Downloaded 242 times







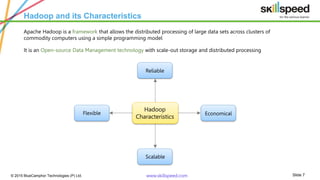
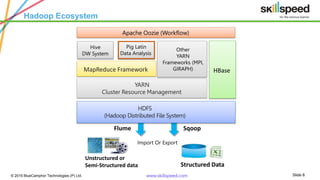




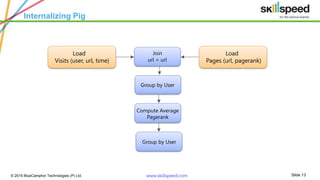

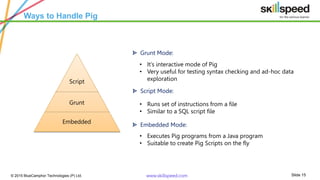

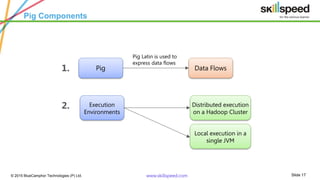
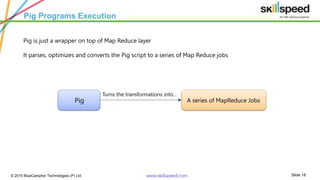
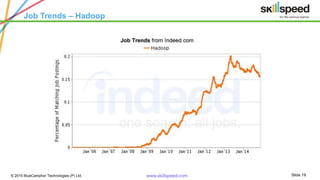
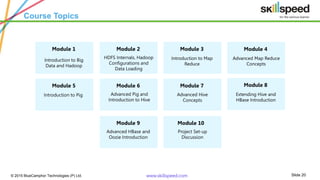



The document provides an overview of big data analytics using Apache Pig, emphasizing challenges in managing large data sets and the capabilities of Hadoop as a processing framework. It introduces Pig as an open-source data flow language suitable for data analysts, detailing its features, modes of operation, and components. Additionally, it outlines a course syllabus for learning Big Data and Hadoop, and mentions the benefits of working with Pig in analyzing and processing data.
































































































