This document summarizes a presentation given at PyCon TW 2017 about removing the Global Interpreter Lock (GIL) in Python to allow multi-threaded Python programs to take advantage of multi-processor systems. It begins with examples showing how the GIL currently prevents parallel execution across threads. It then explores approaches like using the dynamic linker and dlmopen() function to load separate copies of the Python shared library for each thread, thereby removing the shared GIL. While an ideal solution, challenges remain in fully implementing this approach.

![PyCon TW 2017
Preface
• GIL Episode I - Break the Seal[1]
• PyCon APAC 2015
• how to along with GIL peacefully
• GIL Episode II - project#23345678
• too boring for most of us
• GIL Episode III - cat < /dev/zero > GIL;
• how to nullify the GIL
2](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-2-2048.jpg)



![PyCon TW 2017
Example: 1a.c[2]
6
int main()
{
int ret = 1;
pthread_t t1, t2;
Py_Initialize();
PyRun_SimpleString("count = 23345678");
if (pthread_create(&t1, NULL, task1, NULL)) {
ERR("failed to pthread_create");
goto leave;
}
if (pthread_create(&t2, NULL, task2, NULL)) {
ERR("failed to pthread_create");
goto leave;
}
pthread_join(t1, NULL);
pthread_join(t2, NULL);
ret = 0;
leave:
Py_Finalize();
return ret;
}
void *task1(void *arg)
{
PyRun_SimpleString(
"import timen"
"print 'task1: {0:.6f}'.format(time.time())n"
"time.sleep(10)n"
"print 'task1: {0:.6f}'.format(time.time())n"
"print 'task1: {0}'.format(count)n"
);
return NULL;
}
void *task2(void *arg)
{
PyRun_SimpleString(
"import timen"
"print 'task2: {0:.6f}'.format(time.time())n"
"print 'task2: {0}'.format(count)n"
"for i in xrange(23345678):n"
" count += 1n"
"print 'task2: {0:.6f}'.format(time.time())n"
);
return NULL;
}
Get crashed if we don't acquire[3] the GIL before using the Python runtime.
$ ./1a
task1: 1481803678.055977
Segmentation fault (core dumped)](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-6-2048.jpg)
![PyCon TW 2017
GIL
Example: 1b.c[4]
7
void *task1(void *arg)
{
PyGILState_STATE gstate;
gstate = PyGILState_Ensure();
PyRun_SimpleString(
"import timen"
"print 'task1: {0:.6f}'.format(time.time())n"
"time.sleep(10)n"
"print 'task1: {0:.6f}'.format(time.time())n"
"print 'task1: {0}'.format(count)n"
);
PyGILState_Release(gstate);
return NULL;
}
int main()
{
[snip]
PyThreadState *th_state;
Py_Initialize();
PyEval_InitThreads();
[snip]
th_state = PyEval_SaveThread();
pthread_join(t1, NULL);
pthread_join(t2, NULL);
PyEval_RestoreThread(th_state);
[snip]
}
$ ./1b
task1: 1481804487.332934
task2: 1481804487.333096
task2: 23345678
task2: 1481804488.877374
task1: 1481804497.344352
task1: 46691356
void *task2(void *arg)
{
PyGILState_STATE gstate;
gstate = PyGILState_Ensure();
PyRun_SimpleString(
"import timen"
"print 'task2: {0:.6f}'.format(time.time())n"
"print 'task2: {0}'.format(count)n"
"for i in xrange(23345678):n"
" count += 1n"
"print 'task2: {0:.6f}'.format(time.time())n"
);
PyGILState_Release(gstate);
return NULL;
}
1.
3.
4.
5.
6.
7.
8.
11.
12.
13.
14.
15.
16.
2.
17.
acquire lock
release lock
Our multithreading program has been
serialized into one "effective" thread.
Note: if task2 get the lock first, the output will be different
$ ./1b
task2: 1496904735.421629
task2: 23345678
task1: 1496904735.421837
task2: 1496904736.919195
task1: 1496904745.433233
task1: 46691356
*9.
*10.
