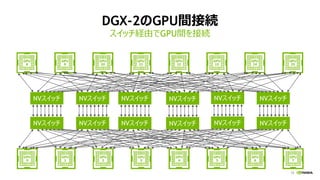
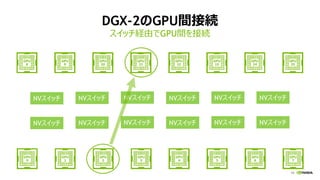
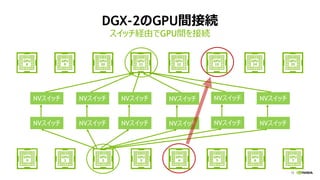
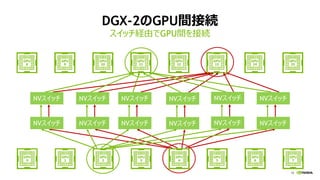
このスライドは、2018 年 4 月 24 日 (火) にベルサール高田馬場にて開催の NVIDIA Deep Learning Seminar 2018における、エヌビディア シニアデベロッパーテクノロジーエンジニア 成瀬 彰による「DGX-2 を取り巻く GPU 最新技術情報」の資料です。




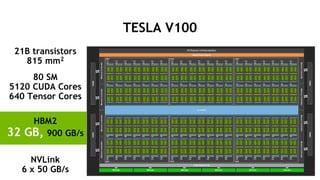
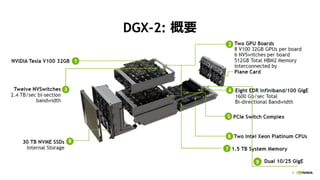

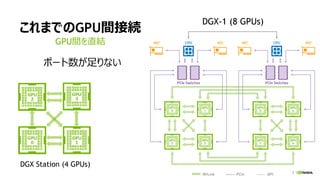




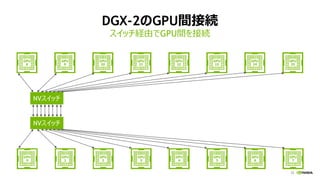
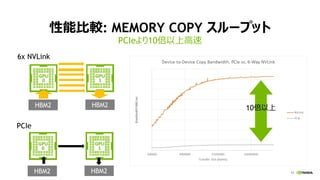
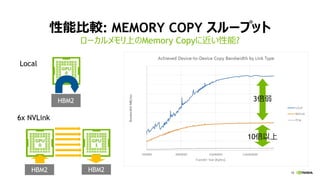

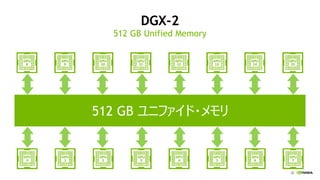


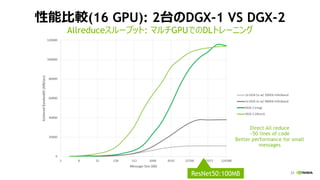
















































![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)



























