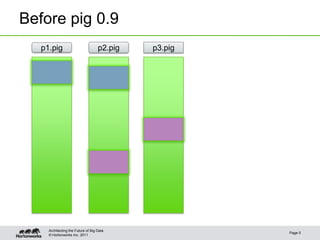
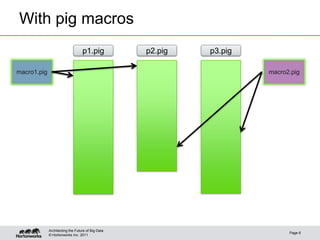
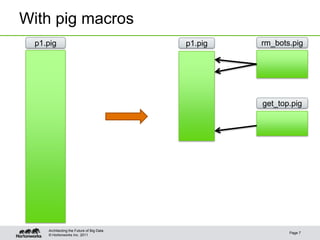
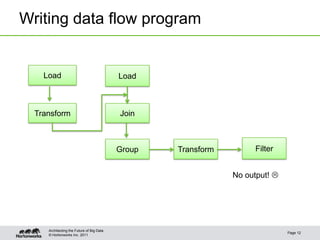
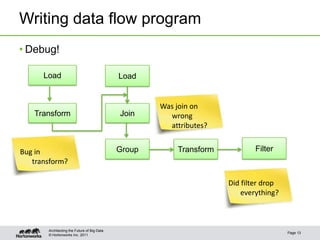
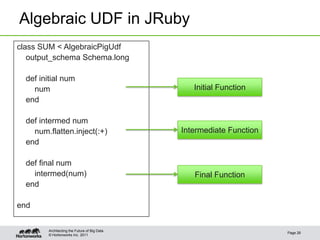
The document provides an overview of Apache Pig, focusing on its functionality, features, and advantages in big data processing. It describes the use of Pig Latin for data querying, macro examples for optimizing scripts, and integration with various scripting languages for enhanced flexibility. Additionally, it covers debugging methods, nested operators, and the integration of HCatalog with Pig for streamlined data management.
















![Use NLTK in Pig
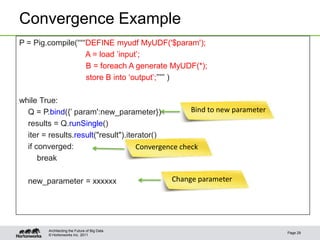
• Example
register ‟nltk_util.py' using jython as nltk; Pig eats everything
……
B = foreach A generate nltk.tokenize(sentence)
Tokenize
nltk_util.py
Stemming
import nltk
porter = nltk.PorterStemmer() (Pig)
@outputSchema("words:{(word:chararray)}") (eat)
def tokenize(sentence): (everything)
tokens = nltk.word_tokenize(sentence)
words = [porter.stem(t) for t in tokens]
return words
Architecting the Future of Big Data
Page 22
© Hortonworks Inc. 2011](https://image.slidesharecdn.com/thu1125amhortonworksdai-120618200125-phpapp02/85/Pig-programming-is-more-fun-New-features-in-Pig-22-320.jpg)

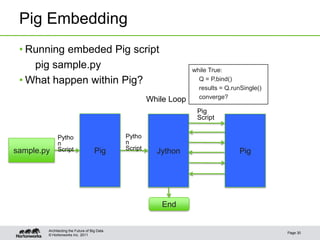
![Writing a Script Engine
Writing a bridge UDF
class JythonFunction extends EvalFunc<Object> { Convert Pig input
into Python
public Object exec(Tuple tuple) {
PyObject[] params = JythonUtils.pigTupleToPyTuple(tuple).getArray();
PyObject result = f.__call__(params); Invoke Python UDF
return JythonUtils.pythonToPig(result);
} Convert result to Pig
public Schema outputSchema(Schema input) {
PyObject outputSchemaDef = f.__findattr__("outputSchema".intern());
return Utils.getSchemaFromString(outputSchemaDef.toString());
}
}
Architecting the Future of Big Data
Page 24
© Hortonworks Inc. 2011](https://image.slidesharecdn.com/thu1125amhortonworksdai-120618200125-phpapp02/85/Pig-programming-is-more-fun-New-features-in-Pig-24-320.jpg)
























![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)























































