⾃⼰紹介
l 名前:秋葉 拓哉
l Twitter, GitHub:@iwiwi
l 経歴:東⼤今井研 (博⼠) → NII (特任助教) → PFN (リサーチャー, 7/1 ⼊社!)
l 今年の戦歴:KDDʼ16, IJCAIʼ16, VLDBʼ16×2, CIKMʼ16×2
仕事内容
l これまで:⼤規模グラフのデータマイニング
l PFN:深層学習関係
今⽇は両⽅関係ありそうな論⽂を選んでみました
2
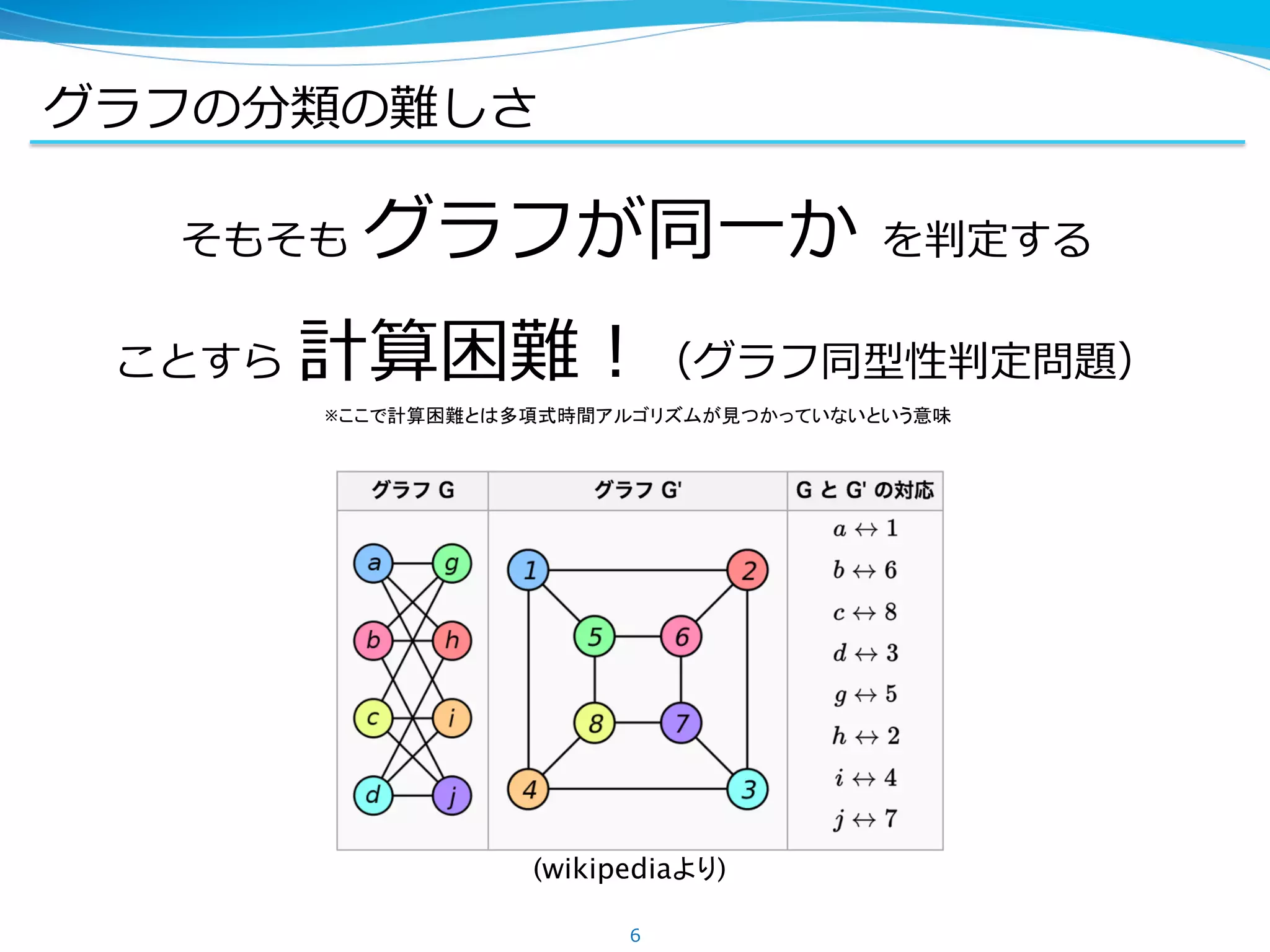
