Downloaded 357 times




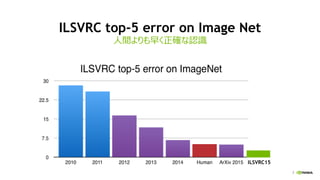







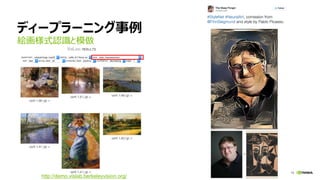

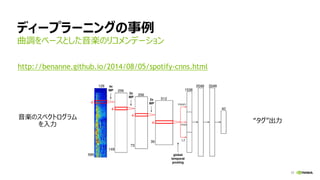




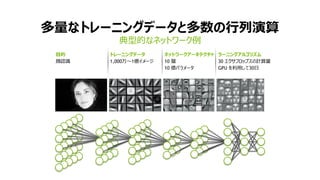
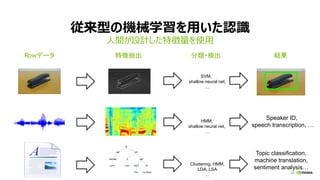
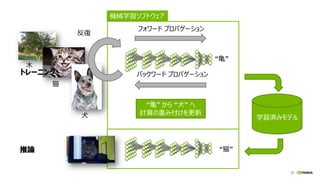

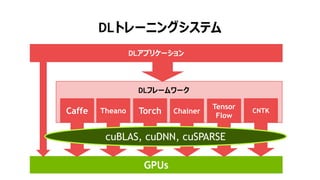
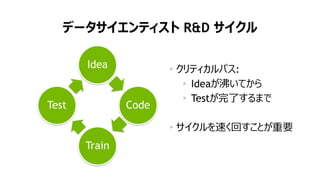
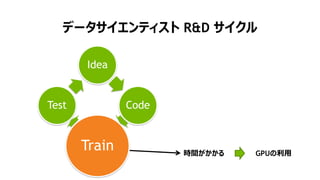






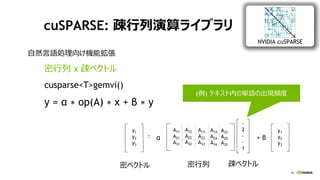
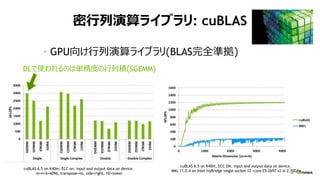
















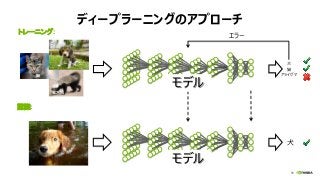




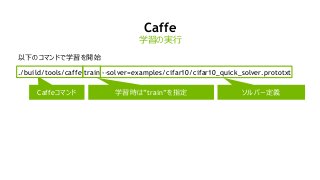




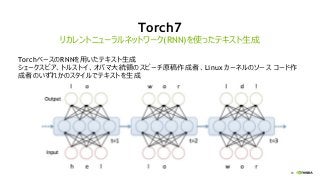






NVIDIA Deep Learning Institute 2016年4月27日のNVIDIA Deep Learning Day 2016 Springの資料です。 エヌビディア合同会社 プラットフォームビジネス本部 ディープラーニングソリューションアーキテクト 兼 CUDA エンジニア 村上 真奈 [概要] ディープラーニングは近年、画像認識の分野で、その高い認識精度から大変注目を集めている技術です。音声認識や自動運転など画像認識の分野以外への応用が進んでおり大変期待されています。本セッションは、日々新しい構造のモデルが提案され進化しているディープラーニングの概要とGPUが必要とされている理由について簡単に説明します。 その後に、実際にディープラーニングの開発のイメージを持って戴けるように、いくつかの代表的なディープラーニングのフレームワークを使い、デモしながら各フレームワークの特徴を解説します。ディープラーニングの最新の状況が知りたい、実際の開発の際にどのフレームワークを使うべきか知りたい、開発を始める前に開発のイメージを持ちたいという方に最適です。










































![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)
























