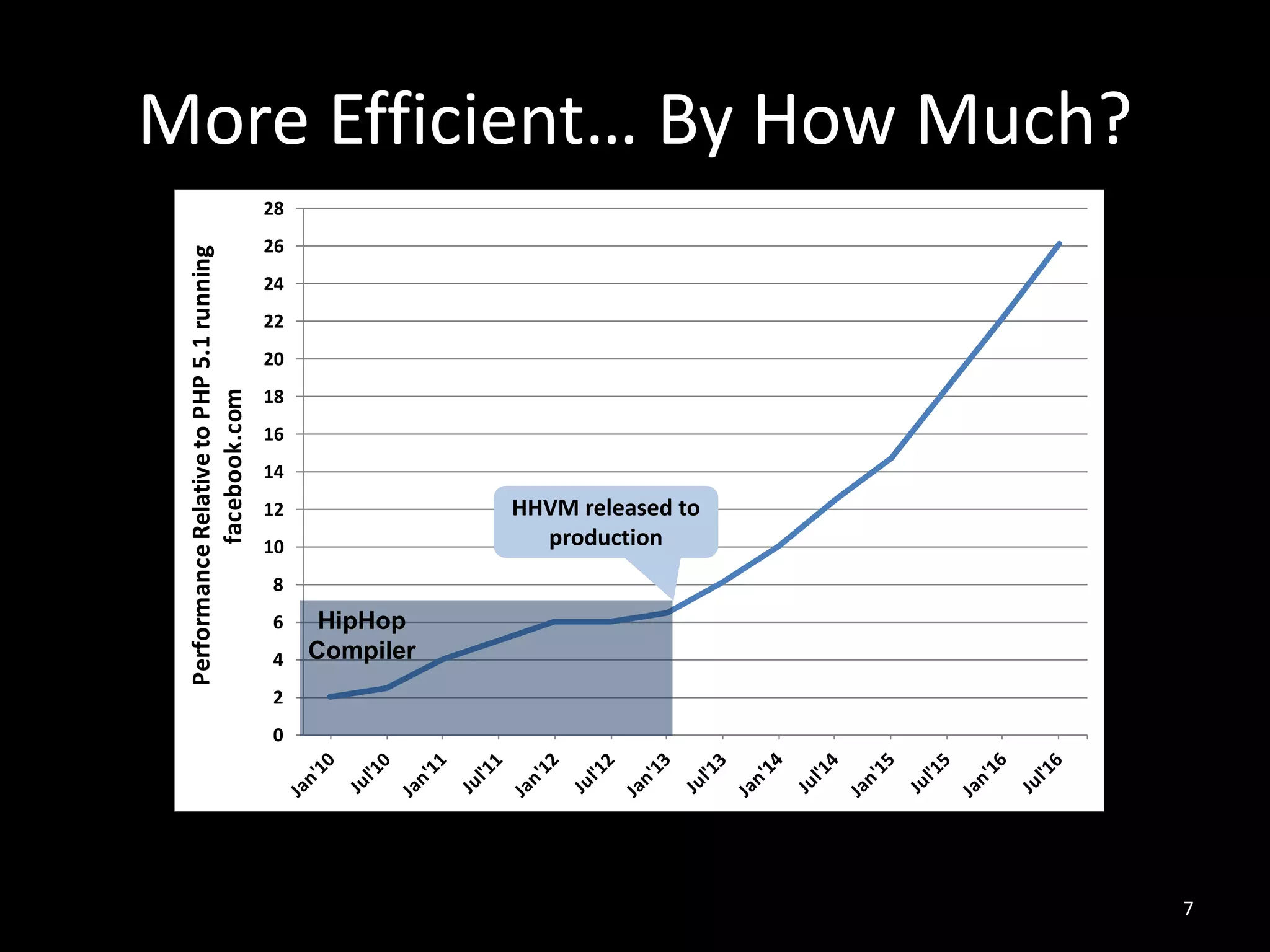
• Wikipedia’s CPU usage dropped by 6x when it
switched to HHVM
[http://hhvm.com/blog/7205/wikipedia-on-hhvm]](https://image.slidesharecdn.com/9-161115135634/75/HHVM-Efficient-and-Scalable-PHP-Hack-Execution-Guilherme-Ottoni-Facebook-8-2048.jpg)



![$elem: uncount; stk: dbl
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
$sum: dbl ; $elem: int
$sum: dbl ; $elem: dbl
$sum: int ; $elem: dbl
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
Example
13
81: CGetM <L:0 EL:3>
94: SetL 4
96: PopC
97: Int 0
106: CGetL2 4
108: Gt
109: JmpZ 13 (122)
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
71: CGetL 1
73: CGetL2 3
75: Lt
76: JmpZ 55 (131)
122: IncDecL 3 PreInc
125: PopC
126: Jmp -55
function addPositive($arr, $n) {
$sum = 0;
for ($i = 0; $i < $n; $i++) {
$elem = $arr[$i];
if ($elem > 0) {
$sum = $sum + $elem;
}
}
return $sum;
}
94: SetL 4
96: PopC
97: Int 0
106: CGetL2 4
108: Gt
109: JmpZ 13 (122)
$elem: uncount; stk: int
$i: int ; $n: int
$arr: array ; $i: int
$sum: int ; $elem: int
$i: int](https://image.slidesharecdn.com/9-161115135634/75/HHVM-Efficient-and-Scalable-PHP-Hack-Execution-Guilherme-Ottoni-Facebook-13-2048.jpg)
![$sum: dbl ; $elem: int
$elem: uncount; stk: dbl
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
$sum: dbl ; $elem: dbl
$sum: int ; $elem: dbl
