Download as PDF, PPTX




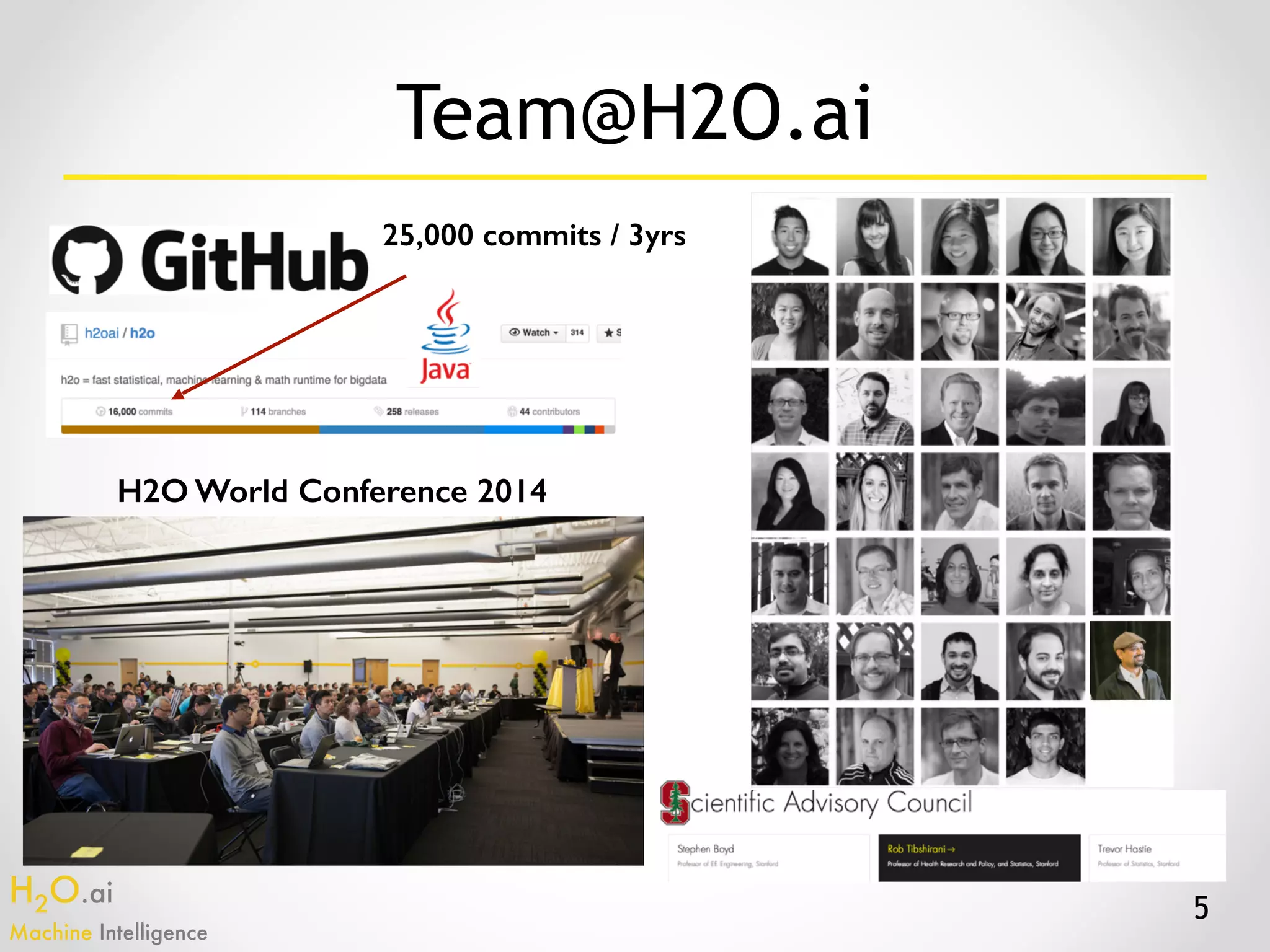

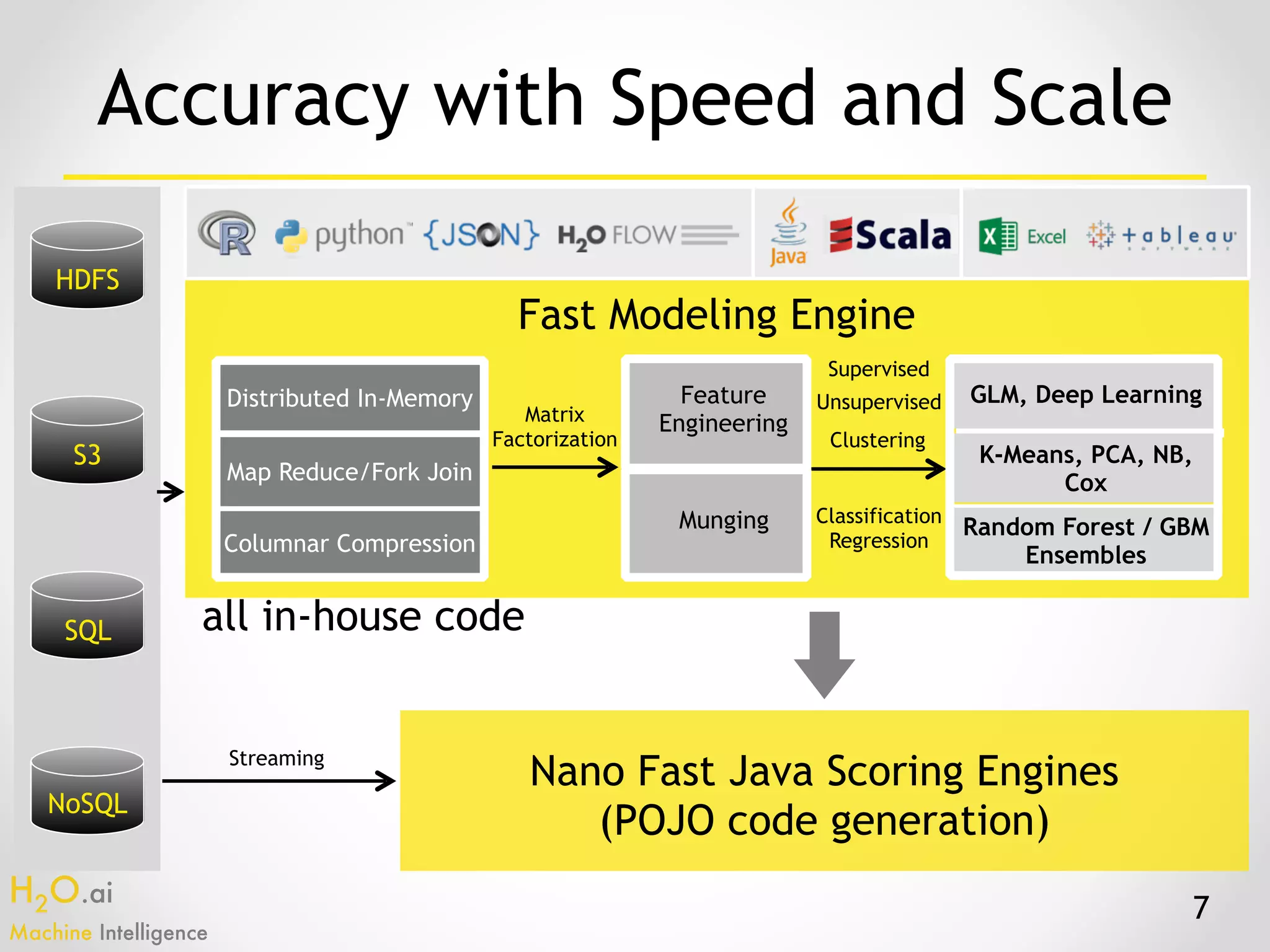

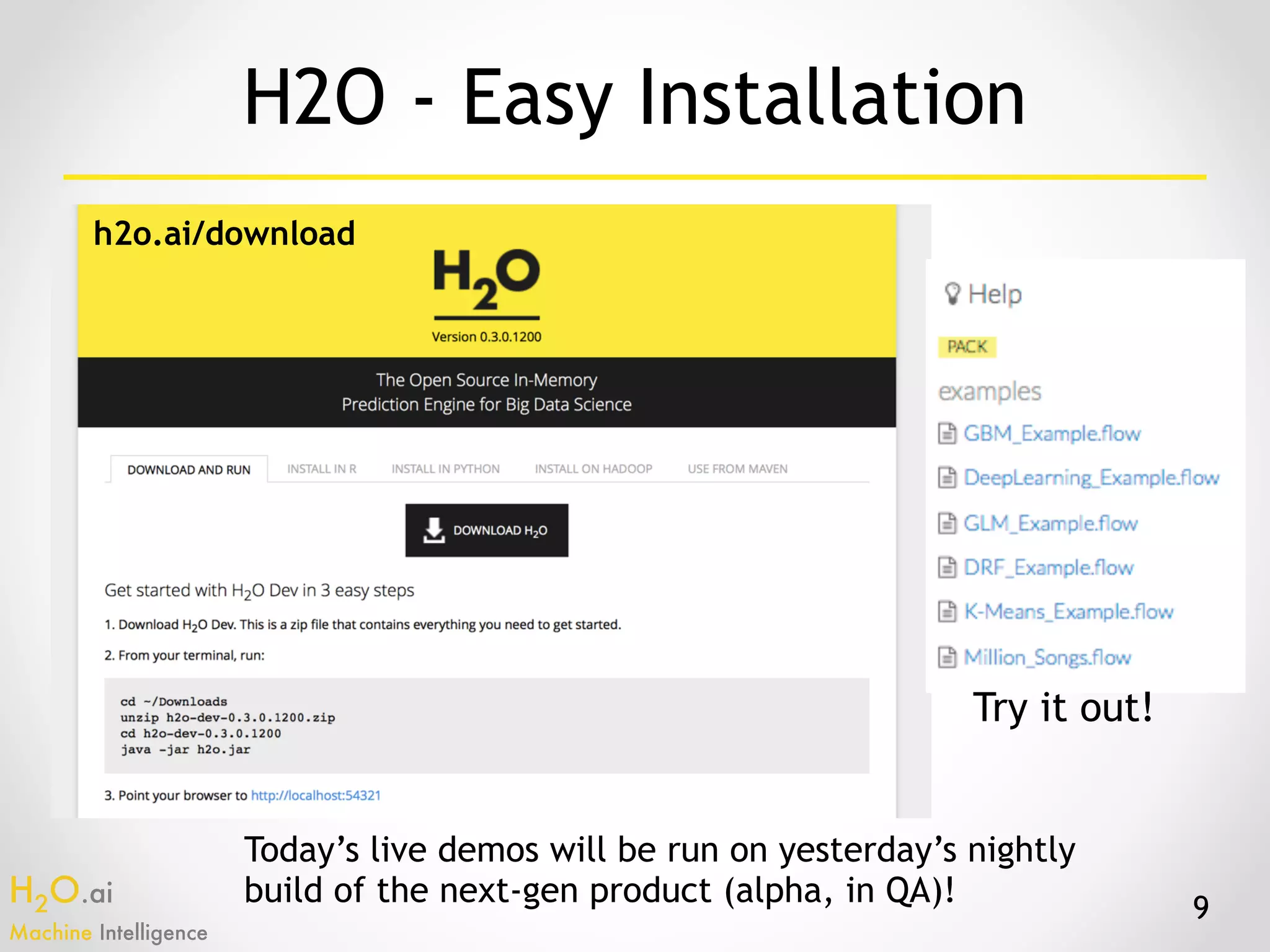
