Downloaded 261 times























![TLE parsing
BSTAR Drag
54-61 -11606-4
(Decimal Assumed)
def
parse_tle_number(tle_number_string):
split_string
=
tle_number_string.split('-‐')
if
len(split_string)
==
3:
new_number
=
'-‐'
+
str(split_string[1])
+
'e-‐'
+
str(int(split_string[2])+1)
elif
len(split_string)
==
2:
new_number
=
str(split_string[0])
+
'e-‐'
+
str(int(split_string[1])+1)
elif
len(split_string)
==
1:
new_number
=
'0.'
+
str(split_string[0])
else:
raise
TypeError('Input
is
not
in
the
TLE
float
format')
return
float(new_number)
Full parser at https://gist.github.com/shawnhermans/4569360
Tuesday, April 9, 13](https://image.slidesharecdn.com/2013-04-08odlugpigpresentation-130409181425-phpapp02/75/Pig-and-Python-to-Process-Big-Data-30-2048.jpg)
![Simple UDF
import tleparser
@outputSchema("params:map[]")
def parseTle(name, line1, line2):
params = tleparser.parse_tle(name, line1, line2)
return params
Tuesday, April 9, 13](https://image.slidesharecdn.com/2013-04-08odlugpigpresentation-130409181425-phpapp02/75/Pig-and-Python-to-Process-Big-Data-31-2048.jpg)
![Extract Parameters
grunt> gps = LOAD 'gps-ops.tsv' USING PigStorage()
AS (name:chararray, line1:chararray, line2:chararray);