mark *: perhaps multiple times](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-7-2048.jpg)
![PyCon TW 2017
Ideal Example: 1c.c[5]
Object-like Programming
8
int main()
{
int ret = 1;
pthread_t t1, t2;
Python ctx1, ctx2;
Py_Initialize(&ctx1);
Py_Initialize(&ctx2);
PyRun_SimpleString(&ctx1, "count = 23345678");
PyRun_SimpleString(&ctx2, "count = 23345678");
if (pthread_create(&t1, NULL, task1, &ctx1)) {
ERR("failed to pthread_create");
goto leave;
}
if (pthread_create(&t2, NULL, task2, &ctx2)) {
ERR("failed to pthread_create");
goto leave;
}
pthread_join(t1, NULL);
pthread_join(t2, NULL);
ret = 0;
leave:
Py_Finalize(&ctx1);
Py_Finalize(&ctx2);
return ret;
}
void *task1(void *arg)
{
Python *ctx = arg;
PyRun_SimpleString(ctx,
"import timen"
"print 'task1: {0:.6f}'.format(time.time())n"
"time.sleep(10)n"
"print 'task1: {0:.6f}'.format(time.time())n"
"print 'task1: {0}'.format(count)n"
);
return NULL;
}
void *task2(void *arg)
{
Python *ctx = arg;
PyRun_SimpleString(ctx,
"import timen"
"print 'task2: {0:.6f}'.format(time.time())n"
"print 'task2: {0}'.format(count)n"
"for i in xrange(23345678):n"
" count += 1n"
"print 'task2: {0:.6f}'.format(time.time())n"
);
return NULL;
}
warning: the example won't compile successfully; only shows the ideal case
23345678
46691356](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-8-2048.jpg)


![PyCon TW 2017
Example: 2a.c[6]
11
void *task1(void *arg)
{
void *handle = dlopen("/usr/lib/x86_64-linux-gnu/libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlopen: %s", dlerror());
goto leave;
}
void (*_Py_Initialize)() = dlsym(handle, "Py_Initialize");
if (!_Py_Initialize) {
ERR("failed to dlsym: %s", dlerror());
goto leave;
}
int (*_PyRun_SimpleString)(const char *) = dlsym(handle, "PyRun_SimpleString");
if (!_PyRun_SimpleString) {
ERR("failed to dlsym: %s", dlerror());
goto leave;
}
[snip]
_Py_Initialize();
_PyRun_SimpleString("count = 23345678");
[snip]
}
void *task2(void *arg)
{
void *handle = dlopen("/usr/lib/x86_64-linux-gnu/libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlopen: %s", dlerror());
goto leave;
}
[snip]
}
$ ./2a
Segmentation fault (core dumped)
crashed
=> the GIL was still shared](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-11-2048.jpg)
![PyCon TW 2017
Example: 2b.c[7]
12
void *task1(void *arg)
{
void *handle = dlopen("./1.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlopen: %s", dlerror());
goto leave;
}
[snip]
}
void *task2(void *arg)
{
void *handle = dlopen("./2.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlopen: %s", dlerror());
goto leave;
}
[snip]
}
int main()
{
[snip]
system("cp /usr/lib/x86_64-linux-gnu/libpython2.7.so 1.so");
system("cp /usr/lib/x86_64-linux-gnu/libpython2.7.so 2.so");
[snip]
}
$ ./2b
task1: 1481821866.140683
task2: 1481821866.140725
task2: 23345678
task2: 1481821867.924265
task1: 1481821876.150968
task1: 23345678
2 distinct shared objects
2 different inodes
symbolic links won't do the trick
don't forget the "./"
dlopen(3) manual[8]:
If filename is NULL, then the returned
handle is for the main program. If
filename contains a slash ("/"), then it
is interpreted as a (relative or
absolute) pathname. Otherwise, the
dynamic linker searches for the object.
it works; but too silly](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-12-2048.jpg)
![PyCon TW 2017
Dynamic Linker
13
dlopen(3) manual[8]:
The dlmopen() function differs from dlopen() primarily in that it accepts an
additional argument, lmid, that specifies the link-map list (also referred to
as a namespace) in which the shared object should be loaded.
Possible uses of dlmopen() are plugins where the author of the plugin-
loading framework can't trust the plugin authors and does not wish any
undefined symbols from the plugin framework to be resolved to plugin
symbols. Another use is to load the same object more than once.
Without the use of dlmopen(), this would require the creation of distinct
copies of the shared object file. Using dlmopen(), this can be achieved
by loading the same shared object file into different namespaces.
The glibc implementation supports a maximum of 16 namespaces.](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-13-2048.jpg)
![PyCon TW 2017
Example: 2c.c[9] (1/2)
14
crashed?