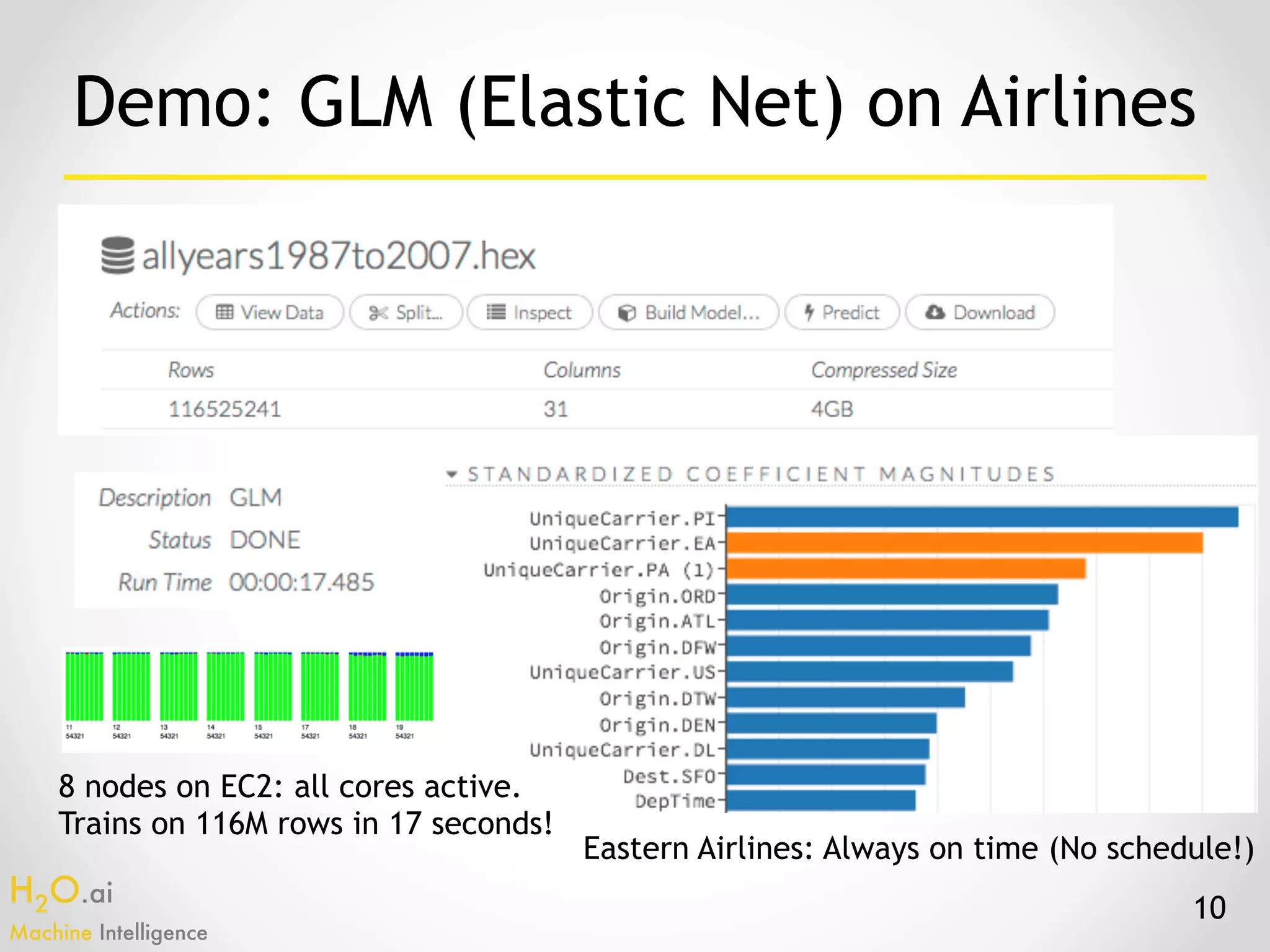


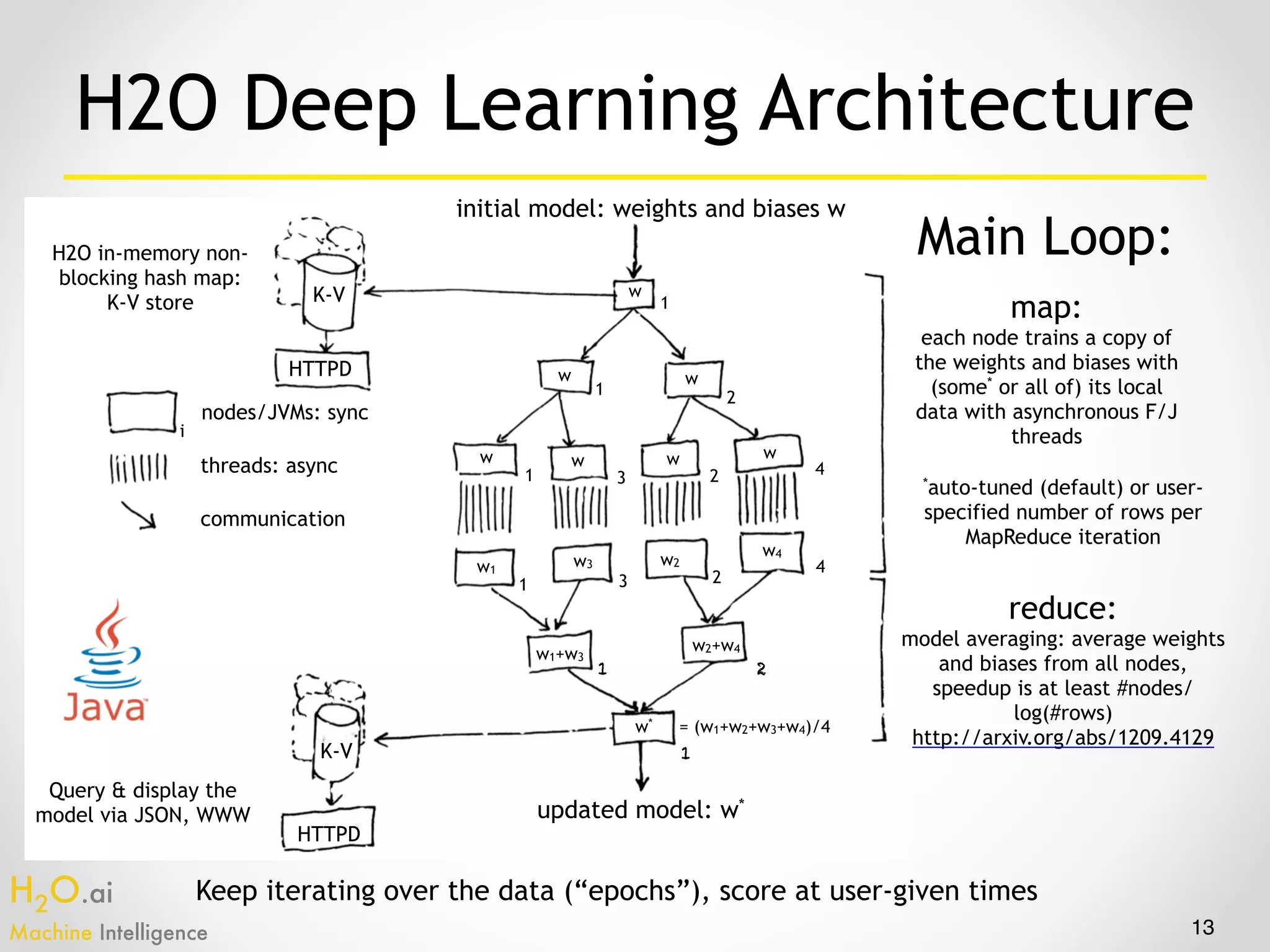

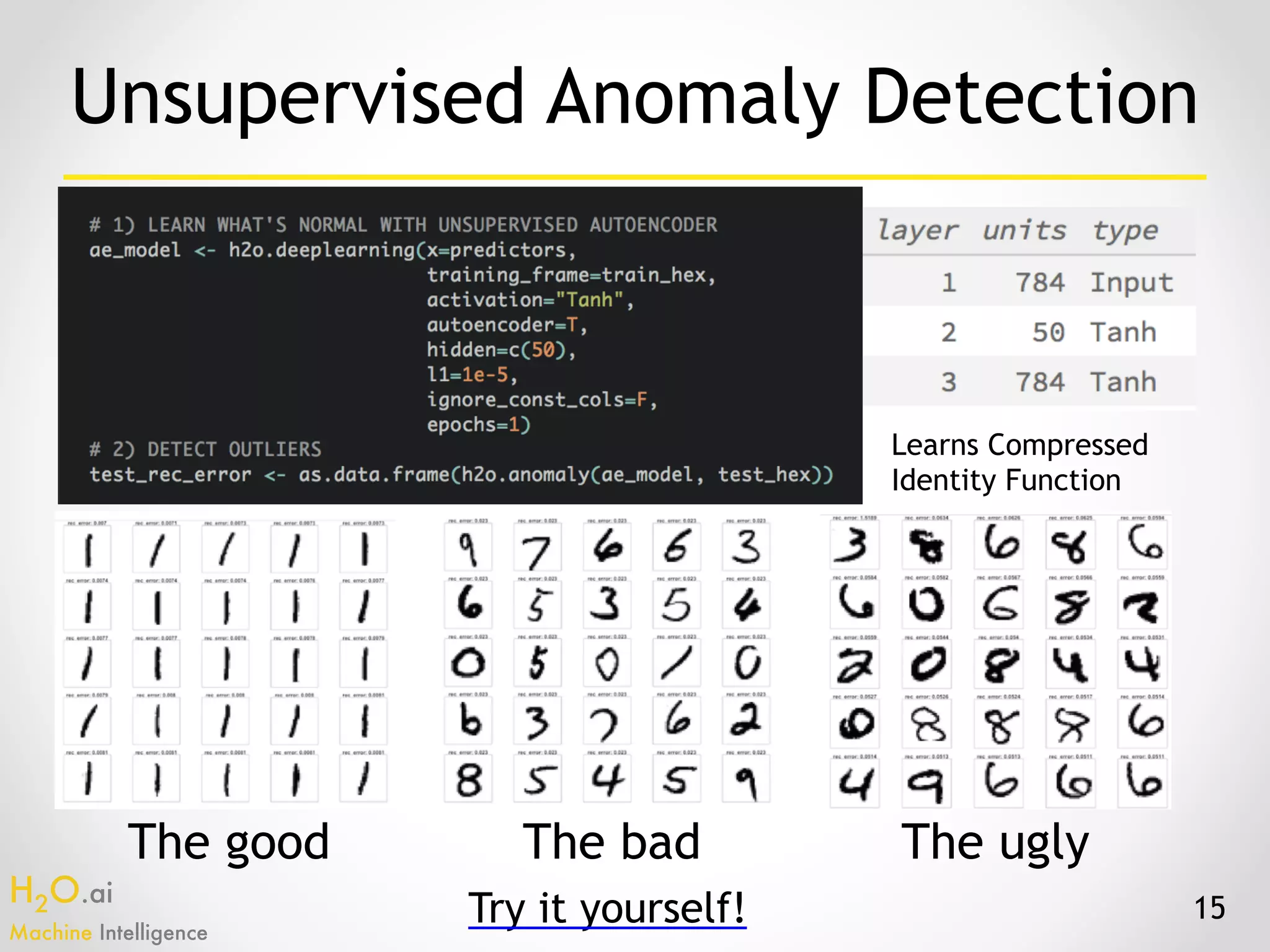




