Downloaded 36 times







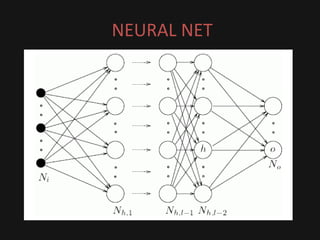



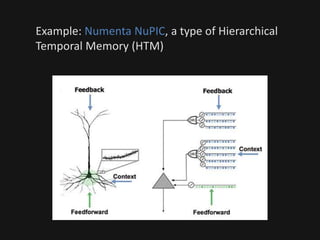

















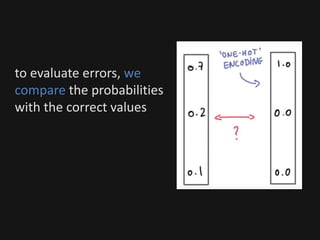
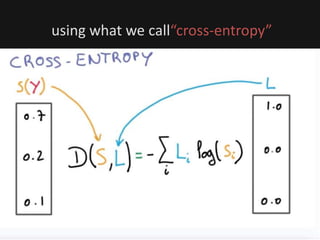

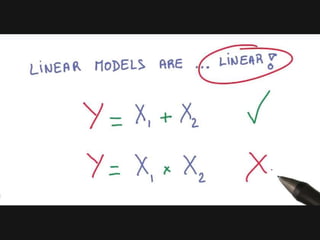


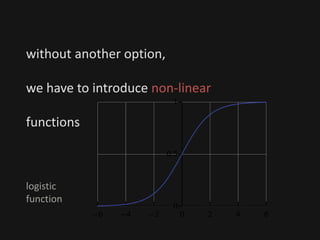
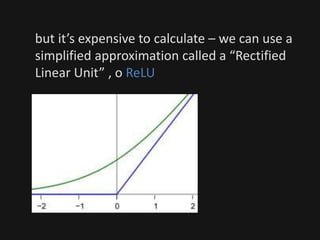
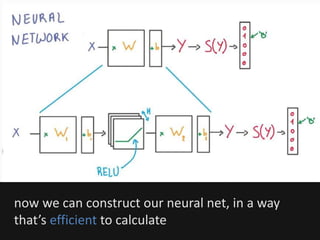
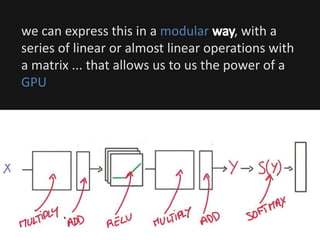



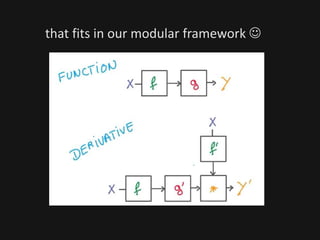
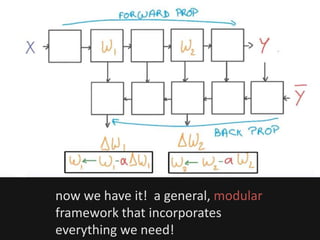



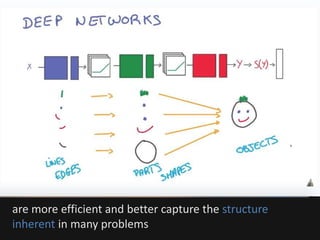


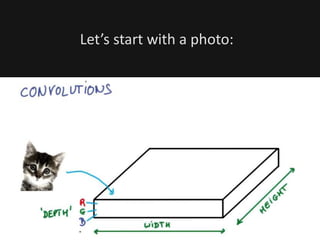
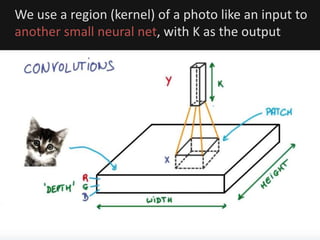
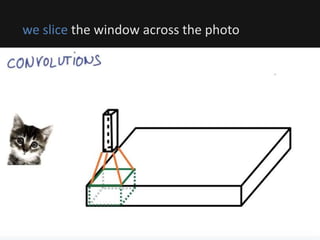
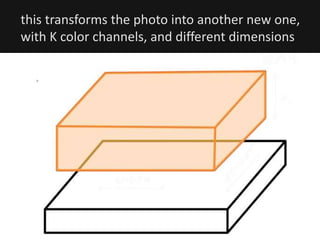





The document introduces deep learning, highlighting its capabilities in achieving human-like performance in tasks such as natural language understanding and video recognition through neural networks. It discusses the construction of classifiers to predict outcomes using linear equations and the need for non-linear functions to enhance model efficiency, leading to deep neural networks. The text emphasizes the advantages of using deep networks, particularly in handling complex problems like language and vision, and briefly describes convolutional networks for visual recognition.


















































































