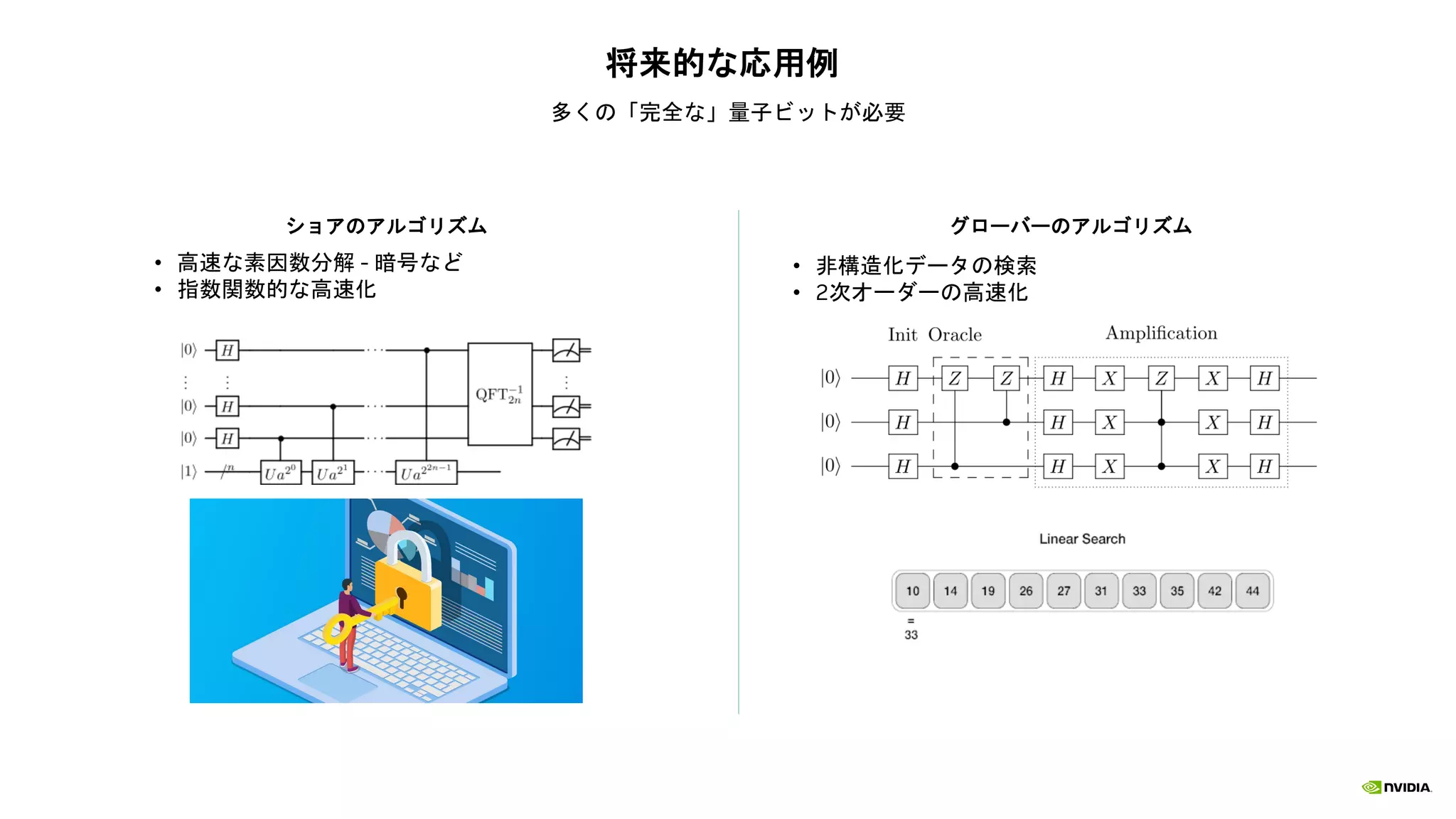
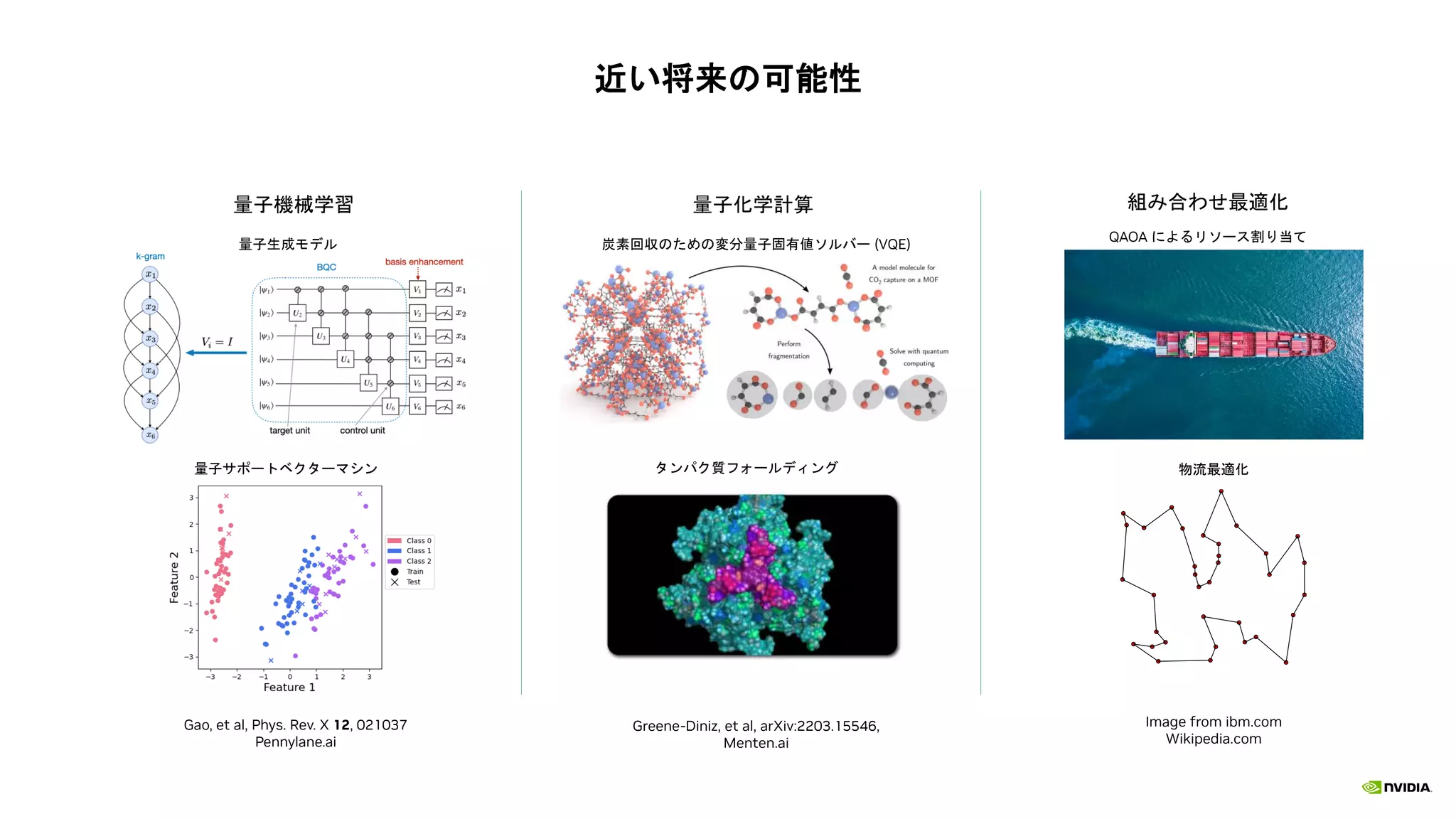
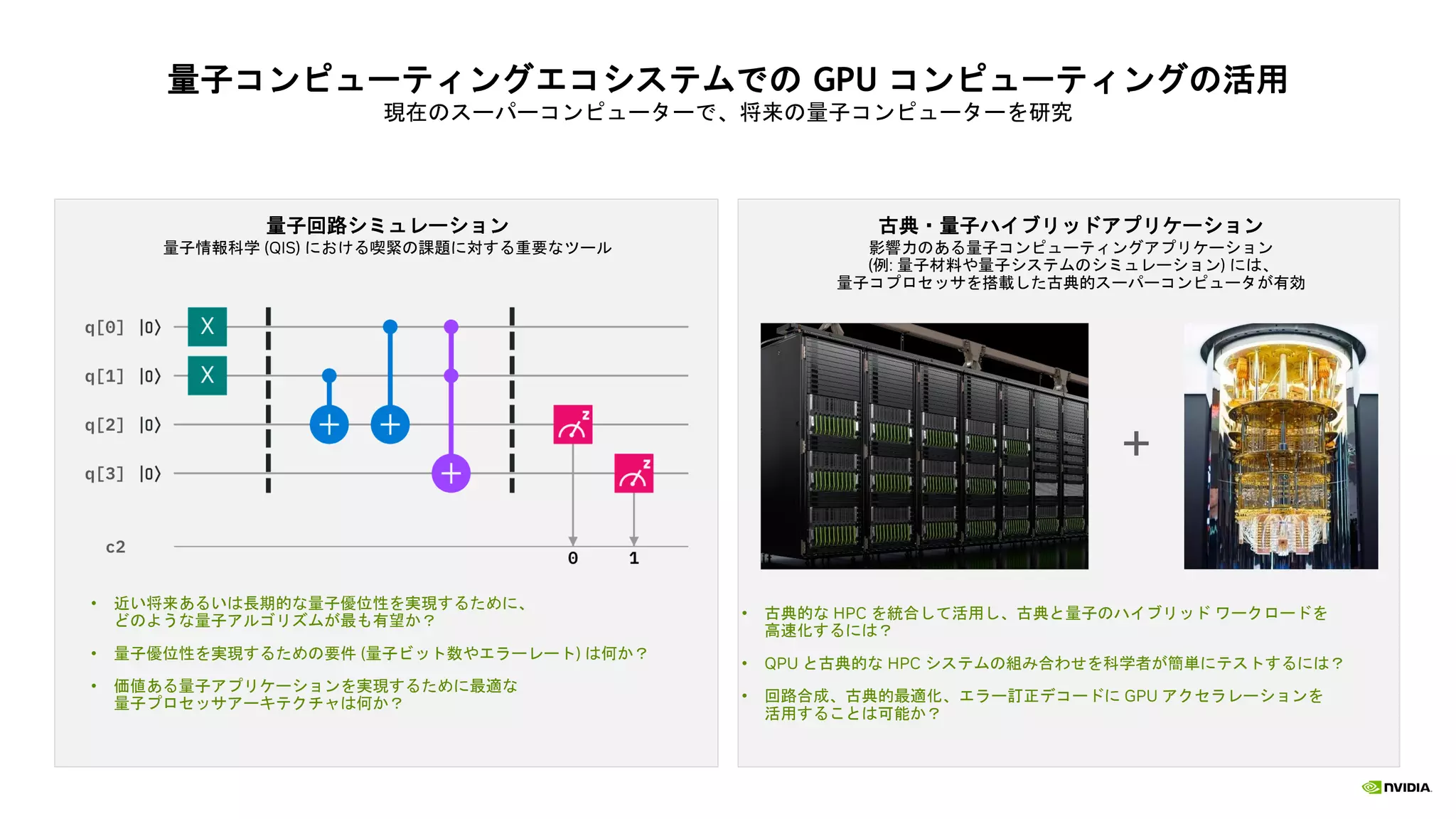
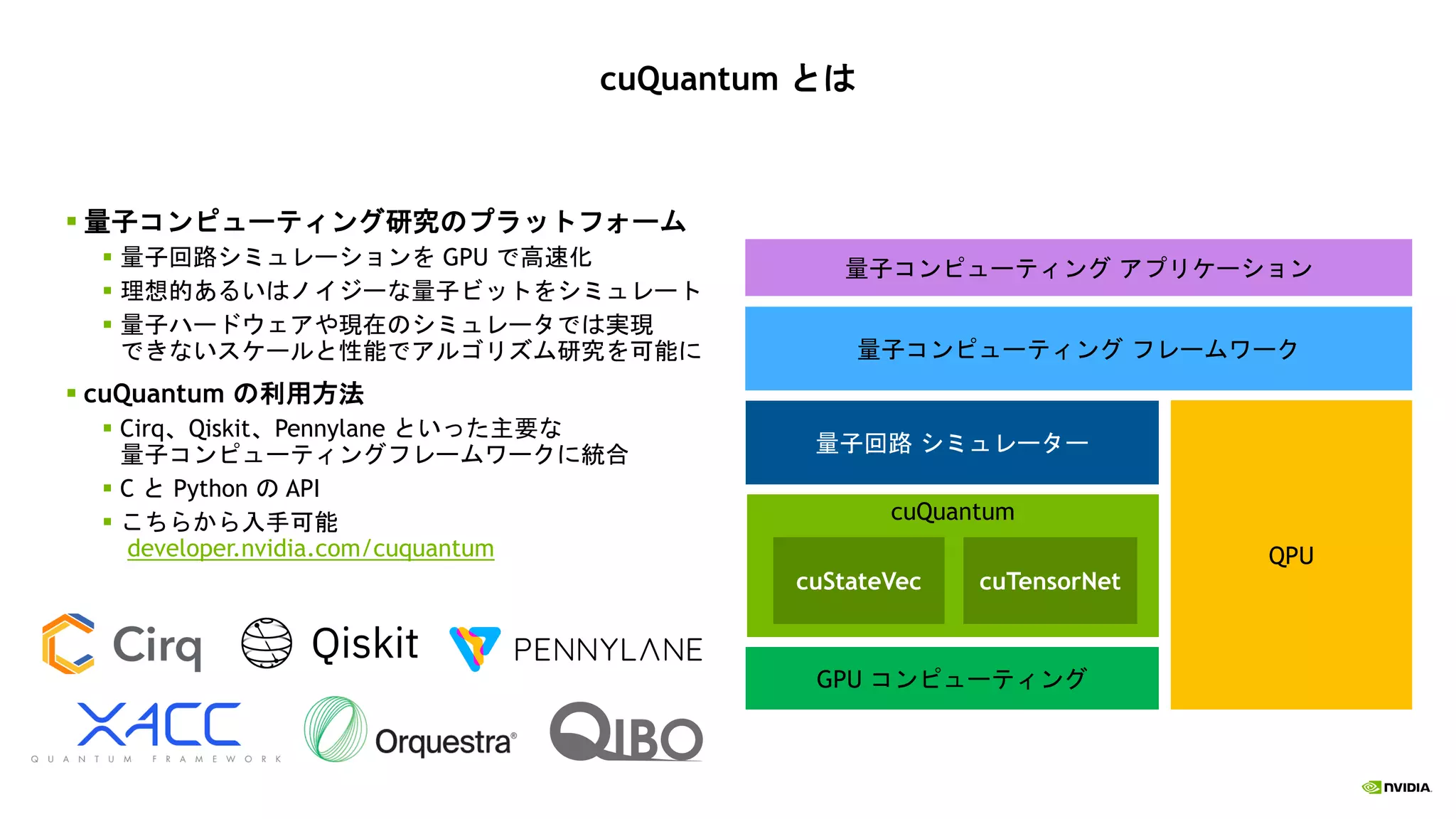
様々なユースケースやユーザーを高速化
Faster Time-to-solution FasterTime-to-solution Faster Time-to-solution
More Circuit Depth Lower Costs More Qubits
Faster Quantum Algorithm for Physics-ML New PennyLane Integration via AWS Braket Orquestra Platform Integration
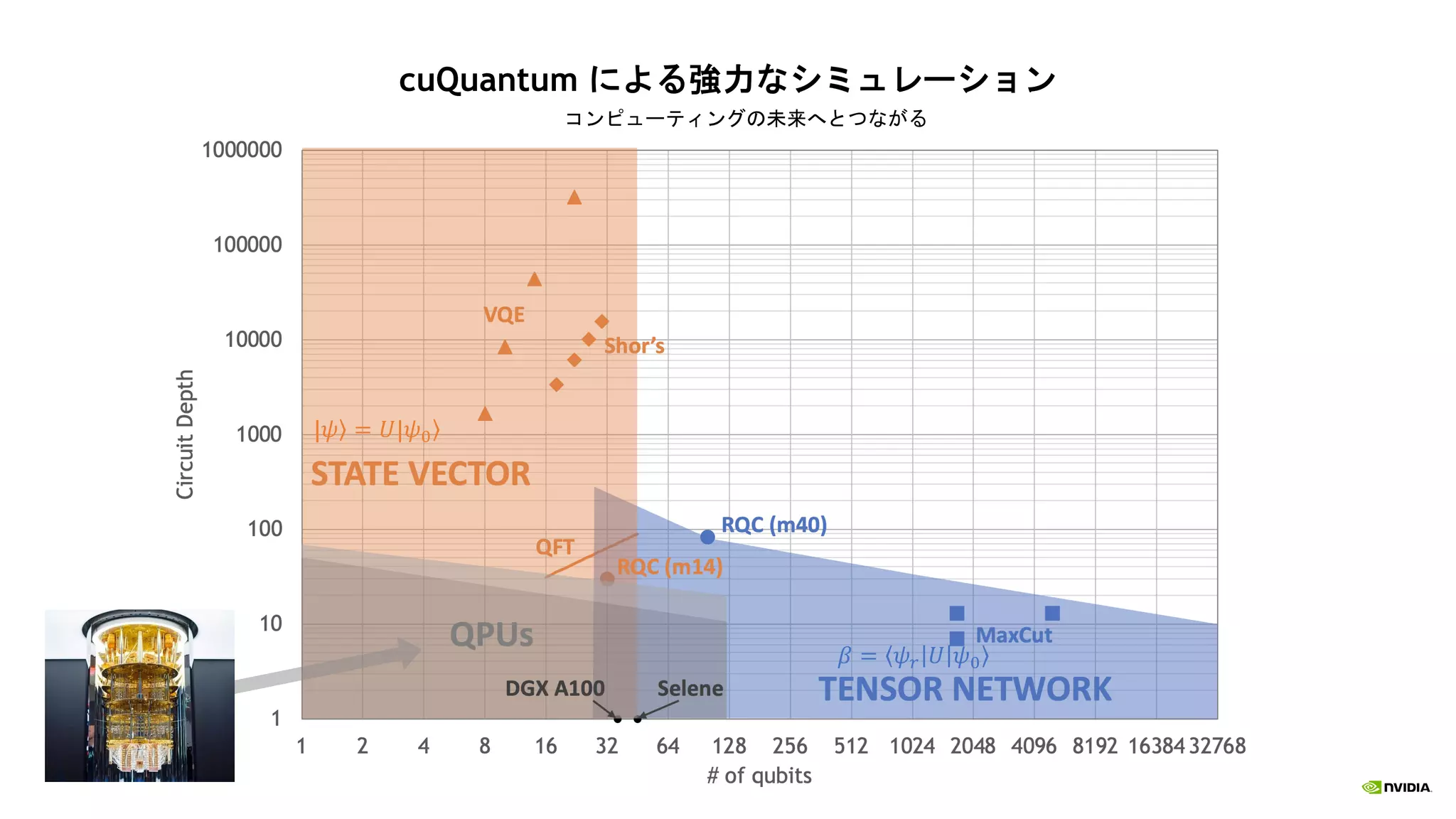
