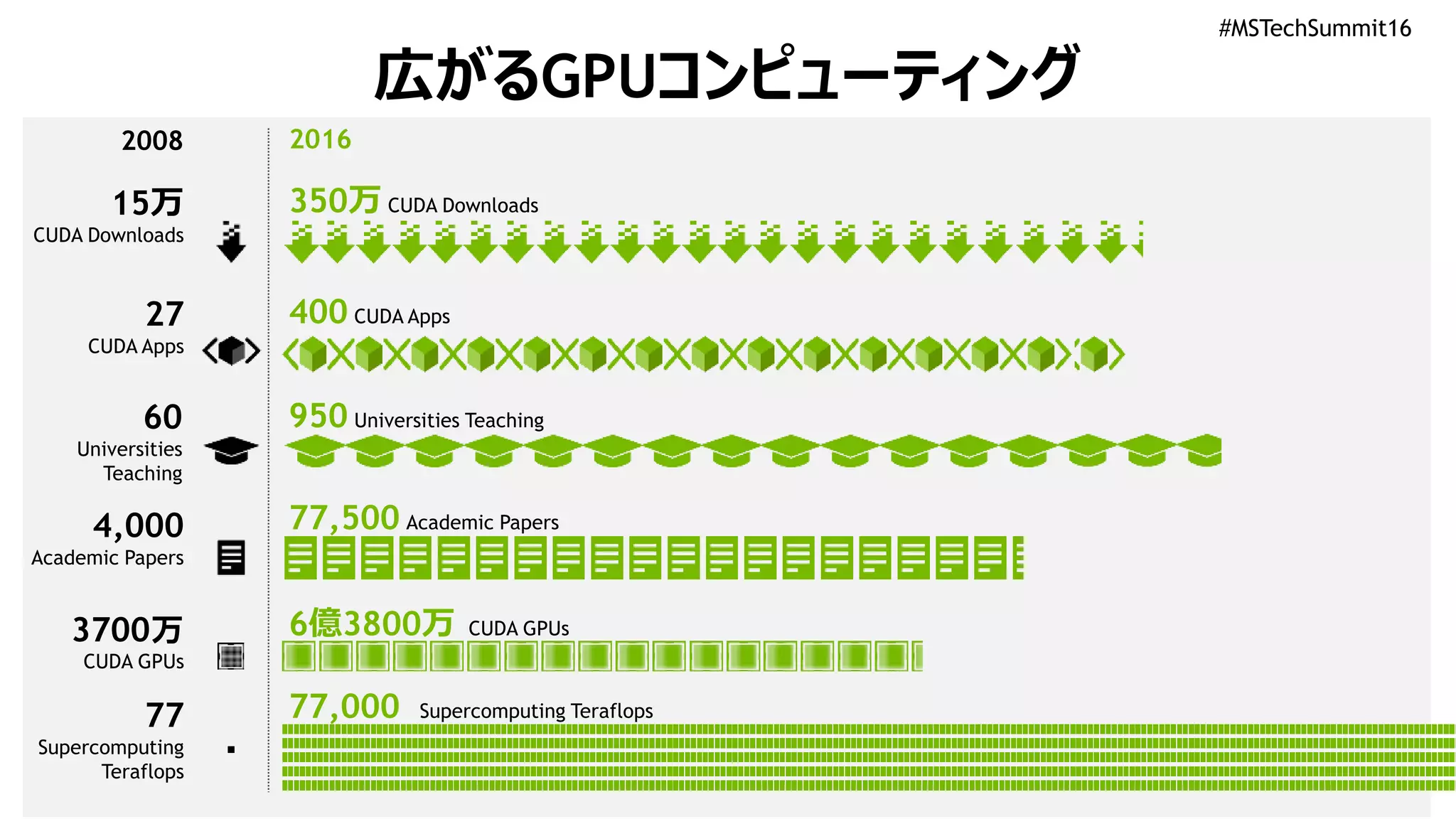
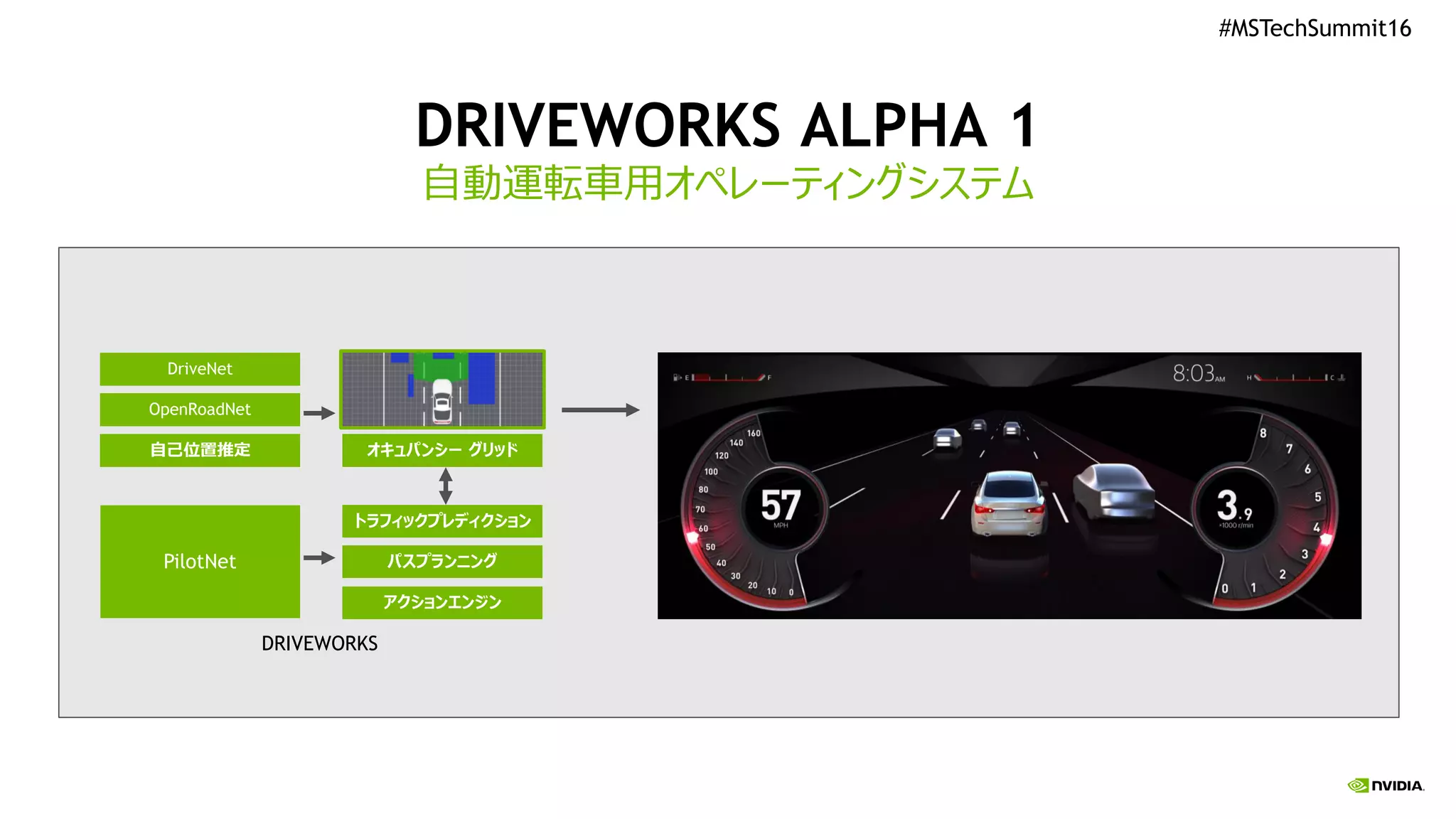
#MSTechSummit16
マルチ GPU を活用
Gradientascent with small mini-batches cannot be meaningfully
parallelized across multiple servers. Instead, we utilize multiple
NVidia Tesla GPGPU devices connected to a single host.
小さなミニバッチでの勾配上昇法は複数サーバーへの並列化ができないため
我々は複数の NVIDIA Tesla GPU を 1 台のホストに搭載した
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
33.
#MSTechSummit16
GPU の効果は絶大
The speed-upfrom using GPGPUs is so large
GPU による高速化は非常に大きなものである
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
34.
#MSTechSummit16
2012 年 DNNで音声認識
Geoffrey Hinton
Li Deng
Dong Yu
George Dahl
Abdel-rahman Mohamed
Navdeep Jaitly
Andrew Senior
Vincent Vanhoucke
Patrick Nguyen
Brian Kingsbury
Tara Sainath
豪華な著者達
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
35.
#MSTechSummit16
この研究でも GPU を活用
Atpresent, the most effective parallelization method
is to parallelize the matrix operations using a GPU.
