Download as PDF, PPTX














![H2O Deep Learning, @ArnoCandel
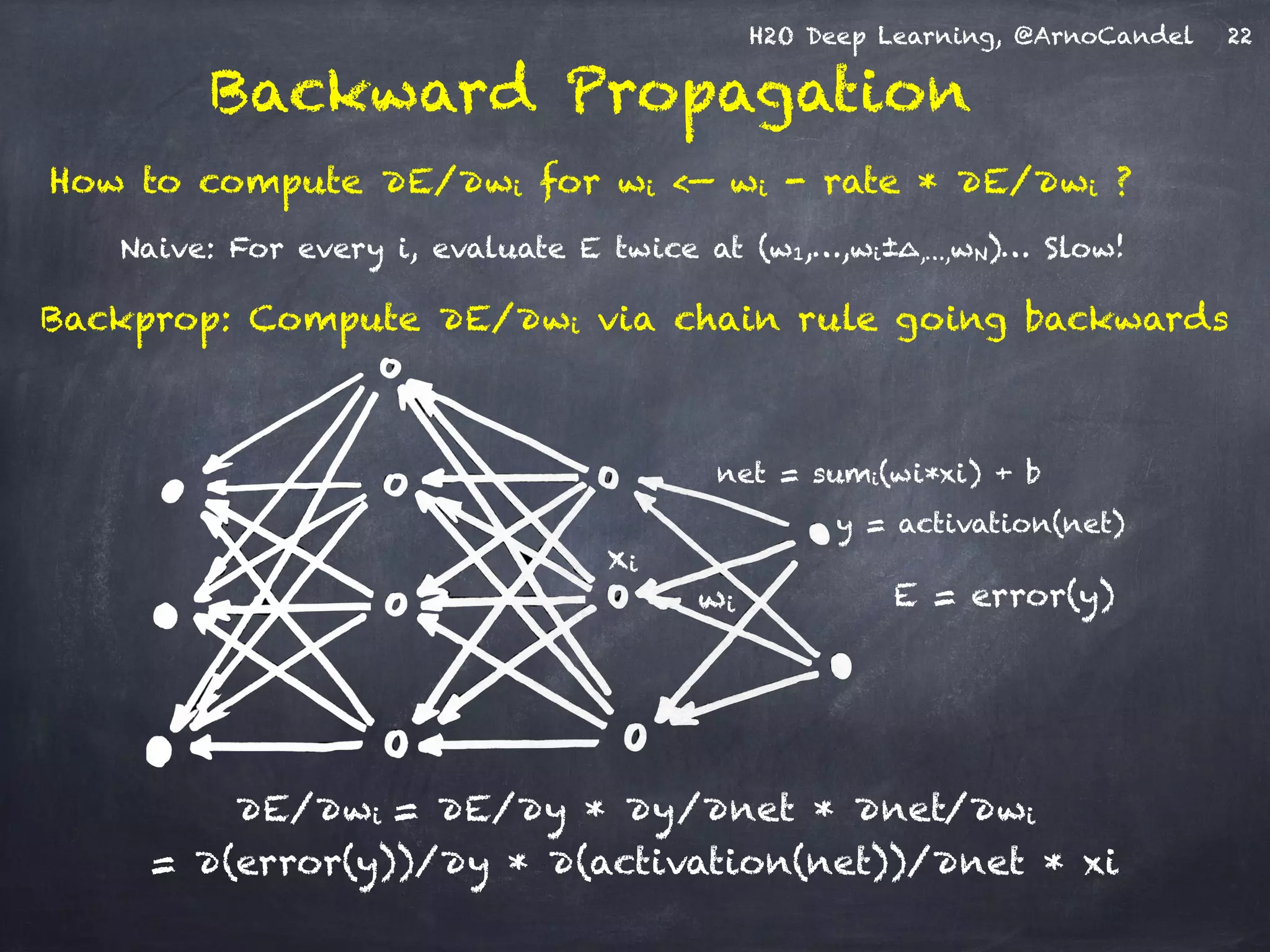
Detail: Adaptive Learning Rate
!
Compute moving average of ∆wi
2 at time t for window length rho:
!
