2
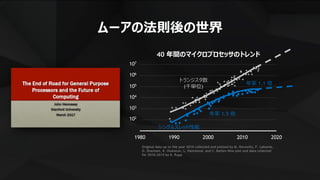
ムーアの法則後の世界
1980 1990 20002010 2020
102
103
104
105
106
107
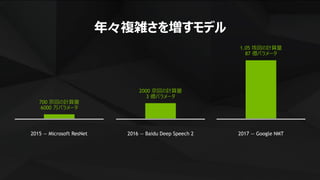
40 年間のマイクロプロセッサのトレンド
Original data up to the year 2010 collected and plotted by M. Horowitz, F. Labonte,
O. Shacham, K. Olukotun, L. Hammond, and C. Batten New plot and data collected
for 2010-2015 by K. Rupp
シングルスレッド性能
年率 1.5 倍
年率 1.1 倍
トランジスタ数
(千単位)
3.
3
1980 1990 20002010 2020
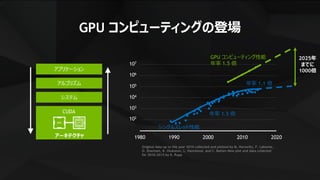
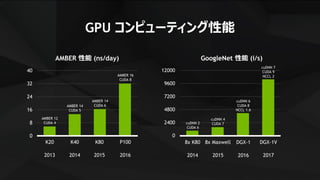
GPU コンピューティング性能
年率 1.5 倍
2025年
までに
1000倍
GPU コンピューティングの登場
Original data up to the year 2010 collected and plotted by M. Horowitz, F. Labonte,
O. Shacham, K. Olukotun, L. Hammond, and C. Batten New plot and data collected
for 2010-2015 by K. Rupp
102
103
104
105
106
107
シングルスレッド性能
年率 1.5 倍
年率 1.1 倍
アプリケーション
システム
アルゴリズム
CUDA
アーキテクチャ
6
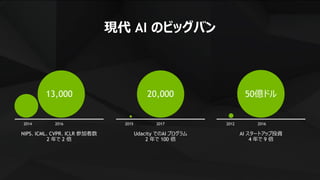
現代の AI のビッグバン
Auto
Encoders
GANLSTM
IDSIA
CNNon GPU
Stanford &
NVIDIA
Large-scale
DNN on GPU
U Toronto
AlexNet
on GPU
CaptioningNVIDIA BB8 Style TransferBRETTImageNet
Google Photo
Arterys
FDA Approved AlphaGo
Super
Resolution Deep Voice
Baidu
DuLight
NMT
Superhuman
ASR
Reinforcement
Learning
Transfer
Learning
30
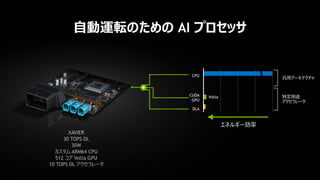
自動運転のための AI プロセッサ
XAVIER
30TOPS DL
30W
カスタム ARM64 CPU
512 コア Volta GPU
10 TOPS DL アクセラレータ
汎用アーキテクチャ
特定用途
アクセラレータ
エネルギー効率
CPU
FPGA
CUDA
GPU
DLA
Pascal
Volta
31.
31
自動運転のための AI プロセッサ
XAVIER
30TOPS DL
30W
カスタム ARM64 CPU
512 コア Volta GPU
10 TOPS DL アクセラレータ
汎用アーキテクチャ
特定用途
アクセラレータ
エネルギー効率
CPU
CUDA
GPU
DLA
Volta
+
32.
32
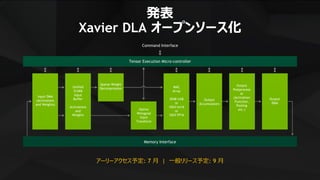
発表
Xavier DLA オープンソース化
アーリーアクセス予定:7 月 | 一般リリース予定: 9 月
Command Interface
Tensor Execution Micro-controller
Memory Interface
Input DMA
(Activations
and Weights)
Unified
512KB
Input
Buffer
Activations
and
Weights
Sparse Weight
Decompression
Native
Winograd
Input
Transform
MAC
Array
2048 Int8
or
1024 Int16
or
1024 FP16
Output
Accumulators
Output
Postprocess
or
(Activation
Function,
Pooling
etc.)
Output
DMA









![13
新開発 Tensor コア
CUDA Tensor 演算命令 及び データフォーマット
4x4 行列処理配列
D[FP32] = A[FP16] * B[FP16] + C[FP32]
ディープラーニングに最適化
アクティベーション入力 重み入力 出力結果](https://image.slidesharecdn.com/02dli2017nagoyahayashi-170521051359/85/GTC-2017-13-320.jpg)


























![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)






