grunt> REGISTER 'tleUDFs.py' USING jython AS myfuncs;
grunt> parsed = FOREACH gps GENERATE myfuncs.parseTle(*);
([bstar#,arg_of_perigee#333.0924,mean_motion#2.00559335,element_number#72,epoch_year#
2013,inclination#54.9673,mean_anomaly#26.8787,rev_at_epoch#210,mean_motion_ddot#0.0,e
ccentricity#5.354E-4,two_digit_year#13,international_designator#12053A,classification
#U,epoch_day#17.78040066,satellite_number#38833,name#GPS BIIF-3 (PRN
24),mean_motion_dot#-1.8E-6,ra_of_asc_node#344.5315])
Tuesday, April 9, 13](https://image.slidesharecdn.com/2013-04-08odlugpigpresentation-130409181425-phpapp02/75/Pig-and-Python-to-Process-Big-Data-32-2048.jpg)

![UDF with Java Import
from jsattrak.objects import SatelliteTleSGP4
@outputSchema("propagated:bag{positions:tuple(time:double, x:double, y:double, z:double)}")
def propagateTleECEF(name,line1,line2,start_time,end_time,number_of_points):
satellite = SatelliteTleSGP4(name, line1, line2)
ecef_positions = []
increment = (float(end_time)-float(start_time))/float(number_of_points)
current_time = start_time
while current_time <= end_time:
positions = [current_time]
positions.extend(list(satellite.calculateJ2KPositionFromUT(current_time)))
ecef_positions.append(tuple(positions))
current_time += increment