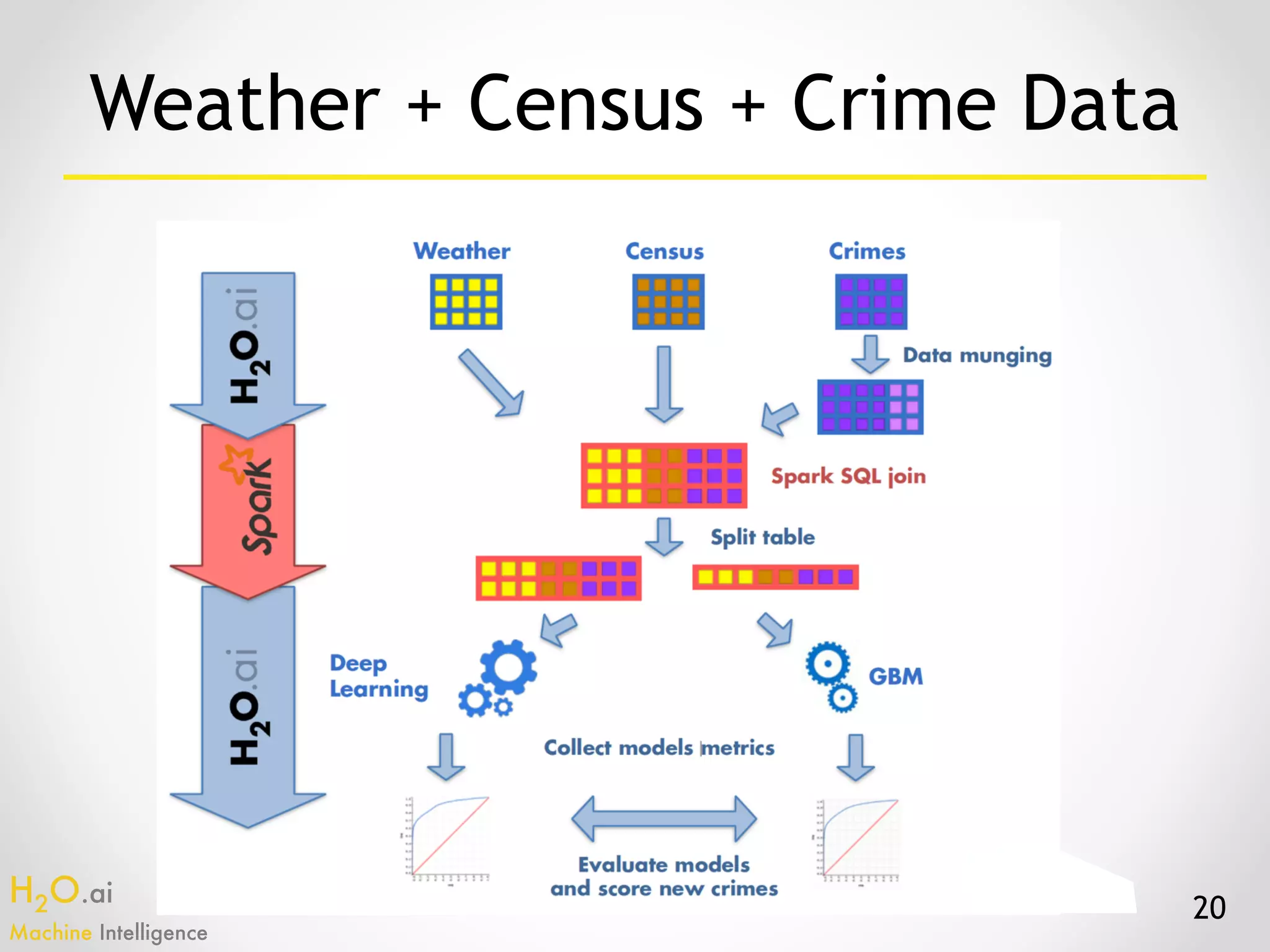
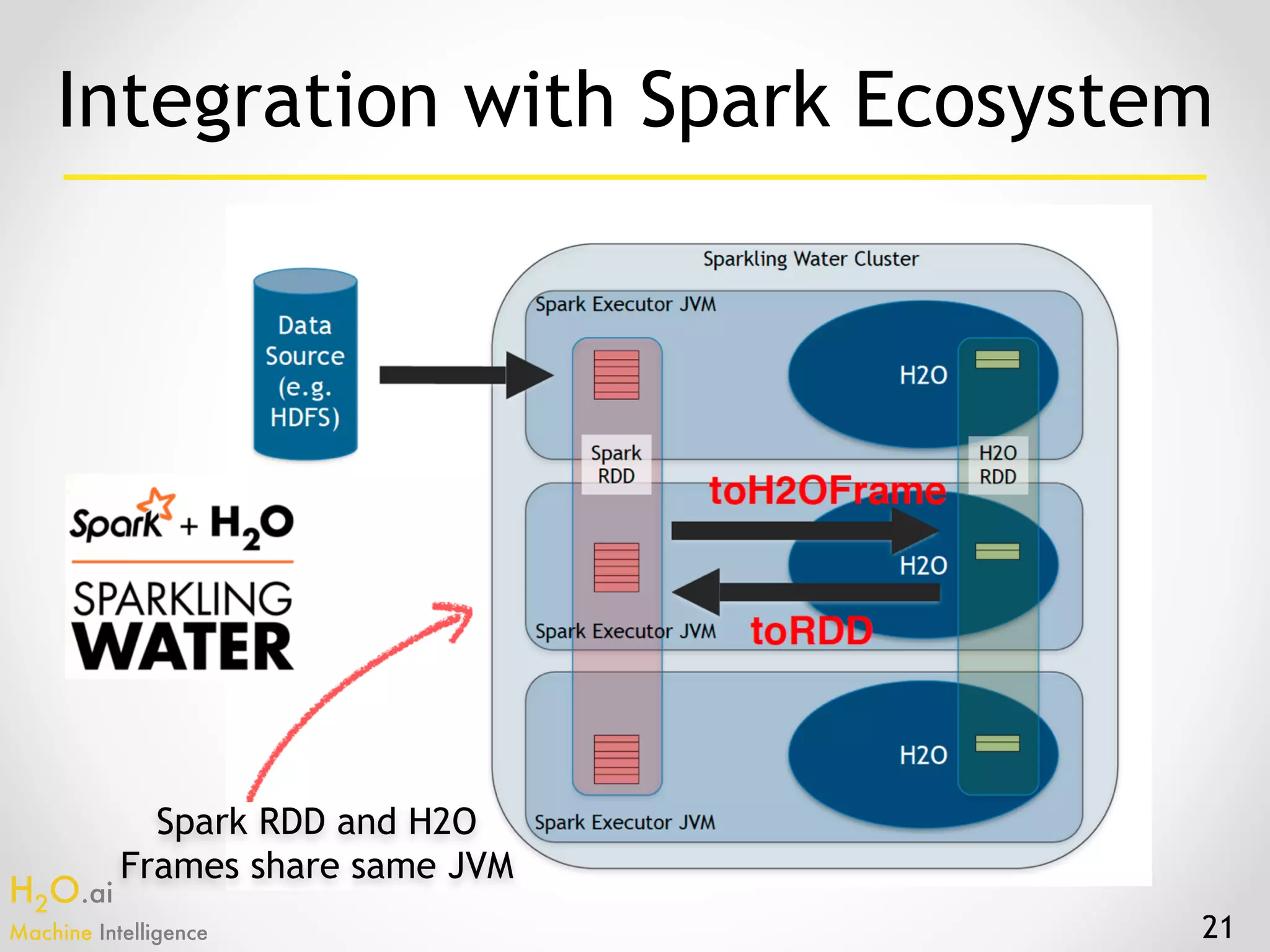

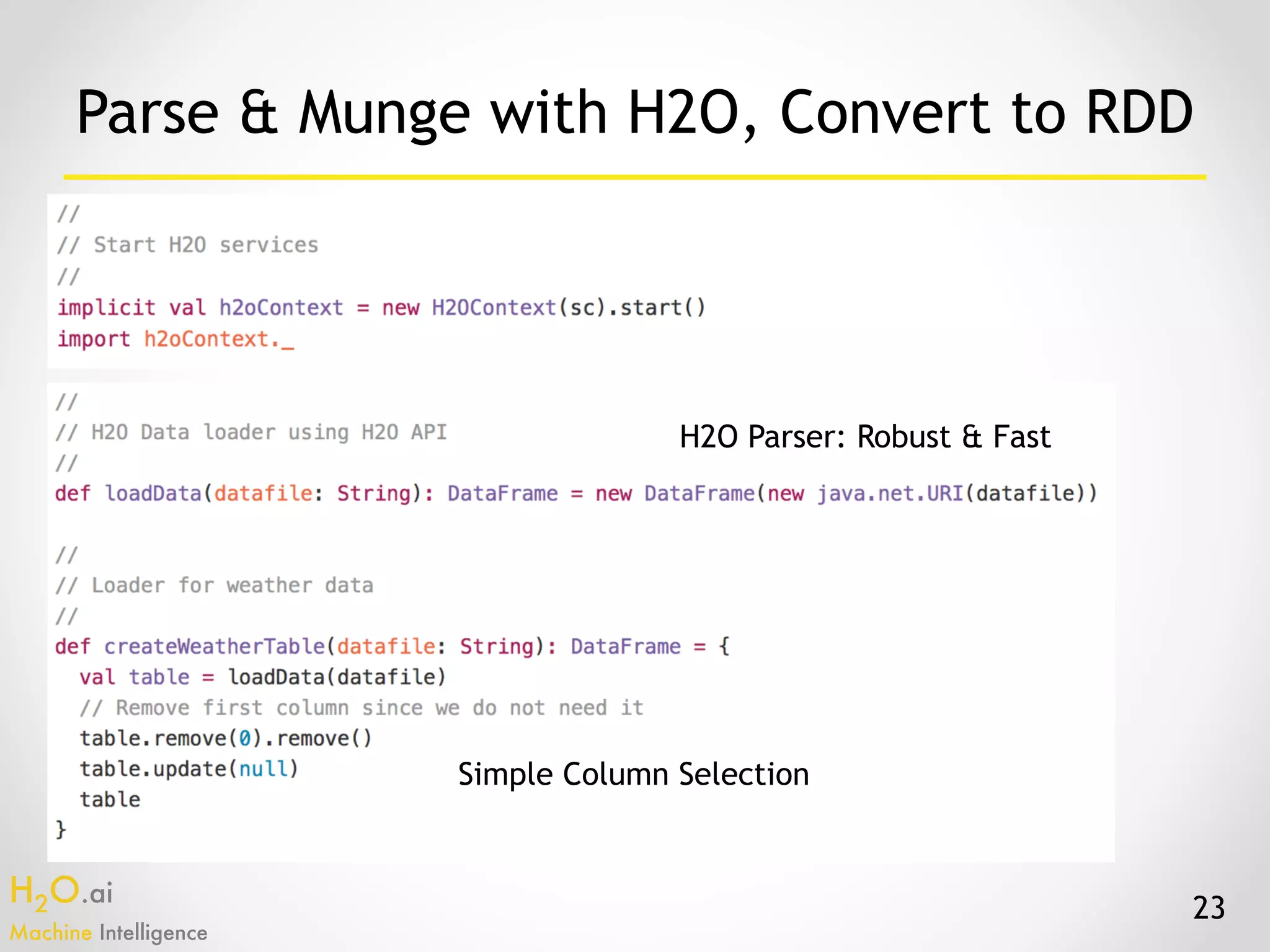



