Downloaded 92 times





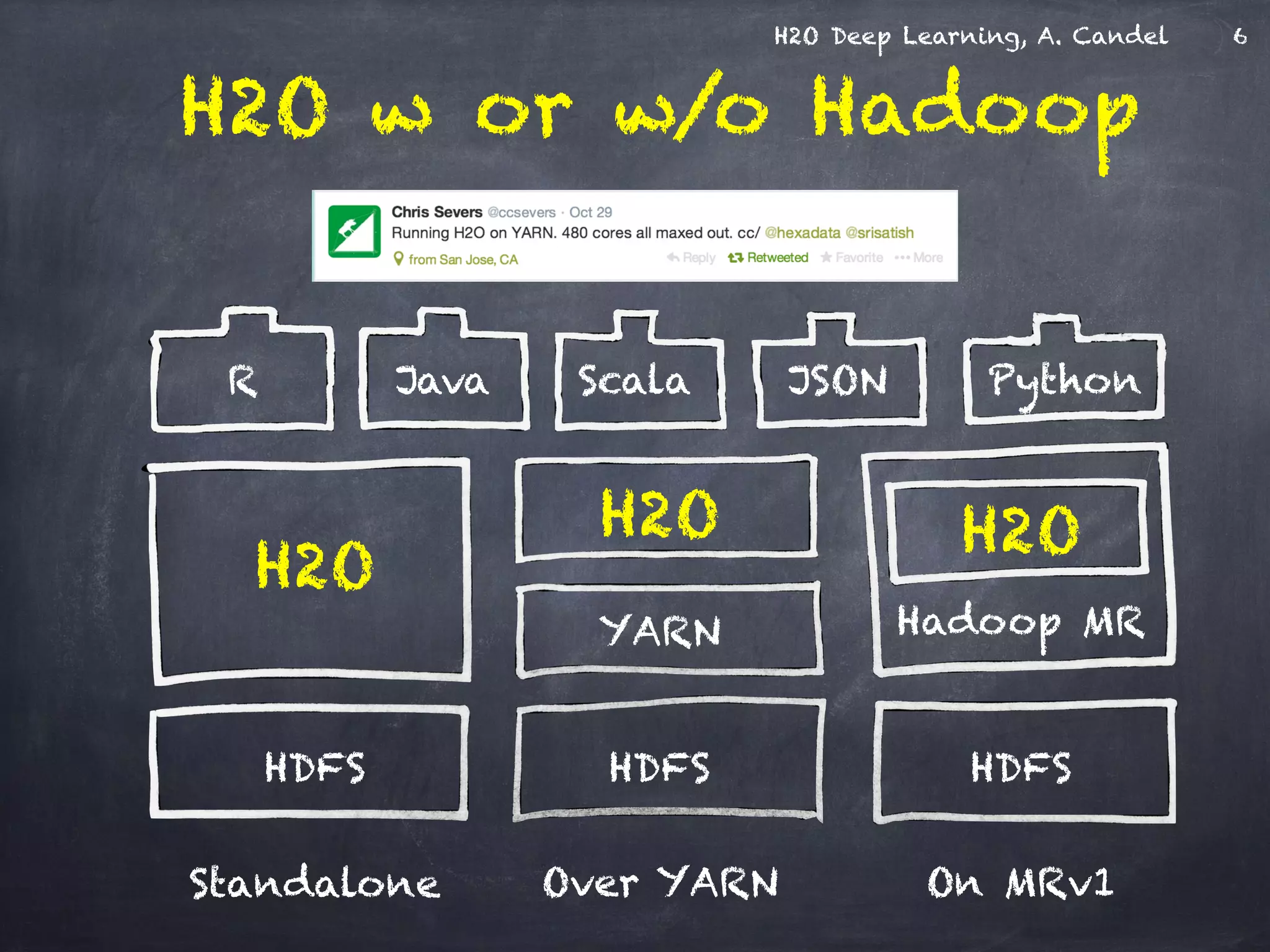
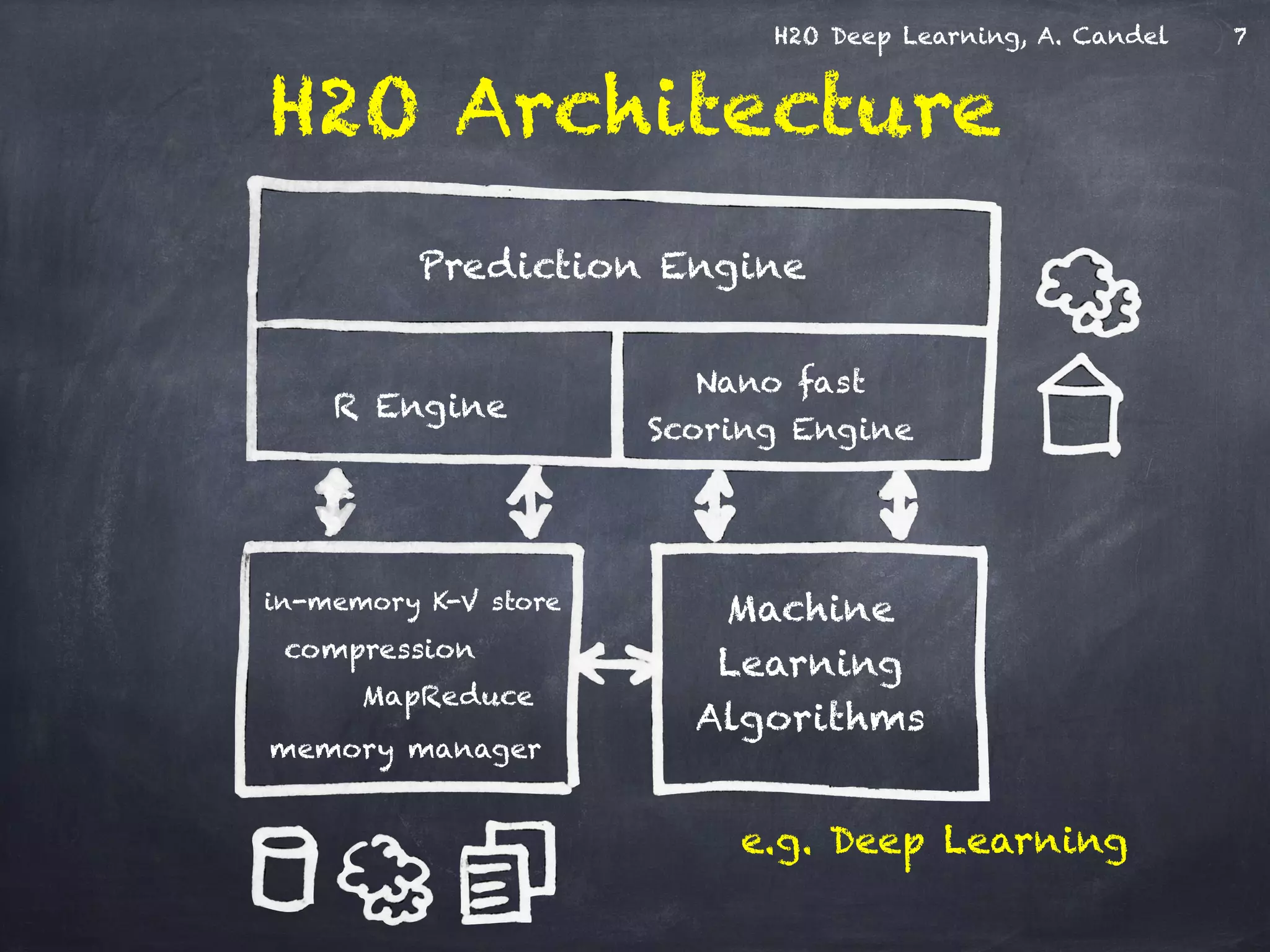