void *task1(void *arg)
{
void *handle = dlmopen(LM_ID_NEWLM, "/usr/lib/x86_64-linux-gnu/libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlmopen: %s", dlerror());
goto leave;
}
[snip]
}
void *task2(void *arg)
{
void *handle = dlmopen(LM_ID_NEWLM, "/usr/lib/x86_64-linux-gnu/libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlmopen: %s", dlerror());
goto leave;
}
[snip]
}
$ ./2c
Segmentation fault (core dumped)](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-14-2048.jpg)
![PyCon TW 2017
Example: 2c.c[9] (2/2)
15
$ LD_DEBUG=all LD_DEBUG_OUTPUT=x ./2c
Segmentation fault (core dumped)
56072: calling init: /lib/x86_64-linux-gnu/libc.so.6
56072:
56072: symbol=__vdso_clock_gettime; lookup in file=linux-vdso.so.1 [0]
56072: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_clock_gettime' [LINUX_2.6]
56072: symbol=__vdso_getcpu; lookup in file=linux-vdso.so.1 [0]
56072: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_getcpu' [LINUX_2.6]
56072:
56072: calling init: /lib/x86_64-linux-gnu/libm.so.6
56072:
56072:
56072: calling init: /lib/x86_64-linux-gnu/libutil.so.1
56072:
56072:
56072: calling init: /lib/x86_64-linux-gnu/libdl.so.2
56072:
56072:
56072: calling init: /lib/x86_64-linux-gnu/libz.so.1
56072:
56072:
56072: calling init: /usr/lib/x86_64-linux-gnu/libpython2.7.so
56072:
56072: opening file=/usr/lib/x86_64-linux-gnu/libpython2.7.so [1]; direct_opencount=1
56072: calling init: /lib/x86_64-linux-gnu/libc.so.6
56072:
56072: symbol=__vdso_clock_gettime; lookup in file=linux-vdso.so.1 [0]
56072: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_clock_gettime' [LINUX_2.6]
56072: symbol=__vdso_getcpu; lookup in file=linux-vdso.so.1 [0]
56072: binding file linux-vdso.so.1 [0] to linux-vdso.so.1 [0]: normal symbol `__vdso_getcpu' [LINUX_2.6]
see ld.so(8)[10]
still don't know why; has some clues to trace; need too much patient](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-15-2048.jpg)
![PyCon TW 2017
Example: 3a.c[11] 3b.c[12]
16
int global = 23345678;
void print()
{
printf("%ld: %dn", syscall(SYS_gettid), global++);
}
void *task(void *arg)
{
void *handle = dlmopen(LM_ID_NEWLM, "./3a.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlmopen: %s", dlerror());
goto leave;
}
void (*print)() = dlsym(handle, "print");
if (!print) {
ERR("failed to dlsym: %s", dlerror());
goto leave;
}
print(); sched_yield();
print(); sched_yield();
print();
leave:
if (handle)
dlclose(handle);
return NULL;
}
dlmopen( ) is truly separate global variables into two namespaces
$ ./3b
55230: 23345678
55231: 23345678
55230: 23345679
55231: 23345679
55230: 23345680
55231: 23345680
$ gcc -shared -fPIC -o 3a.so 3a.c
exercise: replace the dlmopen( ) to dlopen( ) and observe the output](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-16-2048.jpg)
![PyCon TW 2017
Example: 4a.c[13]
17
int main()
{
int ret = 1;
pthread_t t1;
if (pthread_create(&t1, NULL, task, NULL)) {
ERR("failed to pthread_create");
goto leave;
}
pthread_join(t1, NULL);
if (pthread_create(&t1, NULL, task, NULL)) {
ERR("failed to pthread_create");
goto leave;
}
pthread_join(t1, NULL);
ret = 0;
leave:
return ret;
}
dlmopen( ) with libpython2.7.so still get
crashed even in a very basic usage
$ ./4a
Segmentation fault (core dumped)
test combination: glibc 2.12 + python 2.7.12
void *task(void *arg)
