Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takefumi MIYOSHI
PDF, PPTX
2,568 views
Reconf_201409
"企業における"なんて話をさせていただくのは 大変おこがましいのですが...
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 38
2
/ 38
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PDF
Synthesijer.Scala (PROSYM 2015)
by
Takefumi MIYOSHI
PDF
ICD/CPSY 201412
by
Takefumi MIYOSHI
PDF
FPGAのトレンドをまとめてみた
by
Takefumi MIYOSHI
PDF
Reconf 201506
by
Takefumi MIYOSHI
PDF
FPGAX6_hayashi
by
愛美 林
PDF
Fpgax 20130604
by
Takefumi MIYOSHI
PDF
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法
by
Kentaro Sano
PDF
増え続ける情報に対応するためのFPGA基礎知識
by
なおき きしだ
Synthesijer.Scala (PROSYM 2015)
by
Takefumi MIYOSHI
ICD/CPSY 201412
by
Takefumi MIYOSHI
FPGAのトレンドをまとめてみた
by
Takefumi MIYOSHI
Reconf 201506
by
Takefumi MIYOSHI
FPGAX6_hayashi
by
愛美 林
Fpgax 20130604
by
Takefumi MIYOSHI
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法
by
Kentaro Sano
増え続ける情報に対応するためのFPGA基礎知識
by
なおき きしだ
What's hot
PPTX
Abstracts of FPGA2017 papers (Temporary Version)
by
Takefumi MIYOSHI
PDF
Fpga local 20130322
by
Takefumi MIYOSHI
PPTX
ラプラシアンフィルタをZedBoardで実装(ソフトウェアからハードウェアにオフロード)
by
marsee101
PDF
Vyatta 201310
by
Takefumi MIYOSHI
PPTX
Myoshimi extreme
by
Masato Yoshimi
PDF
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
PPT
FPGA
by
firewood
PDF
SDN Japan: ovs-hw
by
ykuga
PPTX
高速シリアル通信を支える技術
by
Natsutani Minoru
PDF
FPGAで作るOpenFlow Switch (FPGAエクストリーム・コンピューティング 第6回) FPGAX#6
by
Kentaro Ebisawa
PDF
High speed-pc-router 201505
by
ykuga
PPTX
FPGAって、何?
by
Toyohiko Komatsu
PDF
Gpu vs fpga
by
Yukitaka Takemura
PDF
FPGA+SoC+Linux実践勉強会資料
by
一路 川染
PDF
ソフトウェア技術者はFPGAをどのように使うか
by
なおき きしだ
PPTX
研究者のための Python による FPGA 入門
by
ryos36
PPTX
ハードウェア技術の動向 2015/02/02
by
maruyama097
Abstracts of FPGA2017 papers (Temporary Version)
by
Takefumi MIYOSHI
Fpga local 20130322
by
Takefumi MIYOSHI
ラプラシアンフィルタをZedBoardで実装(ソフトウェアからハードウェアにオフロード)
by
marsee101
Vyatta 201310
by
Takefumi MIYOSHI
Myoshimi extreme
by
Masato Yoshimi
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
FPGA
by
firewood
SDN Japan: ovs-hw
by
ykuga
高速シリアル通信を支える技術
by
Natsutani Minoru
FPGAで作るOpenFlow Switch (FPGAエクストリーム・コンピューティング 第6回) FPGAX#6
by
Kentaro Ebisawa
High speed-pc-router 201505
by
ykuga
FPGAって、何?