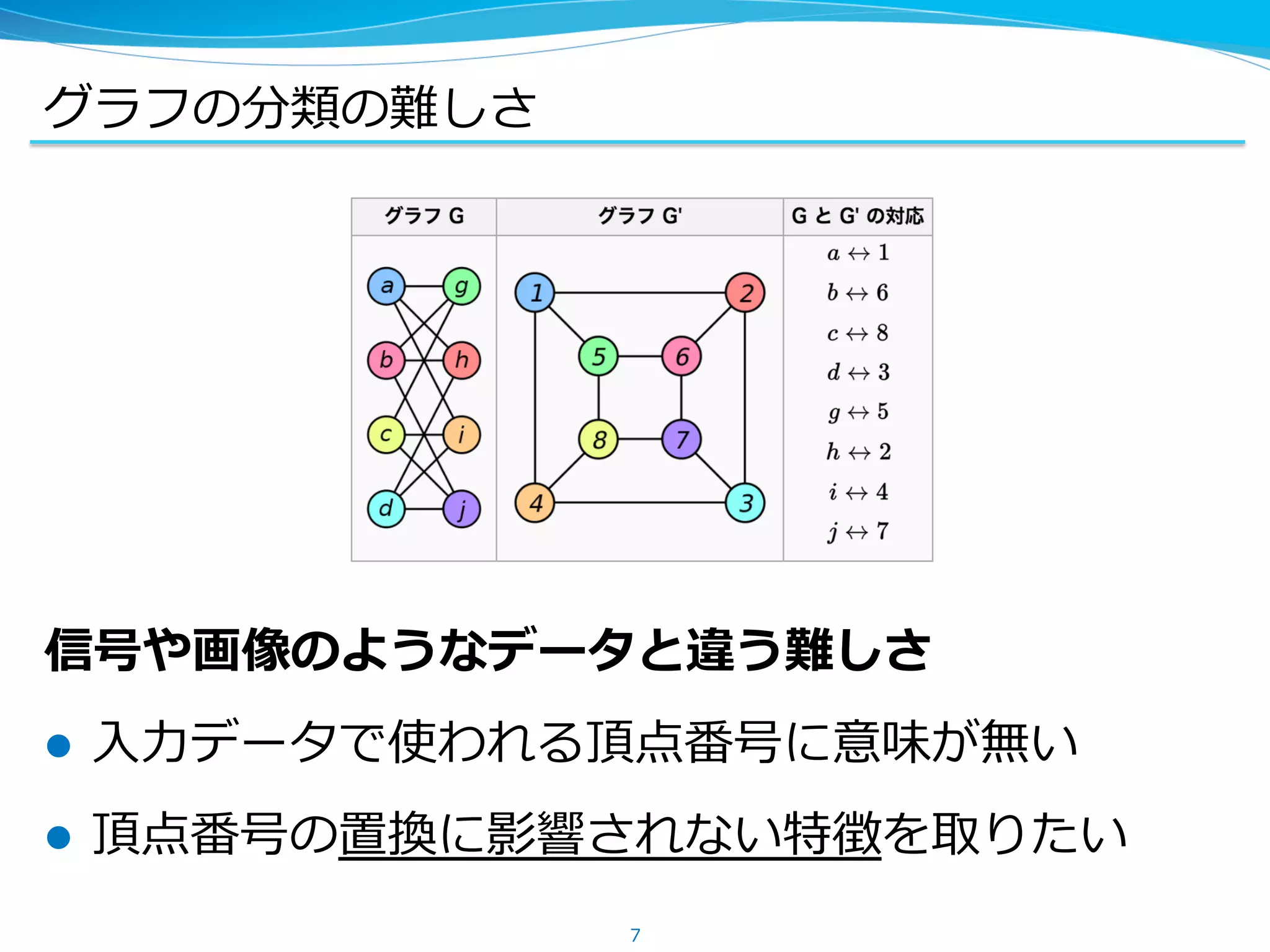
3.
論⽂概要
グラフを CNN に突っ込む
がほぼ全て!
課題
l でも、突っ込み⽅が難しい
l 似た構造が似た突っ込まれ⽅をされてほしい
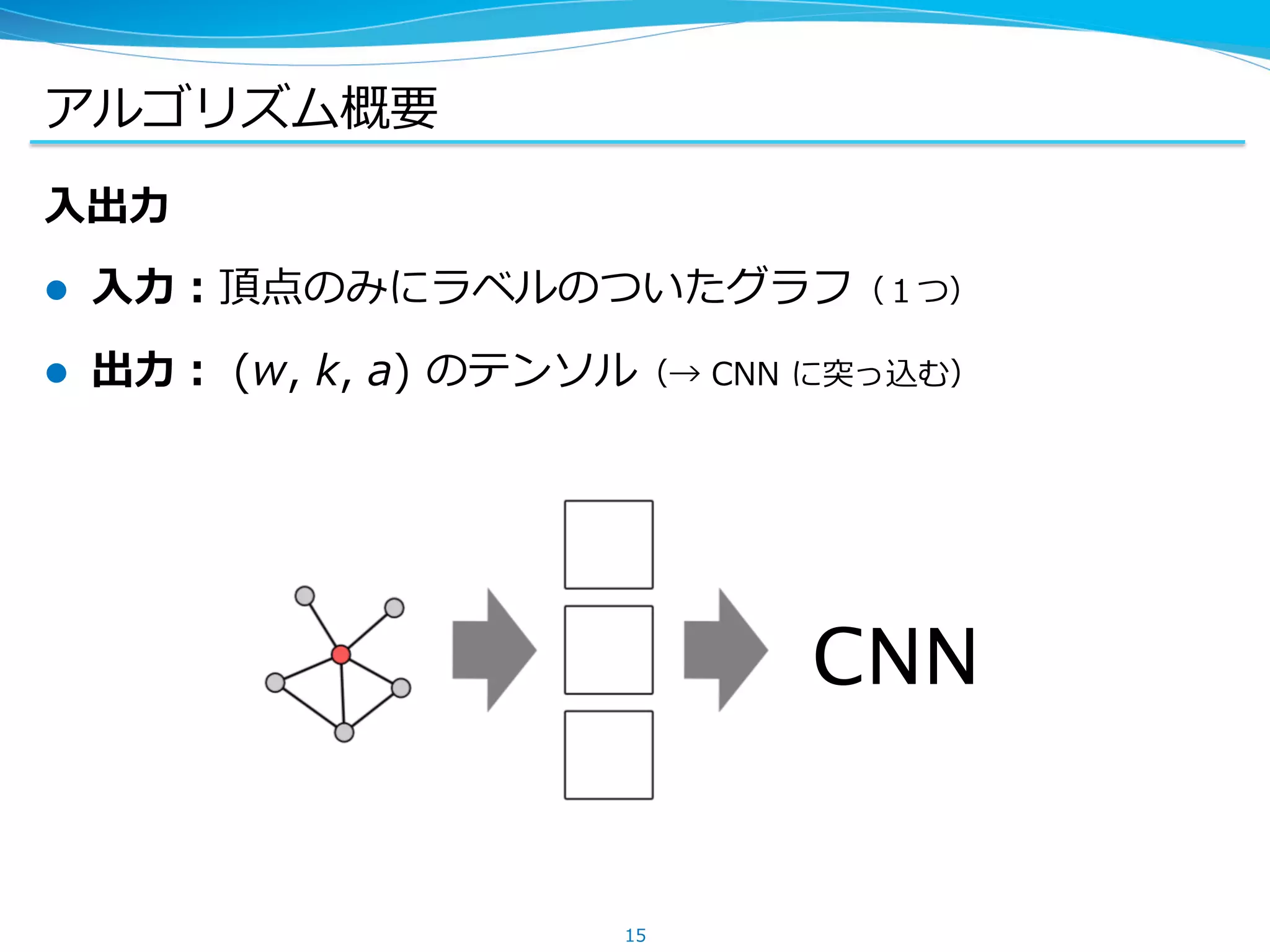
アルゴリズム概要
l 頂点を決まった個数選んで、その近傍を取り出す
l ラベリングによる特徴付けを使って順序を付ける
3