return ecef_positions
Tuesday, April 9, 13](https://image.slidesharecdn.com/2013-04-08odlugpigpresentation-130409181425-phpapp02/75/Pig-and-Python-to-Process-Big-Data-34-2048.jpg)
![Propagate Positions
grunt > REGISTER 'tleUDFs.py' USING jython AS myfuncs;
grunt> gps = LOAD 'gps-ops.tsv' USING PigStorage()
AS (name:chararray, line1:chararray, line2:chararray);
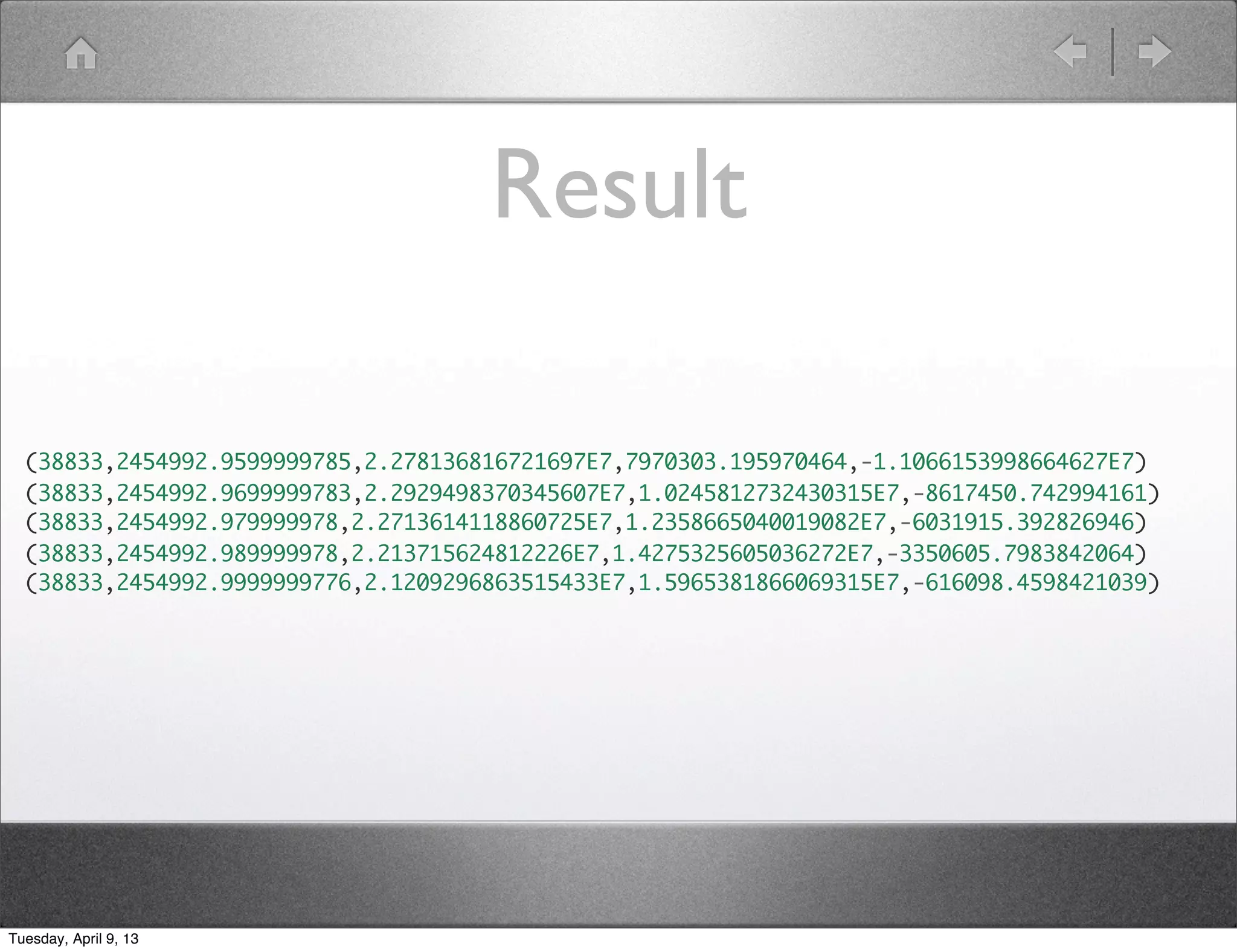
grunt> propagated = FOREACH gps GENERATE myfuncs.parseTle(name, line1, line2),
myfuncs.propagateTleECEF(name, line1, line2, 2454992.0, 2454993.0, 100);
grunt> flattened = FOREACH propagated