by
Toyohiko Komatsu
Gpu vs fpga
by
Yukitaka Takemura
FPGA+SoC+Linux実践勉強会資料
by
一路 川染
ソフトウェア技術者はFPGAをどのように使うか
by
なおき きしだ
研究者のための Python による FPGA 入門
by
ryos36
ハードウェア技術の動向 2015/02/02
by
maruyama097
Viewers also liked
PDF
社会の意見のダイナミクスを物理モデルとして考えてみる
by
takeshi0406
PDF
私のファミコンのfpsは530000です。もちろんフルパワーで(以下略
by
Hiroki Nakahara
PDF
深層学習フレームワークChainerの紹介とFPGAへの期待
by
Seiya Tokui
PDF
Lengua 5 2
by
Bernardita Naranjo
PDF
Lengua 5 3
by
Bernardita Naranjo
PDF
Lengua 5 1
by
Bernardita Naranjo
PDF
Tensor flow usergroup 2016 (公開版)
by
Hiroki Nakahara
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
社会の意見のダイナミクスを物理モデルとして考えてみる
by
takeshi0406
私のファミコンのfpsは530000です。もちろんフルパワーで(以下略
by
Hiroki Nakahara
深層学習フレームワークChainerの紹介とFPGAへの期待
by
Seiya Tokui
Lengua 5 2
by
Bernardita Naranjo
Lengua 5 3
by
Bernardita Naranjo
Lengua 5 1
by
Bernardita Naranjo
Tensor flow usergroup 2016 (公開版)
by
Hiroki Nakahara
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
Similar to Reconf_201409
PDF
2012研究室紹介(大川)
by
猛 大川
PPT
20140310 fpgax
by
funadasatoshi
PDF
Python physicalcomputing
by
Noboru Irieda
PDF
FPGA startup 第一回 LT
by
Yamato Kazuhiro
PDF
Synthesijer and Synthesijer.Scala in HLS-friends 201512
by
Takefumi MIYOSHI
PDF
Synthesijer fpgax 20150201
by
Takefumi MIYOSHI
PPTX
ソフトウェア志向の組込みシステム協調設計環境
by
Hideki Takase
PPTX
Starc verilog hdl2013d
by
Kiyoshi Ogawa
PDF
FPGAをロボット(ROS)で「やわらかく」使うには
by
Hideki Takase
PDF
Introduction of FPGA
by
Imaoka Micihihiro
PDF
ソフトウェア技術者から見たFPGAの魅力と可能性
by
Kenichiro MITSUDA
PPTX
Androidとfpgaを高速fifo通信させちゃう
by
ksk sue
PDF
[DL Hacks]FPGA入門
by
Deep Learning JP
PDF
第11回ACRiウェビナー_インテル/竹村様ご講演資料
by
直久 住川
PDF
第3回ローレイヤー勉強会 : FPGAでコンピュータを作ってみた
by
Ito Takahiro
PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
PDF
FPGAスタートアップ資料
by
marsee101
PDF
藤枝先生ご講演資料_20210824_de10
by
直久 住川
PDF
Fpga online seminar by fixstars (1st)
by
Fixstars Corporation
PDF
FPGAベースのソーティングアクセラレータの設計と実装
by
Ryohei Kobayashi
2012研究室紹介(大川)
by
猛 大川
20140310 fpgax
by
funadasatoshi
Python physicalcomputing
by
Noboru Irieda
FPGA startup 第一回 LT
by
Yamato Kazuhiro
Synthesijer and Synthesijer.Scala in HLS-friends 201512
by
Takefumi MIYOSHI
Synthesijer fpgax 20150201
by
Takefumi MIYOSHI
ソフトウェア志向の組込みシステム協調設計環境
by
Hideki Takase
Starc verilog hdl2013d
by
Kiyoshi Ogawa
FPGAをロボット(ROS)で「やわらかく」使うには
by
Hideki Takase
Introduction of FPGA
by
Imaoka Micihihiro
ソフトウェア技術者から見たFPGAの魅力と可能性
by
Kenichiro MITSUDA
Androidとfpgaを高速fifo通信させちゃう
by
ksk sue
[DL Hacks]FPGA入門
by
Deep Learning JP
第11回ACRiウェビナー_インテル/竹村様ご講演資料
by
直久 住川
第3回ローレイヤー勉強会 : FPGAでコンピュータを作ってみた
