Download as PDF, PPTX











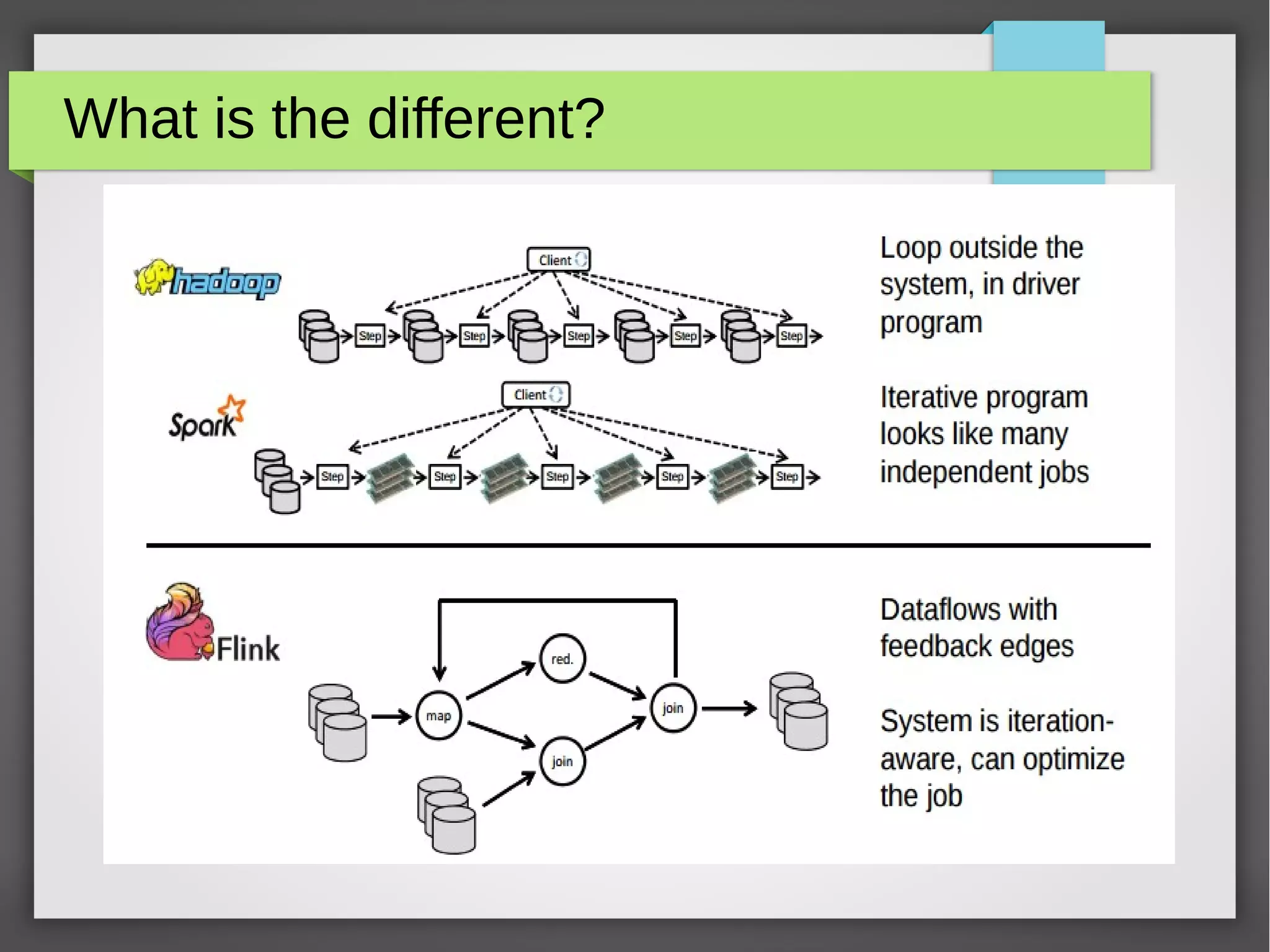



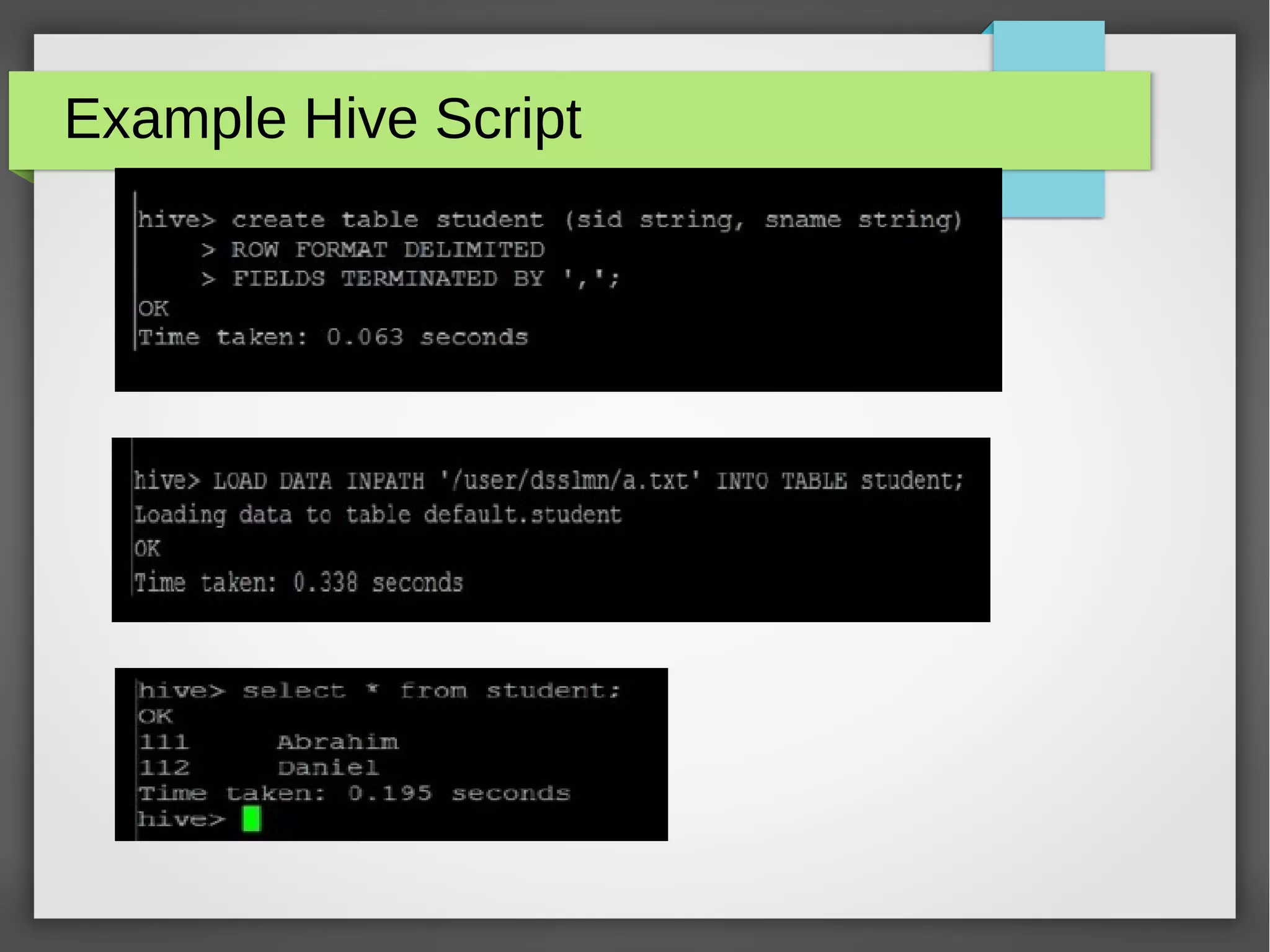

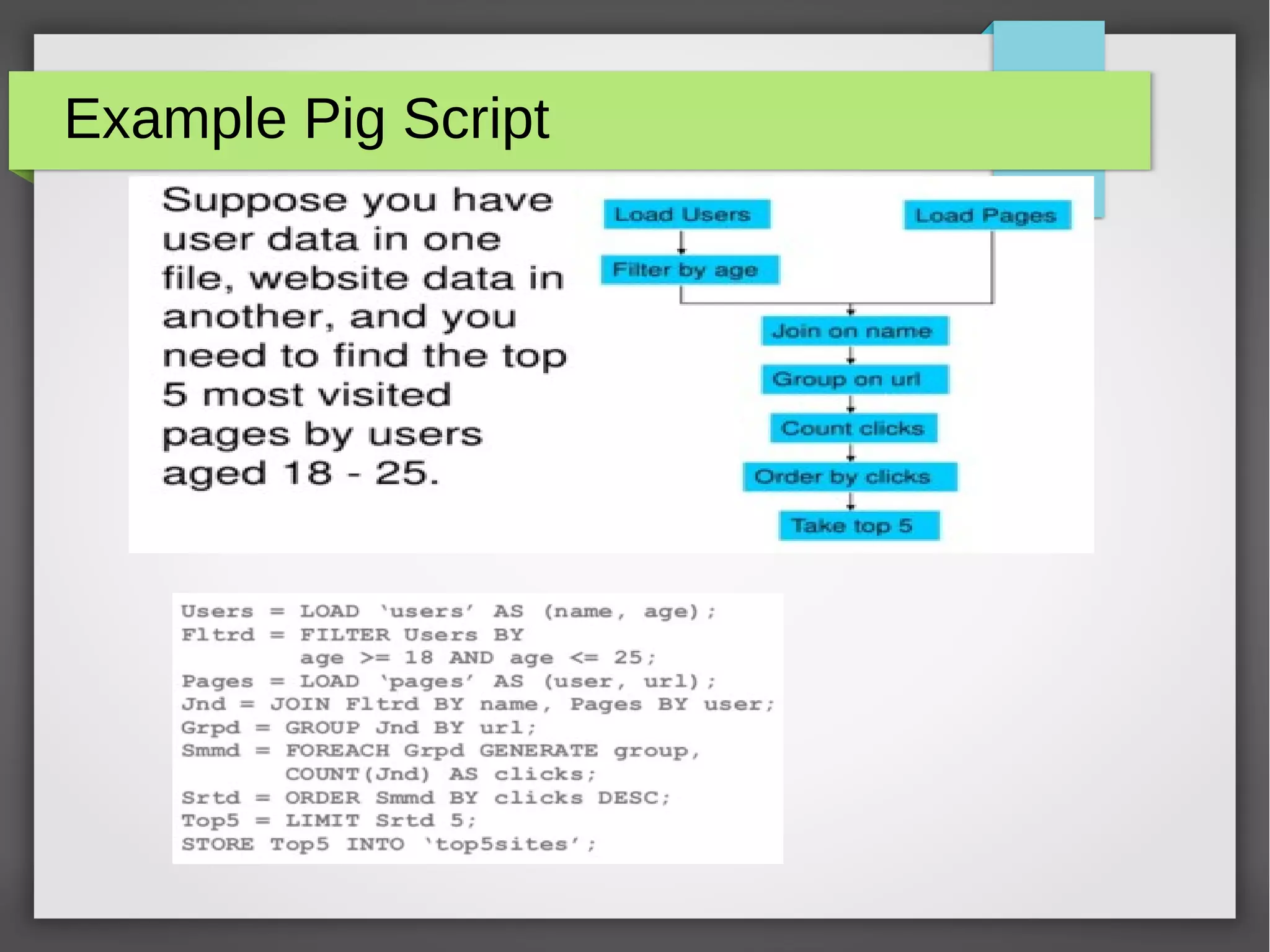


![Spark Example
// Spark wordcount
object WordCount {