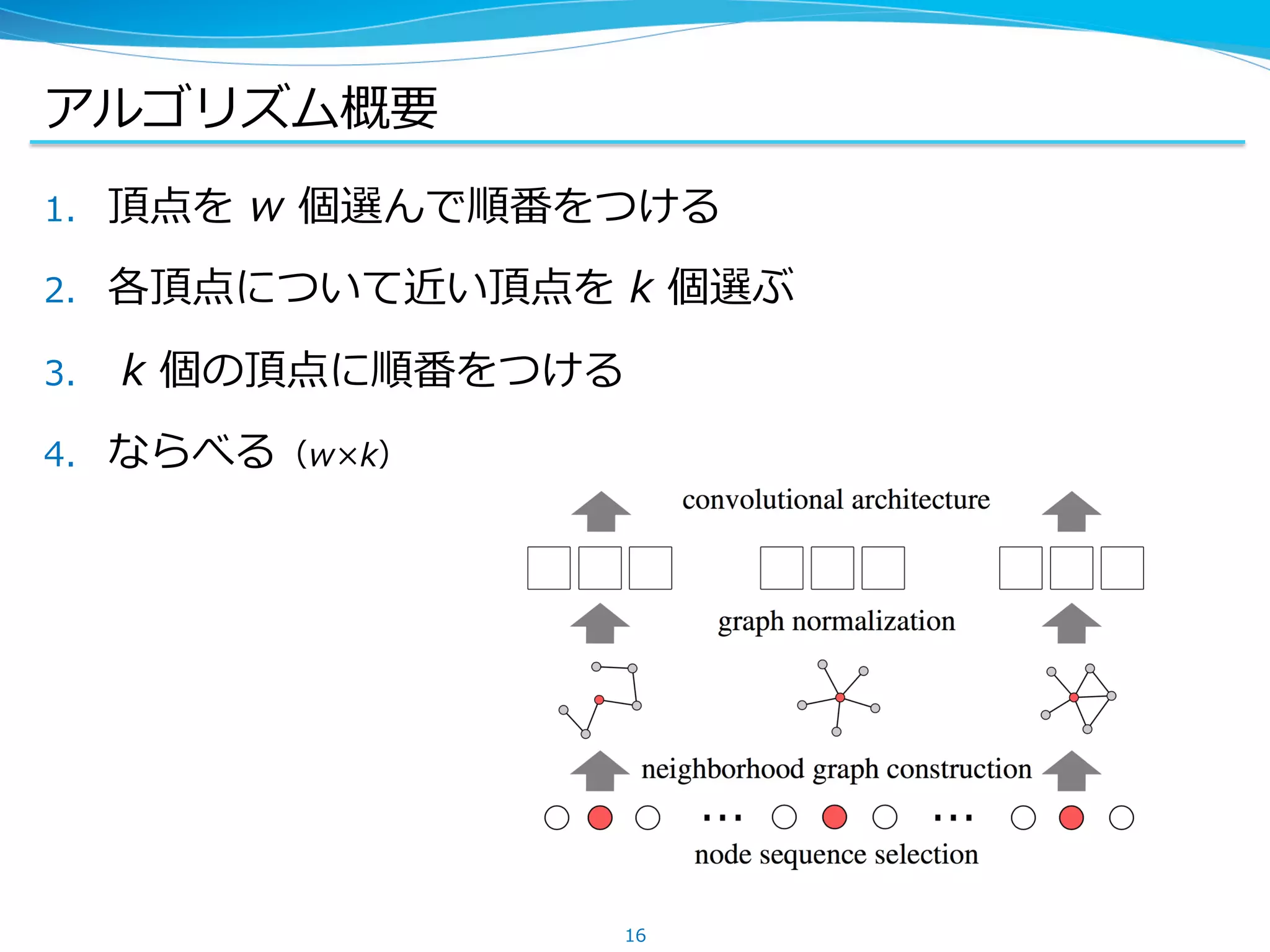
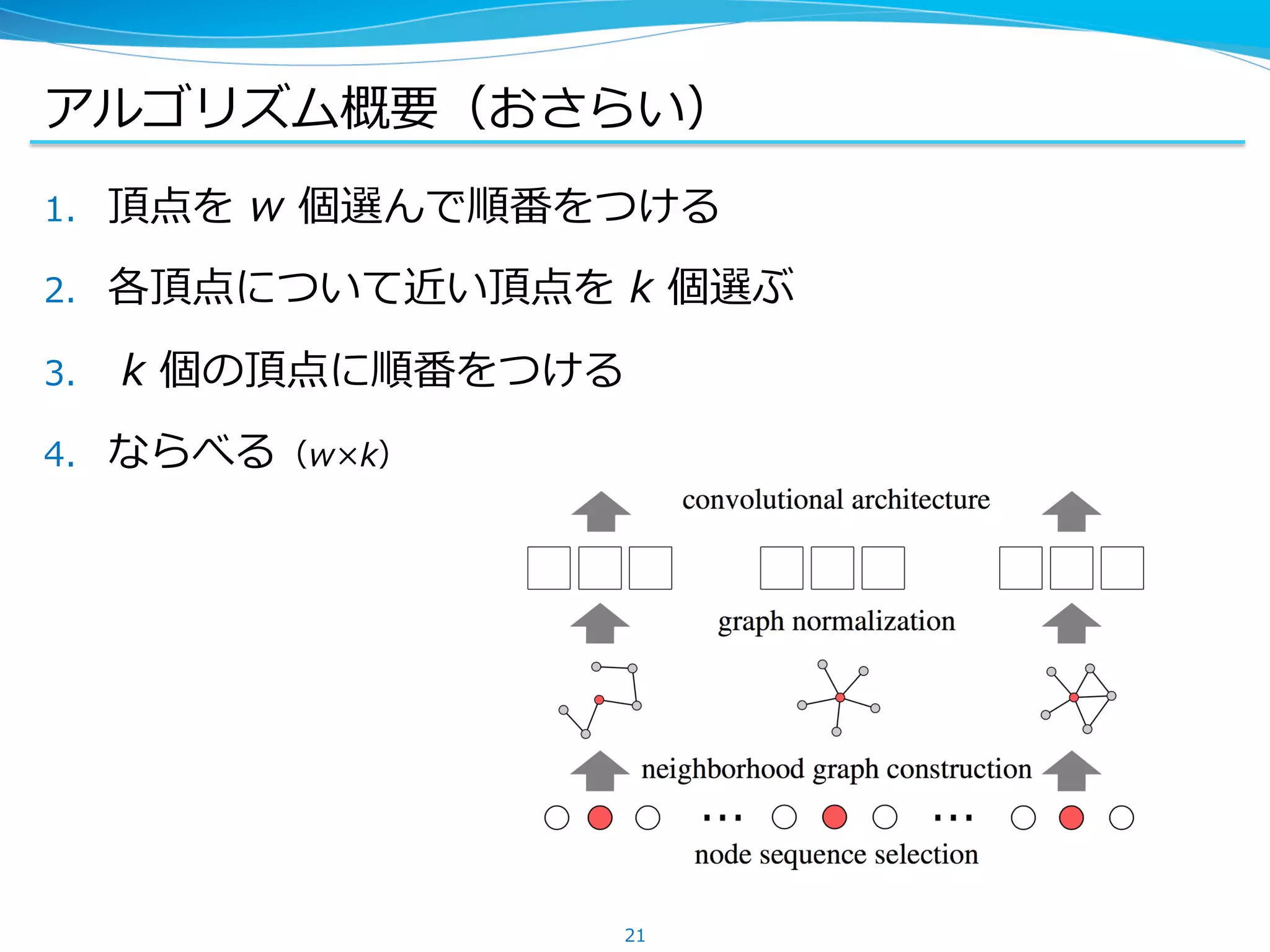
アルゴリズム概要
1. 頂点を w個選んで順番をつける
2. 各頂点について近い頂点を k 個選ぶ
3. k 個の頂点に順番をつける
4. ならべる(w×k)
16
17.
ステップ1:頂点を w 個選択し順番をつける
Weisfeiler-Lehman(WL) のラベルを使う
1. WL のラベルで頂点をソート