by
Ito Takahiro
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
FPGAスタートアップ資料
by
marsee101
藤枝先生ご講演資料_20210824_de10
by
直久 住川
Fpga online seminar by fixstars (1st)
by
Fixstars Corporation
FPGAベースのソーティングアクセラレータの設計と実装
by
Ryohei Kobayashi
More from Takefumi MIYOSHI
PDF
DAS_202109
by
Takefumi MIYOSHI
PDF
ACRiルーム1年間の活動と 新たな取り組み
by
Takefumi MIYOSHI
PDF
RISC-V introduction for SIG SDR in CQ 2019.07.29
by
Takefumi MIYOSHI
PDF
Misc for edge_devices_with_fpga
by
Takefumi MIYOSHI
PDF
Cq off 20190718
by
Takefumi MIYOSHI
PDF
Synthesijer - HLS frineds 20190511
by
Takefumi MIYOSHI
PDF
Reconf 201901
by
Takefumi MIYOSHI
PDF
Hls friends 201803.key
by
Takefumi MIYOSHI
PDF
Hls friends 20161122.key
by
Takefumi MIYOSHI
PDF
Slide
by
Takefumi MIYOSHI
PDF
Das 2015
by
Takefumi MIYOSHI
PDF
Microblaze loader
by
Takefumi MIYOSHI
PDF
Synthesijer jjug 201504_01
by
Takefumi MIYOSHI
PDF
Synthesijer zynq qs_20150316
by
Takefumi MIYOSHI
PDF
Synthesijer hls 20150116
by
Takefumi MIYOSHI
PDF
Fpgax 20130830
by
Takefumi MIYOSHI
PDF
Ptt391
by
Takefumi MIYOSHI
PDF
Google 20130218
by
Takefumi MIYOSHI
PDF
Bluespec @waseda(PDF)
by
Takefumi MIYOSHI
DAS_202109
by
Takefumi MIYOSHI
ACRiルーム1年間の活動と 新たな取り組み
by
Takefumi MIYOSHI
RISC-V introduction for SIG SDR in CQ 2019.07.29
by
Takefumi MIYOSHI
Misc for edge_devices_with_fpga
by
Takefumi MIYOSHI
Cq off 20190718
by
Takefumi MIYOSHI
Synthesijer - HLS frineds 20190511
by
Takefumi MIYOSHI
Reconf 201901
by
Takefumi MIYOSHI
Hls friends 201803.key
by
Takefumi MIYOSHI
Hls friends 20161122.key
by
Takefumi MIYOSHI
Slide
by
Takefumi MIYOSHI
Das 2015
by
Takefumi MIYOSHI
Microblaze loader
by
Takefumi MIYOSHI
Synthesijer jjug 201504_01
by
Takefumi MIYOSHI
Synthesijer zynq qs_20150316
by
Takefumi MIYOSHI
Synthesijer hls 20150116
by
Takefumi MIYOSHI
Fpgax 20130830
by
Takefumi MIYOSHI
Ptt391
by
Takefumi MIYOSHI
Google 20130218
by
Takefumi MIYOSHI
Bluespec @waseda(PDF)
by
Takefumi MIYOSHI
Reconf_201409
1.
企業におけるFPGAアプリケーション 研究開発の一例 株式会社イーツリーズ・ジャパン/わさらぼ合同会社
三好 健文 2014.09.19
2.
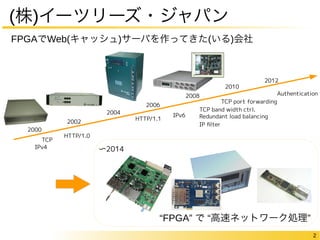
Authentication 2 (株)イーツリーズ・ジャパン
FPGAでWeb(キャッシュ)サーバを作ってきた(いる)会社 2000 2002 2004 2006 2008 2010 2012 TCP HTTP/1.0 IPv4 TCP band width ctrl. IPv6 Redundant load balancing IP filter TCP port forwarding HTTP/1.1 “FPGA” で “高速ネットワーク処理” 〜2014
3.
3 コンテンツ ✔
FPGAアプリケーション事例 ✔ 低消費電力かつ高性能アプリケーション ✔ クロックレベルの決定性の活用 ✔ 容易・柔軟なI/Oアクセスの利用 ✔ I/O性能の指針 ✔ 開発コスト削減の努力
4.
4 コンテンツ ✔
FPGAアプリケーション事例 ✔ 低消費電力かつ高性能アプリケーション ✔ クロックレベルの決定性の活用 ✔ 容易・柔軟なI/Oアクセスの利用 ✔ I/O性能の指針 ✔ 開発コスト削減の努力
5.
