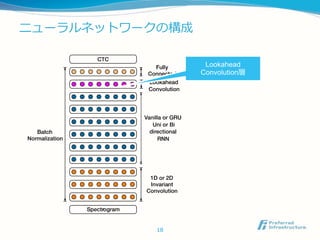
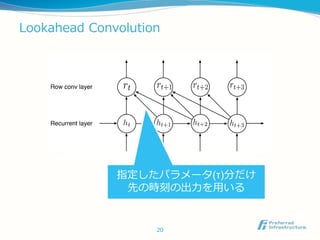
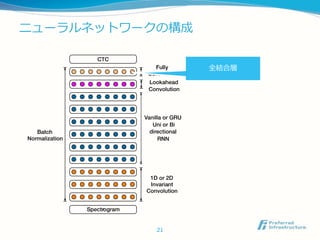
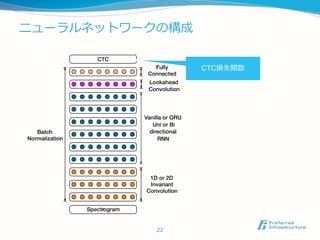
Lookahead Convolution
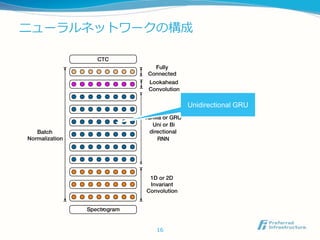
BidirectionalGRUは精度面では良いが、online, 低レイテ
ンシでの実行ができない
19
Here W
(6)
k and b
(6)
k denote thek’th column of the weight matrix and k’th bias, respectively.
Oncewehavecomputed aprediction for P(ct |x), wecomputetheCTC loss[13] L(ˆy, y) to me
he error in prediction. During training, we can evaluate the gradient r ˆy L(ˆy, y) with respe
he network outputs given the ground-truth character sequence y. From this point, computin
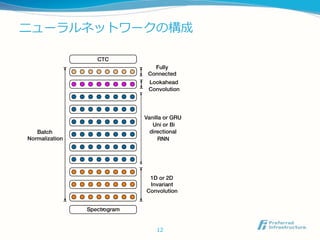
gradient with respect to all of the model parameters may bedone via back-propagation throug
est of thenetwork. WeuseNesterov’sAccelerated gradient method for training [41].3
t1 t2 tn
どの段階の値を計算するにもt1
からtnのすべての入力が必要
デコーダーのスコアリング
25
nesecharacters.
At inference time,CTC modelsarepaired awith langua
model trained on abigger corpusof text. Weuseaspeci
ized beam search (Hannun et al., 2014b) to find the tra
scription y that maximizes
Q(y) = log(pRNN(y|x)) + ↵ log(pLM(y)) + βwc(y)
where wc(y) is the number of words (English) or chara
ters (Chinese) in the transcription y. The weight ↵ co
trols the relative contributions of the language model a
theCTCnetwork. Theweight β encouragesmorewords
thetranscription. Theseparameters aretuned on aheld o
トランスクリプション
文字列のスコア
ニューラルネットワークが出
力する文字列の生起確率
言語モデルによるスコア
word count
α, βは学習データに応じて変更する
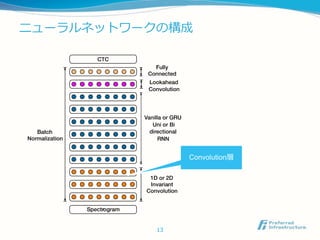
(Sequence-wise) Batch Normalization
正則化に(Sequence-wise) Batch Normalizationを用いる
27
k k
Oncewehavecomputed aprediction for P(ct |x), wecomputetheCTC loss[13] L(ˆy, y) to mea
he error in prediction. During training, we can evaluate the gradient r ˆy L(ˆy, y) with respe
he network outputs given the ground-truth character sequence y. From this point, computing
radient with respect to all of the model parameters may bedone via back-propagation through
est of thenetwork. WeuseNesterov’sAccelerated gradient method for training [41].3
下位層からの入力にのみBatch
Normalizationを適用する
水平方向の入力にはBatch
Normalizationを適用しない
29.
SortaGrad
Curriculum learning
-CTCの学習初期はblank文字列を出力しがちで損失がとても大き
くなりやすい
- 学習データを系列の長さでソートし、短い音声データから学習
を行う
28
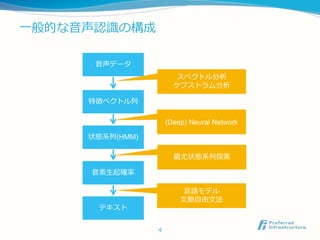
Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin
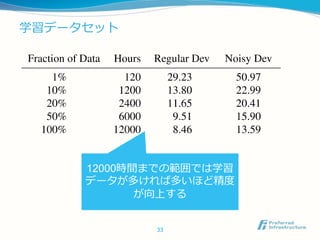
Architecture Baseline BatchNorm GRU
5-layer, 1 RNN 13.55 14.40 10.53
5-layer, 3 RNN 11.61 10.56 8.00
7-layer, 5 RNN 10.77 9.78 7.79
9-layer, 7 RNN 10.83 9.52 8.19
9-layer, 7 RNN
no SortaGrad 11.96 9.78
Table 1: Comparison of WER on a development set as we
vary depth of RNN, application of BatchNorm and Sorta-
Grad, and type of recurrent hidden unit. All networkshave
50 100 150 200
Iteration (⇥10
20
30
40
50
60
Cost
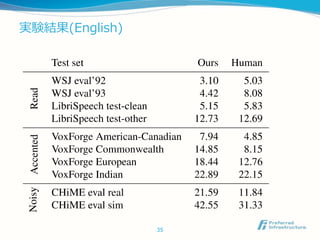
SortaGradを用いない場合
精度が下がっている
補足: Arxiv版
https://arxiv.org/abs/1512.02595に掲載されていてICML
版に掲載されていないこと
- Striding (in convolution)
- Language Modeling
- Scalability and Data parallelism
- Memory allocation
- Node and cluster architecture
- GPU Implementation of CTC Loss Function
- Batch Dispatch
- Data Augmentation
- Beam Search
38