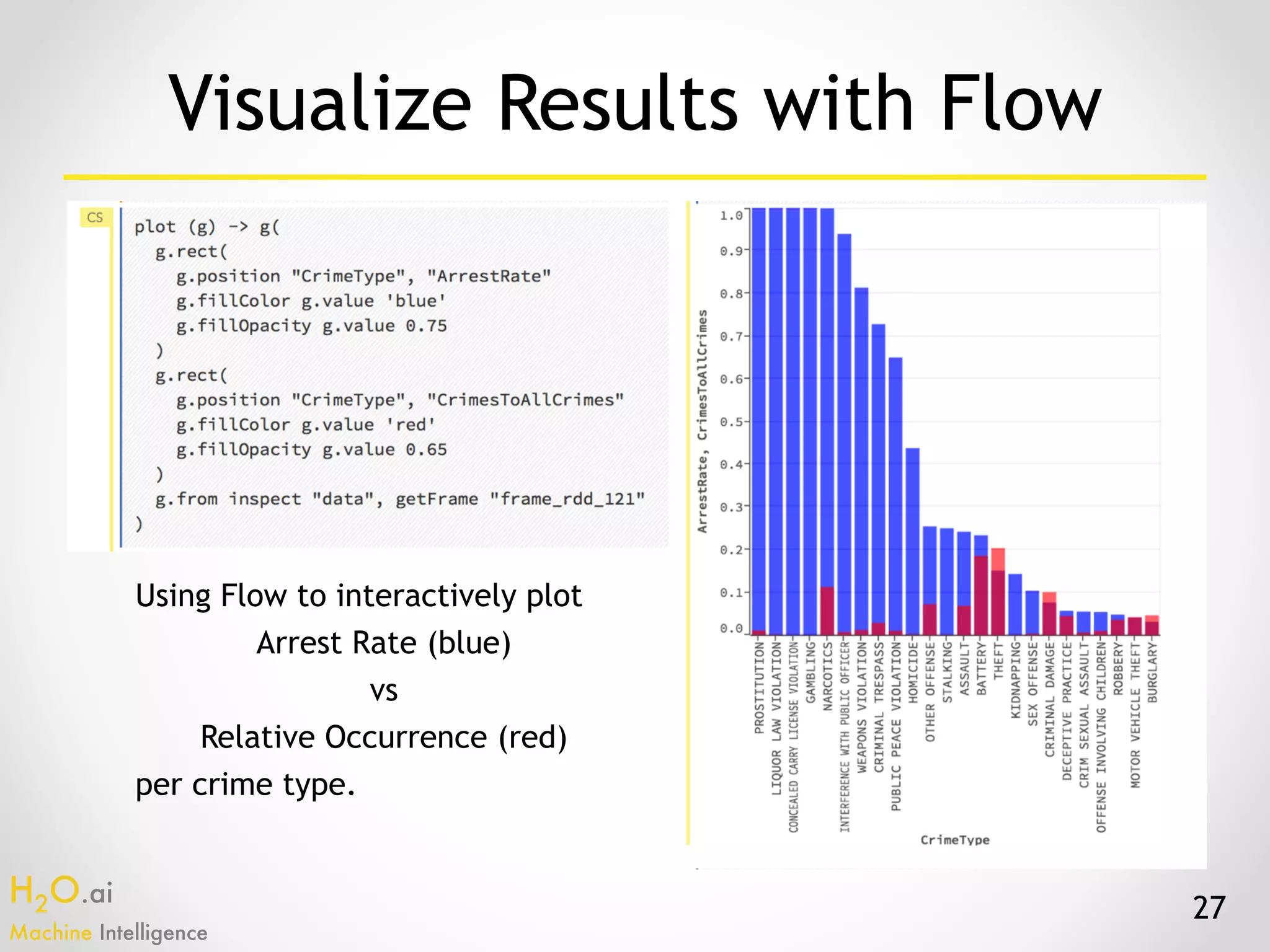


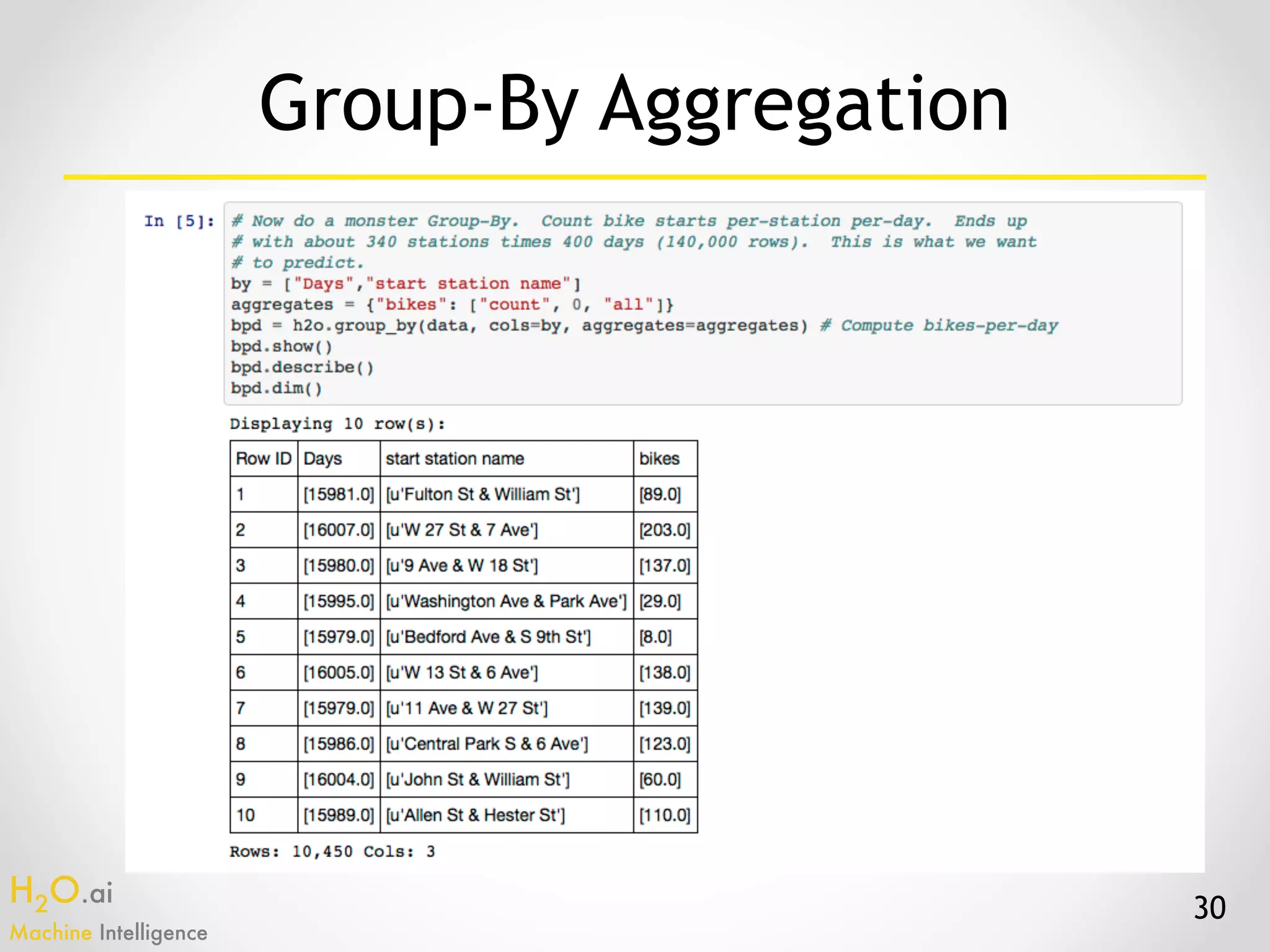

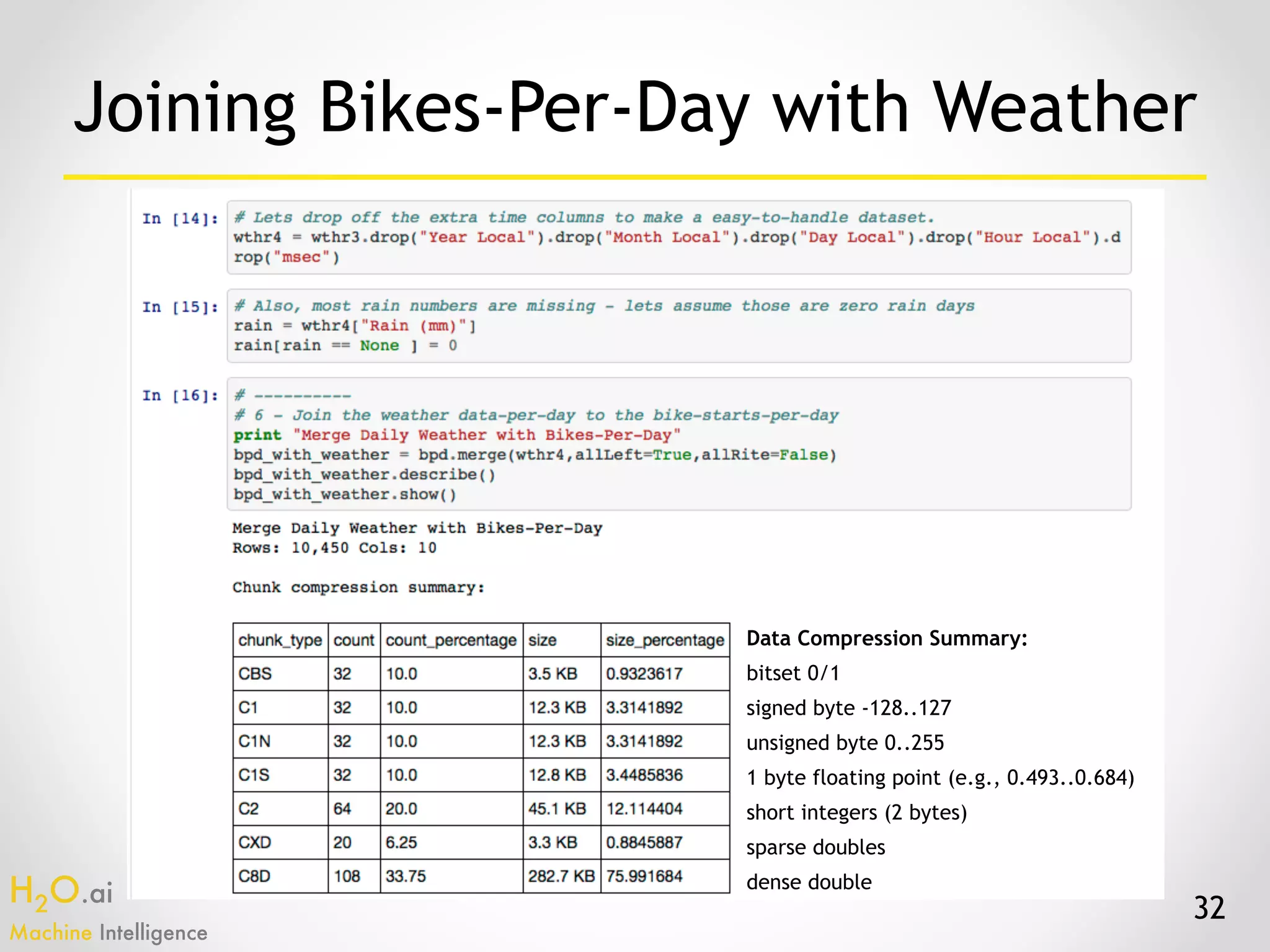






The document presents an overview of H2O.ai's machine learning and deep learning capabilities, emphasizing its scalable architecture, in-memory data processing, and ease of integration. It includes demonstrations of various applications, such as fraud detection and crime prediction, showcasing H2O's speed and accuracy in model training and scoring. The document concludes with an outlook on future developments in H2O's algorithms and features for data scientists and analysts.











































































