5 freeocean ✔
低消費電力,高性能 ネットワークI/F 100/1000BASE-T x 4 対応プロトコルHTTP/1.1, (IPv4, IPv6, TCP, ICMP) メモリ(コンテンツ用) DDR2 SDRAM 4GB〜32GB 最大同時コネクション数491,520 サイズ1.5U(430x603x66 mm) 最大消費電力300W未満
6.
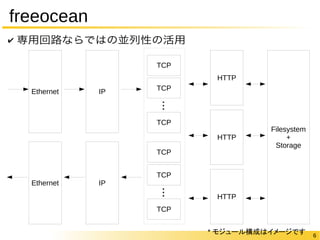
6 freeocean ✔
専用回路ならではの並列性の活用 Ethernet IP TCP HTTP Ethernet IP TCP ・・・ TCP TCP TCP ・・・ TCP HTTP HTTP Filesystem + Storage * モジュール構成はイメージです
7.
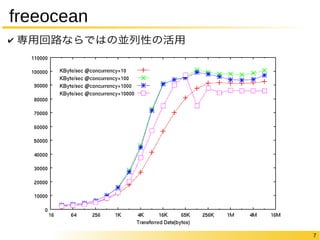
7 freeocean ✔
専用回路ならではの並列性の活用 KBps
8.
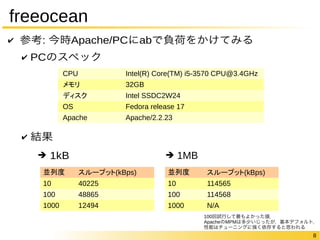
8 freeocean ✔
参考: 今時Apache/PCにabで負荷をかけてみる ✔ PCのスペック ✔ 結果 CPU Intel(R) Core(TM) i5-3570 CPU@3.4GHz メモリ 32GB ディスク Intel SSDC2W24 OS Fedora release 17 Apache Apache/2.2.23 ➔ 1kB ➔ 1MB 並列度スループット(kBps) 10 40225 100 48865 1000 12494 並列度スループット(kBps) 10 114565 100 114568 1000 N/A 100回試行して最もよかった値. ApacheのMPMは多少いじったが,基本デフォルト. 性能はチューニングに強く依存すると思われる
9.
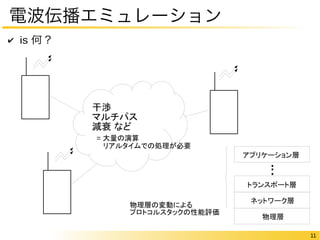
11 電波伝播エミュレーション 干渉
マルチパス 減衰 など アプリケーション層... トランスポート層 ネットワーク層 物理層 ✔ is 何? = 大量の演算 リアルタイムでの処理が必要 物理層の変動による プロトコルスタックの性能評価
10.
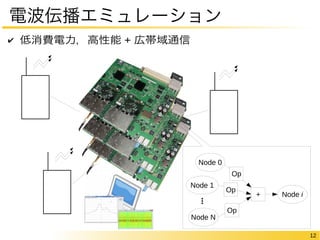
12 電波伝播エミュレーション ✔
低消費電力,高性能 + 広帯域通信 Node 0 Node 1 Node N + Node i Op Op Op ...
11.
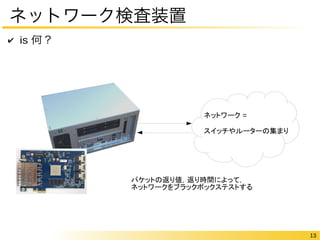
13 ネットワーク検査装置 ✔
is 何? ネットワーク = スイッチやルーターの集まり パケットの返り値,返り時間によって, ネットワークをブラックボックステストする
12.
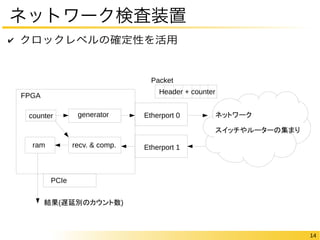
14 ネットワーク検査装置 ✔
クロックレベルの確定性を活用 ネットワーク スイッチやルーターの集まり FPGA Packet Etherport 0 Etherport 1 generator PCIe recv. & comp. counter ram Header + counter 結果(遅延別のカウント数)
13.