GENERATE params#'satellite_number', FLATTEN(propagated);
propagated: {params: map[],propagated: {positions:
(time: double,x: double,y: double,z: double)}}
grunt> DESCRIBE flattened;
flattened: {bytearray,propagated::time: double,propagated::x: double,
propagated::y: double,propagated::z: double}
Tuesday, April 9, 13](https://image.slidesharecdn.com/2013-04-08odlugpigpresentation-130409181425-phpapp02/75/Pig-and-Python-to-Process-Big-Data-35-2048.jpg)


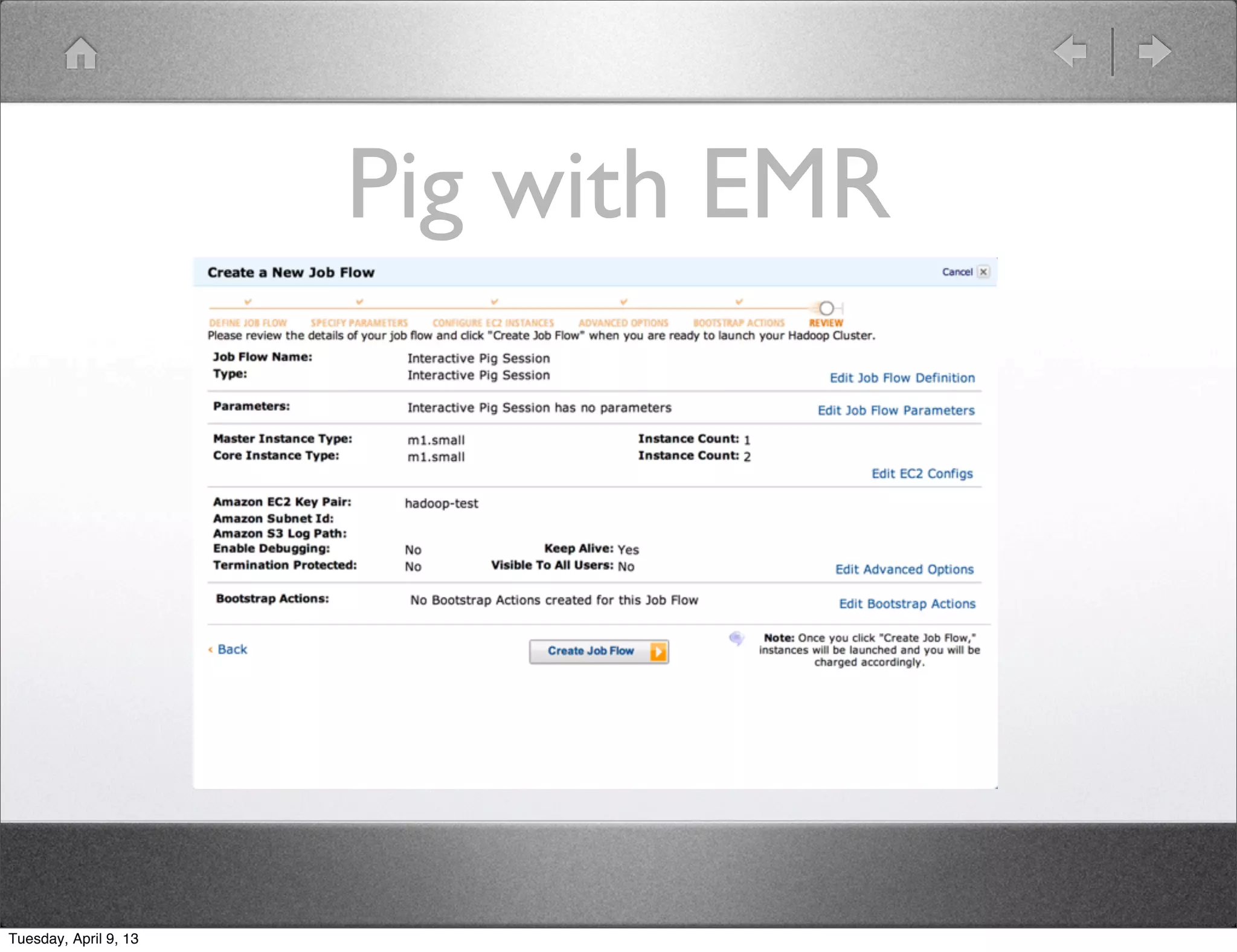




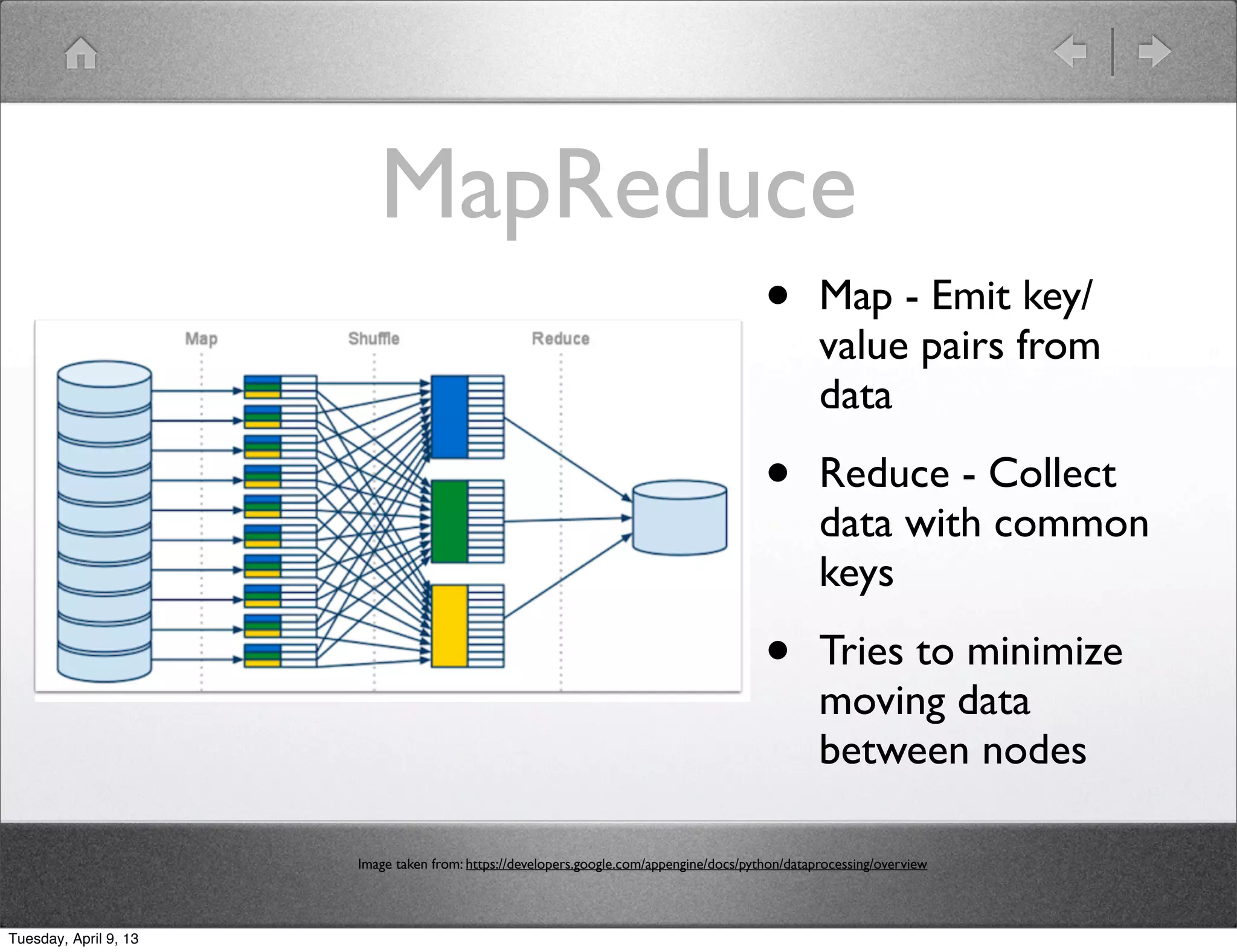
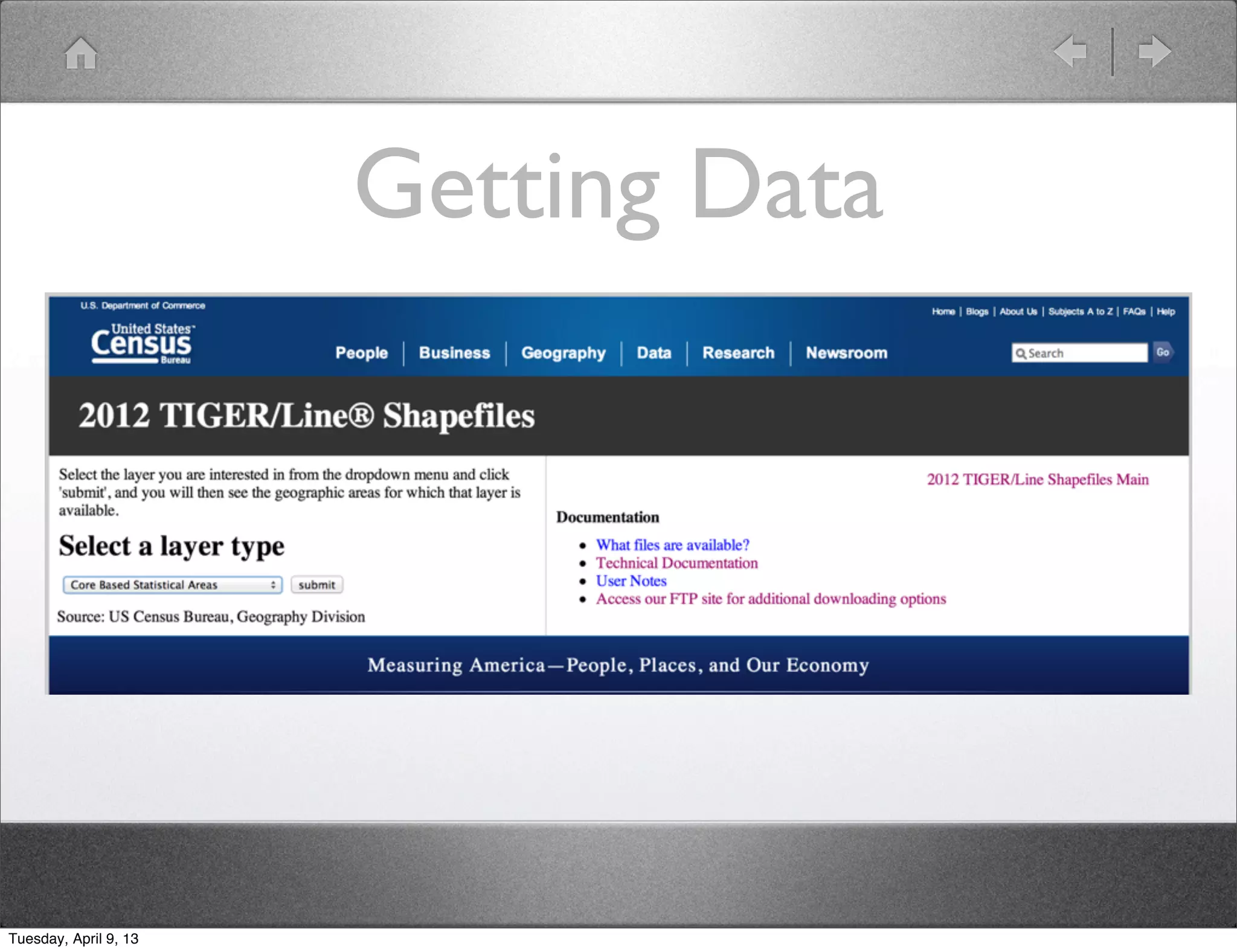
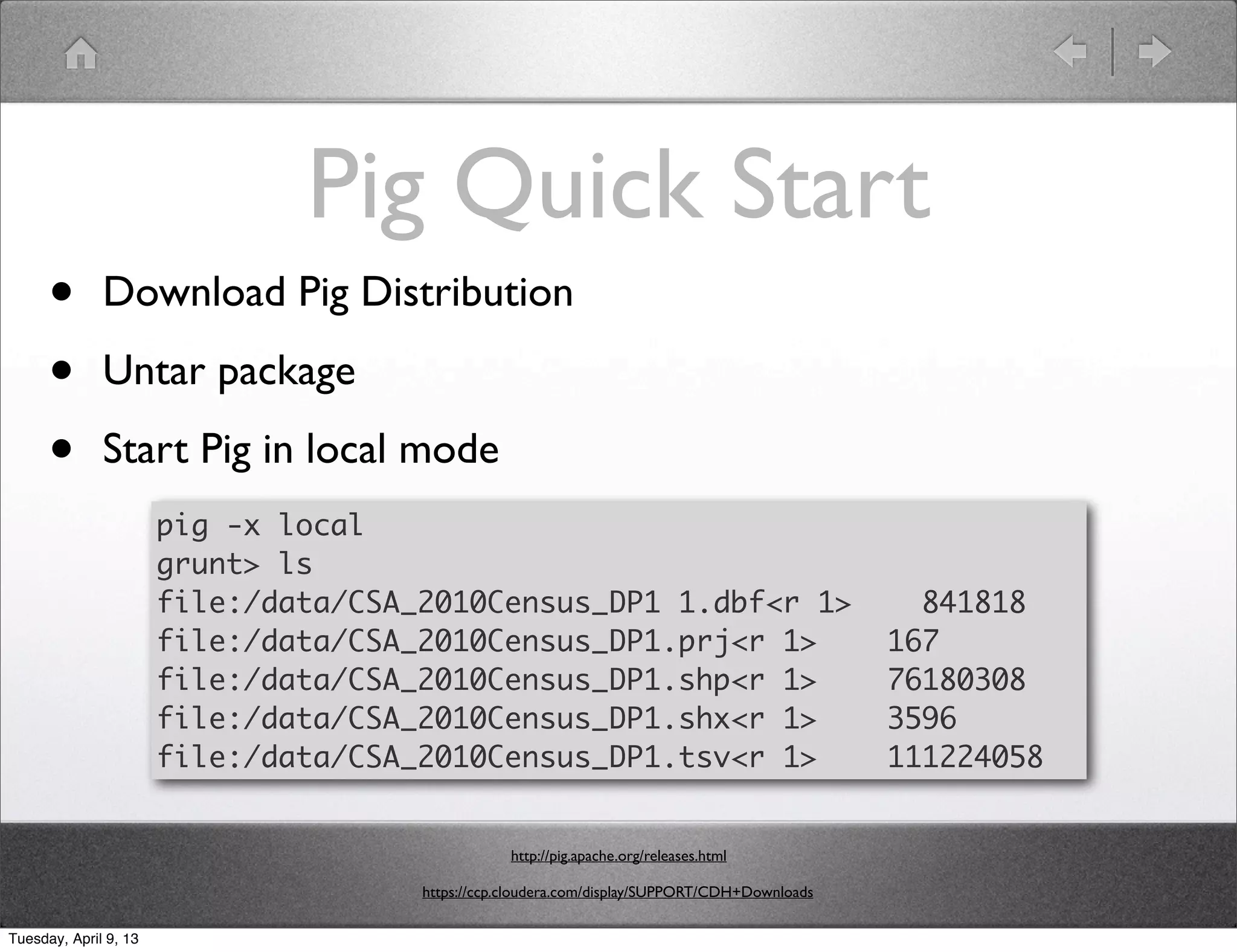