cuQuantum の性能
12.
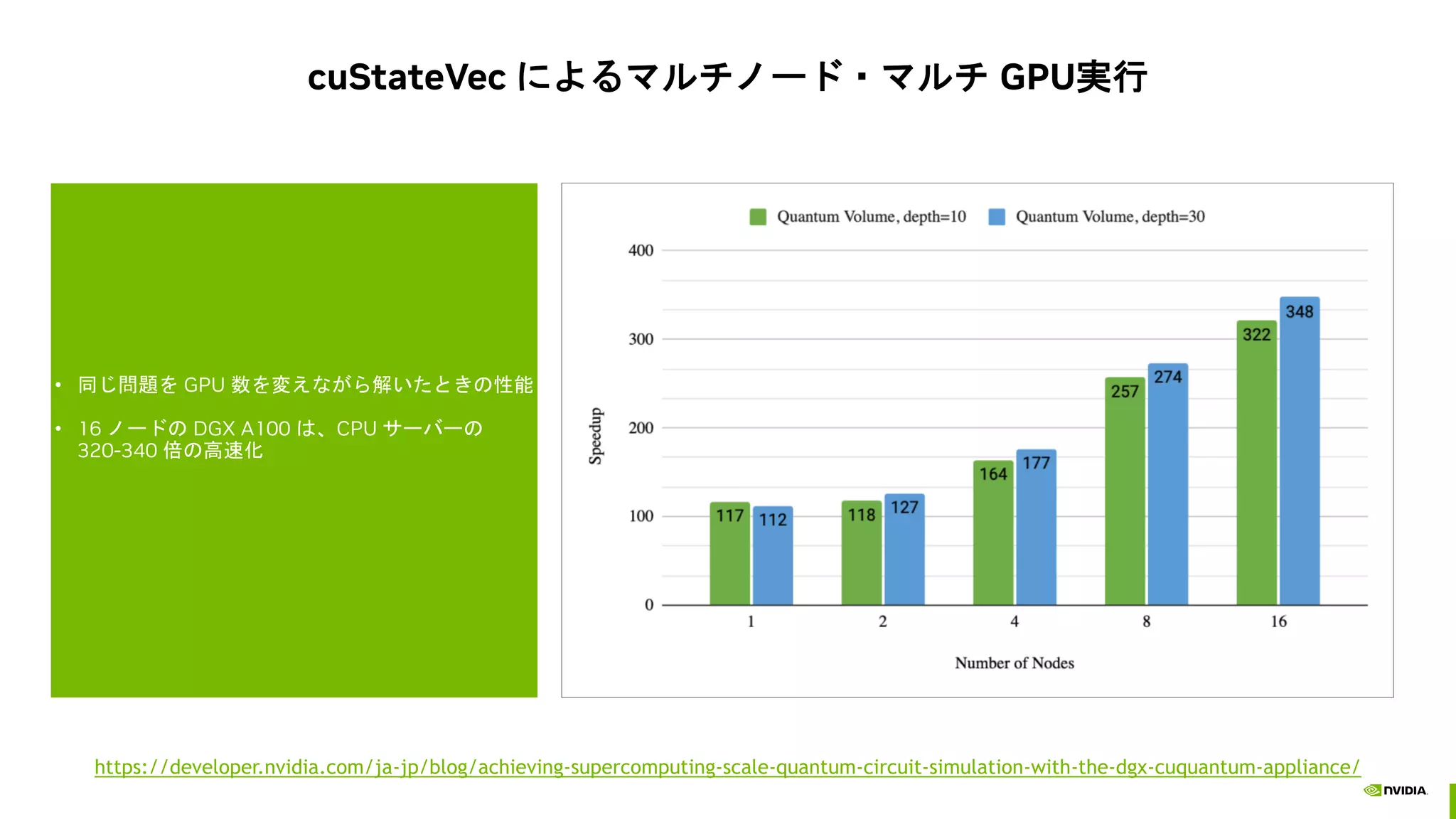
A100 GPU におけるcirq/qsim + cuStateVec の暫定的パフォーマンス
A100 80GB と 64 コア CPU の比較 VQE の高速化 シングル CPU との比較
Benchmarks run using cirq/qsim with modifications to integrate cuStateVec
CPUs used were AMD EPYC 7742 with 64 cores
QFT circuit with 32 qubits and depth 63
Shor’s circuit with 30 qubit and depth 15560 (integer factorized: 65)
Sycamore supremacy circuit m=14 with 7480 gates