15 exStickによる組込みNW機器 ✔
豊富・柔軟なI/Oの活用 GPIOたくさん 100Mbps Ethernet
14.
16 exStickによる組込みNW機器 ✔
豊富・柔軟なI/Oの活用
15.
17 exStickによる組込みNW機器 ✔
豊富・柔軟なI/Oの活用
16.
18 コンテンツ ✔
FPGAアプリケーション事例 ✔ 低消費電力かつ高性能アプリケーション ✔ クロックレベルの決定性の活用 ✔ 容易・柔軟なI/Oアクセスの利用 ✔ I/O性能の指針 ✔ 開発コスト削減の努力
17.
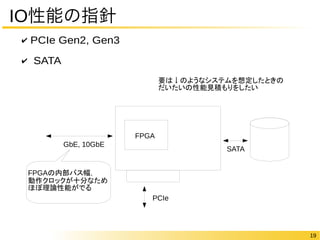
19 IO性能の指針 ✔
PCIe Gen2, Gen3 ✔ SATA FPGA GbE, 10GbE PCIe SATA FPGAの内部バス幅, 動作クロックが十分なため ほぼ理論性能がでる 要は↓のようなシステムを想定したときの だいたいの性能見積もりをしたい
18.
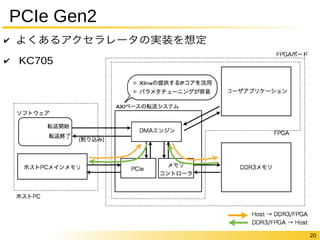
20 PCIe Gen2
✔ よくあるアクセラレータの実装を想定 ✔ KC705
19.
21 PCIe Gen2
20.
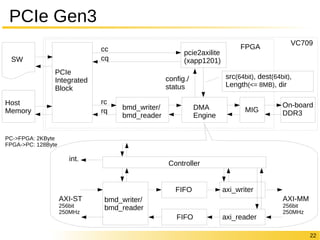
FPGA VC709 22
PCIe Gen3 PCIe Integrated Block cc cq pcie2axilite (xapp1201) rc rq bmd_writer/ bmd_reader config./ status DMA Engine SW Host Memory MIG On-board DDR3 int. Controller FIFO FIFO axi_writer axi_reader bmd_writer/ bmd_reader AXI-ST 256bit 250MHz AXI-MM 256bit 250MHz PC->FPGA: 2KByte FPGA->PC: 128Byte src(64bit), dest(64bit), Length(<= 8MB), dir
21.
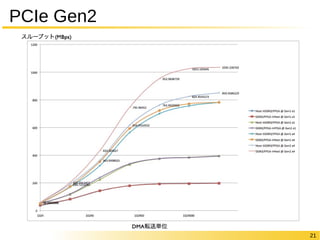
23 PCIe Gen3
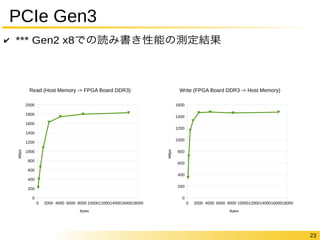
✔ *** Gen2 x8での読み書き性能の測定結果 Write (FPGA Board DDR3 -> Host Memory) 0 2000 4000 6000 8000 1000012000140001600018000 1600 1400 1200 1000 800 600 400 200 0 Bytes MBps Read (Host Memory -> FPGA Board DDR3) 0 2000 4000 6000 8000 1000012000140001600018000 2000 1800 1600 1400 1200 1000 800 600 400 200 0 Bytes MBps
22.
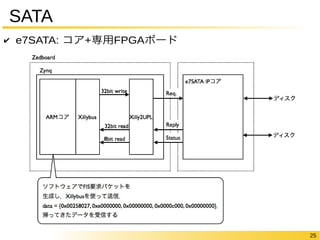
24 SATA ✔
e7SATA: コア+専用FPGAボード2Gb DDR3L Spartan6 XC6SLX45T FMC
23.