{
void *handle = dlmopen(LM_ID_NEWLM, "/usr/lib/x86_64-linux-gnu/libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlmopen: %s", dlerror());
goto leave;
}
dlclose(handle);
leave:
return NULL;
}
exercise: further tests and observations on 4b.c[14] and 4c.c[15]](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-17-2048.jpg)

![PyCon TW 2017
Example: 6a.py[16]
Entropy Calculation
19
switch_on = False
def dbg(msg):
print('[DEBUG] {0}'.format(msg))
class Entropy(object):
def __init__(self):
self._count = defaultdict(int)
self._size = 0
def update(self, data):
for c in data:
self._count[ord(c)] += 1
self._size += len(data)
def final(self):
if not self._size:
return 0.0
ent = 0.0
for i, c in self._count.items():
prob = float(c) / float(self._size)
ent -= prob * log(prob)
return ent / log(2.0)
def run():
current_on = False
ent = None
# ```mknod /dev/urandom c 1 9''' if the device doesn't exist
with open('/dev/urandom') as rf:
while True:
if not switch_on:
if current_on:
print('{0:.4f}'.format(ent.final()))
current_on = False
ent = None
dbg('switch off')
time.sleep(1)
else:
if not current_on:
current_on = True
ent = Entropy()
dbg('switch on')
data = rf.read(4096)
ent.update(data)
the toggle switch
the entry point, no return
Note: the code is mainly for python2; it needs some modifications for python3](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-19-2048.jpg)
![PyCon TW 2017
Example: 6b.c[17] (1/4)
Main Function
20
int main()
{
int ret = 1;
pthread_t calc, config, nihao5884;
struct context ctx = {0};
sigset_t sigmask;
pthread_mutex_init(&ctx.lock, NULL);
pthread_cond_init(&ctx.cond, NULL);
sigemptyset(&sigmask);
sigaddset(&sigmask, SIGUSR1);
if (pthread_sigmask(SIG_BLOCK, &sigmask, NULL)) {
ERR("failed to pthread_sigmask");
goto leave;
}
if (pthread_create(&calc, NULL, calc_task, &ctx)) {
ERR("failed to pthread_create");
goto leave;
}
if (pthread_create(&config, NULL, config_task, &ctx)) {
ERR("failed to pthread_create");
goto leave;
}
if (pthread_create(&nihao5884, NULL, nihao5884_task, &ctx)) {
ERR("failed to pthread_create");
goto leave;
}
pthread_join(calc, NULL);
pthread_join(config, NULL);
pthread_join(nihao5884, NULL);
/* never reachable */
[snip]
struct common_operations {
void (*_Py_InitializeEx)(int);
void (*_Py_Finalize)();
int (*_PyRun_SimpleFileEx)(FILE *, const char *, int);
PyObject *(*_PyModule_New)(const char *);
PyObject *(*_PyModule_GetDict)(PyObject *);
PyObject *(*_PyDict_GetItemString)(PyObject *, const char *);
PyObject *(*_PyImport_ImportModule)(const char *);
PyObject *(*_PyObject_CallObject)(PyObject *, PyObject *);
void (*_Py_IncRef)(PyObject *);
void (*_Py_DecRef)(PyObject *);
void (*_PyEval_InitThreads)();
PyThreadState *(*_PyEval_SaveThread)();
void (*_PyEval_RestoreThread)(PyThreadState *);
void *(*_PyGILState_Ensure)();
void (*_PyGILState_Release)(void *);
int (*_PyRun_SimpleString)(const char *);
long (*_PyLong_AsLong)(PyObject *);
PyObject *(*_PyBool_FromLong)(long);
int (*_PyDict_SetItemString)(PyObject *, const char *, PyObject *);
};
struct context {
pthread_mutex_t lock;
pthread_cond_t cond;
PyObject *calc_main_dict;
struct common_operations *calc_ops;
int cur_switch_on;
};
very simple architecture:
3 worker threads
1 shared context
a few function pointers](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-20-2048.jpg)