現時点でもっとも効果的な並列化手法は
GPU で行列演算を行うことだ
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
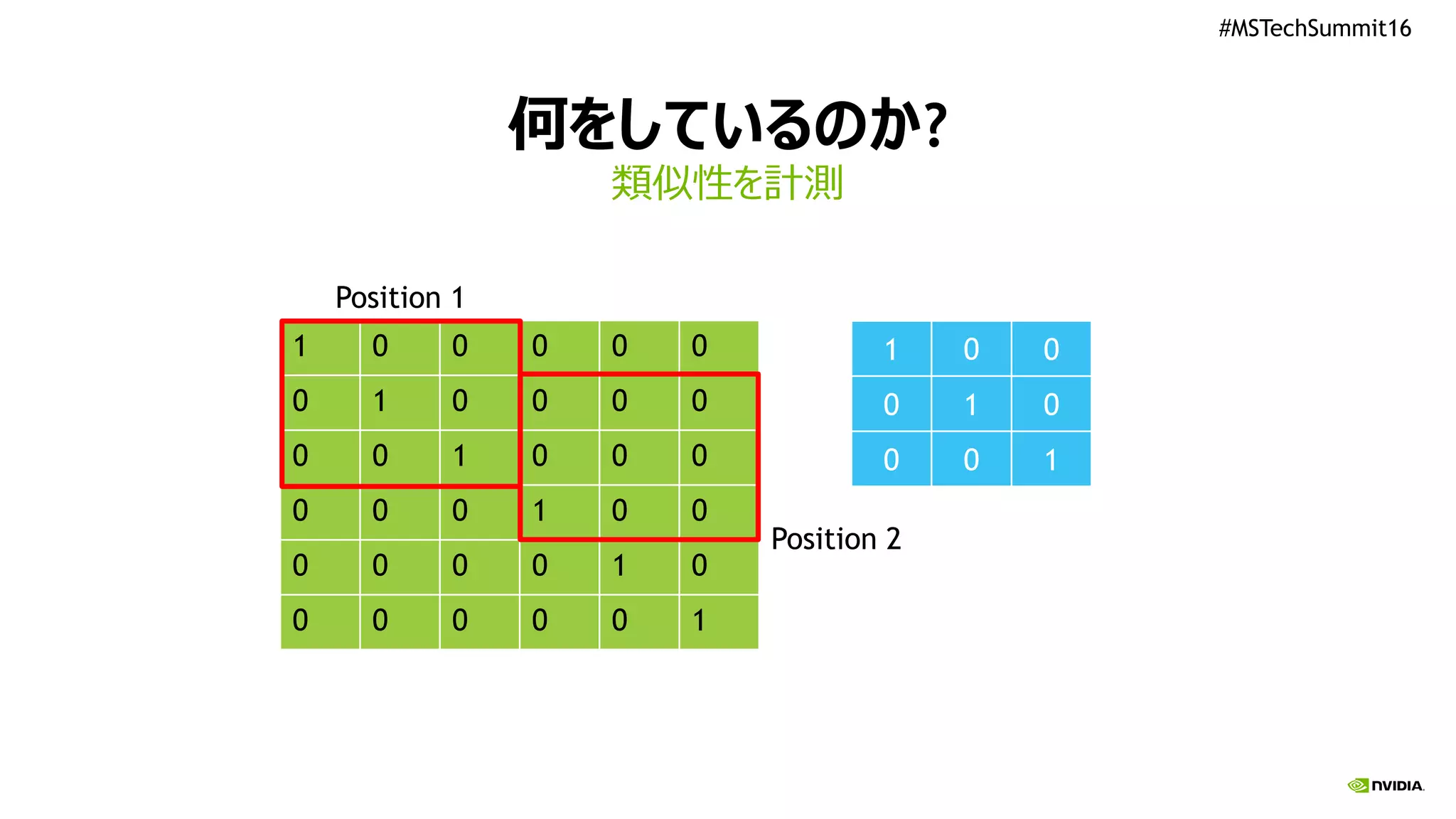
#MSTechSummit16
畳み込みニューラルネットワークと GPU
Luckily, currentGPUs, paired with a highly-optimized
implementation of 2D convolution, are powerful enough to
facilitate the training of interestingly-large CNNs,
幸運なことに、最新の GPU と高度に最適化された 2D 畳み込み
処理実装の組み合わせは、大きな畳み込みニューラルネットワークを
トレーニングするのに十分な能力がある
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
41.
#MSTechSummit16
畳み込みニューラルネットワークと GPU
Our networktakes between five and six days to train on two
GTX 580 3GB GPUs.
我々の(ニューラル)ネットワークは、2 枚の
GTX 580 3GB GPU で 5~6 日間トレーニングした
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
#MSTechSummit16
畳み込みニューラルネットワークと GPU
All ofour experiments suggest that our results can be
improved simply by waiting for faster GPUs and bigger
datasets to become available.