E[∆wi
2]t = rho * E[∆wi
2]t-1 + (1-rho) * ∆wi
2
!
Compute RMS of ∆wi at time t with smoothing epsilon:
!
RMS[∆wi]t = sqrt( E[∆wi
2]t + epsilon )
Adaptive annealing / progress:
Gradient-dependent learning rate,
moving window prevents “freezing”
(unlike ADAGRAD: no window)
Adaptive acceleration / momentum:
accumulate previous weight updates,
but over a window of time
RMS[∆wi]t-1
RMS[∂E/∂wi]t
rate(wi, t) =
Do the same for ∂E/∂wi, then
obtain per-weight learning rate:
cf. ADADELTA paper
25](https://image.slidesharecdn.com/h2odeeplearningarnocandel071614-140717004355-phpapp02/75/H2O-Distributed-Deep-Learning-by-Arno-Candel-071614-25-2048.jpg)
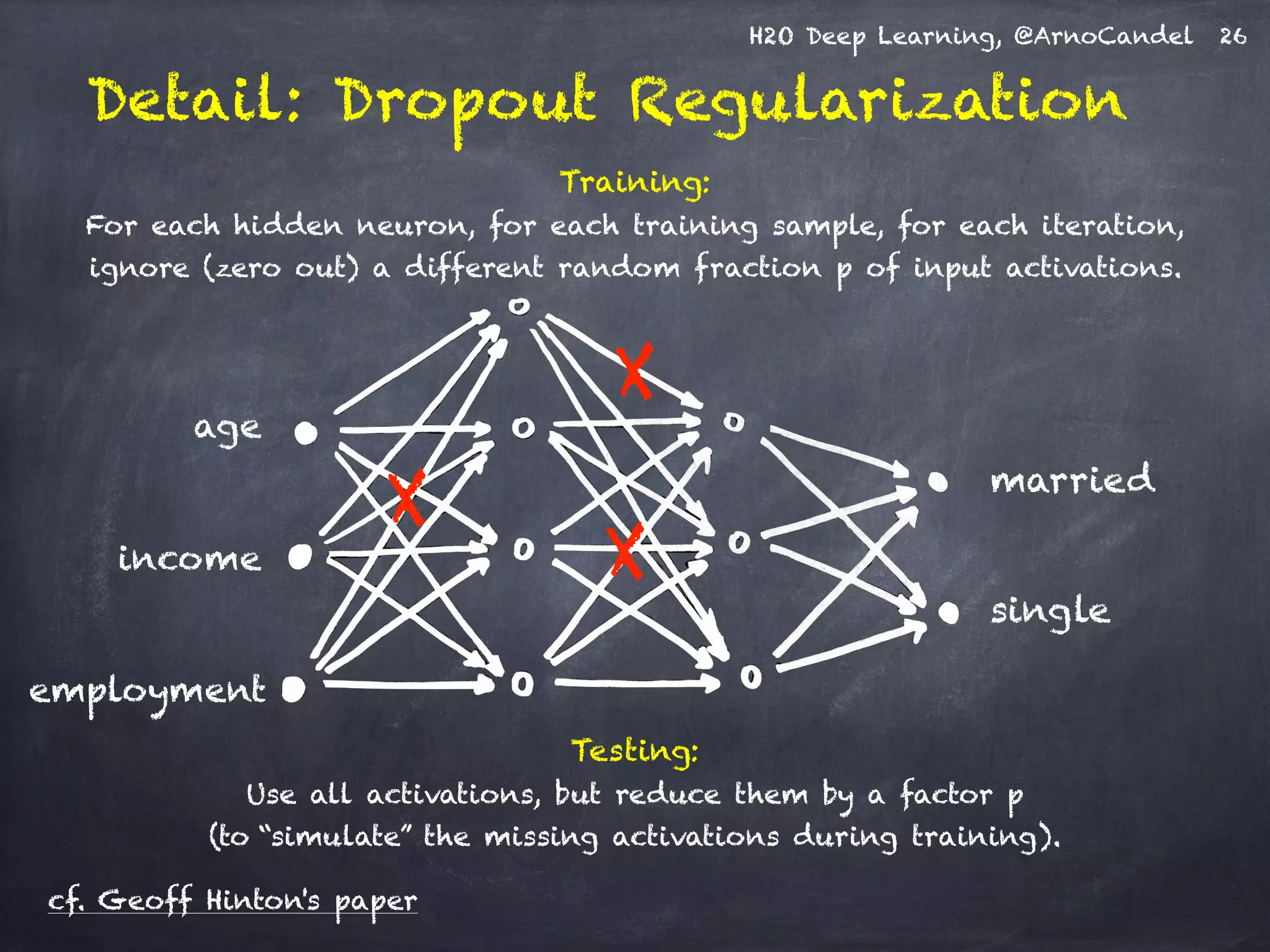









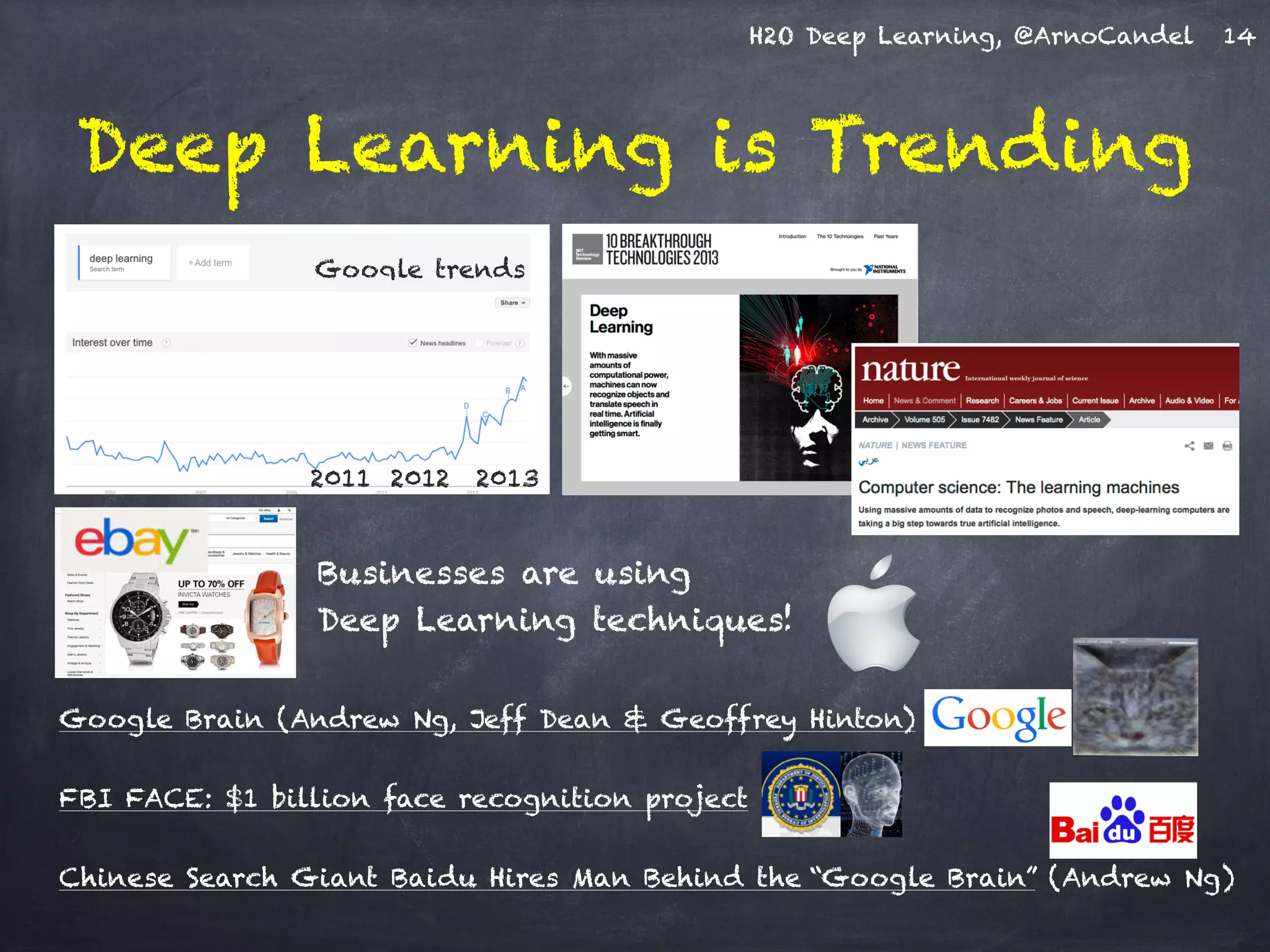
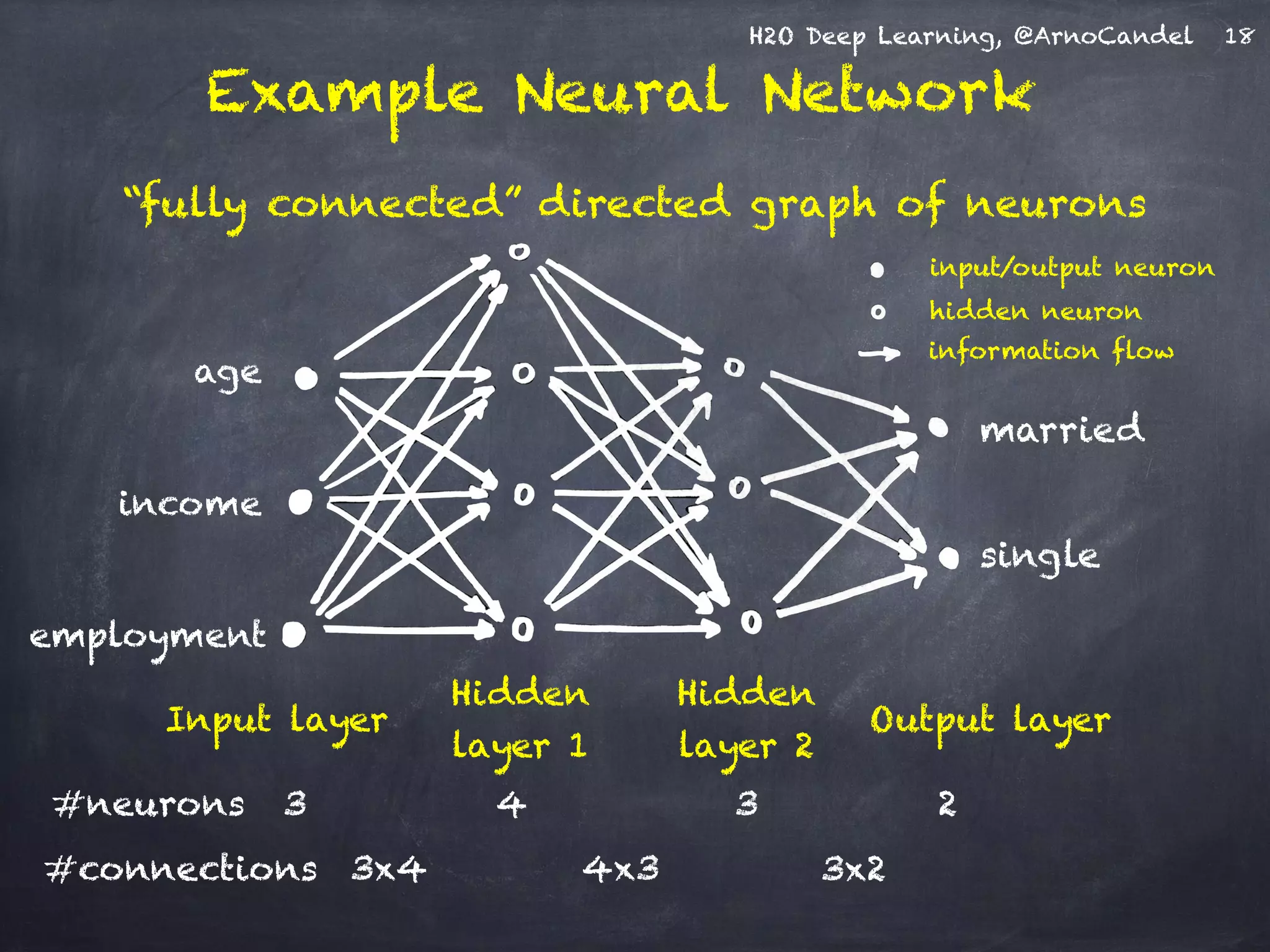