![PyCon TW 2017
ops._PyEval_InitThreads();
ops._Py_InitializeEx(0);
ops._PyRun_SimpleFileEx(fp, "6a.py", 1 /* closeit, fp will be closed */);
main_module = ops._PyImport_ImportModule("__main__");
if (!main_module) {
ERR("failed to _PyImport_ImportModule");
goto leave_python;
}
ctx->calc_main_dict = ops._PyModule_GetDict(main_module);
if (!ctx->calc_main_dict) {
ERR("failed to _PyModule_GetDict");
goto leave_python;
}
ops._Py_IncRef(ctx->calc_main_dict);
switch_on = ops._PyDict_GetItemString(ctx->calc_main_dict, "switch_on");
if (!switch_on) {
ERR("failed to _PyDict_GetItemString");
goto leave_python;
}
ctx->cur_switch_on = ops._PyLong_AsLong(switch_on);
run_method = ops._PyDict_GetItemString(ctx->calc_main_dict, "run");
if (!run_method) {
ERR("failed to _PyDict_GetItemString");
goto leave_python;
}
ops._Py_IncRef(run_method);
pthread_mutex_lock(&ctx->lock);
ctx->calc_ops = &ops;
pthread_cond_signal(&ctx->cond);
pthread_mutex_unlock(&ctx->lock);
ops._PyObject_CallObject(run_method, NULL);
/* never reachable */
Example: 6b.c[17] (2/4)
Calculation Task
21
void *calc_task(void *arg)
{
struct context *ctx = arg;
struct common_operations ops = {0};
void *handle = NULL;
FILE *fp = NULL;
PyObject *main_module = NULL, *run_method = NULL, *switch_on;
system("cp /usr/lib/x86_64-linux-gnu/libpython2.7.so calc_libpython2.7.so");
handle = dlopen("./calc_libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
if (!handle) {
ERR("failed to dlopen: %s", dlerror());
goto leave;
}
if (!resolve_common_operations(handle, &ops)) {
ERR("failed to resolve_common_operations");
goto leave;
}
fp = fopen("6a.py", "r");
if (!fp) {
ERR("failed to fopen: %s", strerror(errno));
goto leave;
}
the entry point of 6a.py
no return
"calc" Python runtime](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-21-2048.jpg)
![PyCon TW 2017
void *config_task(void *arg)
{
[snip]
handle = dlopen("./config_libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
[snip]
while (1) {
ops._PyRun_SimpleString(
"import jsonn"
"calc = json.load(open('"CONFIG_FILE"'))['calc']n"
);
calc = ops._PyDict_GetItemString(main_dict, "calc");
if (!calc) {
ERR("failed to _PyDict_GetItemString");
goto leave_python;
}
if (ops._PyLong_AsLong(calc) != ctx->cur_switch_on) {
DBG("state changed: from %d to %d", ctx->cur_switch_on, 1 - ctx->cur_switch_on);
ctx->cur_switch_on = 1 - ctx->cur_switch_on;
state = ctx->calc_ops->_PyGILState_Ensure();
obj = ctx->calc_ops->_PyBool_FromLong(ctx->cur_switch_on);
if (!obj) {
ERR("failed to _PyBool_FromLong");
ctx->calc_ops->_PyGILState_Release(state);
goto leave_python;
}
if (ctx->calc_ops->_PyDict_SetItemString(ctx->calc_main_dict, "switch_on", obj)) {
ERR("failed to _PyDict_SetItemString");
ctx->calc_ops->_Py_DecRef(obj);
ctx->calc_ops->_PyGILState_Release(state);
goto leave_python;
}
ctx->calc_ops->_Py_DecRef(obj);
ctx->calc_ops->_PyGILState_Release(state);
}
[snip]
}
}
Example: 6b.c[17] (3/4)
Configuration Task
22
parse the JSON configuration
file in "config" Python runtime
acquire the GIL of "calc" Python runtime
release the GIL of "calc" Python runtime
modify the toggle switch in 6a.py
in "calc" Python runtime](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-22-2048.jpg)
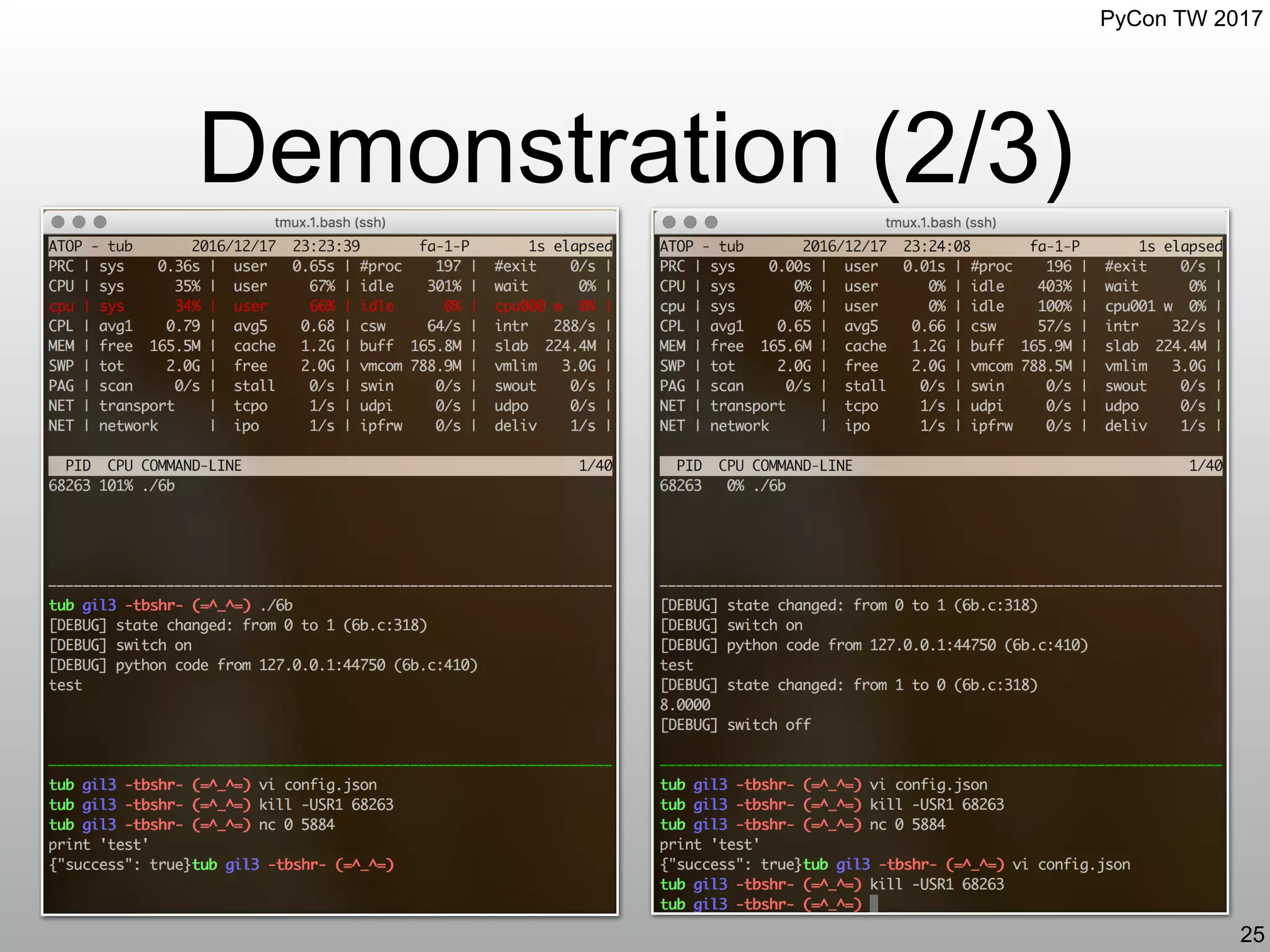
![PyCon TW 2017
Example: 6b.c[17] (4/4)