単純にもっと速い GPU と今より大きなデータセットさえあれば、
さらに良い結果が得られるであろう
https://www.microsoft.com/en-us/research/publication/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/
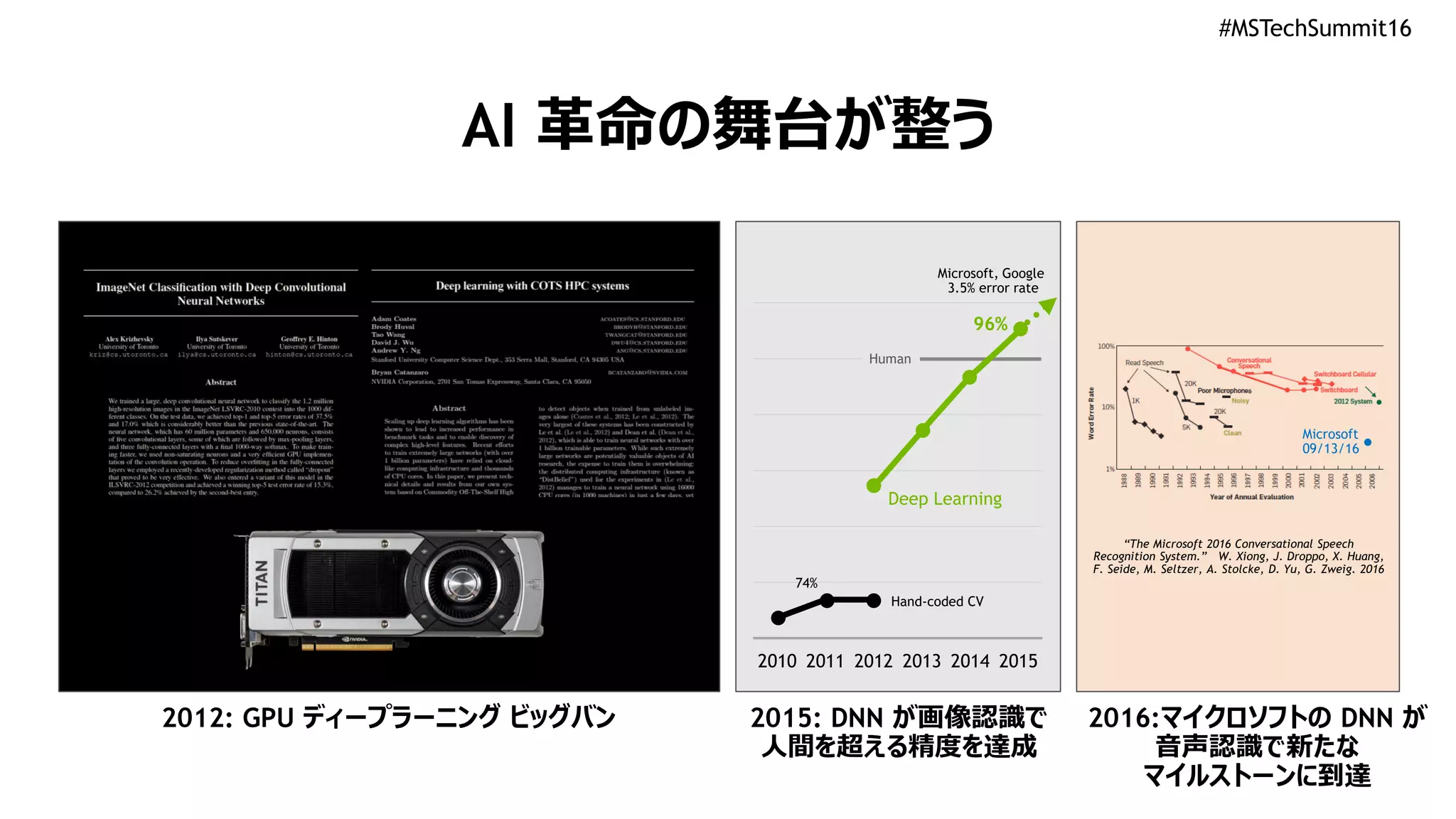
#MSTechSummit16
AI 革命の舞台が整う
2012: GPUディープラーニング ビッグバン 2015: DNN が画像認識で
人間を超える精度を達成
2016:マイクロソフトの DNN が
音声認識で新たな
マイルストーンに到達
74%
96%
2010 2011 2012 2013 2014 2015
Deep Learning
Human
Hand-coded CV
Microsoft, Google
3.5% error rate
Microsoft
09/13/16
“The Microsoft 2016 Conversational Speech
Recognition System.” W. Xiong, J. Droppo, X. Huang,
F. Seide, M. Seltzer, A. Stolcke, D. Yu, G. Zweig. 2016




























































































![DeNAゲーム事業におけるデータエンジニアの貢献 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/techcon2019dataengineer-190218065927-thumbnail.jpg?width=640&height=640&fit=bounds)






![運用中のゲームにAIを導入するには〜プロジェクト推進・ユースケース・運用〜 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/techcon2019okumuraokada-190214063249-thumbnail.jpg?width=640&height=640&fit=bounds)















![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ビッグデータオールスターズ] クラウドサービス最新情報 機械学習/AIでこんなことまでできるんです! (Microsoft編)](https://cdn.slidesharecdn.com/ss_thumbnails/20161218dotsbigdataazureai-161218054508-thumbnail.jpg?width=640&height=640&fit=bounds)






