2. ⼩さいやつから順に w 個を選択
同じような近傍構造を持つ頂点を
テンソル内の同じような位置に持ってきたい。
少なくとも WL ラベルが同じ頂点は
相対的な位置として近い場所に来る。
17
18.
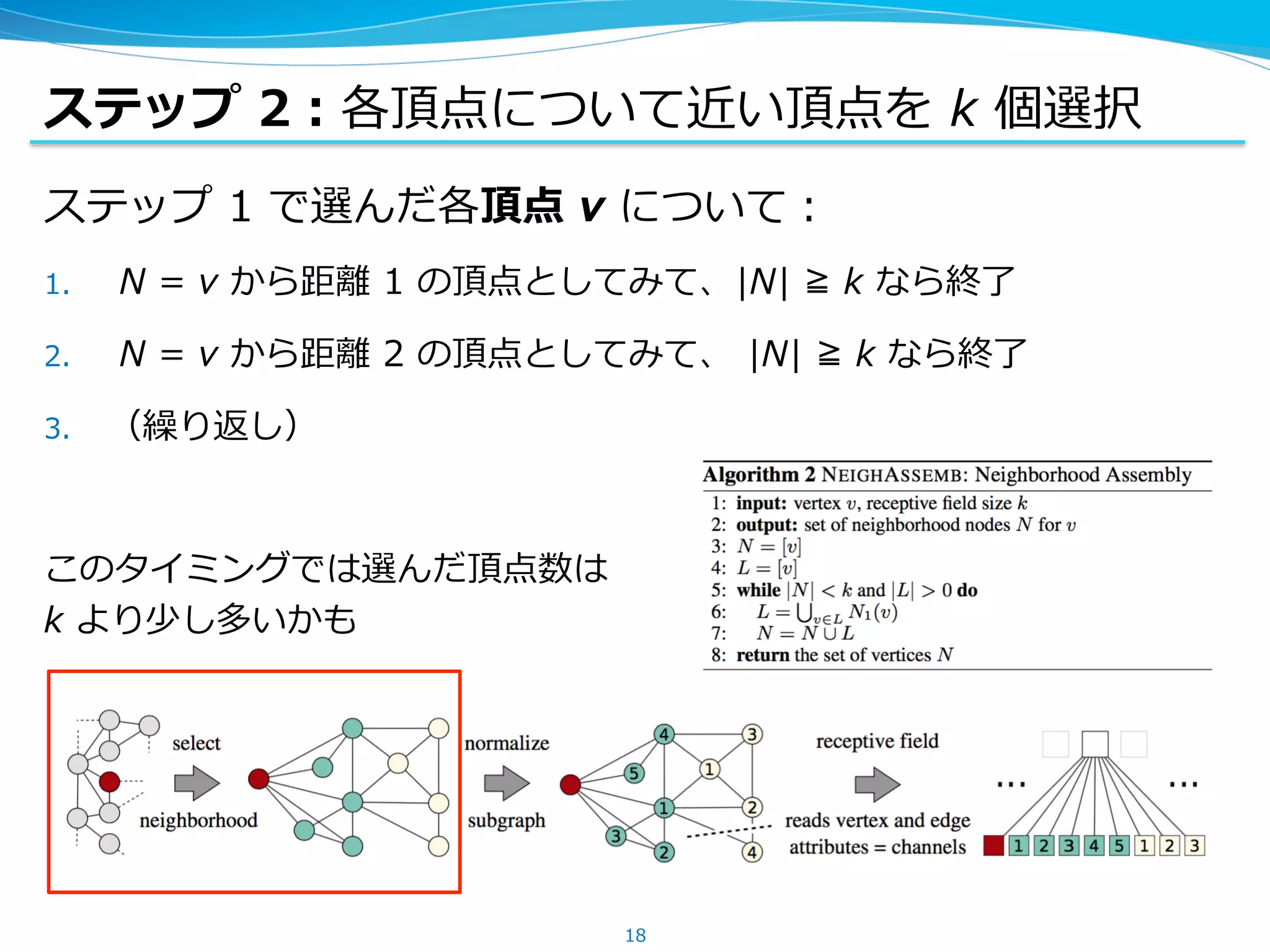
ステップ 2:各頂点について近い頂点を k個選択
ステップ 1 で選んだ各頂点 v について:
1. N = v から距離 1 の頂点としてみて、|N| ≧ k なら終了