VQE benchmarks have all orbitals and results were measured for the energy
function evaluation
cuStateVec – 単一 GPU の性能
NVIDIA H100 TensorCore GPU
Unprecedented Performance, Scalability, and
Security for Every Data Center
FP8, FP16, TF32 performance include sparsity. X-factor compared to A100
HIGHEST AI AND HPC PERFORMANCE
4PF FP8 (6X)| 2PF FP16 (3X)| 1PF TF32 (3X)| 60TF FP64 (3X)
3TB/s (1.5X), 80GB HBM3 memory
TRANSFORMER MODEL OPTIMIZATIONS
6X faster on largest transformer models
HIGHEST UTILIZATION EFFICIENCY AND
SECURITY
7 Fully isolated & secured instances, guaranteed QoS
2nd Gen MIG | Confidential Computing
FASTEST, SCALABLE INTERCONNECT
900 GB/s GPU-2-GPU connectivity (1.5X)
up to 256 GPUs with NVLink Switch | 128GB/s PCI Gen5
19.
DGX H100 HardwareFeature Summary
GPU 8 x NVIDIA H100 Tensor Core GPUs
GPU memory 640 GB total
Performance 32 petaFLOPs FP8
NVswitches 4
CPUs 2 x x86
System Memory 2 TB
Networking
connectivity and speed
4 x OSFP ports provide connectivity to 8 x NVIDIA
ConnectX-7s
8 x 400Gb/s InfiniBand/Ethernet*
2 x dual-port NVIDIA ConnectX-7
1 x 400Gb/s InfiniBand/Ethernet and
1 x 200Gb/s InfiniBand/Ethernet*
Cache Storage 8 x U.2 3.84TB NVMe Secure Erase Drives
Boot Storage 2 x 1.92TB M.2 NVMe (software encryptable)
Host Management On-board 10Gb/s RJ-45 Ethernet
Optional 50Gb/s QSFP Ethernet NIC
Remote System
Management
Baseboard Management Controller (BMC)
1Gb/s RJ-45 network connectivity
Remote Keyboard, Video, Mouse (KVM)
Remote Storage
RedFish, IPMI management
Operating System DGX OS based on Ubuntu
Additional support for Ubuntu and Red Hat Enterprise
Linux
NVIDIA DGX H100
The world’s first AI system with the NVIDIA H100 Tensor Core GPU
* Subject to Change
20.