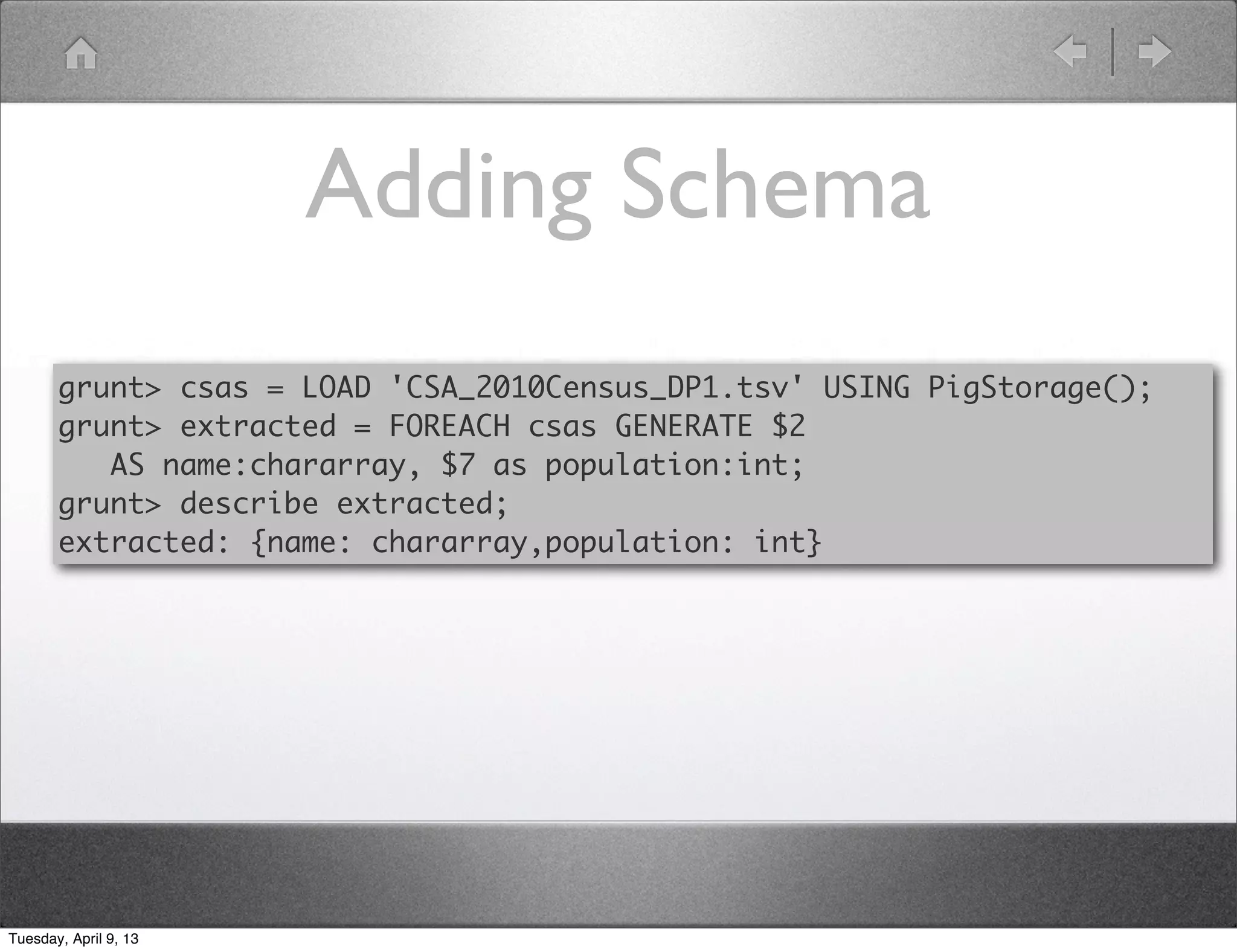
Shawn Hermans gave a presentation on using Pig and Python for big data analysis. He began with an introduction and background about himself. The presentation covered what big data is, challenges in working with large datasets, and how tools like MapReduce, Pig and Python can help address these challenges. As examples, he demonstrated using Pig to analyze US Census data and propagate satellite positions from Two Line Element sets. He also showed how to extend Pig with Python user defined functions.






















































