![Lookahead Convolution
Bidirectional GRUは精度面では良いが、online, 低レイテ
ンシでの実行ができない
19
Here W
(6)
k and b
(6)
k denote thek’th column of the weight matrix and k’th bias, respectively.
Oncewehavecomputed aprediction for P(ct |x), wecomputetheCTC loss[13] L(ˆy, y) to me
he error in prediction. During training, we can evaluate the gradient r ˆy L(ˆy, y) with respe
he network outputs given the ground-truth character sequence y. From this point, computin
gradient with respect to all of the model parameters may bedone via back-propagation throug
est of thenetwork. WeuseNesterov’sAccelerated gradient method for training [41].3
t1 t2 tn
どの段階の値を計算するにもt1
からtnのすべての入力が必要](https://image.slidesharecdn.com/icmldeepspeech2-160721050154/85/Icml-deep-speech2-20-320.jpg)




![(Sequence-wise) Batch Normalization
正則化に(Sequence-wise) Batch Normalizationを用いる
27
k k
Oncewehavecomputed aprediction for P(ct |x), wecomputetheCTC loss[13] L(ˆy, y) to mea
he error in prediction. During training, we can evaluate the gradient r ˆy L(ˆy, y) with respe
he network outputs given the ground-truth character sequence y. From this point, computing
radient with respect to all of the model parameters may bedone via back-propagation through
est of thenetwork. WeuseNesterov’sAccelerated gradient method for training [41].3
下位層からの入力にのみBatch
Normalizationを適用する
水平方向の入力にはBatch
Normalizationを適用しない](https://image.slidesharecdn.com/icmldeepspeech2-160721050154/85/Icml-deep-speech2-28-320.jpg)











![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)




