nihao5884 Task
23
void *nihao5884_task(void *arg)
{
[snip]
handle = dlopen("./nihao5884_libpython2.7.so", RTLD_LAZY | RTLD_LOCAL);
[snip]
ops._Py_InitializeEx(0);
while (1) {
static const char *success = "{"success": true}";
static const char *fail = "{"success": false}";
struct sockaddr_in caddr;
socklen_t len = sizeof(caddr);
int n;
char buf[40960];
cfd = accept(sfd, (struct sockaddr *) &caddr, &len);
if (cfd == -1) {
ERR("failed to accept: %s", strerror(errno));
goto python_leave;
}
DBG("python code from %s:%d", inet_ntop(AF_INET, &caddr.sin_addr, buf, len), ntohs(caddr.sin_port));
n = read(cfd, buf, sizeof(buf) / sizeof(buf[0]));
if (n == -1) {
ERR("failed to read: %s", strerror(errno));
goto python_leave;
}
buf[n] = 0;
/* forget it if write isn't success */
if (ops._PyRun_SimpleString(buf) == 0)
write(cfd, success, strlen(success));
else
write(cfd, fail, strlen(fail));
close(cfd);
cfd = -1;
}
[snip]
}
yet another "nihao5884" Python runtime
executing the backdoor command in
"nihao5884" Python runtime](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-23-2048.jpg)
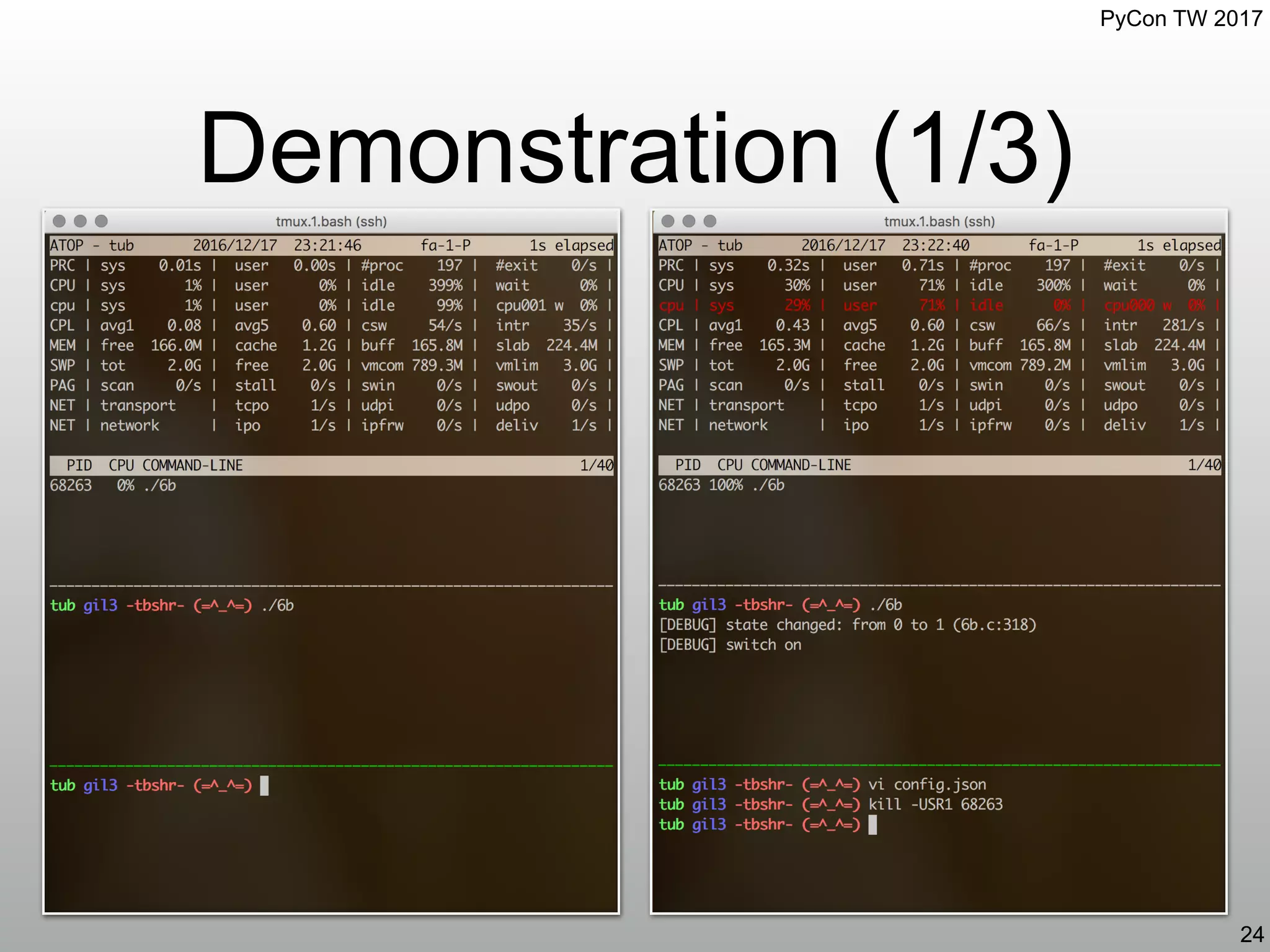
![PyCon TW 2017
Demonstration (3/3)
26
$ less /proc/68263/maps
00400000-00403000 r-xp 00000000 08:01 264227 /home/tbshr/gil3/6b
00602000-00603000 r--p 00002000 08:01 264227 /home/tbshr/gil3/6b
00603000-00604000 rw-p 00003000 08:01 264227 /home/tbshr/gil3/6b
00705000-00726000 rw-p 00000000 00:00 0 [heap]
[snip]
7f1de9de2000-7f1dea0d4000 r-xp 00000000 08:01 264267 /home/tbshr/gil3/config_libpython2.7.so
7f1dea0d4000-7f1dea2d4000 ---p 002f2000 08:01 264267 /home/tbshr/gil3/config_libpython2.7.so
7f1dea2d4000-7f1dea2d6000 r--p 002f2000 08:01 264267 /home/tbshr/gil3/config_libpython2.7.so
7f1dea2d6000-7f1dea34d000 rw-p 002f4000 08:01 264267 /home/tbshr/gil3/config_libpython2.7.so
7f1dea34d000-7f1dea370000 rw-p 00000000 00:00 0
7f1dea370000-7f1dea662000 r-xp 00000000 08:01 271854 /home/tbshr/gil3/nihao5884_libpython2.7.so
7f1dea662000-7f1dea862000 ---p 002f2000 08:01 271854 /home/tbshr/gil3/nihao5884_libpython2.7.so
7f1dea862000-7f1dea864000 r--p 002f2000 08:01 271854 /home/tbshr/gil3/nihao5884_libpython2.7.so
7f1dea864000-7f1dea8db000 rw-p 002f4000 08:01 271854 /home/tbshr/gil3/nihao5884_libpython2.7.so
7f1dea8db000-7f1dea8fe000 rw-p 00000000 00:00 0
[snip]
7f1deb024000-7f1deb316000 r-xp 00000000 08:01 271846 /home/tbshr/gil3/calc_libpython2.7.so
7f1deb316000-7f1deb516000 ---p 002f2000 08:01 271846 /home/tbshr/gil3/calc_libpython2.7.so
7f1deb516000-7f1deb518000 r--p 002f2000 08:01 271846 /home/tbshr/gil3/calc_libpython2.7.so
7f1deb518000-7f1deb58f000 rw-p 002f4000 08:01 271846 /home/tbshr/gil3/calc_libpython2.7.so
7f1deb58f000-7f1deb5b2000 rw-p 00000000 00:00 0
7f1deb5b2000-7f1deb5b3000 ---p 00000000 00:00 0](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-26-2048.jpg)

![PyCon TW 2017
References
28
[1]: http://www.slideshare.net/penvirus/global-interpreter-lock-episode-i-break-the-seal
[2]: https://github.com/penvirus/gil3/blob/master/1a.c
[3]: https://docs.python.org/2.7/c-api/init.html#non-python-created-threads
[4]: https://github.com/penvirus/gil3/blob/master/1b.c
[5]: https://github.com/penvirus/gil3/blob/master/1c.c
[6]: https://github.com/penvirus/gil3/blob/master/2a.c
[7]: https://github.com/penvirus/gil3/blob/master/2b.c