25 SATA ✔
e7SATA: コア+専用FPGAボード
24.
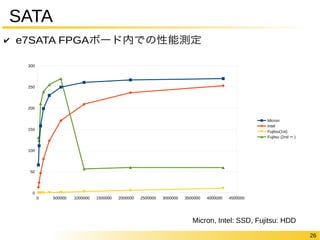
26 SATA ✔
e7SATA FPGAボード内での読み出し性能測定 0 500000 1000000 1500000 2000000 2500000 3000000 3500000 4000000 4500000 300 250 200 150 100 50 0 Micron Intel Fujitsu(1st) Fujitsu (2nd〜) Bytes Micron: RealSSD C400, Intel: Intel SSD 330 Series, Fujitsu: MHV2080BS(HDD) MBps
25.
27 コンテンツ ✔
FPGAアプリケーション事例 ✔ 低消費電力かつ高性能アプリケーション ✔ クロックレベルの決定性の活用 ✔ 容易・柔軟なI/Oアクセスの利用 ✔ I/O性能の指針 ✔ 開発コスト削減の努力
26.
28 開発コスト削減の努力 ✔
Universal Protocol Line ✔ Synthesijer ✔ Synthesijer.scala
27.
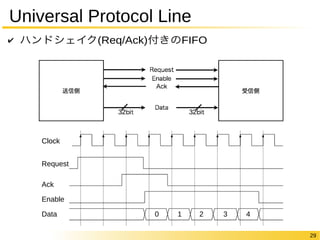
29 Universal Protocol
Line ✔ ハンドシェイク(Req/Ack)付きのFIFO Clock Request Ack Enable Data 0 1 2 3 4
28.
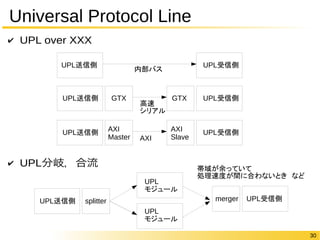
30 Universal Protocol
Line ✔ UPL over XXX 内部バスUPL送信側UPL受信側 UPL送信側GTX GTX UPL受信側 UPL送信側AXI UPL受信側 ✔ UPL分岐,合流 高速 シリアル AXI Master AXI Slave UPL モジュール UPL送信側splitter merger UPL受信側 UPL モジュール 帯域が余っていて 処理速度が間に合わないとき など
29.
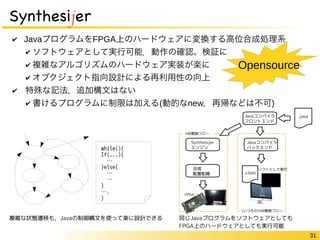
31 Synthesijer ✔
JavaプログラムをFPGA上のハードウェアに変換する高位合成処理系 ✔ ソフトウェアとして実行可能.動作の確認、検証に ✔ 複雑なアルゴリズムのハードウェア実装が楽に ✔ オブクジェクト指向設計による再利用性の向上 ✔ 特殊な記法,追加構文はない Opensource ✔ 書けるプログラムに制限は加える(動的なnew,再帰などは不可) Javaコンパイラ フロントエンド Synthesijer エンジン Javaコンパイラ バックエンド 合成 配置配線 while(){ If(...){ … }else{ … … } …. } 複雑な状態遷移も,Javaの制御構文を使って楽に設計できる同じJavaプログラムをソフトウェアとしても FPGA上のハードウェアとしても実行可能
30.
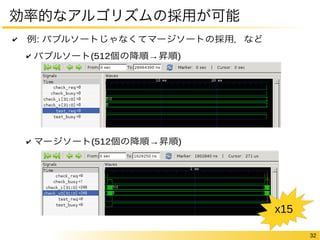
32 効率的なアルゴリズムの採用が可能 ✔ 例:
バブルソートじゃなくてマージソートの採用,など ✔ バブルソート(512個の降順→昇順) ✔ マージソート(512個の降順→昇順) x15
31.
