

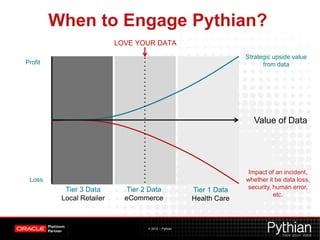





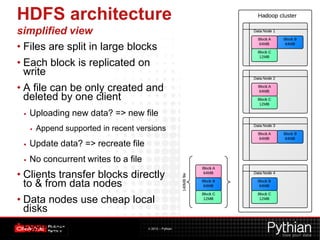

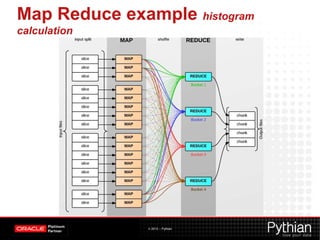

















This document provides an overview of Hadoop and its uses. It defines Hadoop as a distributed processing framework for large datasets across clusters of commodity hardware. It describes HDFS for distributed storage and MapReduce as a programming model for distributed computations. Several examples of Hadoop applications are given like log analysis, web indexing, and machine learning. In summary, Hadoop is a scalable platform for distributed storage and processing of big data across clusters of servers.
















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)






