Downloaded 160 times




![H2O Deep Learning, @ArnoCandel 7
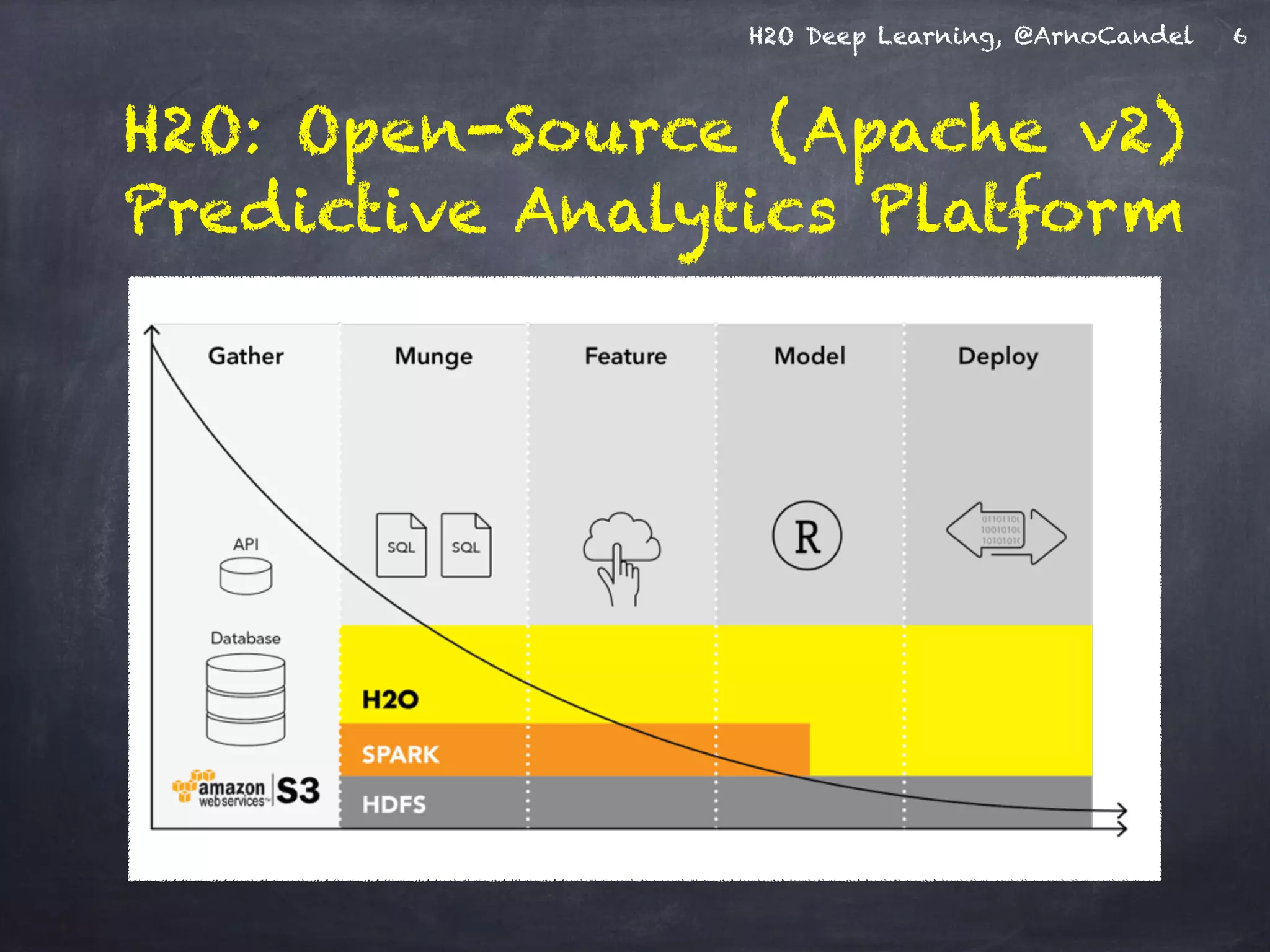
H2O Architecture - Designed for speed,
scale, accuracy & ease of use
Key technical points:
• distributed JVMs + REST API
• no Java GC issues
(data in byte[], Double)
• loss-less number compression