2. N = v から距離 2 の頂点としてみて、 |N| ≧ k なら終了
3. (繰り返し)
このタイミングでは選んだ頂点数は
k より少し多いかも
18
19.
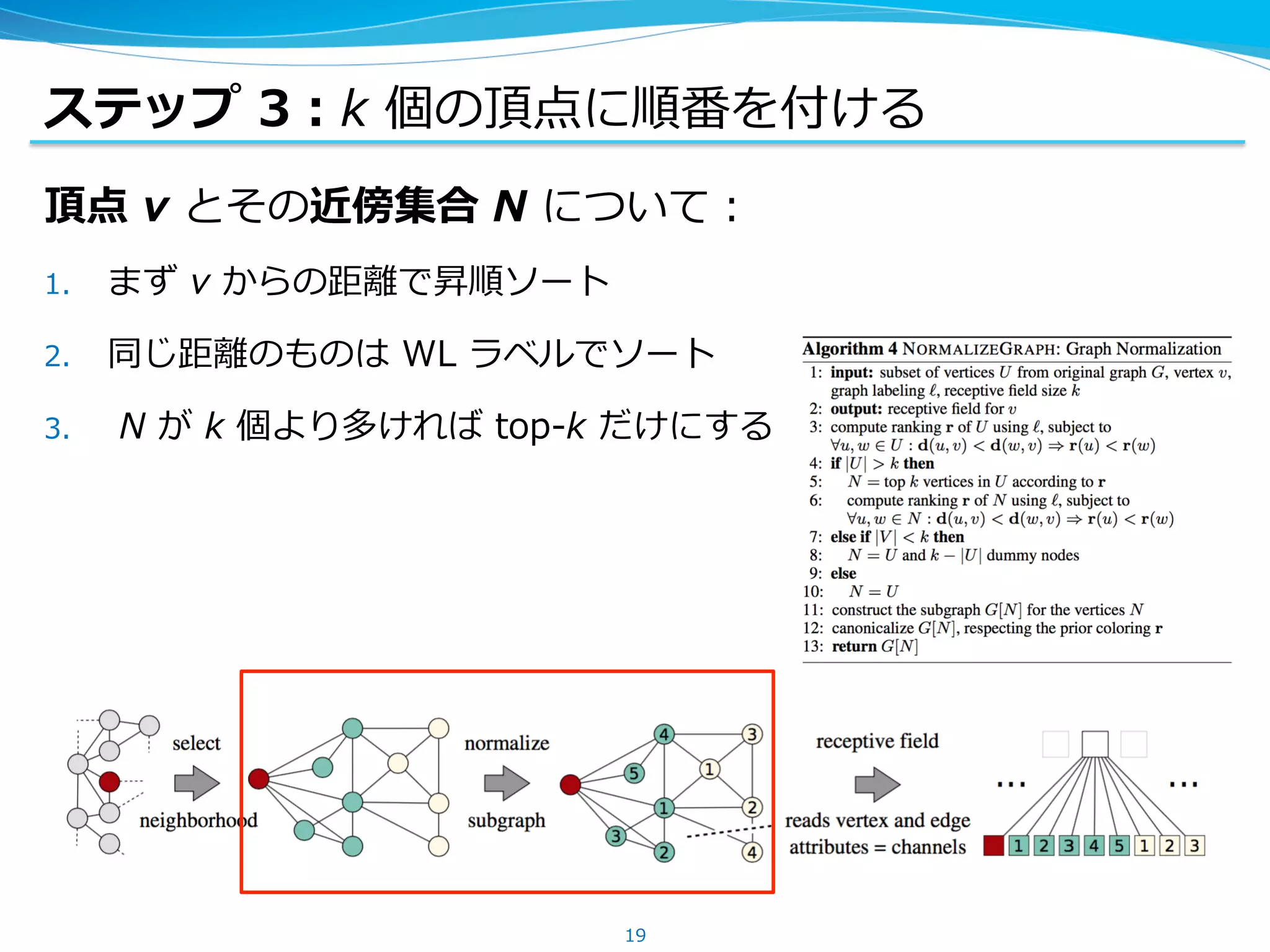
ステップ 3:k 個の頂点に順番を付ける
頂点v とその近傍集合 N について:
1. まず v からの距離で昇順ソート
2. 同じ距離のものは WL ラベルでソート
3. N が k 個より多ければ top-k だけにする
19
20.