[8]: http://man7.org/linux/man-pages/man3/dlopen.3.html
[9]: https://github.com/penvirus/gil3/blob/master/2c.c
[10]: http://man7.org/linux/man-pages/man8/ld.so.8.html
[11]: https://github.com/penvirus/gil3/blob/master/3a.c
[12]: https://github.com/penvirus/gil3/blob/master/3b.c
[13]: https://github.com/penvirus/gil3/blob/master/4a.c
[14]: https://github.com/penvirus/gil3/blob/master/4b.c
[15]: https://github.com/penvirus/gil3/blob/master/4c.c
[16]: https://github.com/penvirus/gil3/blob/master/6a.py
[17]: https://github.com/penvirus/gil3/blob/master/6b.c](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-28-2048.jpg)
![PyCon TW 2017
Appendix: Road to Practical (1/7)
• the trick is shared object-dependent
• libpythonX.X.so provided by the distribution may
not applicable
• if do so, recompile the libpythonX.X.so
29
we will use 6b.c[17] as an example and need to get your hands
dirty enough to make it work](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-29-2048.jpg)
![PyCon TW 2017
Appendix: Road to Practical (2/7)
30
# download the source code
$ wget https://www.python.org/ftp/python/2.7.13/Python-2.7.13.tar.xz
# decompress and untar
$ tar Jxf Python-2.7.13.tar.xz
# get the configuration args
$ python
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sysconfig
>>> sysconfig.get_config_var('CONFIG_ARGS')
"'--enable-shared' '--prefix=/usr' '--enable-ipv6' '--enable-unicode=ucs4' '--with-
dbmliborder=bdb:gdbm' '--with-system-expat' '--with-computed-gotos' '--with-system-ffi' '--with-
fpectl' 'CC=x86_64-linux-gnu-gcc' 'CFLAGS=-Wdate-time -D_FORTIFY_SOURCE=2 -g -fstack-protector-
strong -Wformat -Werror=format-security ' 'LDFLAGS=-Wl,-Bsymbolic-functions -Wl,-z,relro'"
# configure with referenced options
$ cd Python-2.7.13
$ CC=x86_64-linux-gnu-gcc CFLAGS='-Wdate-time -D_FORTIFY_SOURCE=2 -g -fstack-protector-strong -
Wformat -Werror=format-security' LDFLAGS='-Wl,-Bsymbolic-functions -Wl,-z,relro' ./configure --
prefix=/tmp/AAA --enable-shared --enable-ipv6 --enable-unicode=ucs4 --with-dbmliborder=bdb:gdbm
--with-system-expat --with-computed-gotos --with-system-ffi --with-fpectl
$ make -j4
$ make install
temporary test folder](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-30-2048.jpg)
![PyCon TW 2017
Appendix: Road to Practical (3/7)
31
$ PYTHONHOME=/tmp/AAA PYTHONPATH=/tmp/AAA/lib ./6b
# and you will find that it doesn't work
$ python
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import time
>>> time
<module 'time' (built-in)>
$ PYTHONHOME=/tmp/AAA PYTHONPATH=/tmp/AAA/lib LD_LIBRARY_PATH=/tmp/AAA/lib /tmp/AAA/bin/python2.7
Python 2.7.13 (default, Feb 14 2017, 17:49:28)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import time
>>> time
<module 'time' from '/tmp/AAA/lib/python2.7/lib-dynload/time.so'>
we need the output binaries more tightly-coupled, i.e., built-in](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-31-2048.jpg)
![PyCon TW 2017
Appendix: Road to Practical (4/7)
32
$ cd Python-2.7.13
$ vim Modules/Setup
[snip]
posix posixmodule.c # posix (UNIX) system calls
errno errnomodule.c # posix (UNIX) errno values
pwd pwdmodule.c # this is needed to find out the user's home dir
# if $HOME is not set
_sre _sre.c # Fredrik Lundh's new regular expressions
_codecs _codecsmodule.c # access to the builtin codecs and codec registry