• Hadoop integration (v1,YARN)
• R package (CRAN)
Pre-built fully featured algos:
K-Means, NB, PCA, CoxPH,
GLM, RF, GBM, DeepLearning](https://image.slidesharecdn.com/lo6y60hsdah8awyl4cc1-signature-4ca2b82e8767405e80dd899badc072c10a988208a853085706a7f5032621ccfc-poli-150212232753-conversion-gate01/75/H2ODeepLearningThroughExamples021215-7-2048.jpg)





![H2O Deep Learning, @ArnoCandel
Detail: Adaptive Learning Rate
Compute moving average of ∆wi
2 at time t for window length rho:
E[∆wi
2]t = rho * E[∆wi
2]t-1 + (1-rho) * ∆wi
2
Compute RMS of ∆wi at time t with smoothing epsilon:
RMS[∆wi]t = sqrt( E[∆wi
2]t + epsilon )
Adaptive annealing / progress:
Gradient-dependent learning rate,
moving window prevents “freezing”
(unlike ADAGRAD: no window)
Adaptive acceleration / momentum:
accumulate previous weight updates,
but over a window of time
RMS[∆wi]t-1
RMS[∂E/∂wi]t
rate(wi, t) =
Do the same for ∂E/∂wi, then
obtain per-weight learning rate:
cf. ADADELTA paper
18](https://image.slidesharecdn.com/lo6y60hsdah8awyl4cc1-signature-4ca2b82e8767405e80dd899badc072c10a988208a853085706a7f5032621ccfc-poli-150212232753-conversion-gate01/75/H2ODeepLearningThroughExamples021215-18-2048.jpg)