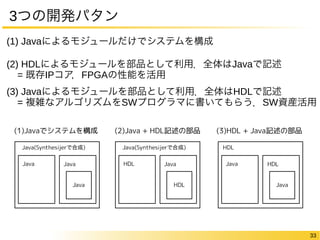
3つの開発パタン (1) Javaによるモジュールだけでシステムを構成
(2) HDLによるモジュールを部品として利用.全体はJavaで記述 = 既存IPコア,FPGAの性能を活用 (3) Javaによるモジュールを部品として利用.全体はHDLで記述 = 複雑なアルゴリズムをSWプログラマに書いてもらう.SW資産活用 33 (1)Javaでシステムを構成(2)Java + HDL記述の部品(3)HDL + Java記述の部品
32.
34 Java+HDL記述の部品 public
void run(){ while(port.ready == false) ; port.op_start = true; port.send_length = port.recv_length; int len = port.data[DATA_LENGTH]; if((len & 0x3) == 0) len = len >> 2; else len = (len >> 2) + 1; for(int i = 0; i < len; i++){ int v = port.data[i+DATA_OFFSET]; int r = 0; r += (toLow((v >> 0) & 0x000000FF)) << 0; r += (toLow((v >> 8) & 0x000000FF)) << 8; r += (toLow((v >> 16) & 0x000000FF)) << 16; r += (toLow((v >> 24) & 0x000000FF)) << 24; port.data[i+DATA_OFFSET] = r; } port.op_start = false; port.op_done = true; port.op_done = false; } } ✔ UPLモジュールにJavaでアクセス package synthesijer.lib.upl; public class UPLPortTest { private final UPLPort port = new UPLPort(); public static int DATA_OFFSET = 4; public static int DATA_LENGTH = 3; private int toLow(int ch){ int ret; if(ch >= 'A' && ch <= 'Z'){ ret = ch - 'A' + 'a'; }else{ ret = ch; } return ret; }
33.
35 HDL+Java記述の部品 FIFO
ドライバ req busy Java モジュール w [byte] f [Hz] スループット T [bps] ドライバ req busy Java モジュール FIFO ドライバ req busy Java モジュール パケットデータが d [byte] のとき全データ入力を受け取るのにかかる時間 = (d/w)*(1/f) [sec] 同様に、全データの出力にかかる時間 = (d/w)*(1/f) [sec] スループットT [bps]を実現するとき、パケットデータを(8*d)*(1/T) [sec]内で処理し続ける必要がある → 各モジュールで処理に使える時間 t は 8*d/T-2*d/(w*f) [sec] → (8*d/T-2*d/(w*f))/(1/f) [cycle] たとえば、d=1500, T=1G, w=4, f=100Mのとき 1パケットあたりの処理にかけられるサイクル数は450サイクル.f=200Mなら1650サイクル
34.
36 Synthesijer.scala ✔
もう普通のHDL(= VHDL/Verilog HDL)は書きたくない ✔ たくさんの似たような名前の変数の定義 ✔ リセット,パルス信号をもとに戻すの忘れる ✔ 制御構造とデータ処理が同じ,な設計モデルはいやだ ✔ 記述の再利用をしたい ✔ データ処理とデータ代入をわけたい もっと高級なHDLがあればいい
35.
37 Synthesijer.scala とは
✔ Synthesijerのバックエンドを使ったScala“で”HDLを書くDSL ✔ signal, port: 状態を変更可能なオブジェクト ✔ expr: 副作用なしの式 ✔ sequencer: 状態遷移機械 ✔ module: モジュール全体 ✔ 上記のオブジェクトをScalaでインスタンス化.つなぎ合わせる.
36.
38 Synthesijer.scala の例(1)
✔ Lチカ def generate_led() : Module = { val m = new Module("led") val q = m.outP("q") val counter = m.signal("counter", 32) q <= m.expr(Op.REF, counter, 5) val seq = m.sequencer("main") counter <= (seq.idle, VECTOR_ZERO) val s0 = seq.idle -> seq.add() counter <= (s0, m.expr(Op.+, counter, 1)) return m } def generate_sim(target:Module, name:String) : SimModule = { val sim = new SimModule(name) val inst = sim.instance(target, "U") val (clk, reset, counter) = sim.system(10) inst.sysClk <= clk inst.sysReset <= reset return sim }
37.