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
Example
14
81: CGetM <L:0 EL:3>
94: SetL 4
96: PopC
97: Int 0
106: CGetL2 4
108: Gt
109: JmpZ 13 (122)
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
71: CGetL 1
73: CGetL2 3
75: Lt
76: JmpZ 55 (131)
122: IncDecL 3 PreInc
125: PopC
126: Jmp -55
function addPositive($arr, $n) {
$sum = 0;
for ($i = 0; $i < $n; $i++) {
$elem = $arr[$i];
if ($elem > 0) {
$sum = $sum + $elem;
}
}
return $sum;
}
94: SetL 4
96: PopC
97: Int 0
106: CGetL2 4
108: Gt
109: JmpZ 13 (122)
$elem: uncount; stk: int
$i: int ; $n: int
$arr: array ; $i: int
$sum: int ; $elem: int
$i: int](https://image.slidesharecdn.com/9-161115135634/75/HHVM-Efficient-and-Scalable-PHP-Hack-Execution-Guilherme-Ottoni-Facebook-14-2048.jpg)
![$elem: uncount; stk: dbl
$sum: dbl ; $elem: dbl
Example
15
81: CGetM <L:0 EL:3>
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
71: CGetL 1
73: CGetL2 3
75: Lt
76: JmpZ 55 (131)
122: IncDecL 3 PreInc
125: PopC
126: Jmp -55
function addPositive($arr, $n) {
$sum = 0;
for ($i = 0; $i < $n; $i++) {
$elem = $arr[$i];
if ($elem > 0) {
$sum = $sum + $elem;
}
}
return $sum;
}
94: SetL 4
96: PopC
97: Int 0
106: CGetL2 4
108: Gt
109: JmpZ 13 (122)
$i: int ; $n: int
$arr: array ; $i: int
$i: int](https://image.slidesharecdn.com/9-161115135634/75/HHVM-Efficient-and-Scalable-PHP-Hack-Execution-Guilherme-Ottoni-Facebook-15-2048.jpg)