def main(args: Array[String]) {
val env = new SparkContext("local","wordCount")
val data = List("hi","how are you","hi")
val dataSet = env.parallelize(data)
val words = dataSet.flatMap(value => value.split("s+"))
val mappedWords = words.map(value => (value,1))
val sum = mappedWords.reduceByKey(_+_)
println(sum.collect())
}
}](https://image.slidesharecdn.com/jonysugianto-bigdata-160518152007/75/What-is-Big-Data-29-2048.jpg)

![Flink Example
// Flink wordcount
object WordCount {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
val data = List("hi","how are you","hi")
val dataSet = env.fromCollection(data)
val words = dataSet.flatMap(value => value.split("s+"))
val mappedWords = words.map(value => (value,1))
val grouped = mappedWords.groupBy(0)
val sum = grouped.sum(1)
println(sum.collect())
}
}](https://image.slidesharecdn.com/jonysugianto-bigdata-160518152007/75/What-is-Big-Data-31-2048.jpg)

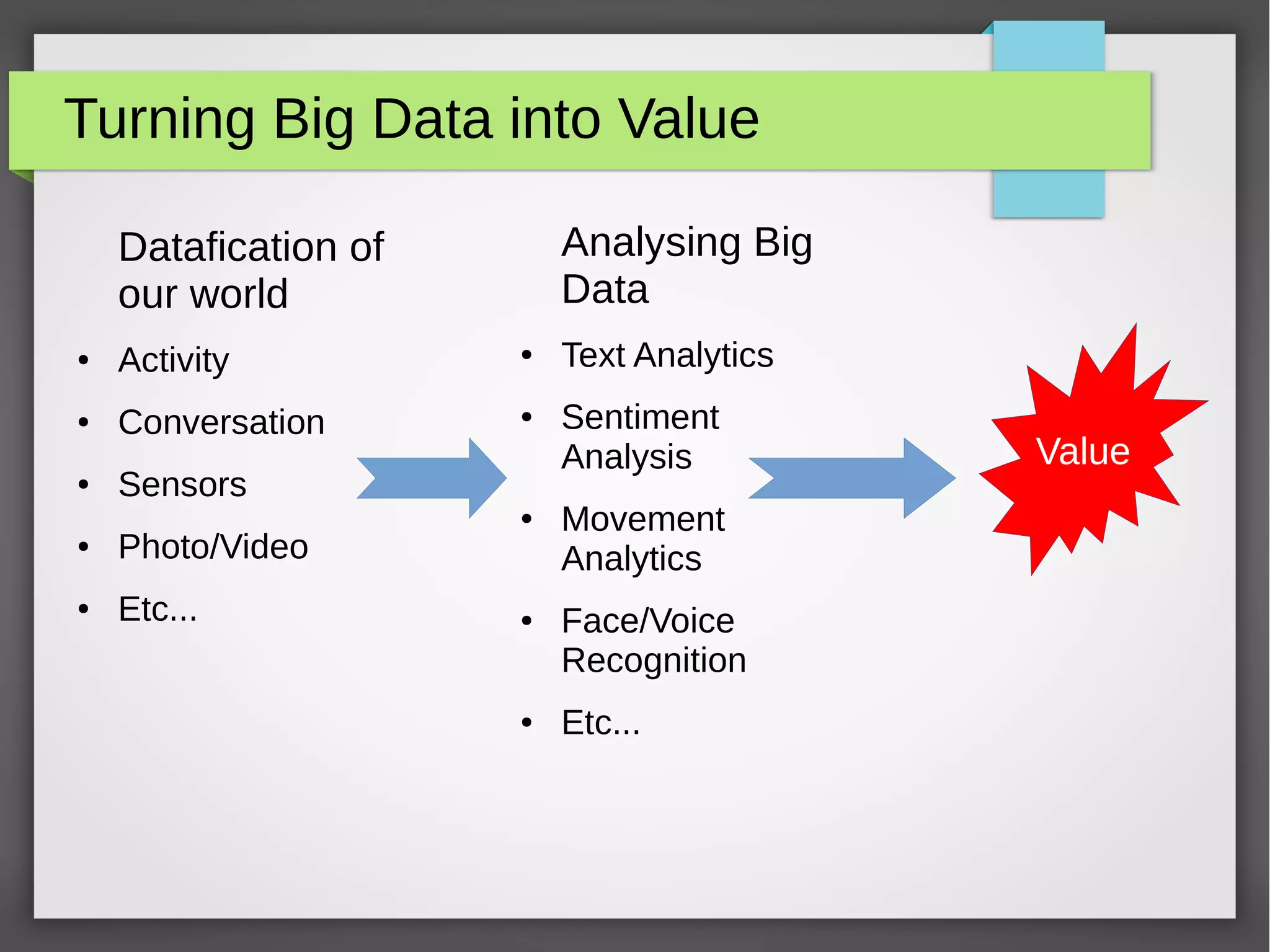