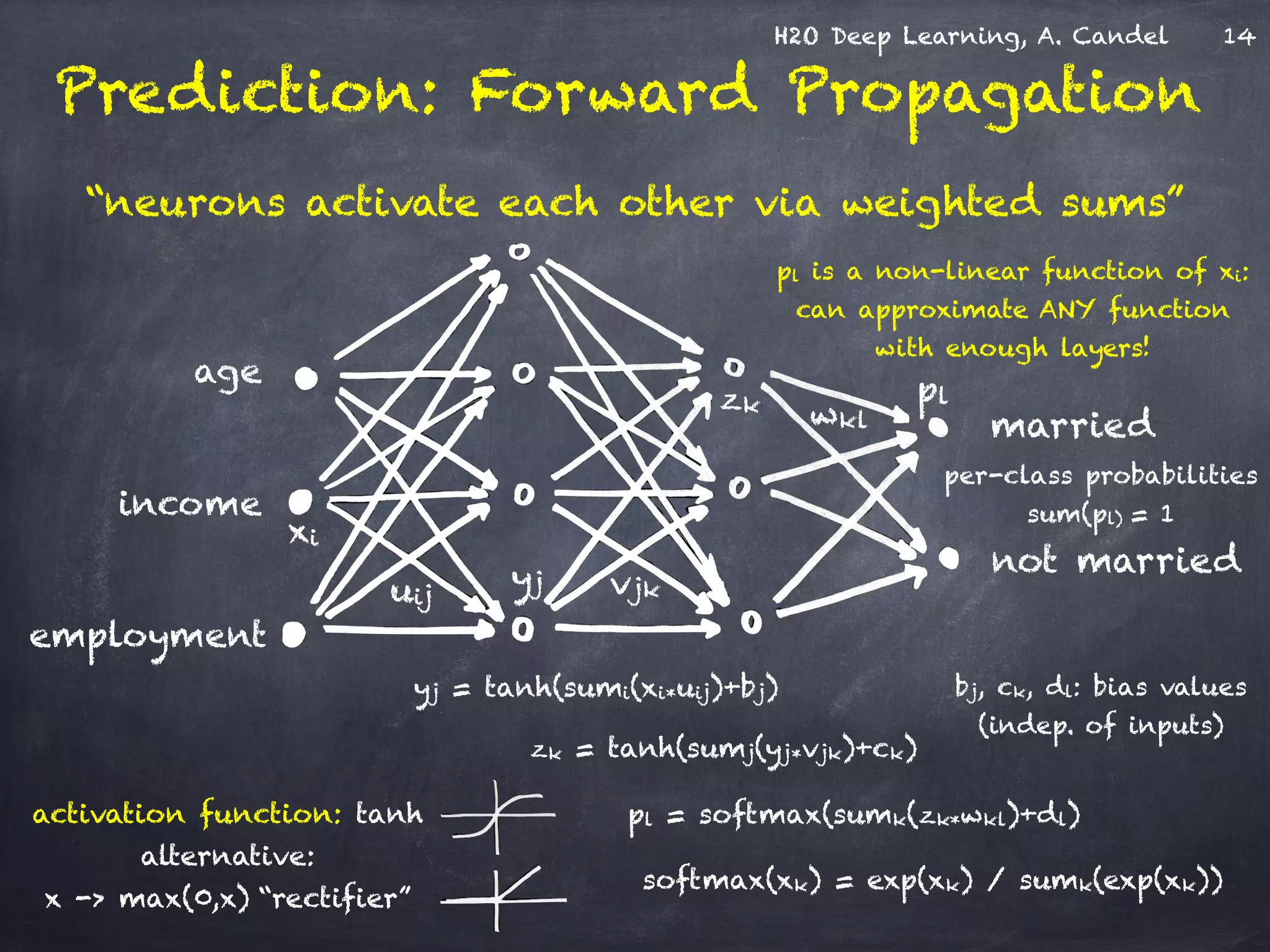
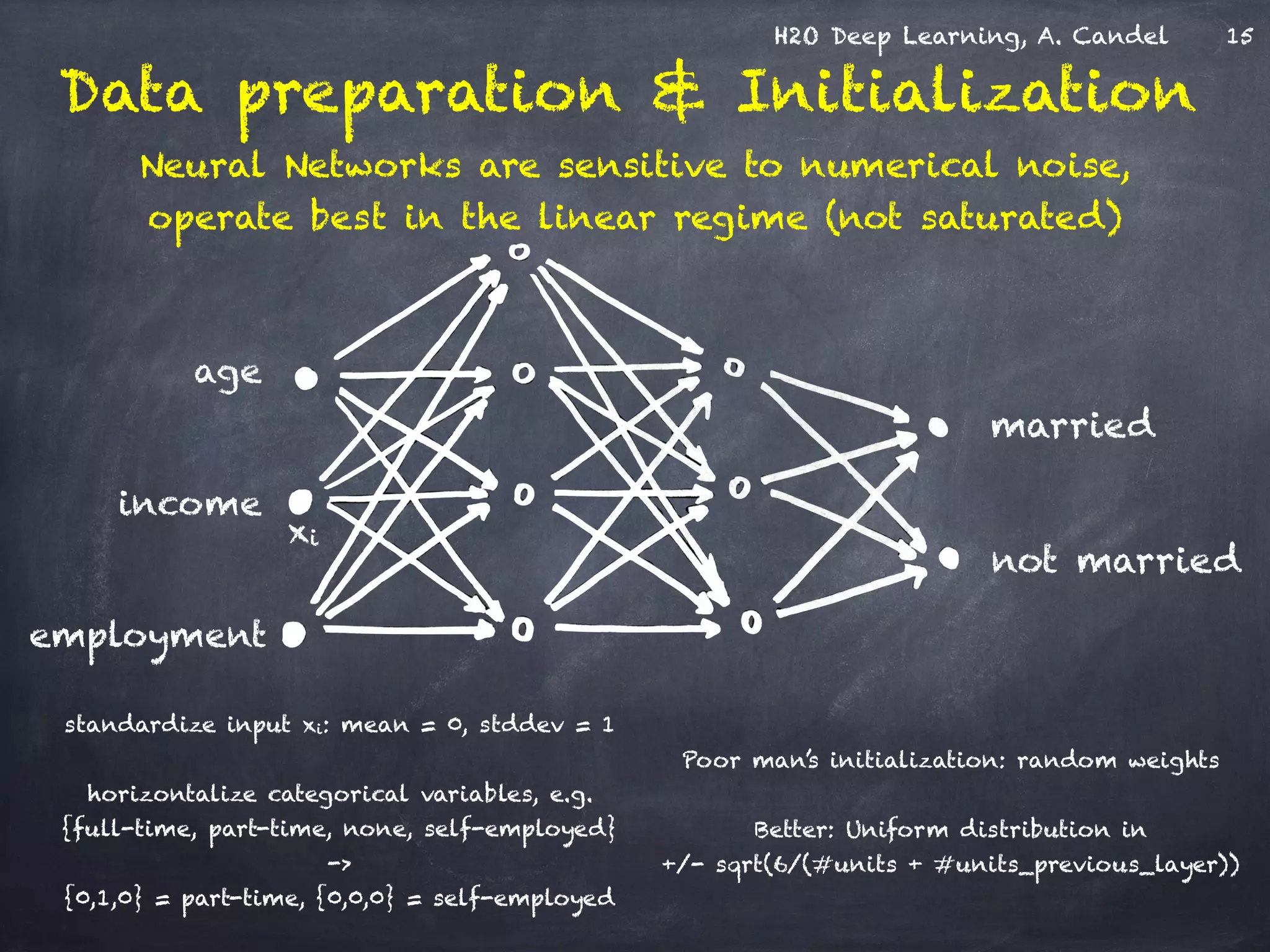

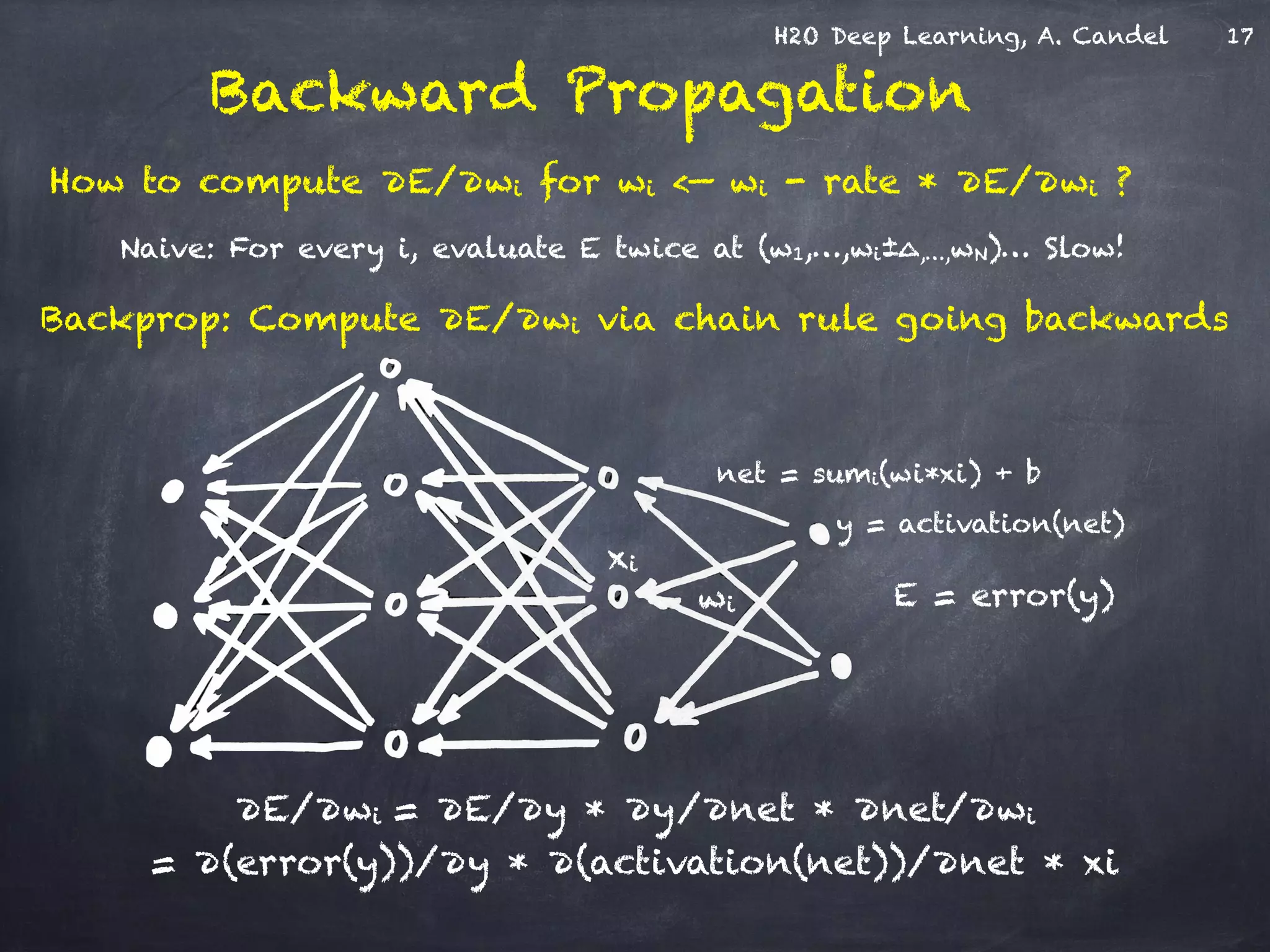
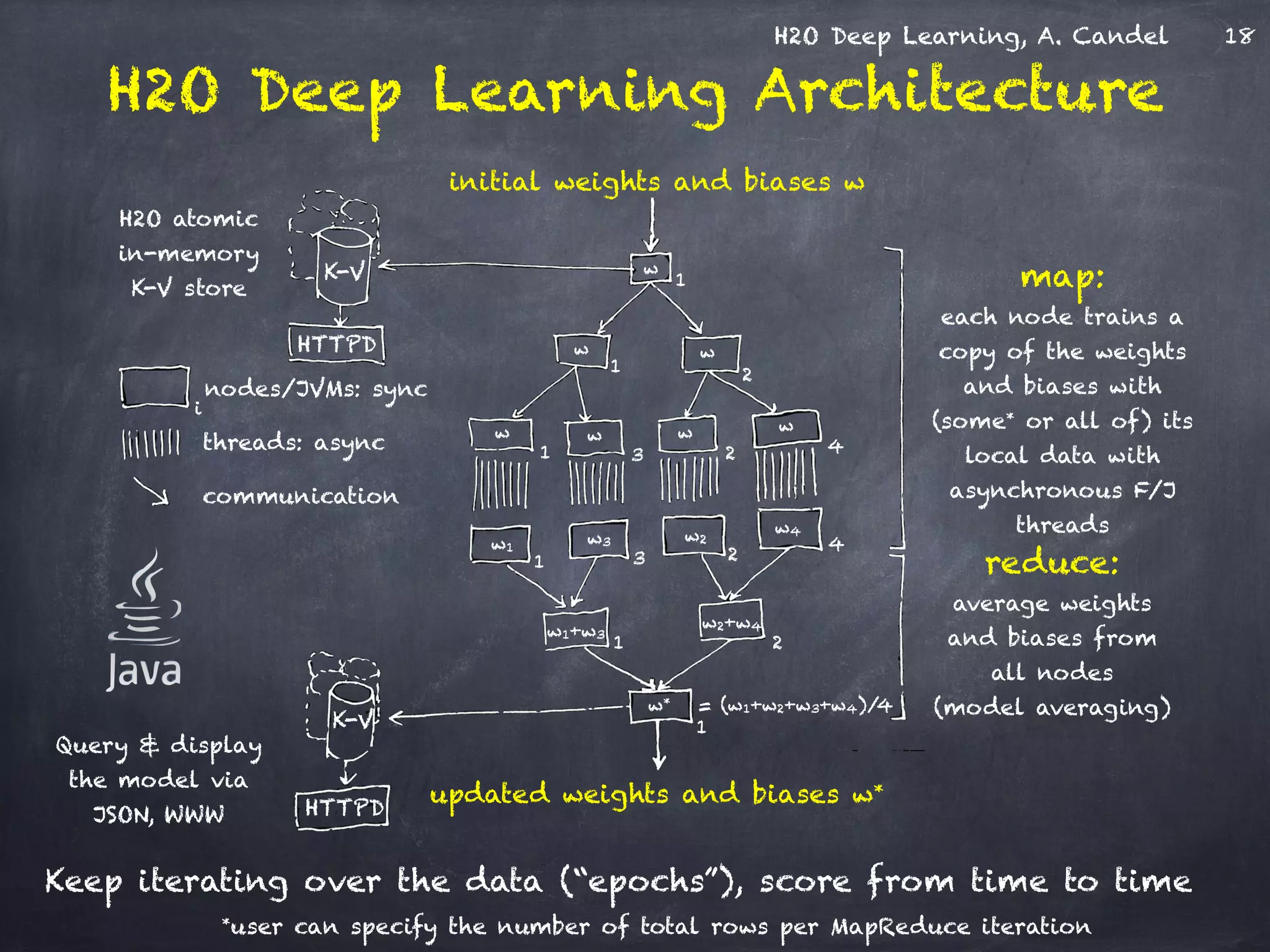