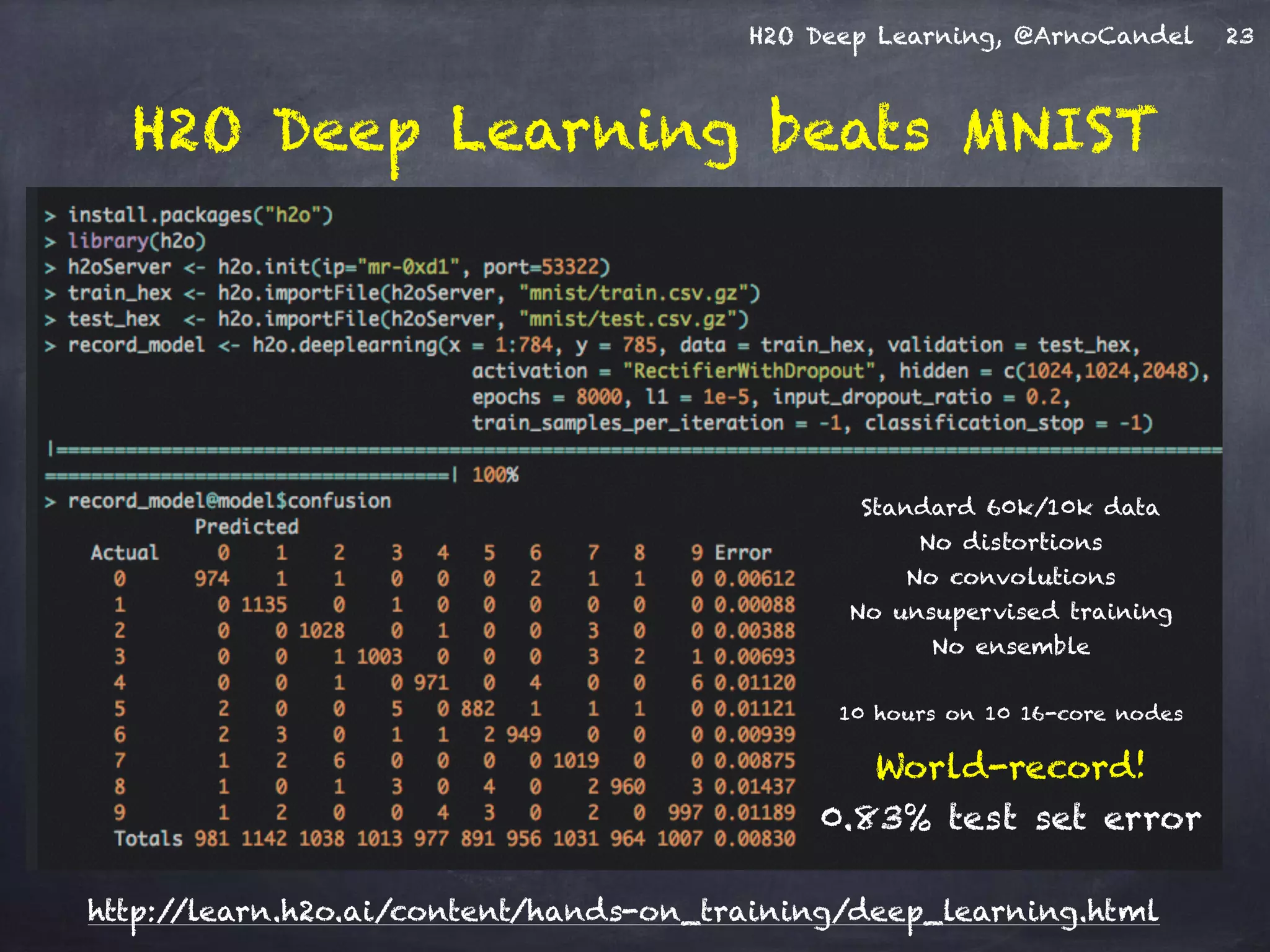

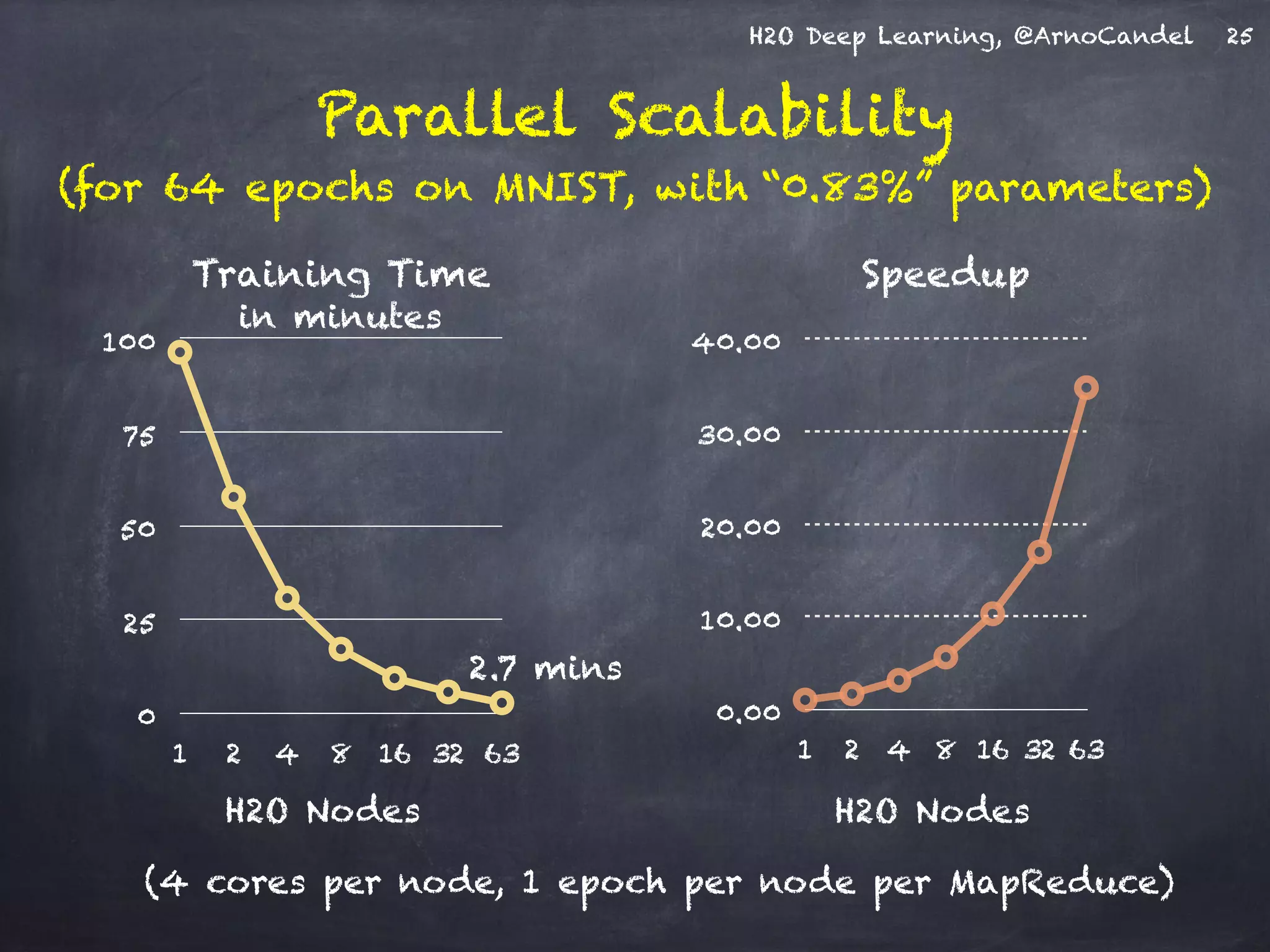
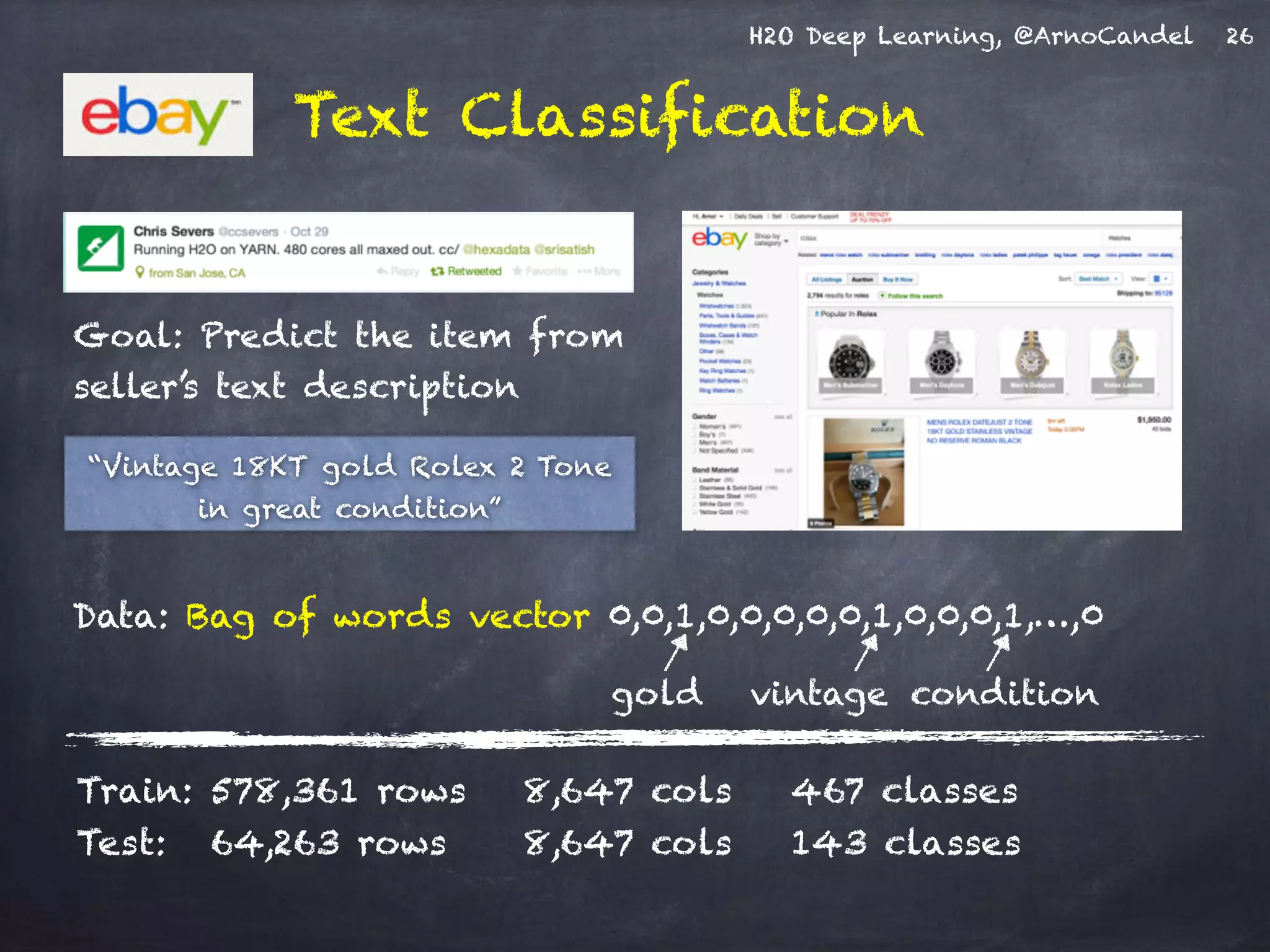
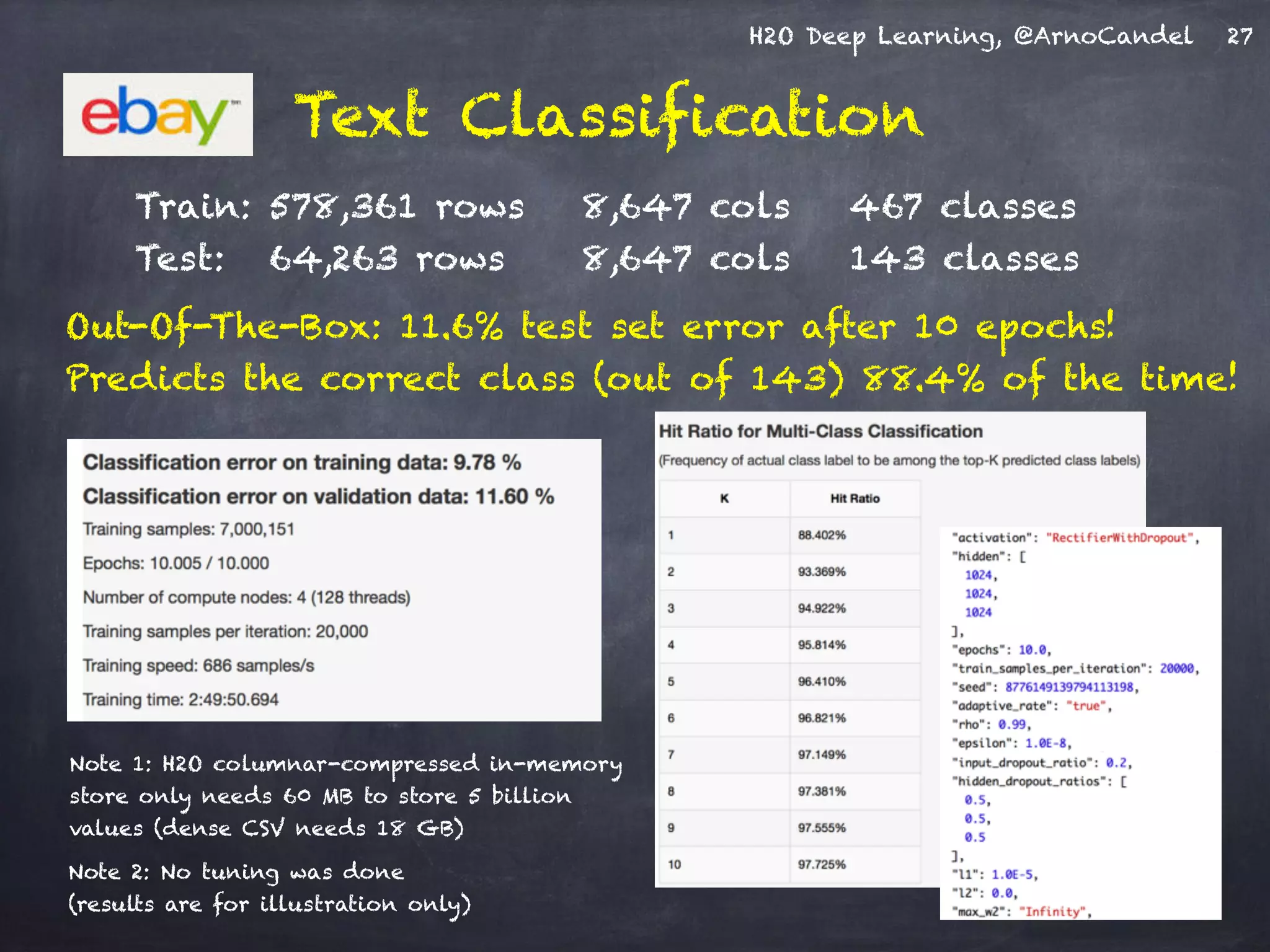


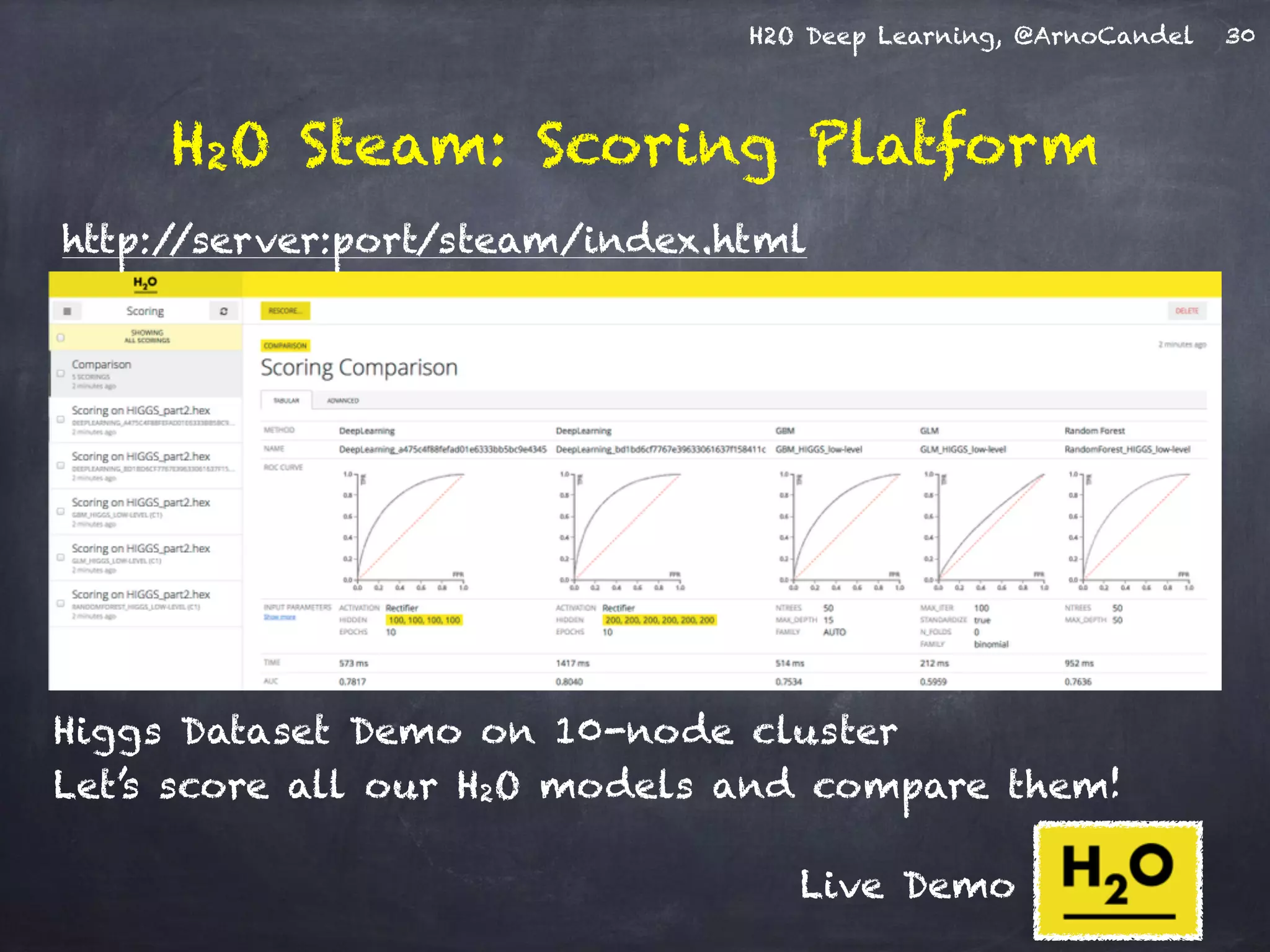
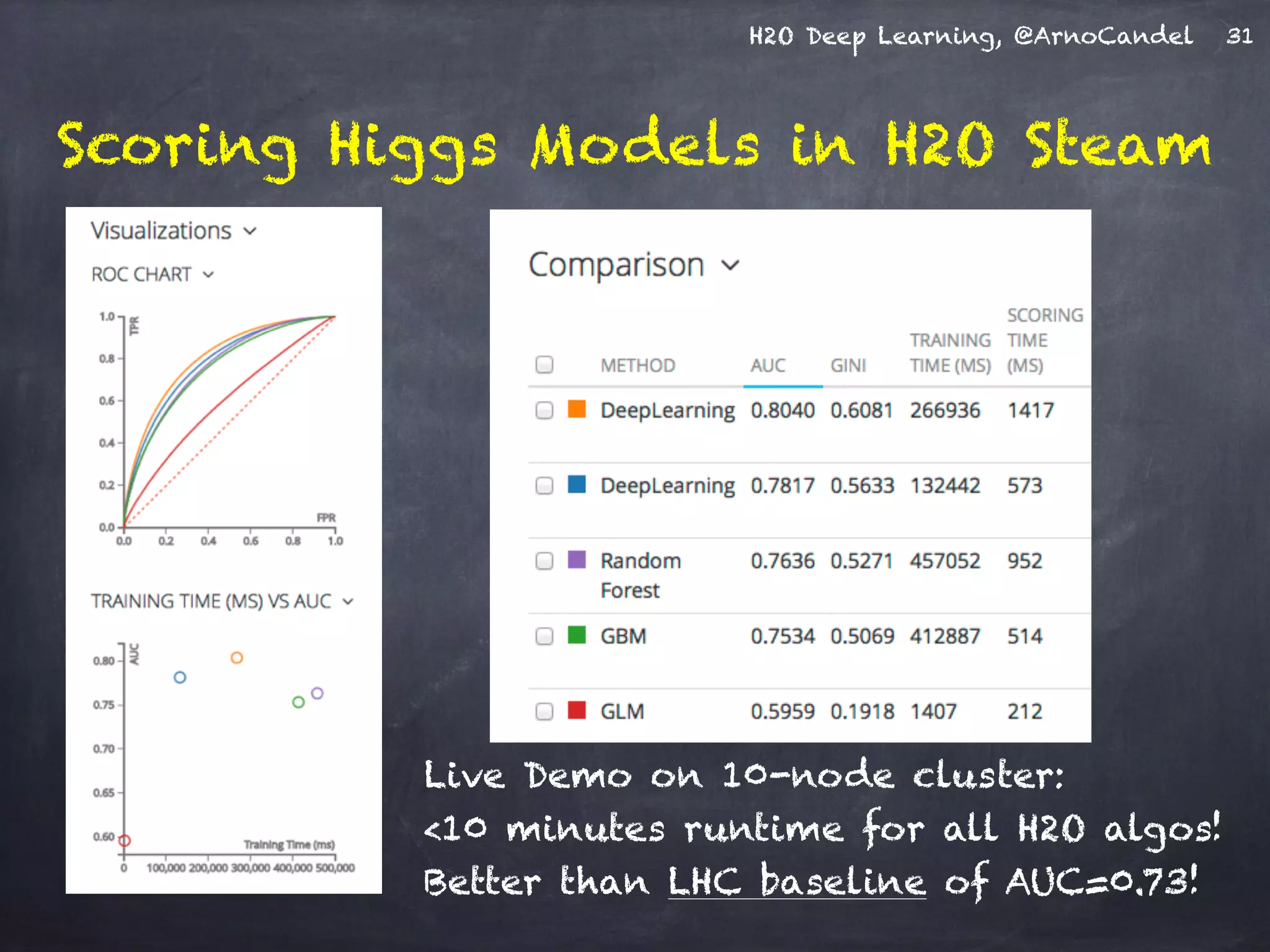