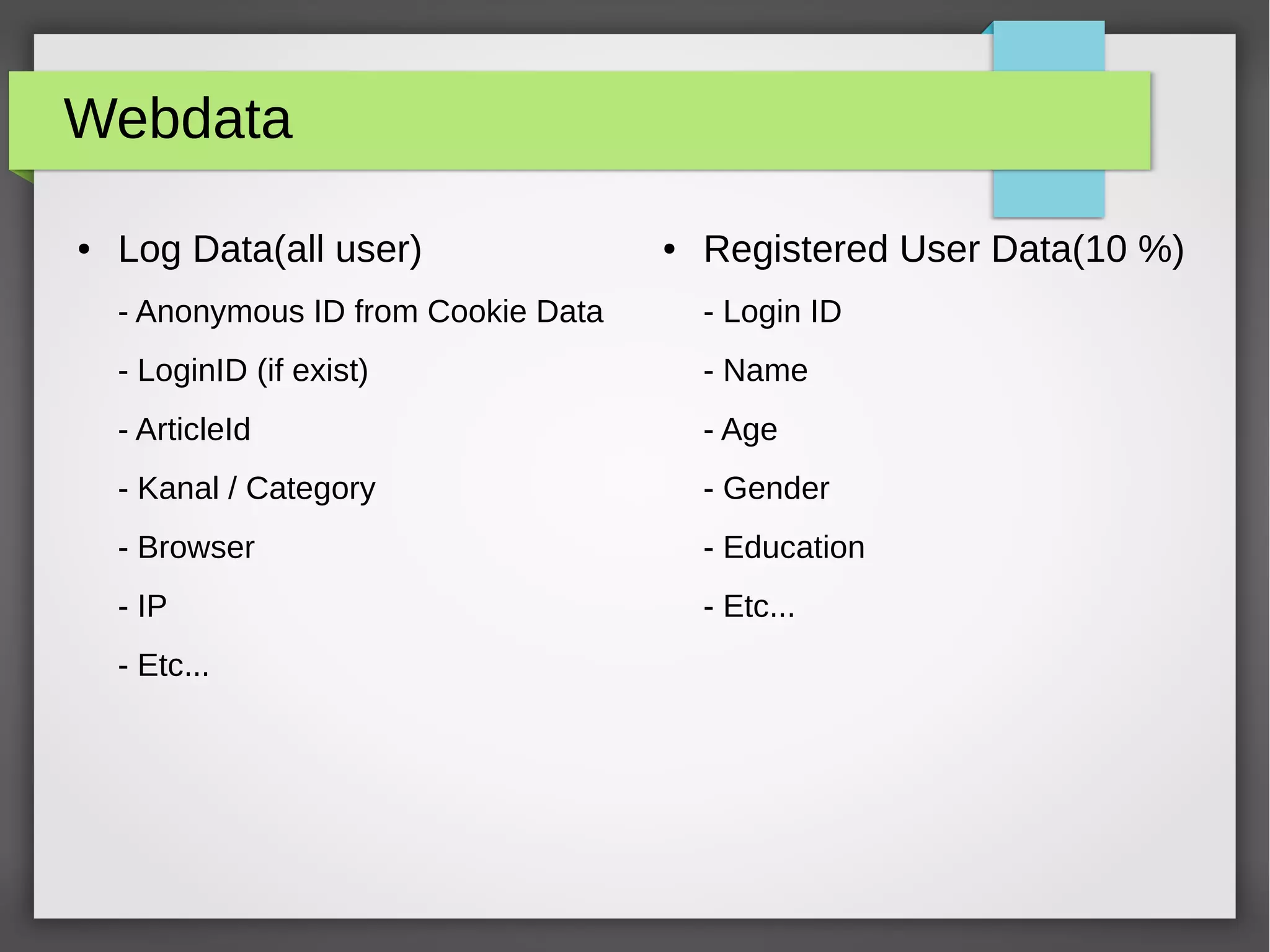
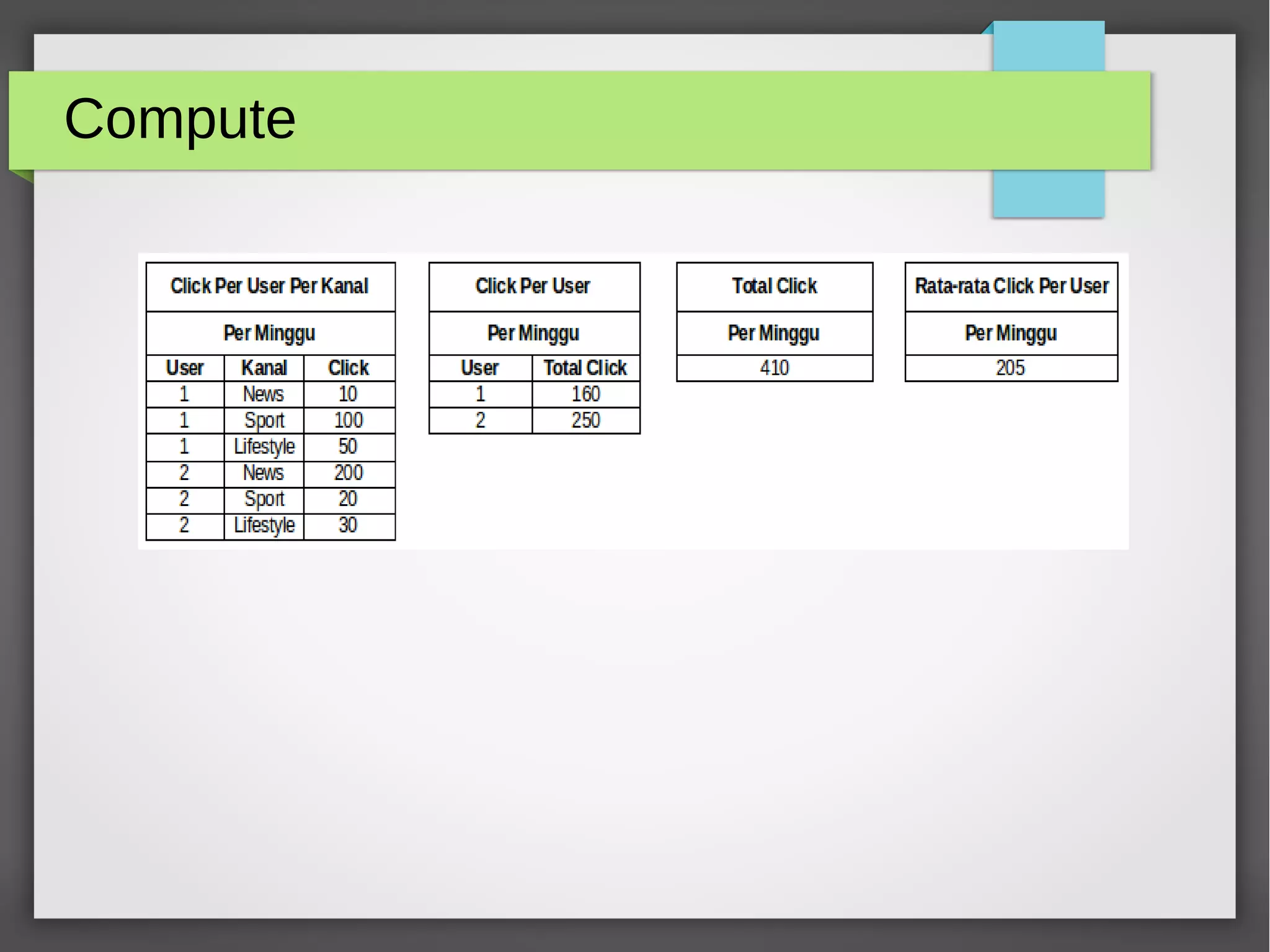
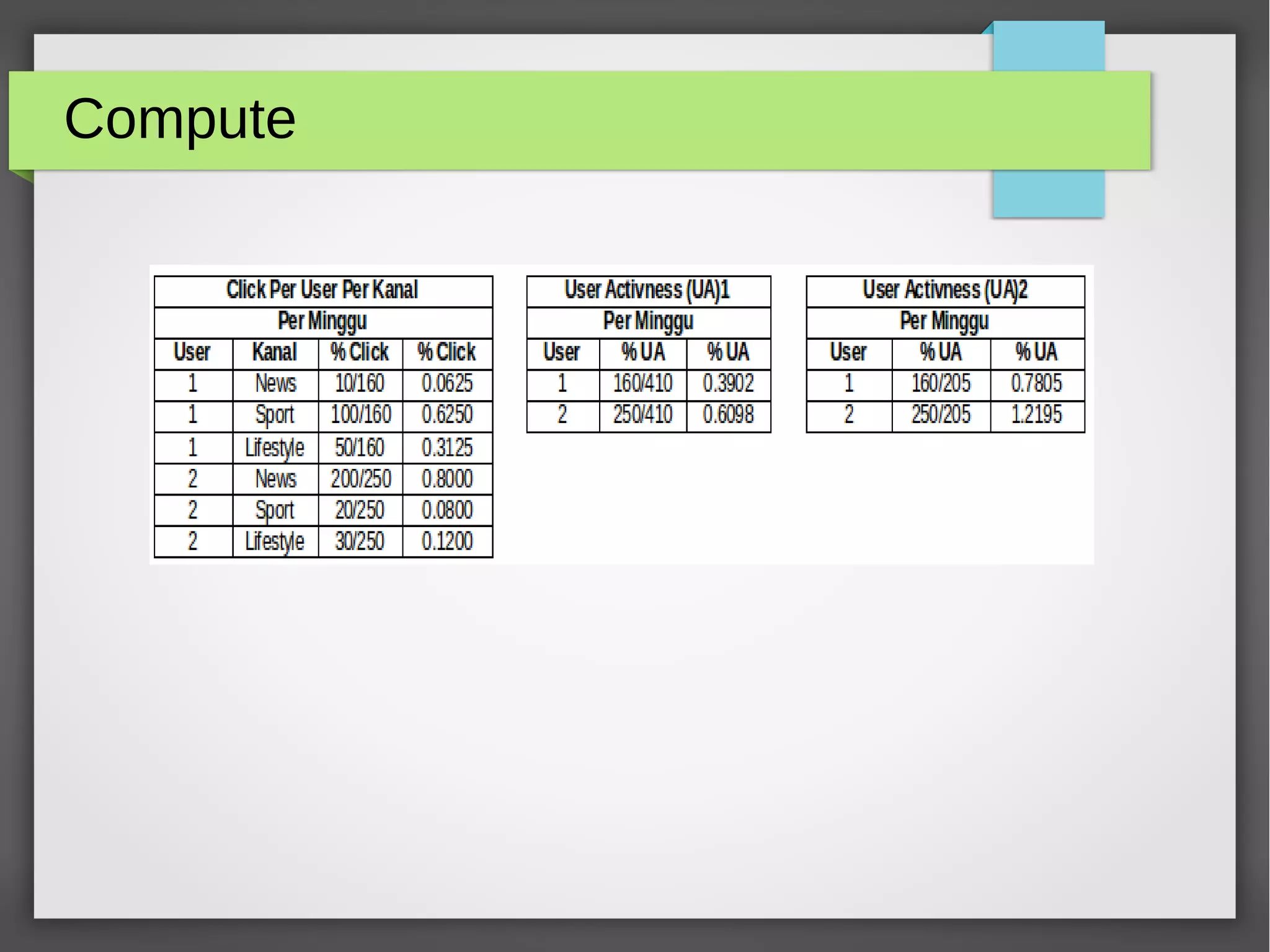
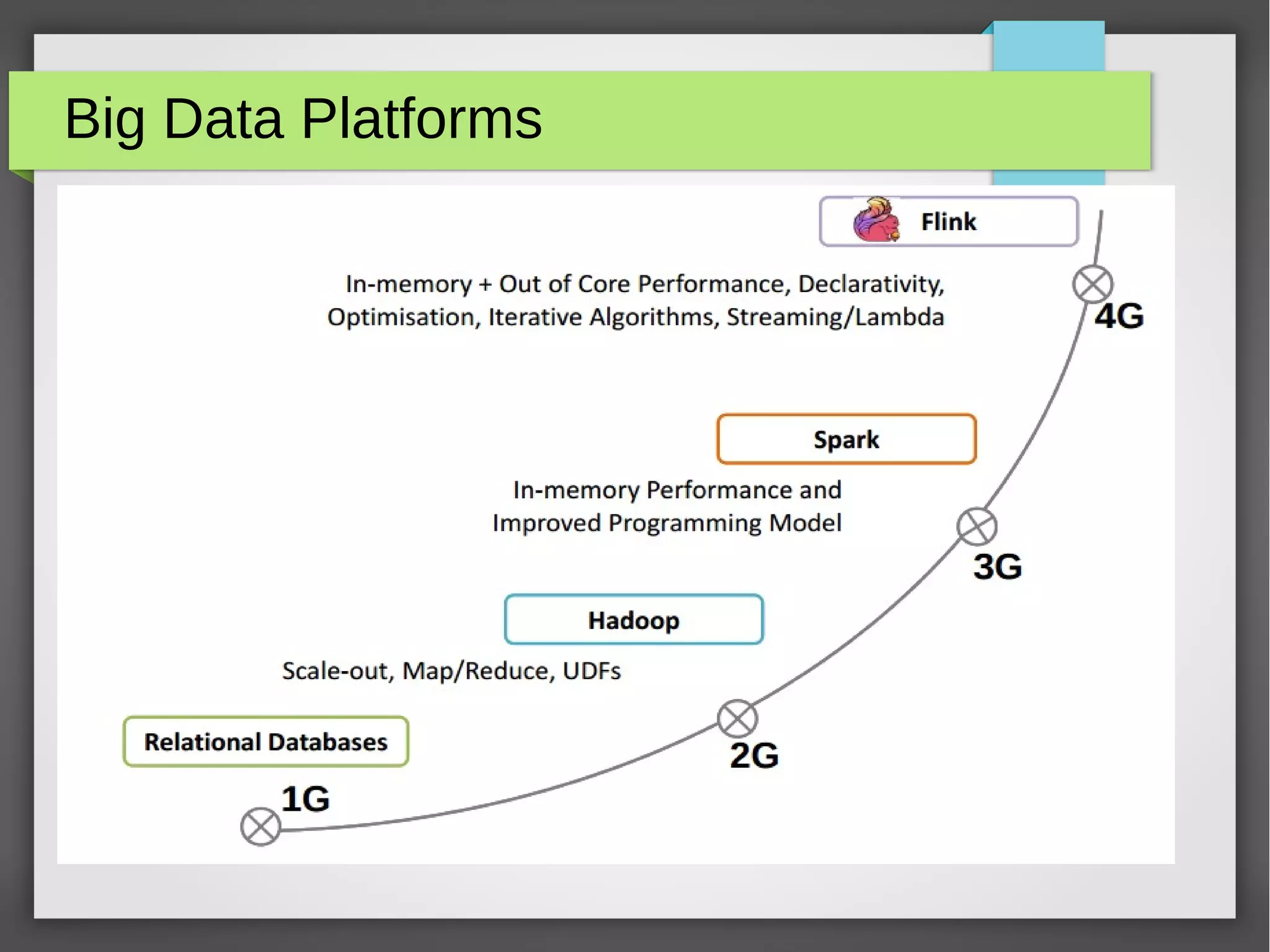
The document provides an overview of big data, its significance, and various platforms used for analyzing it, such as Hadoop, Hive, Pig, Spark, and Flink. It discusses the concept of datafication, the techniques for analyzing big data, and the importance of extracting value from vast amounts of data. Additionally, it emphasizes technical components and examples of big data processing using these platforms.













































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)