DGX H100 ExplodedView
Power Supplies
Chassis
GPU tray
Motherboard
Front Cage
Bezel
Fan Modules
Secure Erase Drives
Front Console
Board
Understanding DGX BasePODvs DGX SuperPOD
Scalable, foundational architecture
• Flexible reference architectures
• Powered by Base Command
• Sold through channel
• Partner professional services
• Validated against key benchmarks
• Foundation for partner branded offerings
Digital twin of NVIDIA’s infrastructure
• Turnkey data center product
• Powered by Base Command
• Sold through channel, but with mandatory…
…white-glove NVIDIA PS – order > install > commission
• Certified performance for the most complex workloads
• No customization, no partner re-branding
NVIDIA DGX BasePOD NVIDIA DGX SuperPOD
Customer needs:
• Choice of flexible vs performance optimized designs
• Inclusion of non-SuperPOD certified storage
Customer needs:
• a replica of NVIDIA’s infrastructure
• a turnkey deployment
• full-stack support of the entire deployment









![NVIDIA’ l n DGX P D
[1] Danylo Lykov et al, Tensor Network Quantum Simulator With Step-Dependent Parallelization, 2020
https://arxiv.org/pdf/2012.02430.pdf
0
2000
4000
6000
8000
10000
12000
Category 1
グラフ タイトル
210
512
3,375
10,000
Previous largest
problem, Theta
Supercomputer [1]
Single GPU
97% Accuracy
Supercomputer
97% Accuracy
Supercomputer
93% Accuracy
頂点の数
• NVIDIA の Selene スーパーコンピューターを利用
• 3,375 頂点問題 (1,688 量子ビット) で精度 97%
• 10,000 頂点問題 (5,000 量子ビット) で精度 93%
スーパーコンピューターへの拡張](https://image.slidesharecdn.com/20221129nvidiacuquantum-221212045104-823ba6cf/75/NVIDIA-cuQuantum-SDK-16-2048.jpg)







![関連情報
▪ cuQuantum SDK
https://developer.nvidia.com/cuquantum-sdk
▪ cuQuantum GitHub リポジトリ
https://github.com/NVIDIA/cuQuantum
▪ NVIDIA cuQuantum アプライアンス
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/cuquantum-appliance
▪ NVIDIA ブログ「量子コンピューティングとは」
https://blogs.nvidia.co.jp/2021/04/16/what-is-quantum-computing/
▪ NVIDIA ブログ「NVIDIA cuQuantum と QODA を採用する研究者や科学者が拡大」
https://blogs.nvidia.co.jp/2022/09/26/cuquantum-qoda-adoption-accelerates/
▪ Lightning-fast simulations with PennyLane and the NVIDIA cuQuantum SDK
https://pennylane.ai/blog/2022/07/lightning-fast-simulations-with-pennylane-and-the-nvidia-cuquantum-sdk/
▪ Orquestra Integrates with NVIDIA cuQuantum
https://www.zapatacomputing.com/orquestra-cuquantum-integration/
▪ [GTC22] Defining the Quantum-Accelerated Supercomputer
https://www.nvidia.com/en-us/on-demand/session/gtcfall22-a41134/
▪ [GTC22] Scaling Quantum Circuit Simulations with cuQuantum for Quantum Algorithms
https://www.nvidia.com/en-us/on-demand/session/gtcfall22-a41102/](https://image.slidesharecdn.com/20221129nvidiacuquantum-221212045104-823ba6cf/75/NVIDIA-cuQuantum-SDK-24-2048.jpg)





































![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)





