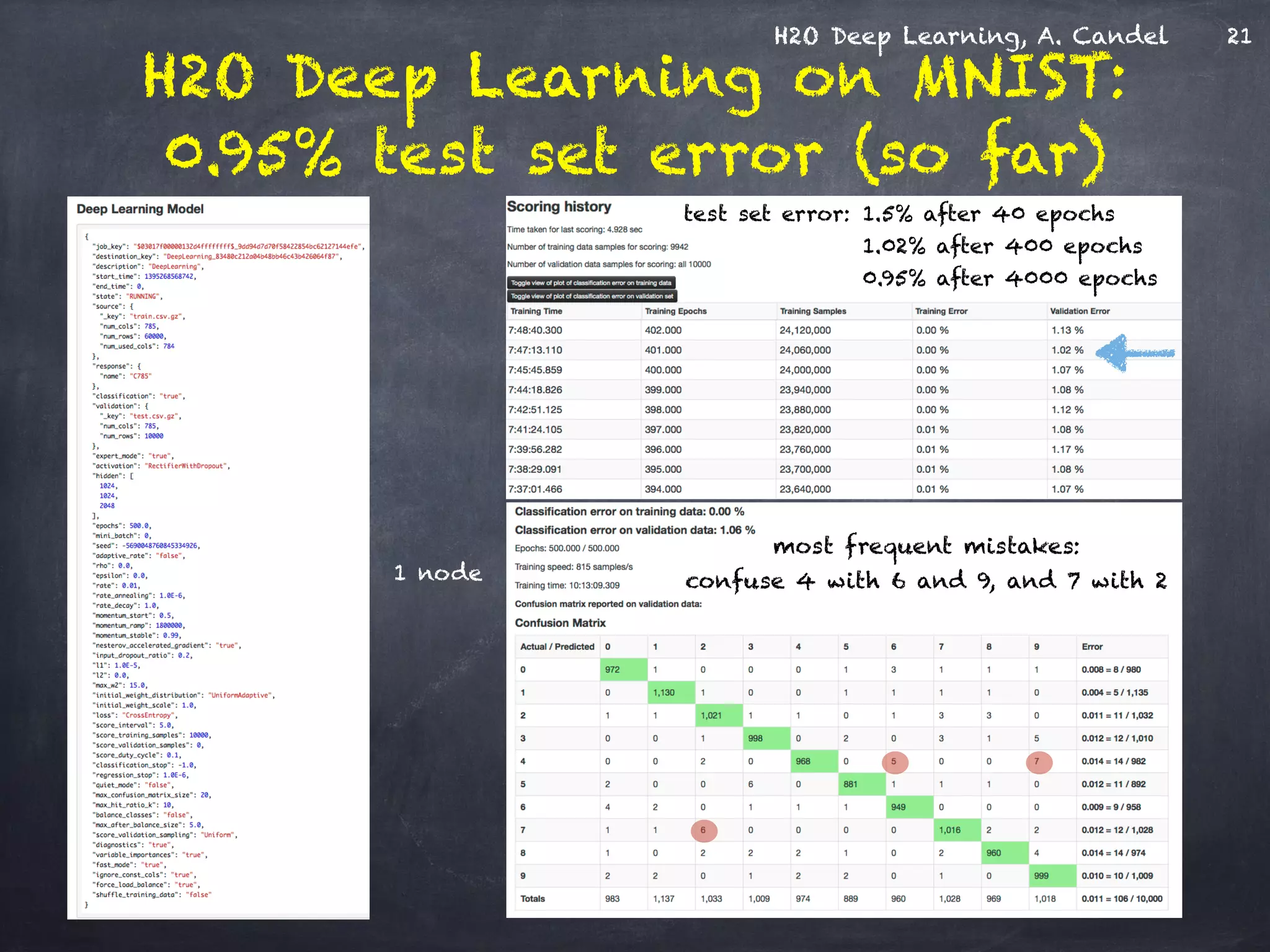

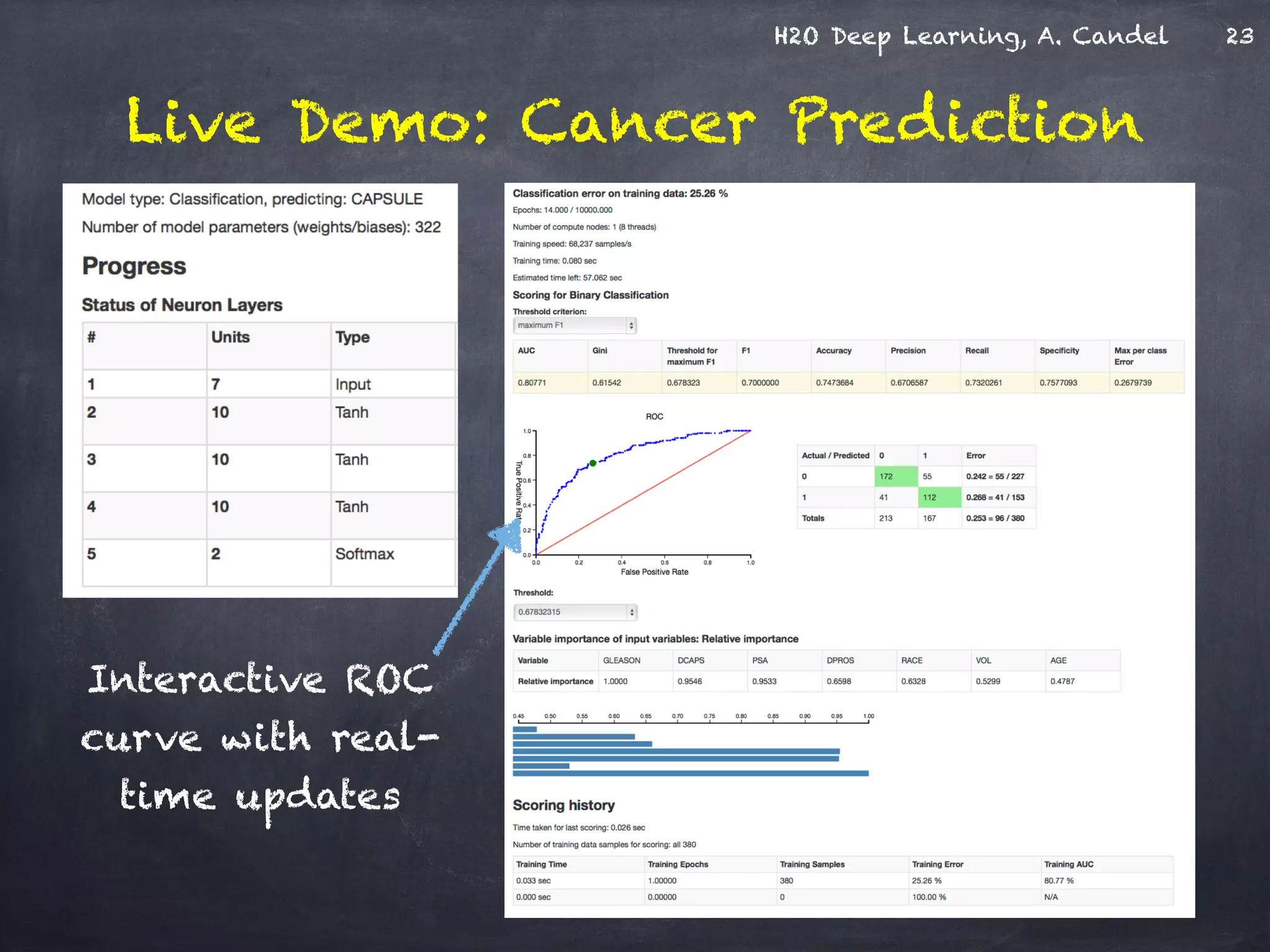
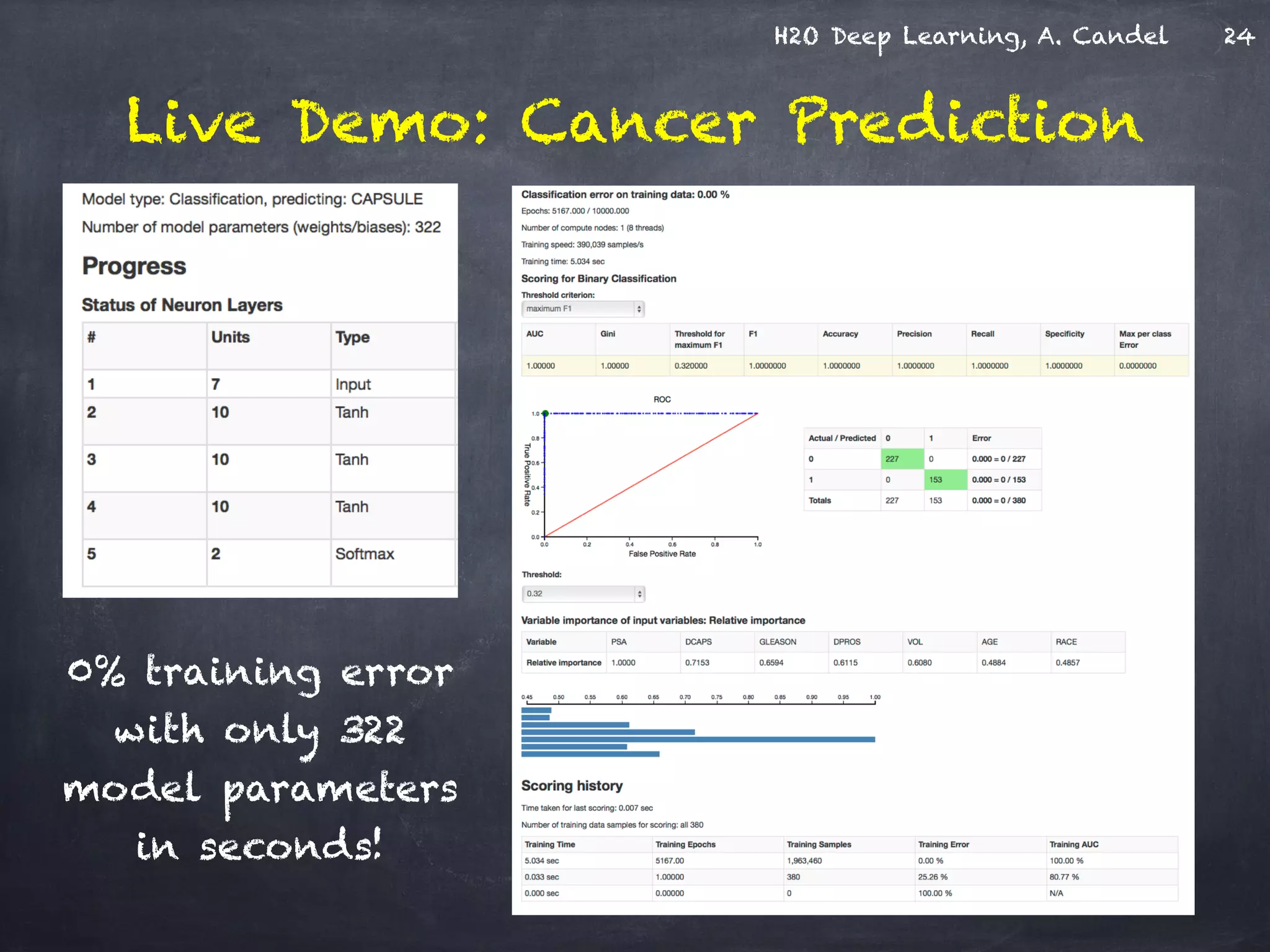