39 Synthesijer.scala の例(2)
val m = new Module("UPLTest") val uplin = new UPLIn(m, "pI0", 32) val uplout = new UPLOut(m, "pO0", 32) val ipaddr = m.inP("pMyIpAddr", 32) val port = m.inP("pMyPort", 16) val server_addr = m.inP("pServerIpAddr", 32) val server_port = m.inP("pServerPort", 16) def wait_trigger():State = ... val ack_ready = m.expr(Op.==, uplout.ack, Constant.HIGH) def wait_ack_and_send_data():State = ... def send_dest_addr():State = ... def send_port():State = ... def send_length():State = ... def send_data():State = ... (idle -> (m.expr(Op.==, trigger, Constant.HIGH), wait_trigger()) -> (ack_ready, wait_ack_and_send_data()) -> send_dest_addr() -> send_port() -> send_length() -> send_data() -> idle) Clock Request Ack Enable Data
38.
40 まとめ ✔
FPGAアプリケーション事例 ✔ 低消費電力かつ高性能 = freeocean,電波伝播エミュ ✔ クロックレベルの決定性 = ネットワーク検査 ✔ 容易・柔軟なI/Oアクセス = exStick ✔ I/O性能の指針 ✔ PCIe,SATAのだいたいの見積もり ✔ 開発コスト削減の努力 ✔ Univarsal Protocol Line ✔ Synthesijer と Synthesijer.scala
Download













![34
Java+HDL記述の部品
public void run(){
while(port.ready == false) ;
port.op_start = true;
port.send_length = port.recv_length;
int len = port.data[DATA_LENGTH];
if((len & 0x3) == 0) len = len >> 2;
else len = (len >> 2) + 1;
for(int i = 0; i < len; i++){
int v = port.data[i+DATA_OFFSET];
int r = 0;
r += (toLow((v >> 0) & 0x000000FF)) << 0;
r += (toLow((v >> 8) & 0x000000FF)) << 8;
r += (toLow((v >> 16) & 0x000000FF)) << 16;
r += (toLow((v >> 24) & 0x000000FF)) << 24;
port.data[i+DATA_OFFSET] = r;
}
port.op_start = false;
port.op_done = true; port.op_done = false;
}
}
✔ UPLモジュールにJavaでアクセス
package synthesijer.lib.upl;
public class UPLPortTest {
private final UPLPort port
= new UPLPort();
public static int DATA_OFFSET = 4;
public static int DATA_LENGTH = 3;
private int toLow(int ch){
int ret;
if(ch >= 'A' && ch <= 'Z'){
ret = ch - 'A' + 'a';
}else{
ret = ch;
}
return ret;
}](https://image.slidesharecdn.com/reconf201409-140921231223-phpapp02/85/Reconf_201409-32-320.jpg)
![35
HDL+Java記述の部品
FIFO
ドライバ
req
busy
Java
モジュール
w [byte]
f [Hz]
スループット T [bps]
ドライバ
req
busy
Java
モジュール
FIFO
ドライバ
req
busy
Java
モジュール
パケットデータが d [byte] のとき全データ入力を受け取るのにかかる時間 = (d/w)*(1/f) [sec]
同様に、全データの出力にかかる時間 = (d/w)*(1/f) [sec]
スループットT [bps]を実現するとき、パケットデータを(8*d)*(1/T) [sec]内で処理し続ける必要がある
→ 各モジュールで処理に使える時間 t は 8*d/T-2*d/(w*f) [sec] → (8*d/T-2*d/(w*f))/(1/f) [cycle]
たとえば、d=1500, T=1G, w=4, f=100Mのとき
1パケットあたりの処理にかけられるサイクル数は450サイクル.f=200Mなら1650サイクル](https://image.slidesharecdn.com/reconf201409-140921231223-phpapp02/85/Reconf_201409-33-320.jpg)


















































![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)

























