















![Use NLTK in Pig
• Example
register ’nltk_util.py' using jython as nltk;
……
B = foreach A generate nltk.tokenize(sentence)
nltk_util.py
import nltk
porter = nltk.PorterStemmer()
@outputSchema("words:{(word:chararray)}")
def tokenize(sentence):
tokens = nltk.word_tokenize(sentence)
words = [porter.stem(t) for t in tokens]
return words
Architecting the Future of Big Data
Page 22
© Hortonworks Inc. 2011](https://image.slidesharecdn.com/pigprogrammingisfun-120620113526-phpapp01/85/Pig-programming-is-fun-22-320.jpg)
![Writing a Script Engine
Writing a bridge UDF
class JythonFunction extends EvalFunc<Object> {
public Object exec(Tuple tuple) {
PyObject[] params = JythonUtils.pigTupleToPyTuple(tuple).getArray();
PyObject result = function.__call__(params);
return JythonUtils.pythonToPig(result);
}
public Schema outputSchema(Schema input) {
PyObject outputSchemaDef = f.__findattr__("outputSchema".intern());
return Utils.getSchemaFromString(outputSchemaDef.toString());
}
}
Architecting the Future of Big Data
Page 23
© Hortonworks Inc. 2011](https://image.slidesharecdn.com/pigprogrammingisfun-120620113526-phpapp01/85/Pig-programming-is-fun-23-320.jpg)




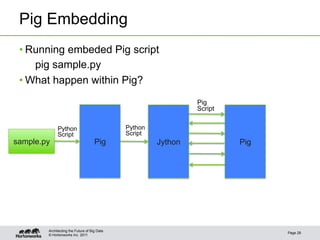





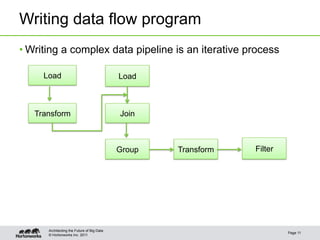
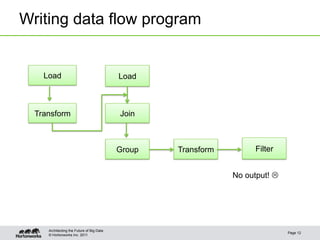
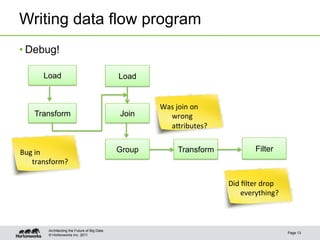
The document discusses new features in Pig including macros, debugging tools, UDF support for scripting languages, embedding Pig in other languages, and new operators like nested CROSS and FOREACH. Examples are provided for macros, debugging with Pig Illustrate, writing UDFs in Python and Ruby, running Pig from Python, and using nested operators. Future additions mentioned are RANK and CUBE operators.































































