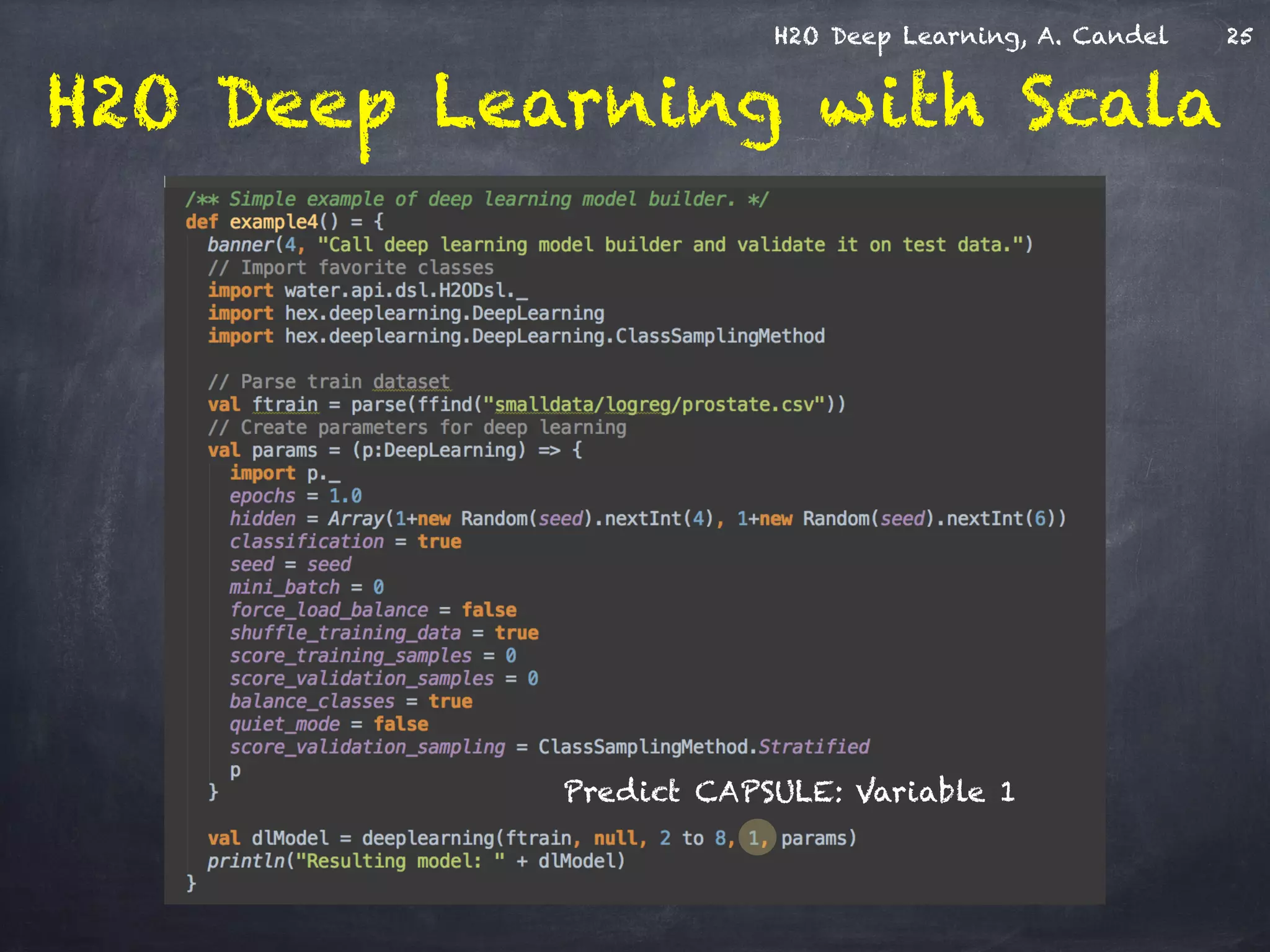
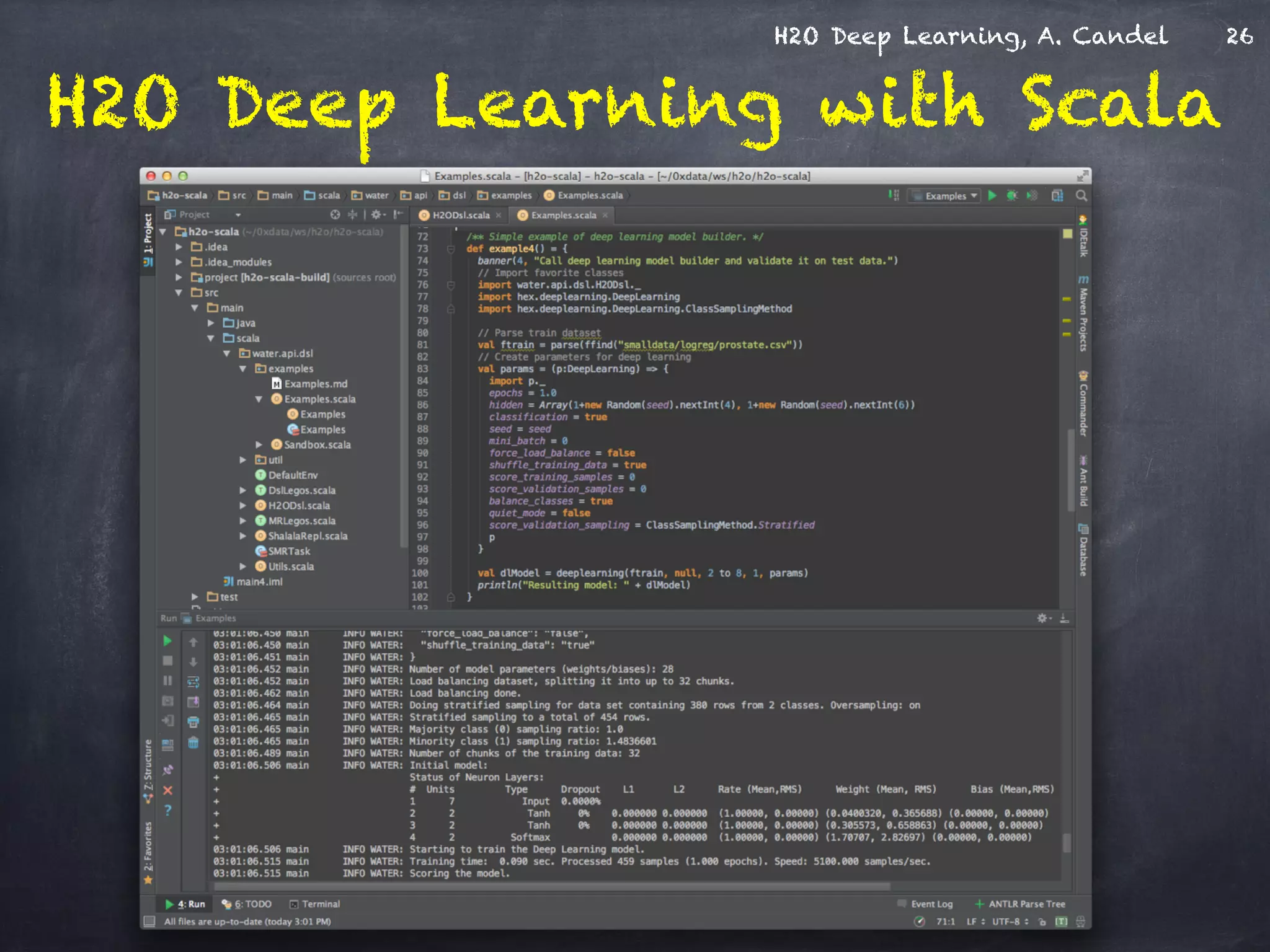






The document discusses H2O, a distributed in-memory machine learning platform that supports deep learning applications across multiple programming languages. It highlights the architecture and functionalities of H2O, showcasing its capabilities in areas such as deep learning for image classification and cancer prediction. The document also includes live demo examples and practical tips for optimizing deep learning model performance.











































































