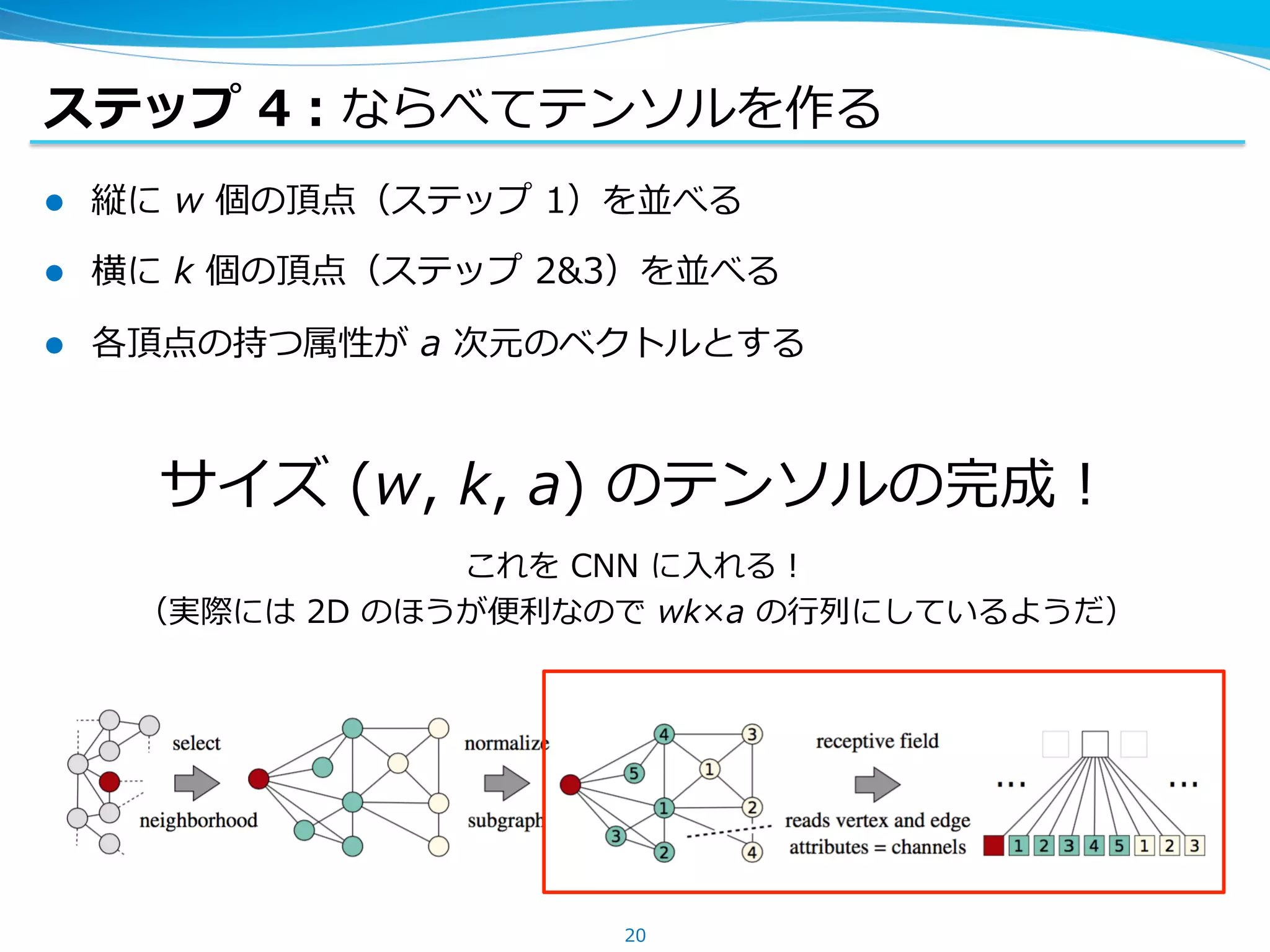
ステップ 4:ならべてテンソルを作る
l 縦にw 個の頂点(ステップ 1)を並べる
l 横に k 個の頂点(ステップ 2&3)を並べる
l 各頂点の持つ属性が a 次元のベクトルとする
サイズ (w, k, a) のテンソルの完成!
これを CNN に⼊れる!
