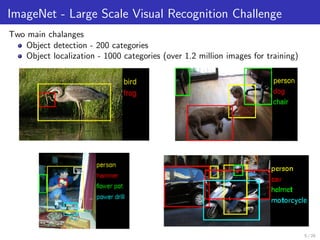
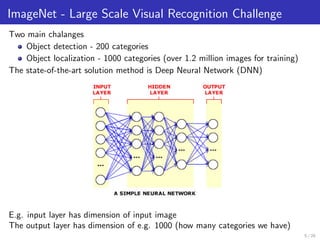
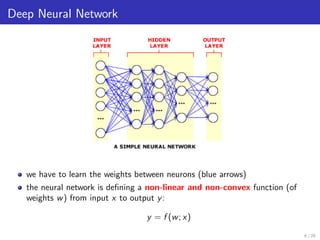
The document presents methods for solving large-scale machine learning problems, particularly using deep neural networks (DNN) in a distributed computing environment. It discusses various machine learning tasks, the structure of DNNs, and the challenges faced in distributed stochastic gradient descent algorithms, emphasizing the importance of mini-batch processing and model/data parallelism. It also touches upon advanced techniques like using Hessian information to improve convergence rates in optimization.




![Mathematical Formulation
Expected Loss Minimization
let (X, Y ) be the distribution of input samples and its labels
we would like to find w such that
w∗
= arg min
w
E(x,y)∼(X,Y )[ (f (w; x), y)]
is a loss function, i.e. (f (w; x), y) = f (w; x) − y 2
8 / 28](https://image.slidesharecdn.com/takacbeamer-160609135232/85/Martin-Takac-Solving-Large-Scale-Machine-Learning-Problems-in-a-Distributed-Way-9-320.jpg)
![Mathematical Formulation
Expected Loss Minimization
let (X, Y ) be the distribution of input samples and its labels
we would like to find w such that
w∗
= arg min
w
E(x,y)∼(X,Y )[ (f (w; x), y)]
is a loss function, i.e. (f (w; x), y) = f (w; x) − y 2
Impossible, as we do not know the distribution (X, Y )
8 / 28](https://image.slidesharecdn.com/takacbeamer-160609135232/85/Martin-Takac-Solving-Large-Scale-Machine-Learning-Problems-in-a-Distributed-Way-10-320.jpg)
![Mathematical Formulation
Expected Loss Minimization
let (X, Y ) be the distribution of input samples and its labels
we would like to find w such that
w∗
= arg min
w
E(x,y)∼(X,Y )[ (f (w; x), y)]
is a loss function, i.e. (f (w; x), y) = f (w; x) − y 2
Impossible, as we do not know the distribution (X, Y )
Common approach: Empirical loss minimization:
we sample n points from (X, Y ): {(xi , yi )}n
i=1
we minimize regularized empirical loss
w∗
= arg min
w
1
n
n
i=1
(f (w; xi ), yi ) +
λ
2
w 2
8 / 28](https://image.slidesharecdn.com/takacbeamer-160609135232/85/Martin-Takac-Solving-Large-Scale-Machine-Learning-Problems-in-a-Distributed-Way-11-320.jpg)



![Stochastic Gradient Descent (SGD) Algorithm
How can we solve
min
w
F(w) :=
1
n
n
i=1
(f (w; xi ); yi ) +
λ
2
w 2
1 we can use an iterative algorithm
2 we start with some initial w
3 we compute g = F(w)
4 we get a new iterate w ← w − αg
5 if w is still not good enough go to step 3
if n is very large, computing g can take a while.... even few hours/days
Trick:
choose i ∈ {1, . . . , n} randomly
define gi = (f (w; wi ); yi ) + λ
2 w 2
use gi instead of g in the algorithm (step 4)
Note: E[gi ] = g, so in expectation, the ”direction” the algorithm is going is the
same as if we use the true gradient, but we can compute it n times faster!
9 / 28](https://image.slidesharecdn.com/takacbeamer-160609135232/85/Martin-Takac-Solving-Large-Scale-Machine-Learning-Problems-in-a-Distributed-Way-15-320.jpg)
















![The Dilemma
large b allows algorithm to be efficiently run on large computer cluster (more
nodes)
very large b doesn’t reduce number of iterations, but each iteration is more
expensive!
The Trick: Do not use just gradient, but use also Hessian (Martens 2010)
Caveat: Hessian matrix can be very large, e.g. the dimension of weights for
TIMIT datasets is almost 1.5M, hence to store Hessian we would need almost
10TB.
The Trick:
We can use Hessian Free approach (we need to be able to compute just
Hessian-vector products)
Algorithm:
w ← w − α[ 2
F(w)]−1
F(w)
19 / 28](https://image.slidesharecdn.com/takacbeamer-160609135232/85/Martin-Takac-Solving-Large-Scale-Machine-Learning-Problems-in-a-Distributed-Way-32-320.jpg)

![Computing Step
recall the algorithm
w ← w − α[ 2
F(w)]−1
F(w)
we need to compute p = [ 2
F(w)]−1
F(w), i.e. to solve
2
F(w)p = F(w) (1)
we can use few iterations of CG method to solve it
(CG assumes that 2
F(w) 0)
In our case it may not be true, hence, it is suggested to stop CG sooner, if it
is detected during CG that 2
F(w) is indefinite
We can use a Bi-CG algorithm to solve (1) and modify the algorithm2
as
follows
w ← w − α
p, if pT
F(x) > 0,
−p, otherwise
PS: we use just b samples to estimate 2
F(w)
2Xi He, Dheevatsa Mudigere, Mikhail Smelyanskiy and Martin Tak´aˇc: Large Scale Distributed
Hessian-Free Optimization for Deep Neural Network, arXiv:1606.00511, 2016.
21 / 28](https://image.slidesharecdn.com/takacbeamer-160609135232/85/Martin-Takac-Solving-Large-Scale-Machine-Learning-Problems-in-a-Distributed-Way-34-320.jpg)




































![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)


























