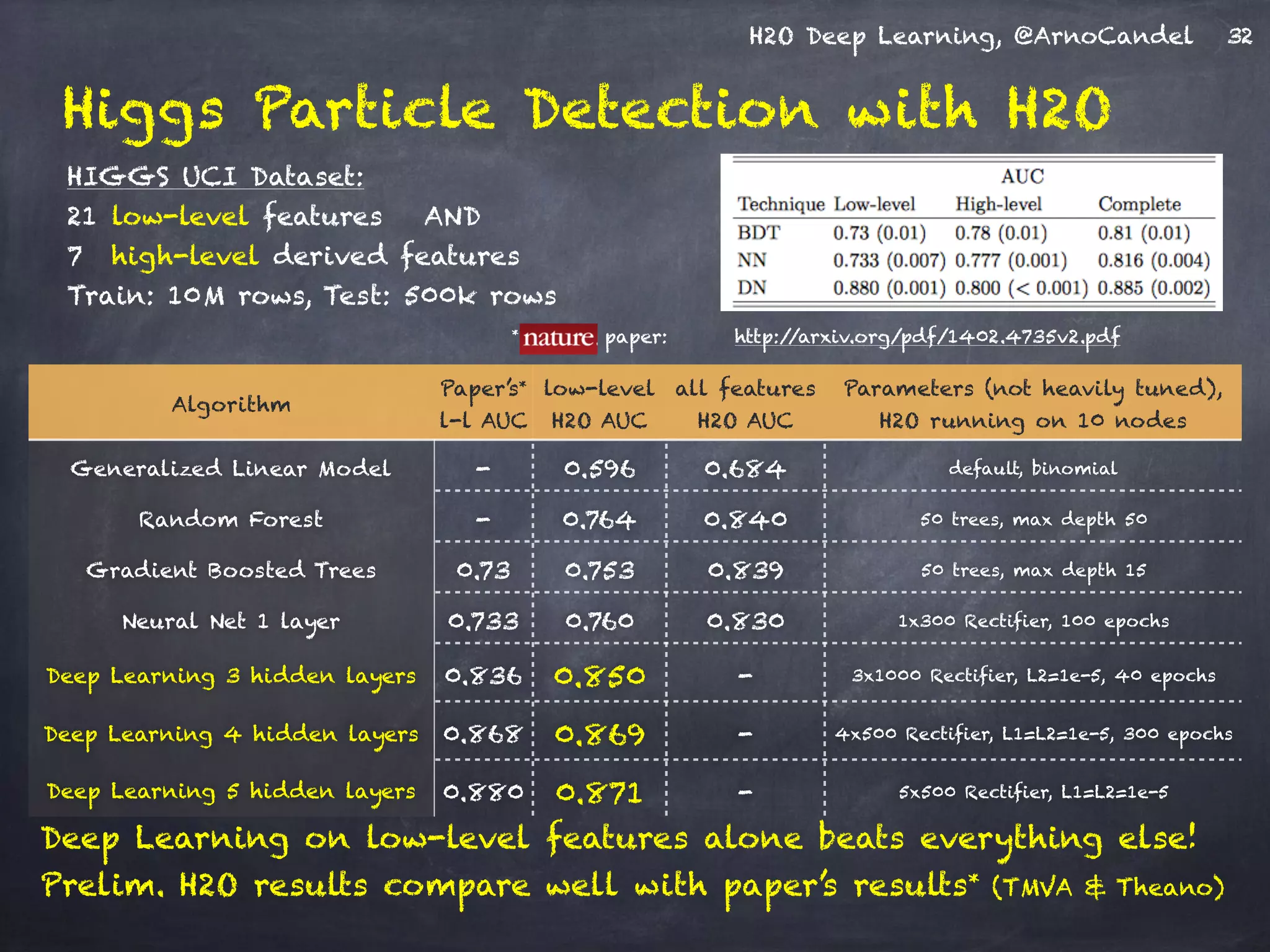
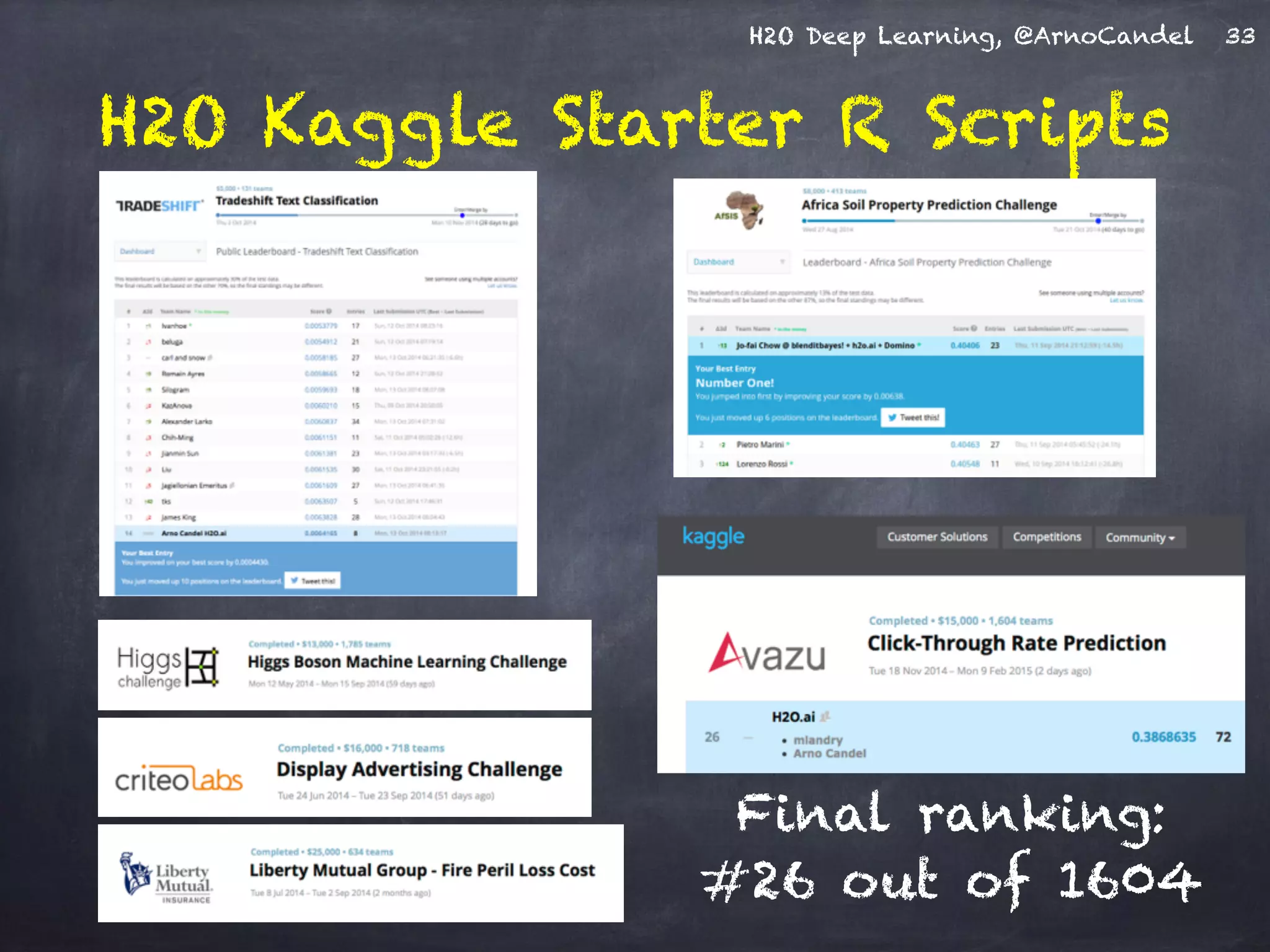





- The document describes a presentation on deep learning given by Arno Candel of H2O.ai. - The presentation covered deep learning methods and implementations, results from case studies in Higgs boson classification, handwritten digit recognition, and text classification. - It also demonstrated H2O's scalability and the ability of its deep learning algorithm to achieve state-of-the-art results on benchmark datasets.























































