(実際には 2D のほうが便利なので wk×a の⾏列にしているようだ)
20
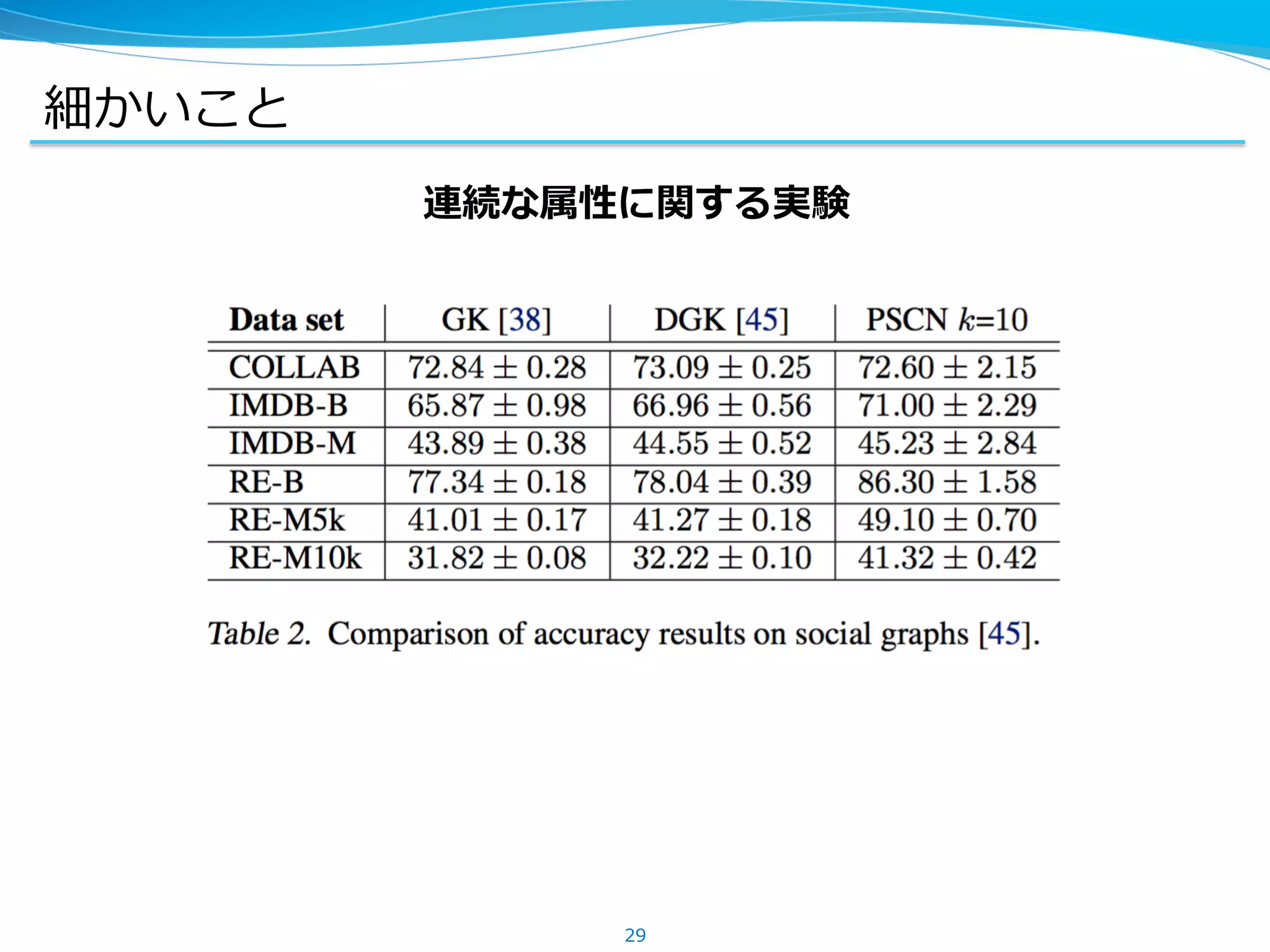
細かいこと
l ラベリングは Weisfeiler-Lehmanでなくても良い
– 類似した頂点が類似した値を取るような指標であれば良い
– 次数、中⼼性、PageRank, ......
l 同じラベルになった頂点の tie-breaking には Nauty を使う
– Nauty はグラフ同型性判定関連のツール
31
32.
関連研究
l Halting inRandom Walk Kernels (NIPSʼ15)
– Random Walk Kernel が理論的に微妙という話
– 阪⼤の杉⼭さん
l DeepWalk: Online Learning of Social Representations (KDDʼ14)
l node2vec: Scalable Feature Learning for Networks (KDDʼ16)
– ソーシャルグラフのような⼤きなグラフが 1 つある状況
– 各頂点の構造的な⽴ち位置を表すベクトルを出⼒する
32
33.