![$elem: uncount; stk: dbl
$sum: dbl
Example
16
81: CGetM <L:0 EL:3>
114: CGetL 4
116: CGetL2 2
118: Add
119: SetL 2
121: PopC
71: CGetL 1
73: CGetL2 3
75: Lt
76: JmpZ 55 (131)
122: IncDecL 3 PreInc
125: PopC
126: Jmp -55
function addPositive($arr, $n) {
$sum = 0;
for ($i = 0; $i < $n; $i++) {
$elem = $arr[$i];
if ($elem > 0) {
$sum = $sum + $elem;
}
}
return $sum;
}
94: SetL 4
96: PopC
97: Int 0
106: CGetL2 4
108: Gt
109: JmpZ 13 (122)
$i: int ; $n: int
$arr: array](https://image.slidesharecdn.com/9-161115135634/75/HHVM-Efficient-and-Scalable-PHP-Hack-Execution-Guilherme-Ottoni-Facebook-16-2048.jpg)










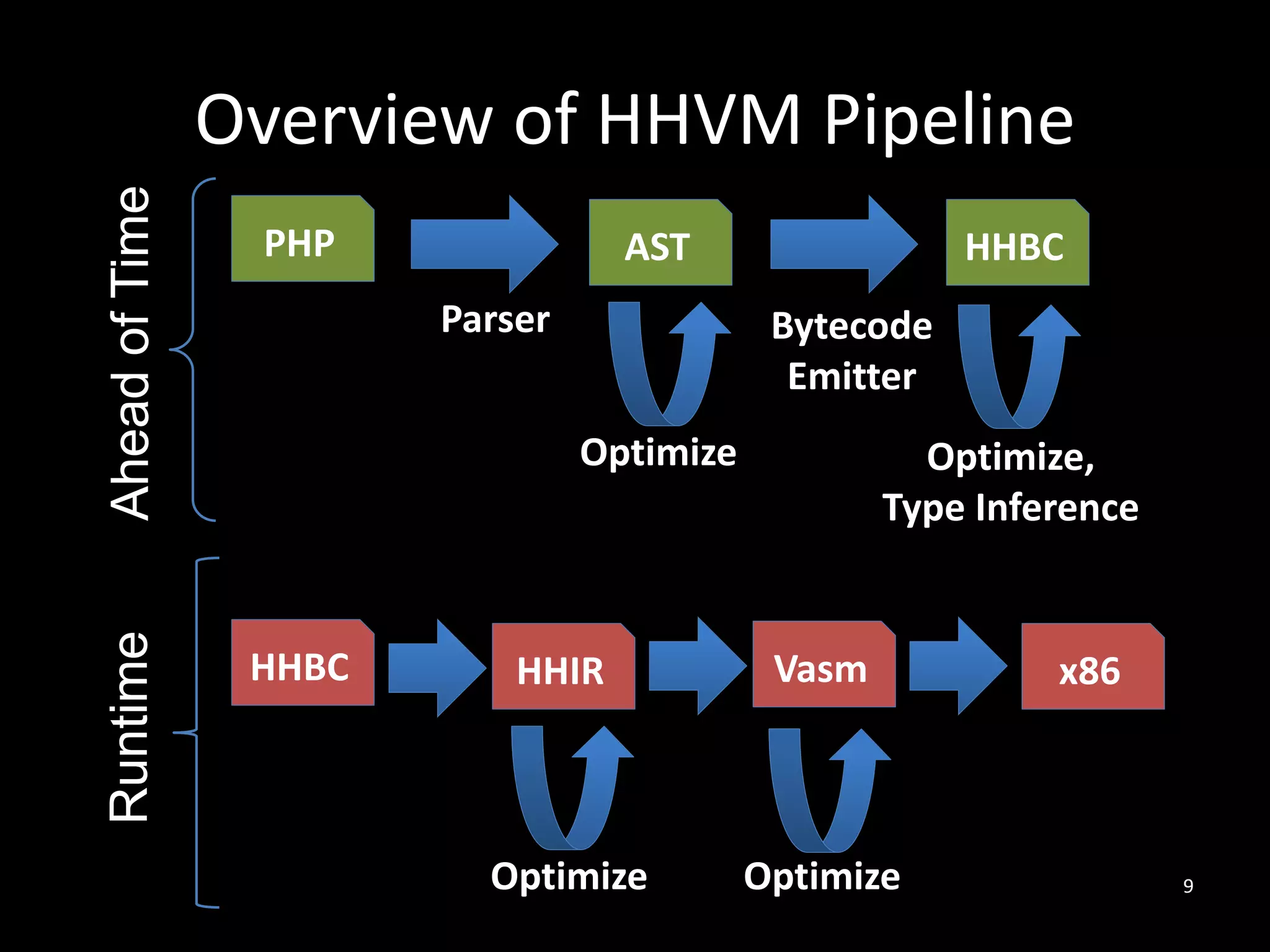
The document discusses HHVM, a high-performance PHP execution engine developed by Facebook, aimed at improving the efficiency of PHP applications. It highlights the challenges faced in PHP performance, including dynamic typing, large code size, and memory management, and explains how HHVM addresses these issues through techniques like just-in-time compilation and type specialization. Additionally, it notes HHVM's compatibility with standard PHP and its support for the Hack programming language.







































































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)