_weakref _weakref.c # weak references
[snip]
array arraymodule.c # array objects
cmath cmathmodule.c _math.c # -lm # complex math library functions
math mathmodule.c # -lm # math library functions, e.g. sin()
_struct _struct.c # binary structure packing/unpacking
#time timemodule.c # -lm # time operations and variables
$ make -j4
$ make install
$ PYTHONHOME=/tmp/AAA PYTHONPATH=/tmp/AAA/lib LD_LIBRARY_PATH=/tmp/AAA/lib /tmp/AAA/bin/python2.7
Python 2.7.13 (default, Feb 14 2017, 18:11:25)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import time
>>> time
<module 'time' (built-in)>
uncomment as much as you can
we got it, the time.so embedded into libpython2.7.so
instead of an individual shared object](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-32-2048.jpg)
![PyCon TW 2017
Appendix: Road to Practical (5/7)
33
$ PYTHONHOME=/tmp/AAA PYTHONPATH=/tmp/AAA/lib ./6b
^C
$ PYTHONHOME=/tmp/AAA PYTHONPATH=/tmp/AAA/lib ./6b
^C
$ PYTHONHOME=/tmp/AAA PYTHONPATH=/tmp/AAA/lib ./6b
Fatal Python error: PyThreadState_Get: no current thread
Aborted (core dumped)
and you will find that it doesn't work SOMETIMES
$ gdb 6b
(gdb) set environment PYTHONHOME /tmp/AAA
(gdb) set environment PYTHONPATH /tmp/AAA/lib
(gdb) run
[snip]
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/AAA/lib/python2.7/json/__init__.py", line 108, in <module>
from .decoder import JSONDecoder
File "/tmp/AAA/lib/python2.7/json/decoder.py", line 7, in <module>
from json import scanner
File "/tmp/AAA/lib/python2.7/json/scanner.py", line 5, in <module>
from _json import make_scanner as c_make_scanner
what's wrong on JSON?](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-33-2048.jpg)
![PyCon TW 2017
Appendix: Road to Practical (6/7)
34
$ ldd /tmp/AAA/lib/python2.7/lib-dynload/_json.so
linux-vdso.so.1 => (0x00007ffe483f2000)
libpython2.7.so.1.0 => /usr/lib/x86_64-linux-gnu/libpython2.7.so.1.0 (0x00007fc988924000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fc988707000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fc98833d000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007fc988123000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fc987f1f000)
libutil.so.1 => /lib/x86_64-linux-gnu/libutil.so.1 (0x00007fc987d1b000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007fc987a12000)
/lib64/ld-linux-x86-64.so.2 (0x000055c158b6e000)
$ readelf -a /tmp/AAA/lib/python2.7/lib-dynload/_json.so | grep NEEDED
0x0000000000000001 (NEEDED) Shared library: [libpython2.7.so.1.0]
0x0000000000000001 (NEEDED) Shared library: [libpthread.so.0]
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
$ x86_64-linux-gnu-gcc -pthread -shared -Wl,-Bsymbolic-functions -Wl,-z,relro build/temp.linux-
x86_64-2.7/tmp/Python-2.7.13/Modules/_json.o -o /tmp/AAA/lib/python2.7/lib-dynload/_json.so
$ readelf -a /tmp/AAA/lib/python2.7/lib-dynload/_json.so | grep NEEDED
0x0000000000000001 (NEEDED) Shared library: [libpthread.so.0]
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
we don't need this
recompile _json.so
"-L/usr/lib/x86_64-linux-gnu -L/usr/local/lib -L. -lpython2.7" has been eliminated](https://image.slidesharecdn.com/gil3-170610030315/75/Global-Interpreter-Lock-Episode-III-cat-lt-dev-zero-GIL-34-2048.jpg)




































































