More Related Content

PDF
「NVIDIA プロファイラを用いたPyTorch学習最適化手法のご紹介(修正版)」 
PDF
「NVIDIA プロファイラを用いたPyTorch学習最適化手法のご紹介(修正前 typoあり)」 
PDF
Chainer でのプロファイリングをちょっと楽にする話 
PDF

PDF
20170421 tensor flowusergroup 
PDF
OHS#2 GREでディープラーニング学習REST APIを作る 
PDF
20161121 open hyperscale#6 
PDF
What's hot

PDF

PDF

PDF
NGC でインフラ環境整備の時間短縮!素早く始めるディープラーニング 
PDF

PDF

PDF
Maxwell と Java CUDAプログラミング 
PDF

PPTX

PDF
1018: ディープラーニング最新技術情報~cuDNN 3、DIGITS 2、CUDA 7.5のご紹介~ 
PDF

PDF
NVIDIA GRID が実現する GPU 仮想化テクノロジー 
PPTX

PDF
ChainerRL の学習済みモデルを gRPC 経由で使ってみる試み (+アルファ) 
PDF
GTC Japan 2016 Rescaleセッション資料「クラウドHPC ではじめるDeep Learning」- Oct/5/2016 at GTC ... 
PDF
ディープラーニングイメージで構築する快適・高速な機械学習環境 
PDF

PDF
Flow �in VR Funhouse MOD Kit 
PDF
NVIDIA Deep Learning SDK を利用した画像認識 
PDF
Google Cloud AI の紹介 @ GCPUG Nara #03 
PDF
1090: NVIDIA プロフェッショナルビジュアリゼーション Similar to 20170518 eureka dli

PDF
エヌビディアが加速するディープラーニング~進化するニューラルネットワークとその開発方法について~ ![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢 
PDF

PDF
エヌビディアが加速するディープラーニング ~進化するニューラルネットワークとその開発方法について~ 
PDF
1010: エヌビディア GPU が加速するディープラーニング 
PDF
【A-1】AIを支えるGPUコンピューティングの今 
PDF

PDF

PDF

PDF
エヌビディアのディープラーニング戦略 TESLA P100 & NVIDIA DGX-1 
PDF
エヌビディア GPU が加速するディープラーニング 
PDF
Watsonをささえる ハイパフォーマンスクラウドで はじめるDeep Learning 
PDF