関連研究
l Efficient Top-kShortest-path Distance Queries on Large Networks
by Pruned Landmark Labeling (AAAIʼ15)
– 秋葉、林くん、則さん、岩⽥さん、吉⽥さんの研究(宣伝)
– グラフ上の 2 点間の関係を表現するベクトルを計算
– SVM に突っ込んでグラフの構造を予測
33
まとめ
グラフを CNN に突っ込む
課題
l 似た構造が似た突っ込まれ⽅になるようにテンソルにする
アルゴリズム
l 既存の特徴付け (Weisfeiler-Lehman) で順序を付けて並べる
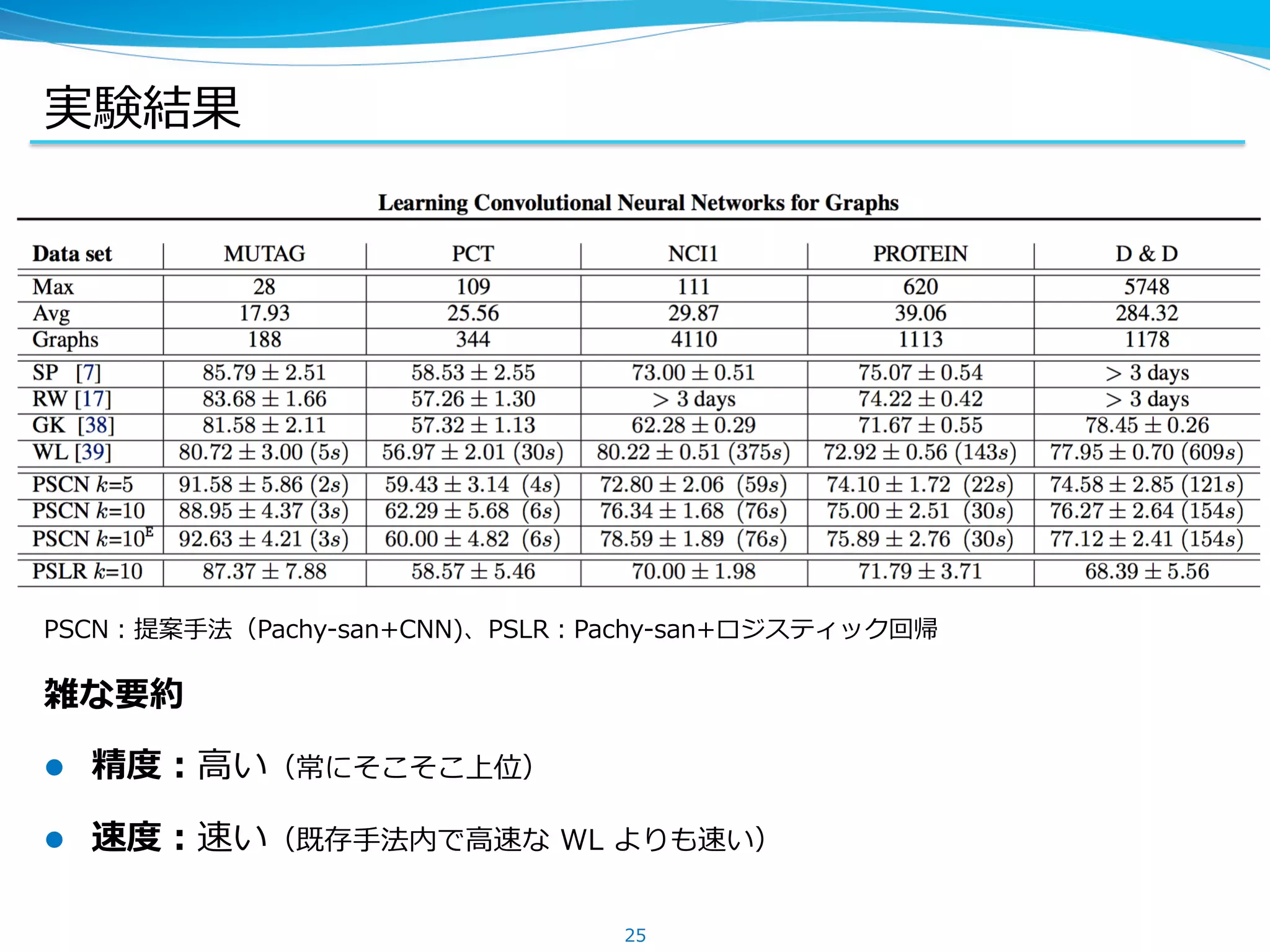
実験結果
l ⾼精度かつ⾼速
35
36.
個⼈的な感想
l 前処理が多く、Weisfeiler-Lehman ラベリングにかなり頼っている
– 特徴の抽出はできるだけ NN に移譲したいが、グラフはやはり難しい……
– とはいえこれまでのカーネルよりは NN に移譲できているということか
l ラベリングの影響がどの程度なのかかなり気になる
– 著者いわく媒介中⼼性を使ってもほぼ同様だったらしい
– そもそもランダム置換と⽐較してほしい
l とはいえ悪くない精度は出ているし、NN の枠組みの中でグラフも
他のデータと統合的に扱えるようになるのはとても良い
36





![グラフの分類
想定する状況
l グラフが⼤量にある
l 分類をしたい
応⽤例
1. 化学化合物の作⽤を分類する
2. 分⼦(タンパク質)の空間構造から酵素か否かを分類する
3. ⽂や⽂章の構造を分類する
本論⽂の実験では 1 と 2 のデータが使われています。
5
[Ralaivola+, 2005, Fig. 2]](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-5-2048.jpg)

![既存研究:Weisfeiler-Lehman Graph Kernel
9
[Shervashidze+, JMLR’11, Fig. 2]](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-9-2048.jpg)
![既存研究:Weisfeiler-Lehman Graph Kernel
10
[Shervashidze+, JMLR’11, Fig. 2]
近傍のラベルを集める](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-10-2048.jpg)
![既存研究:Weisfeiler-Lehman Graph Kernel
11
[Shervashidze+, JMLR’11, Fig. 2]
ラベルを振り直す](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-11-2048.jpg)
![既存研究:Weisfeiler-Lehman Graph Kernel
12
[Shervashidze+, JMLR’11, Fig. 2]
頂点のラベルを新しくしてしまう](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-12-2048.jpg)
![既存研究:Weisfeiler-Lehman Graph Kernel
13
[Shervashidze+, JMLR’11, Fig. 2]
これを繰り返した
最終的なグラフ
multiset
とみなす](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-13-2048.jpg)








![細かいこと
l Weisfeiler-Lehman でグラフの同型性判定って解けてない?
→ 解けません!
30
[Shervashidze+, JMLR’11, Fig. 1]](https://image.slidesharecdn.com/2016-07-21icml-160721045555/75/Learning-Convolutional-Neural-Networks-for-Graphs-30-2048.jpg)











![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/2017-06-22-170623004409-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)


