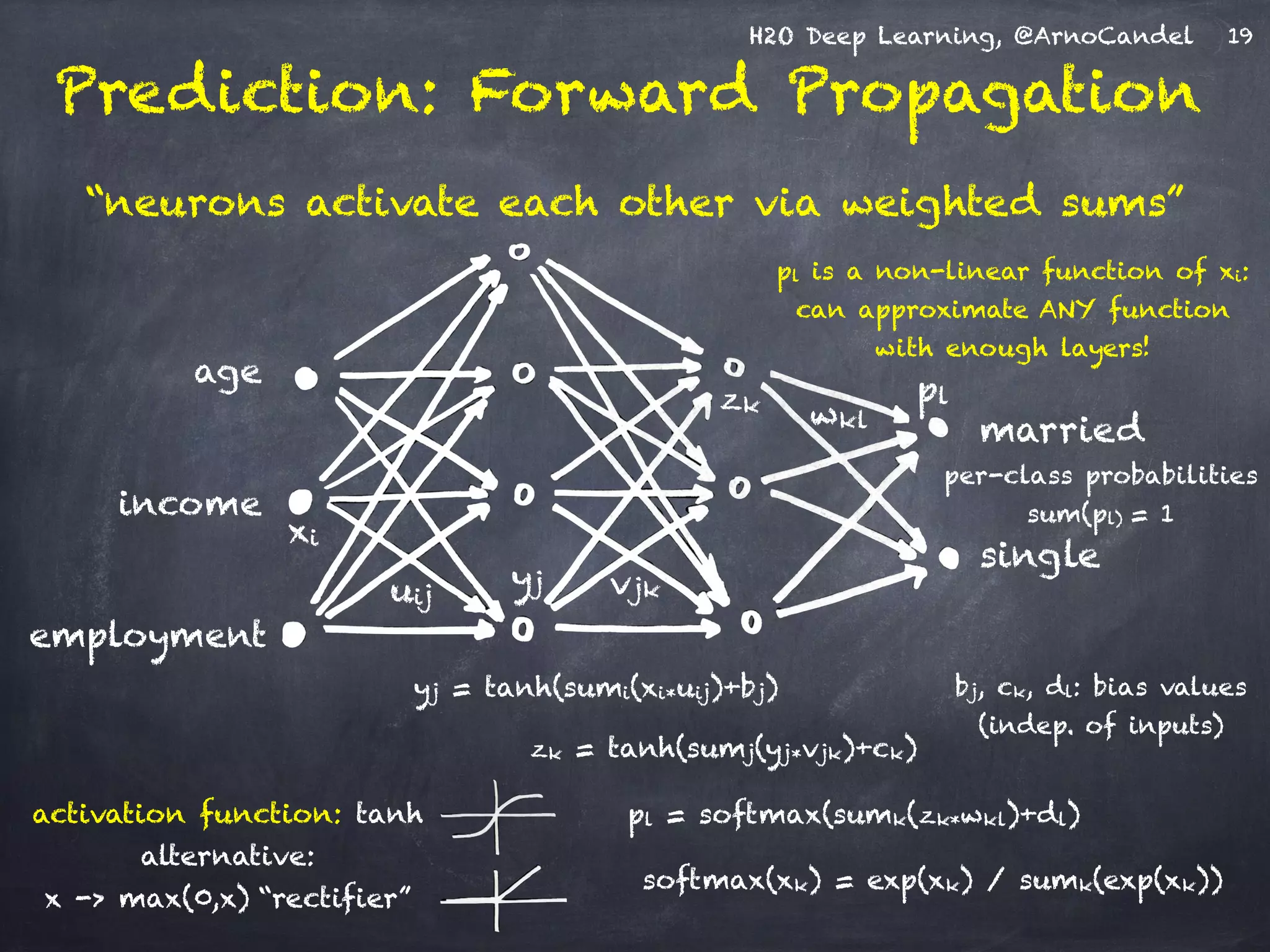
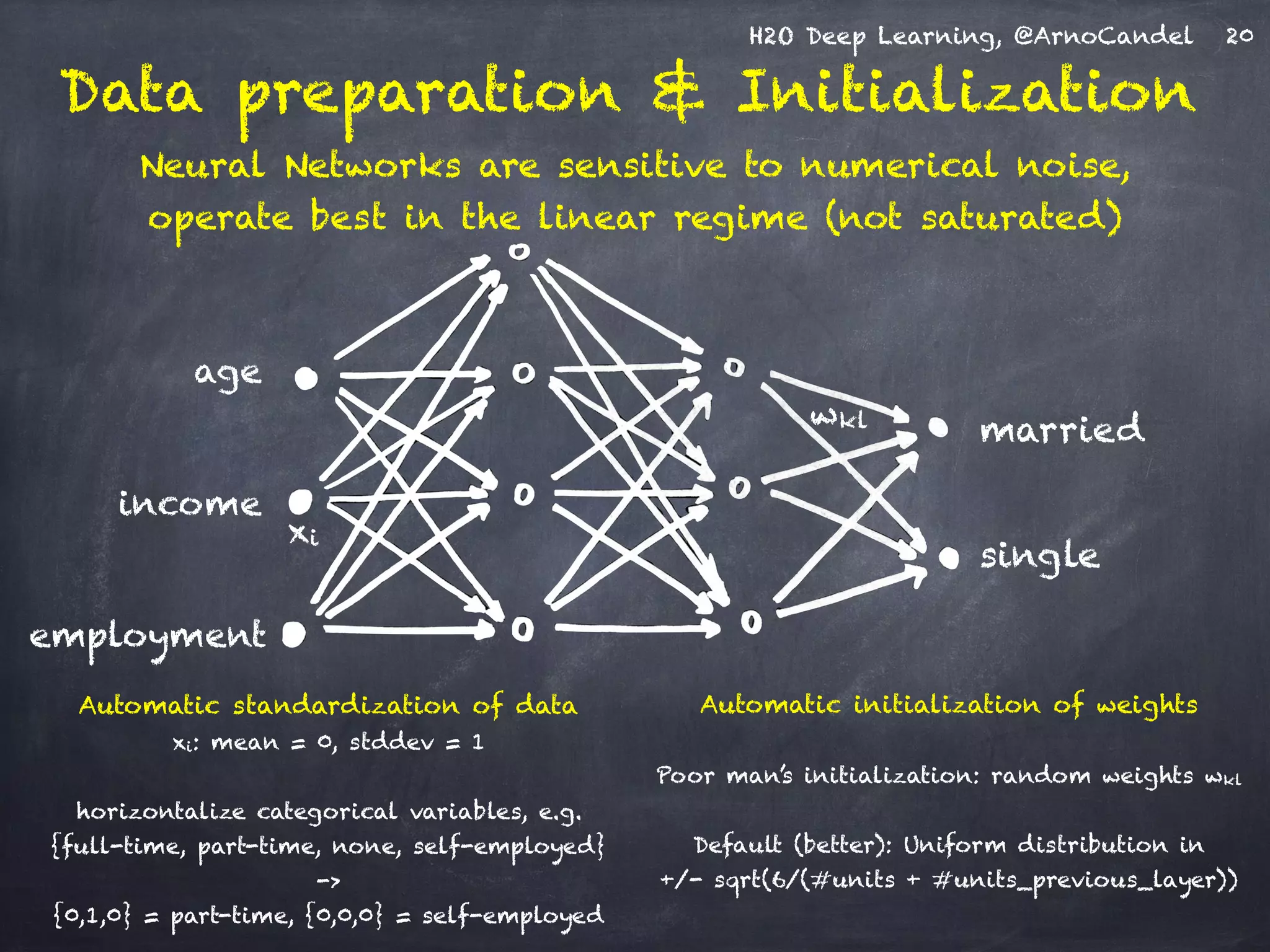
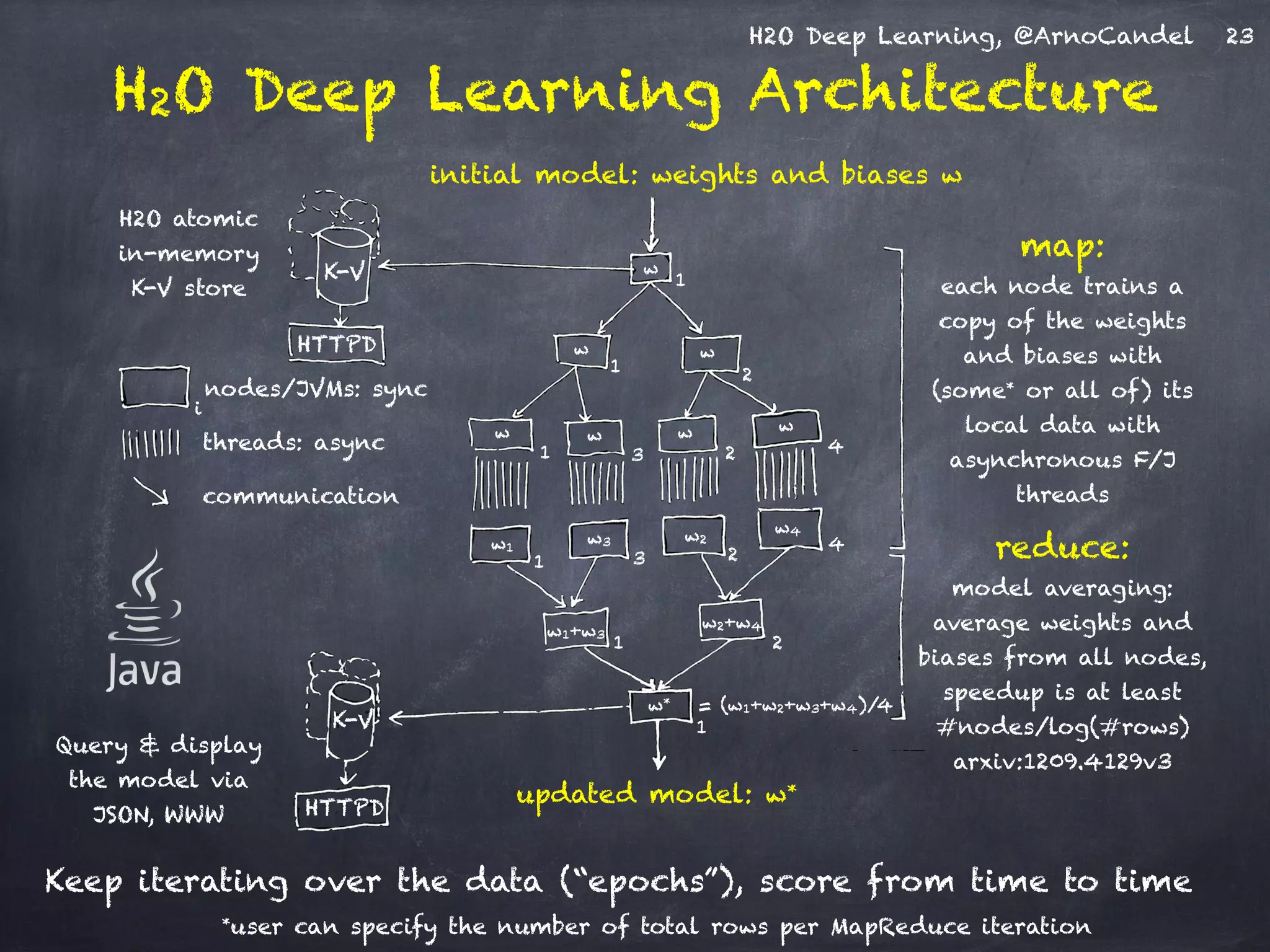
The document presents H2O, a distributed in-memory platform designed for scalable machine learning, focusing on deep learning applications. It includes insights on the architecture, functionality, and various use cases such as handwritten digit recognition, weather prediction, and text classification, highlighting H2O's ease of use and powerful performance. Additionally, it emphasizes the platform's ability to handle big data without the need for sampling, making it suitable for diverse machine learning tasks.





























![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)













































