PDF
NVIDIA deep learning最新情報in沖縄 
PDF

PDF

PDF
ハードウェア進化についていけ 〜 実用化が進む GPU、そして注目が集まる Edge TPU の威力に迫る 〜 
PDF

PDF
IEEE ITSS Nagoya Chapter NVIDIA 
PDF
GTC 2017 基調講演からディープラーニング関連情報のご紹介 20170518 eureka dli
- 1.
- 2.
2
自己紹介
村上真奈(むらかみまな) / mmurakami@nvidia.com
•CUDAエンジニア+ディープラーニングSA
• ディープラーニング・CUDA技術サポートとか、いろいろ
埼玉県さいたま市
早稲田大学教育学部理学科数学⇒システム計画研究所⇒サムスン日本研究所⇒エヌビディア
画像処理(主に静止画)、ソフトの最適化とか、
プリクラとか放送機器とかテレビとか
2010年頃に初めてCUDAにふれる(CUDA1.XXとかの時代)
NVIDIAGPUComputing
NVIDIAJapan
@NVIDIAJapan
- 3.
- 4.
- 5.
- 6.
- 7.
8
2012 20142008 20102016 2018
48
36
12
0
24
60
72
Tesla
Fermi
Kepler
Maxwell
Pascal
混合精度演算
倍精度演算
3D メモリ
NVLink
Volta
GPU ロードマップ
SGEMM/W
- 8.
- 9.
11
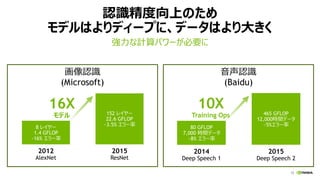
ディープラーニングを加速する3つの要因
MLテクノロジー 計算パワービッグデータ
100 hourvideo
uploaded
per minute
350 million
images uploaded
per day
2.5 trillion
transactions
per hour
0.0
0.5
1.0
1.5
2.0
2.5
3.0
2008 2009 2010 2011 2012 2013 2014
NVIDIA GPU x86 CPU
TFLOPS
TORCH
THEANO
CAFFE
MATCONVNET
PURINEMOCHA.JL
MINERVA MXNET*
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
18
0.0x
0.5x
1.0x
1.5x
2.0x
AlexnetOWT GoogLenet VGG-DIncep v3 ResNet-50
8x M40 8x P40 8x P100 PCIE DGX-1
P100 SXM2 For fastest training
FP32 Training, 8 GPU Per Node
Refer to “Measurement Config.” slide for HW & SW details
AlexnetOWT/GoogLenet use total batch size=1024, VGG-D uses total batch size=512, Incep-v3/ResNet-50 use total batch size=256
Speedup
Img/sec
5506 2088 563 514 706
1.2x
1.2x1.7x
- 16.
- 17.
- 18.
- 19.
22
計算リソース問題
1. AWS(Amazon WebServices)
• Tesla K80に対応。Deep Learning AMI(Amazon Machine Image)が提供されており、すぐに機
械学習を始める事が出来る。
• https://aws.amazon.com
2. Microsoft Azure
• Tesla K80/M60に対応。インフィニバンドで高速にマルチノード計算が可能
• https://azure.microsoft.com
3. Google Cloud Platform
• Tesla K80/P100(近日対応予定)に対応。高速なマルチノード通信。パワフルな計算環境
• https://cloud.google.com
4. IBM Bluemix Infrastructure
• Tesla K80に対応。ベアメタルとして提供。好みの環境にカスタマイズ。
• https://www.ibm.com/cloud-computing/jp/ja/softlayer.html
5. IDCFクラウド
• Tesla K80/P100(近日対応予定)に対応。国内にデータセンター
• https://www.idcf.jp/cloud/
GPUクラウド
- 20.
- 21.
25
ディープラーニング・フレームワーク
Caffe Torch7 CNTKMXNet TensorFlow Chainer
インターフェース C++/Python/Matlab Lua/C
C++/Python/.Net/
BrainScript
C++/Scala/R
JS/python/Go/Matlab
C/C++/Python Python
ライセンス BSD-2 BSD MIT
Apache 2.0
Apache 2.0 MIT
マルチGPU
(1ノード)
○ ○ ○ ○ ○ ○
マルチノード × × ○ ○ ○
△
(※ChainerMN)
モデルの柔軟性 △ ◎ ○ ○ ○ ◎
CNN ○ ○ ○ ○ ○ ○
RNN
○
#2033
○ ○ ○ ○ ○
備考
高速
Caffe Model Zoo
多数のアルゴリズムを
サポート
高速
スケーラビリティ
スケーラビリティ
軽量で組み込みもOK
自動微分
TensorBoard
Define by Run
CuPy
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
31
DIGITS 5
• Imagesegmentation(領域分割)問題に対応!
• ディープラーニング・モデルストア機能を追加!
• 様々なモデルのPre-trained modelをダウンロード可能に
• DIGITSジョブのグループ機能など
•
領域分割タスクに対応した新しいDIGITS
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
39
nvidia-docker+コンテナでアプリケーションを起動
GPU2 GPU3 GPU4GPU6 GPU7
NVIDIA CUDA Driver
Dockerエンジン
GPU5GPU0 GPU1
ホストPC
GPU0 GPU1
CUDA Libraries
Dockerコンテナ1
CUDA 7.5 Runtime
アプリケーション1
GPU0 GPU1 GPU2
CUDA Libraries
Dockerコンテナ2
CUDA 8.0 Runtime
アプリケーション2
GPU0 GPU1 GPU2
CUDA Libraries
Dockerコンテナ3
CUDA 7.0 Runtime
アプリケーション3
- 36.
- 37.